
🚀 Digital Asset Opportunity: TransferLearning.io
Transfer Learning is one of the most important concepts powering modern AI—enabling models to apply knowledge from one task to another, reducing costs and accelerating innovation.
TransferLearning.io is a premium, brandable AI domain positioned at the intersection of machine learning, enterprise AI, education, and emerging technologies.
💰 Asking Price: $4,800
Ideal for:
• AI startups
• ML platforms
• AI education companies
• Research organizations
• Enterprise AI solutions
#TransferLearning #TransferLearningIO #AI #MachineLearning #ArtificialIntelligence #DomainNames #DigitalAssets #Startup #TechInvestment #AIDomains
18

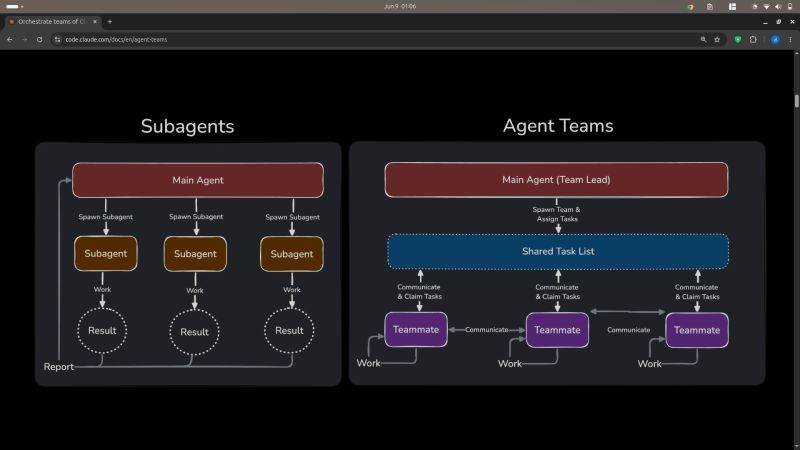
Recently Switched from a 18 months fullstack developer intern role to ml engineer intern role in the same company.
have a very friendly, passionate lead.
asked us to understand basics and explore how agents SDK work, then worked on transferlearning or training a small model.
1
12

🔈Introducing GID — A Large‑Scale Land‑Cover Dataset for High‑Resolution Remote Sensing!
🌍150 pixel‑level annotated Gaofen‑2 satellite images with wide geographic coverage across China.
📡Including both a large‑scale classification set and a fine land‑cover classification set with 30,000 multi‑scale patches.
🗂️15 land‑cover categories, fully labeled, designed for training and evaluating transferable deep models.
🔎Ideal for land‑cover mapping, cross‑sensor generalization, and domain adaptation — validated on GF‑1, Jilin‑1, ZY‑3, Sentinel‑2A, and Google Earth imagery.
📃Dataset: lnk.ink/GIDdata
#IEEEGRSS #RemoteSensing #LandCover #HighResolution #DeepLearning #Gaofen2 #TransferLearning #EarthObservation

1
5
49
1,717

🌍 Just completed a full End-to-End Image Classification project on Intel's Natural Scenes Dataset!
As a Data Scientist & ML Engineer, I built a complete pipeline that automatically identifies 6 types of natural scenes — Buildings, Forest, Glacier, Mountain, Sea & Street — from raw images.
📌 What I did:
✅ Exploratory Data Analysis (EDA) — class distributions, brightness/contrast stats, color histograms
✅ Data Augmentation — rotation, zoom, flip, brightness tuning to prevent overfitting
✅ Built & compared 4 Deep Learning models:
🔹 Simple CNN (Baseline)
🔹 Deep Custom CNN with BatchNorm Dropout
🔹 VGG16 Transfer Learning (freeze fine-tune)
🔹 MobileNetV2 Transfer Learning
✅ Grad-CAM visualizations — to explain WHAT the model actually sees
✅ Confusion Matrix, Classification Report & Per-Class Accuracy
✅ Final predictions exported as CSV with confidence scores
📊 Dataset: ~25,000 images | 6 classes | 150×150 px
🏆 Best Model Accuracy: 94%
💡 Key Takeaway:
Transfer Learning is a game-changer. MobileNetV2 & VGG16 significantly outperformed custom CNNs — and Grad-CAM made the model explainable to non-technical stakeholders.
🚀 If your business needs:
→ Image classification or object detection solutions
→ Computer Vision pipelines for automation
→ Explainable AI for stakeholder reporting
Let's connect and talk! 📩 DM me or drop a comment below.
#MachineLearning #DeepLearning #ComputerVision #CNN #TransferLearning #ImageClassification #VGG16 #MobileNetV2 #GradCAM #Python #TensorFlow #Keras #DataScience #AI #NeuralNetworks #Kaggle #OpenToWork #MLEngineer #DataScientist #AIFreelancer #ClientWork #Portfolio #BuildInPublic #ArtificialIntelligence #MLOps #ExplainableAI #LinkedInLearning #TechPakistan #PakistaniDeveloper #FreelancePakistan
1
28

