
May 11
Congratulations for achieving the learning objectives. So happy to see #Ingazi work to support young people in #SkillLearning!
1
3
76

Wealth often creates its own networks, systems, and private circles of influence. The rich usually have access to stronger support structures, faster resources, and powerful connections when challenges arise.
For the poor and middle class, society and community are often expected to provide support, security, and opportunity during crucial life moments—whether for jobs, marriage, emergencies, or social stability.
But the painful reality is that many people feel these systems sometimes offer more symbolic presence than real support during their hardest times, while still claiming credit during visible successes.
This raises an important question:
Are our social systems truly empowering people in vulnerable situations—or are they sometimes maintaining appearances over meaningful action?
Real community should not just celebrate success.
It should stand strong in moments of crisis.
At TrueLove18Club International, we are committed to building a new ecosystem—one that genuinely supports people through:
🔹 Career growth
🔹 Relationship wellness
🔹 Skill development
🔹 Emotional well-being
🔹 Happiness and personal empowerment
Our vision is to create a meaningful global support system where people are valued not only in their victories, but also in their struggles.
TrueLove18Club International
Where Feeling Matters
— Kota RJ Pawan
International Relationship Expert Psychologist
Founder, TrueLove18Club International
#SocialPsychology #CommunitySupport #HumanBehavior #EmotionalWellness #SocialSystems #RelationshipExpert #TrueLove18Club #Leadership #MentalHealthAwareness #SocialReality #PersonalGrowth #CareerDevelopment #SkillLearning #GlobalCommunity #HappinessMatters #kotarjpawan