May 22
Today I’m sharing a new scientific milestone:
“Congruity as a Candidate Structural Invariance Class: Interpretable Cross-Domain Symbolic Emergence, Falsification, and Transfer Evaluation”
Preprint: doi.org/10.5281/zenodo.20349…
Public reproducibility repository: github.com/andrearomeo74-clo…
This work does not claim a final universal equation.
Instead, it asks a narrower and more testable scientific question:
Do viable heterogeneous systems repeatedly exhibit interpretable proportional structural patterns under interacting burdens?
To explore this, the study evaluates reproducible benchmarks across multiple domains:
• breast cancer morphology classification
• external unseen diabetes clinical validation
• synthetic ecological collapse dynamics
• symbolic structural discovery
• permutation falsification
• proxy robustness analysis
• adaptive leave-one-domain-out transfer
• fixed-sign transfer stress testing
Core observations:
• interpretable proportional structures repeatedly emerge
• symbolic search converges toward multiplicative burden forms
• randomized falsification materially degrades performance
• transfer remains partially preserved across domains
• some assumptions fail under stress, which is scientifically informative
This is important because the goal is not to defend a theory at all costs.
The goal is to determine whether Congruity represents a genuine structural invariance family, or a domain-specific artifact.
Everything public here is intentionally reproducible.
Independent verification, critique, replication, and failure analysis are welcome.
Science progresses through exposure, not insulation.
#Science #ComplexSystems #AI #MachineLearning #SystemsBiology #InterpretableAI #SymbolicAI #Reproducibility #TransferLearning #SystemsScience #ComputationalScience #OpenScience