3
147

Apr 22
a bunch here where I’m saying ok Garry’s kinda right?! 👀…in some ways :) we’re making this loop much easier to close out of the box soon
If more people get into evals & traces to ground self-improving agents from Garry’s posts, there’ll be no one happier than me
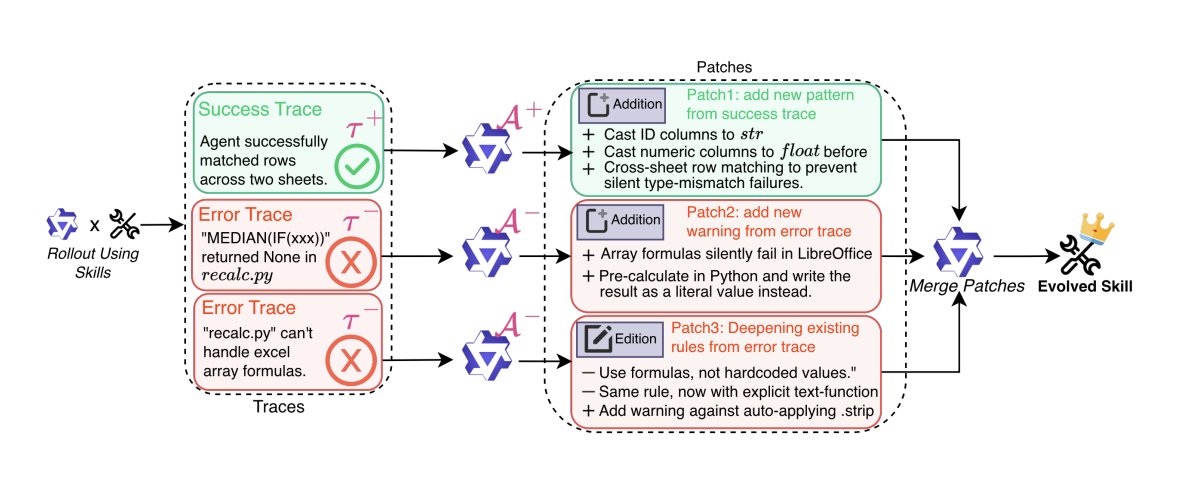
have written about this at length so will also share some linked materials for anyone (including your Clanker) who wants to dig into more details of building evals & self-improving agent systems:
Traces Evals are the lifeblood of agent improvement loops
We point compute at traces so we can classify what agents did wrong. Yes, but the hard part is figuring out what the error even was and how to fix it in a way that actually generalizes over time (not play whack-a-mole with if-else statements all the time). Is our agent a bad long horizon planner for X tasks? Should we change the model, or add better planning instructions, or use subagents to isolate context because these types of tasks bloat the main window.
Evals encode the behavior we want agents to have in production. Generating evals from traces is how we figure out how to measure the changes we’re making over time. This is why we lean so hard into Tracing Evals tooling with LangSmith (more coming soon on making this loop even easier!).
Skill Learning is ONE great Way to Codify Trace Learnings into Context for your Agent
“skillify”/SkillLearning is great, agreed!! (see our /remember youtube video below blogs on hill climbing coding agents), love that Garry’s discovering Skill Learning from Traces as a mechanism for fixing agent mistakes. Skills are semantic bundlers so they basically encompass everything needed to accomplish a goal in one folder like instructions and code. This reduces search in aggregating cross-source information. Skills have built-in context engineering with progressive disclosure which helps many users.
Skills are great, I love them and we use them heavily, but just a note that there’s other approaches you can use to fix errors in production trace data. We discuss them briefly below! Remember
Things to think about more deeply:
Context Engineering Still Matters even with Skills & Resolvers
We still need good context engineering! If you bloat your context window with TONS of skills that are hard for an agent to disambiguate when to use, then the “Resolver” mechanism will suck you’re back in context-rot world. “Resolvers” are classifiers of intent, you need to protect your context window and make sure the “rules” in the table are self-consistent over time and also not massively bloating context.
Good context engineering is often a search problem! We need to find the right context and pass it into the computation boundary —> the context window. The better we do that without confusing the agent, the better our results.
Maybe that looks like Skill Search?! Maybe similar skills should get merged or subagents should actually spend more compute doing proper skill research and disambiguation. If we use Skills as the primary agent update mechanism, then we need to think about how this works with context as we use agents across month and year timescales.
Building in Higher-Level Primitives
I love Skill-Learning but often it’s a whack-a-mole- solution if not managed properly. For example, if you wanted to build an ultra-long horizon coding agent (think Factory Missions or something on Frontier-SWE), then you need to think through the harness architecture of how to work backwards from the goal like how to recursively use subagents & planning. Or how to manage & share context in a filesystem. Traces often help you uncover local issues and skills help you solve those, but it’s very important today to think about agent architecture and working backwards from big problems to avoid the potential local minima of Skill Learning. It’s tbd how much compute you need to use to uncover good agent architecture primitives to solve very hard problems. Skill Learning to fix scoped problems is great in the meantime and maybe can get us much further with smarter models.
Evals Alongside/Beyond LLM as a Judge
The hardest part of this all is by far figuring out what actually went wrong across Traces at scale testing if the proposed fix works over time! Does it work across models? Does it continue to work if you change something else in the system prompt or add another skill? Evals codify the case into an eval that can be detected in realtime (Online Evals/Monitoring). We need to test this stuff, which is why I like using LLM as a Judge that Garry mentions, but there’s much more we can do (programmatic evals, multi-turn cases, containerizing the eval environment to faithfully reproduce what went wrong) - great start, happy to help extend to make your agents better :)
Could write on this for days but I promise you, we’re thinking SUPER hard about primitives for self-improving agents, mining data from Traces, agent-first tooling that makes this possible, and basically any ways we can be helpful to help builders create the best agents in the world.
We have a lot coming soon, reach out if I can help, let’s cook 🚀