2
4
466

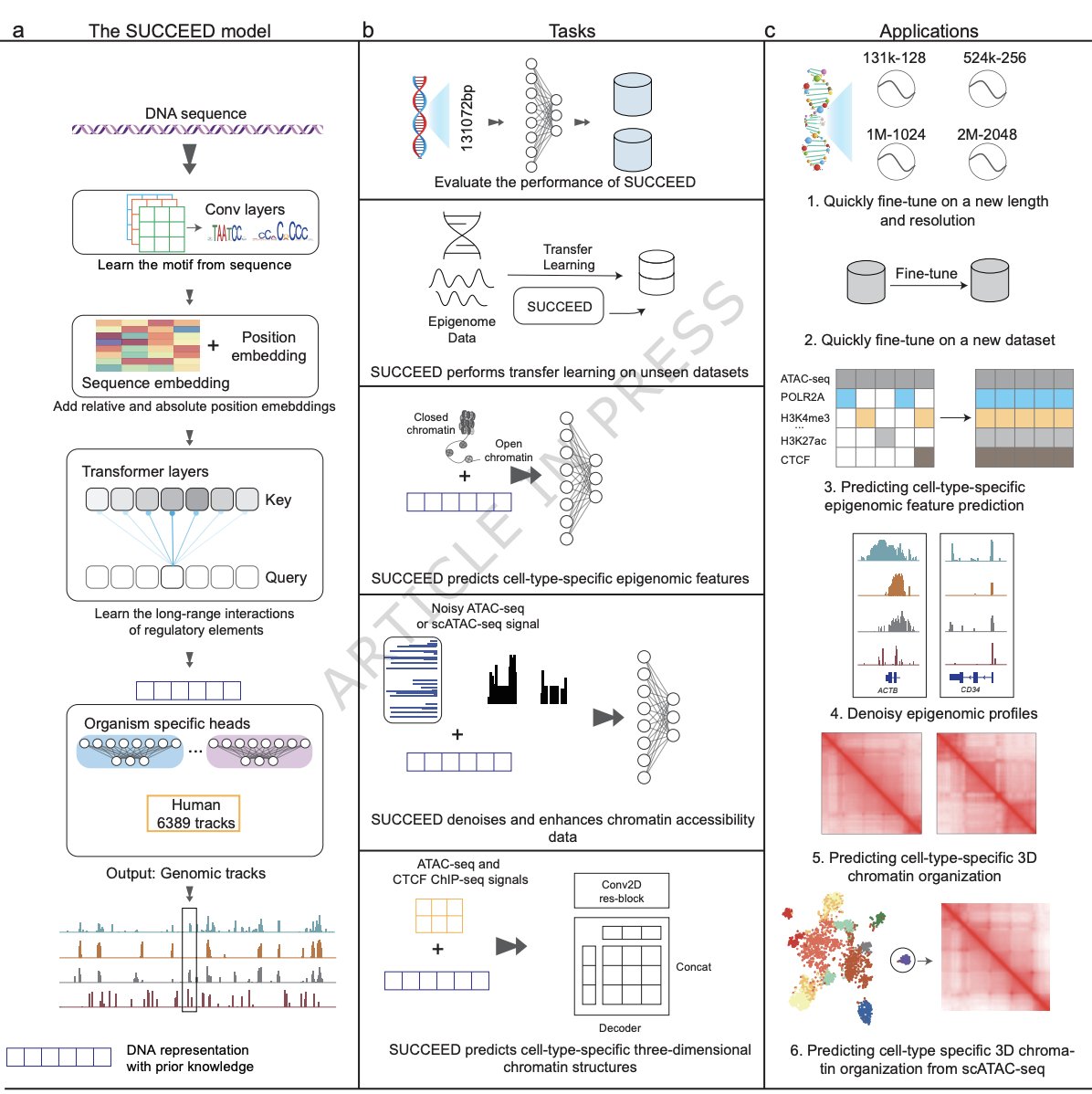
Large-scale data-driven pre-trained DNA models enhance performance across diverse genomics tasks
1. The paper introduces SUCCEED, a supervised multi-task DNA foundation model pretrained on 6,389 ENCODE functional genomics tracks, aiming to learn transferable regulatory representations that can be adapted across many downstream genomics tasks with minimal retraining.
2. SUCCEED’s core design is a lightweight hybrid CNN–Transformer: convolutional layers learn local motif features, while a Transformer encoder models long-range regulatory dependencies; several LLM-inspired upgrades are included (SwiGLU, RMSNorm, RoPE, and grouped-query attention) to improve stability and efficiency.
3. In a DNA-only benchmark against Enformer, SUCCEED achieves comparable or better performance despite reduced architectural complexity; for example, it improves CAGE prediction (PCC 0.76 vs 0.703), is similar on histone ChIP-seq, slightly below on TF ChIP-seq, and close on DNase/ATAC.
4. On standard short-sequence genomic benchmarks (promoter and splice-site tasks), fine-tuning the pretrained SUCCEED yields a higher mean accuracy than training from scratch (0.906 vs 0.891) and is competitive with (or better than) large self-supervised DNA language models on most tasks.
5. Interpretability analyses indicate SUCCEED learns biologically meaningful features: first-layer filters recover known TF motifs (via TOMTOM/JASPAR matching), and Input×Gradient attributions suggest predictions rely on both local motifs and distal sequence context.
6. The work emphasizes multi-scale transfer: models trained at 131 kb inputs can be fine-tuned to longer contexts (e.g., 524 kb, 1 Mb, 2 Mb) and different resolutions with strong performance; updating only the prediction head (or head Transformer) can outperform training from scratch while reducing compute and accelerating convergence.
7. For unseen cell types, SUCCEED is tested on scATAC-seq-derived pseudo-bulk profiles from 45 human brain cell types; fine-tuning is computationally cheaper and can match (or sometimes exceed) de novo training, suggesting the pretrained model captures broadly reusable regulatory “grammar”.
8. To predict cell-type-specific epigenomic profiles, SUCCEED is extended with an ATAC-seq encoder to inject cell-state information; in cross-chromosomal and cross-cell-type evaluations, it generally outperforms EPCOT, with especially strong gains for histone mark prediction and competitive TF-binding prediction.
9. SUCCEED is also used as a prior for denoising/enhancing chromatin accessibility: it outperforms AtacWorks on bulk and scATAC-seq, remains robust under extreme low coverage (e.g., 0.2M reads), and can reconstruct accessibility from very small cell counts (reported as single-cell input approaching conventional performance that typically needs far more cells).
10. For 3D genome modeling, SUCCEED improves training stability and can predict cell-type-specific Hi-C contact patterns; notably, it can reconstruct 3D architecture without requiring CTCF ChIP-seq input, and it remains effective when driven by sparse scATAC-seq (including small numbers of cells), supporting scalable 3D inference where Hi-C/CTCF data are unavailable.
📜Paper: doi.org/10.1038/s41467-026-7…
#ComputationalBiology #Genomics #DeepLearning #FoundationModels #ENCODE #Epigenomics #ATACseq #HiC #3DGenome #TransferLearning
11
37
3,275