7
10
84
20,525

Mar 31
Every time you train an AI agent for a new task, you start from scratch. Trace2Skill from Alibaba changes this by extracting reusable skills from agent execution traces and transferring them across tasks.
The framework dispatches parallel sub-agents to analyze diverse execution trajectories. It extracts trajectory-specific lessons and hierarchically consolidates them into a unified skill directory. Skills generated automatically from trajectories outperform skills written by human experts on VisionQA and math reasoning.
Think of it like a new employee who extracts transferable skills across jobs rather than learning each one from zero. Time management from job 1, debugging from job 2 — those compose into competence at job 3 they've never seen.
Should AI agents write their own training curriculum?
Save this. Follow @drawais_ai for daily AI paper breakdowns — I read it first, try it, then explain it simply.
#Trace2Skill #AIAgents #TransferLearning #Alibaba #Qwen #SkillLearning #ReinforcementLearning #LLM #MachineLearning #AgenticAI #DeepLearning
1
2
45

20 Oct 2025
I cannot avoid to think about what happens when we can have a robot coach that mimics Rafael Nadal on the tennis court...
Just watched Kristen Grauman (@KristenGrauman7) at #ICCV2025 .
Her topic was: Show and Tell: Skill Learning from Video.
AI that learns from how-to videos to coach human skills, from cooking to climbing using ego-exo4D data (gaze, motion, audio, language).
I think robotics could learn a lot from her team’s ego-exo approach... it’s a blueprint for teaching machines how we learn.
#EmbodiedAI #Robotics #SkillLearning #AIResearch #ICCV @ICCVConference



3
175

13 Oct 2025
Learning a new skill can often feel overwhelming—where to start, how to break down the process, and how to track progress.
At @infinityg_ai, you can manage all of this with the Task Breakdown Tool 🧠✨
With the help of AI, you simply write the skill you want to learn → the system will:
📝 Create a step-by-step learning plan
🧭 Provides guidance and logical sequence
📊 Provides real-time progress tracker
Suitable for anyone who wants to learn coding, design, blockchain, or even create personal projects without getting confused along the way.
🌱 Learning becomes more focused, measurable, and enjoyable.
👉 Have you thought about what skills you want to break down into your first roadmap?
#InfinityGround #AI #Web3 #SkillLearning #NoCode #TaskBreakdownTool

ALT Infinity Ground "Task Breakdown Tool: Plan Skill Learning, Track Progress"
2
1
12
2,411

Under the NEP, learning goes beyond classrooms ,focusing on skills, creativity, and holistic growth.
With clubs bringing this vision alive, children are becoming future-ready citizens.
📒🎯
#NEP #SkillLearning #HolisticEducation
#school
#schoolclubs
#skillsinchildren
6
125

15 Jul 2025
With every stitch sew, every tool mastered, a new chapter begins.
#prasannatrust #skilllearning #swamisukhabodhananda #sukhohom

2
26

5 Apr 2025
ನಮ್ಮ ಸರ್ಕಾರ ಉದ್ಯೋಗ ಮೇಳವನ್ನು ಎಲ್ಲೆಡೆ ಆಯೋಜಿಸುತ್ತಿದೆ. ಯಾವ ಸಂಸ್ಥೆಗೆ ಯಾರನ್ನು ಸೇರಿಸಬೇಕು ಎಂಬುದನ್ನು ಮ್ಯಾಪಿಂಗ್ ಮಾಡುತ್ತಿದ್ದೇವೆ. ಸ್ಕಿಲ್ ಕೌನ್ಸಿಲ್, ಇಂಡಸ್ಟ್ರಿ ಲಿಂಕೇಜ್ ಯೋಜನೆ ಮೂಲಕ "ಯುವನಿಧಿ" ಪೋರ್ಟ್ಲ್ನಲ್ಲಿ ಅರ್ಹರನ್ನು ಆಯ್ಕೆ ಮಾಡಿ ತರಬೇತಿ ನೀಡಲಾಗುತ್ತಿದೆ. ಇದಕ್ಕಾಗಿ ಸಂಸ್ಥಗಳು ನಮ್ಮ ಜೊತೆ ಕೈ ಜೋಡಿಸಿವೆ.
ಇದಲ್ಲದೇ "ಕಲಿಕೆ ಜೊತೆಗೆ ಕೌಶಲ್ಯ" ಯೋಜನೆಯಡಿ ತರಬೇತಿ ನೀಡುತ್ತಿದ್ದೇವೆ. ನಮ್ಮ ಸರ್ಕಾರ ಯುವಕರ ಭವಿಷ್ಯದ ಬಗ್ಗೆ ಕಾಳಜಿ ವಹಿಸಿ ಪರಿಣಾಮಕಾರಿ ಕ್ರಮಗಳನ್ನು ಕೈಗೊಳ್ಳುತ್ತಿದೆ.
#SkillJobs #Skilllearning #Yuvanidhi #UdyogMela
1
9
166

9 Jan 2025
According to the latest report by World Economic Forum, the future holds high demands for tech related jobs like AI & machine learning. The study also suggests that US & India are seeing the highest enrolment in AI skills. #WEFreport #worldeconomicforum #AI #machinelearning #jobs #security #skilllearning #cnbctv18digital
Watch here:
youtu.be/qO7g6foNU-Q
1
1,897

Your journey to becoming a Human Resources expert starts here! 📷 Learn the skills to build diverse teams and drive business success. Start shaping the future of work today!
#HRExcellence #CareerGrowth #hrprogram #CCBST #SkillLearning #skills

1
23

#MintPrimer | A well-integrated skill education in the mainstream school curriculum offers many socio-economic benefits. Most students, the report says, drop out of school as they do not perceive regular academic subjects as valuable to their career
Read more: tinyurl.com/ebb4ur6e
#SkillLearning #SkillBasedJobs #SkillDevelopment #SchoolsInIndia #Employment

1
4
1,614
#MintPrimer | A recent #WorldBank skill gap analysis done across six states has thrown up the need to offer #skilleducation in schools for India to reap the demographic dividend and become a developed nation by 2047. Mint looks at the current status and the way forward.
Read more: tinyurl.com/ebb4ur6e
(@Madhuta reports)
#SkillLearning #SkillBasedJobs #SkillDevelopment #SchoolsInIndia

2
1
5
2,284

18 Nov 2024
From research to application: our #demonstrators in action! 🎥 #skilllearning in the #metaverse: #CeTI brings teachers and learners together to promote motor skills such as juggling with haptic feedback and customizable gravity.
@tudresden_de @dfg_public #XR #tactileinternet
1
2
251

8 Jul 2024
Aprendizagem Implícita
#eegLatam #skilllearning #cognitiveNeuroscience #neuroscience #socialinteraction #semioticsResearch #sentienceConsciousness
theneurosoft.com/post/aprend…

7
7
21

4 Jul 2024
When the YouTube tutorial makes it look easy but you're still struggling.
#SkillLearning #StruggleIsReal #LightforthLearning #Lightforth #memes
3
5
9
137

1 Jun 2024
#LtGenMVSuchindraKumar, #ArmyCdrNC & All Ranks of #DhruvaCommand convey best wishes to All Ranks & Veterans of Army Educational Corps & their Families on the occasion of 104th Raising Day.
#Education
#SkillLearning
@adgpi
@artrac_ia
@EduMinOfIndia
12
27
101
12,177

16 May 2024
Boost your brain by learning new skills! 🧠♟ Find out how becoming a pro at games like chess can help you think steps ahead! #BrainPower #SkillLearning discovermagazine.com/mind/le…
2
2,476

10 May 2024
ہنر میں عظمت ہے۔
Be an advocate for the Skill Education
Spot the bus and share a picture in the comment
@EduMinistryPK
@ranamashhood
@ShazaFK
#SpottheBus #NAVTTC #Skilleducation #SkillLearning #ہنرمندپاکستان

3
170

29 Apr 2024
With @SimenLT, @LosnegardThomas, @froemero1, Reid, Gilgien and Haugen.
#motorlearning #skilllearning #reinforcementlearning #alpineskiing #slalom #expertperformance #decisionmaking
1
1
1
389