May 15
📢 #highlycited paper
📚 Comparison of #ImagePreprocessing Strategies for #ConvolutionalNeuralNetwork-Based Growth Stage Classification of Butterhead Lettuce in Industrial Plant Factories
🔗 mdpi.com/2076-3417/15/11/627…
👨🔬 by Jung-Sun Gloria Kim et al.
🏫 Seoul National University
#transferlearning #deeplearning

1
2
40

A Transfer Learning-Based Pairwise Information Extraction Framework Using BERT and Korean-Language Modification Relationships
✏️ Hanjo Jeong
🔗 brnw.ch/21x2gik
Viewed: 1864; Cited: 5
#mdpisymmetry #transferlearning #informationextraction

3
2
29

Apr 16
Embedding robots with an internal understanding of their own joint limits, or #kinematic intelligence, can enable #TransferLearning across various robot types after a single demonstration.
Learn more in Science #Robotics: scim.ag/4mslTXu
7
58
4,425

Mar 31
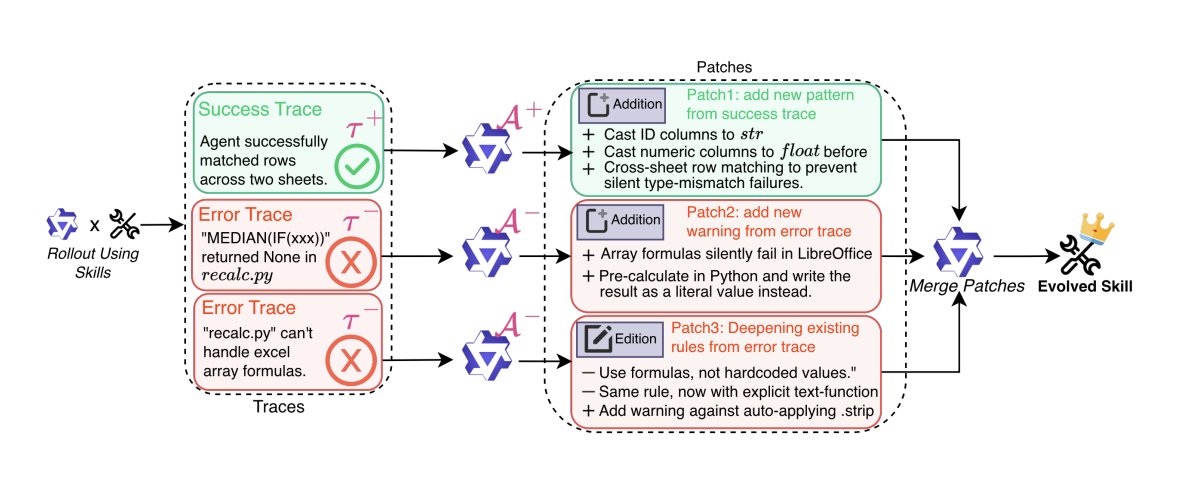
Every time you train an AI agent for a new task, you start from scratch. Trace2Skill from Alibaba changes this by extracting reusable skills from agent execution traces and transferring them across tasks.
The framework dispatches parallel sub-agents to analyze diverse execution trajectories. It extracts trajectory-specific lessons and hierarchically consolidates them into a unified skill directory. Skills generated automatically from trajectories outperform skills written by human experts on VisionQA and math reasoning.
Think of it like a new employee who extracts transferable skills across jobs rather than learning each one from zero. Time management from job 1, debugging from job 2 — those compose into competence at job 3 they've never seen.
Should AI agents write their own training curriculum?
Save this. Follow @drawais_ai for daily AI paper breakdowns — I read it first, try it, then explain it simply.
#Trace2Skill #AIAgents #TransferLearning #Alibaba #Qwen #SkillLearning #ReinforcementLearning #LLM #MachineLearning #AgenticAI #DeepLearning
1
2
45
Mar 26
📢 #highlycited paper
📚 Physics-Informed #NeuralNetworks for High-Frequency and Multi-Scale Problems Using #TransferLearning
🔗 mdpi.com/2076-3417/14/8/3204
👨🔬 by Abdul Hannan Mustajab et al.
🏫 Kiel University/University of Genoa/University of Waterloo
#PINN #dampedharmonicoscillator
2
3
46

Mar 22
Transfer Learning in Public Health: How Pre-Trained AI Models Accelerate... youtu.be/OKM4mFB4SLo?si=WQ6n… via @YouTube
🎧Listen to the audio version here: podcasts.apple.com/us/podcas…
#transferlearning #AI #publichealth #machinelearning #deeplearning #neuralnetworks #datascience
2
19

Mar 18
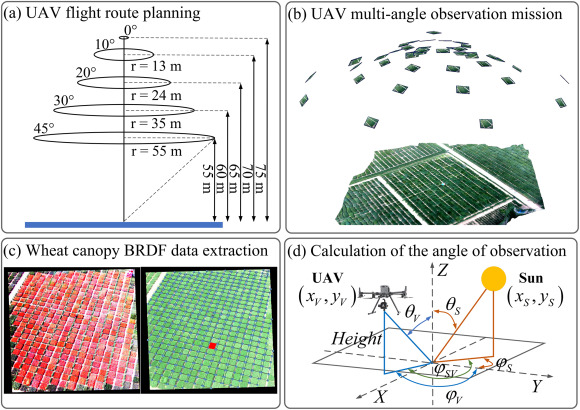
Multi-angular UAV boosts wheat canopy retrieval: LAI R² 0.59 vs 0.38 nadir-only. Kernel-driven BRDF CNN transfer learning capture anisotropy for precision breeding. #TransferLearning #CropModeling
Details: doi.org/10.1016/j.plaphe.202…
1
4
167
🌟 Article of the Week 🌟
This week’s featured article from IEEE Transactions on Geoscience and Remote Sensing (TGRS) presents a practical and impactful advance in Domain Adaptation for remote sensing image scene classification.
🔍 This Week’s Highlight
Title: Universal Domain Adaptation for Remote Sensing Image Scene Classification
Authors: Qingsong Xu, Yilei Shi, Xin Yuan, Xiao Xiang Zhu
📖 🌍 Real-world remote sensing often involves unknown classes and unavailable source data. This paper proposes a Universal Domain Adaptation (UniDA) framework for scene classification that requires no prior label-set alignment and works even without source data, offering a practical solution for open-world remote sensing scenarios.
🔗 Read the full paper here: doi.org/10.1109/TGRS.2023.32…
Stay tuned for more groundbreaking research every week as we celebrate excellence in geoscience and remote sensing! 🌍📡
#IEEEGRSS #RemoteSensing #Geoscience #ieeexplore #DomainAdaptation #TransferLearning #AOTW

1
1
4
346

#ForestryRes #grns #transferlearning #plants
Hybrid CNNs ML map plant GRNs, 95% accurate. Transfer learning bridges species gaps.
@MaximumAcademic @TrendsPlantSci @michigantech
Details: maxapress.com/article/doi/10…
2
3
143
Transfer Learning as a Service lets you fine-tune state-of-the-art models on your own data — faster, cheaper, and smarter. TRANSFERLEARNING.io can be a TLD domain offering:
🔹 Faster model deployment
🔹 Lower compute costs
🔹 Domain-specific intelligence
🔹 Enterprise-ready APIs
🌐 TRANSFERLEARNING.io
#TransferLearning #AI #MachineLearning #DeepLearning #MLOps #ArtificialIntelligence #SaaS #AIStartup #DataScience #TechInnovation
1
9
110

📣 Deal of the Day 📣 Feb 20
HALF OFF new liveProject series!
Vision Models for Classification and YOLO Segmentation & selected titles: hubs.la/Q0440C840
For aspiring #machinelearning engineers, #AI-curious developers, and students looking to dive deep into #deeplearning through a fun, real-world project.
Help wildlife organizations automatically identify and monitor elephants in images! In this liveProject series, you’ll build a custom CNN to classify Asian vs. African elephants, boost accuracy with transfer learning using #Xception and #MobileNet, and implement #YOLOv8 #segmentation for precise detection and localization.
#ImageClassification #TransferLearning #ObjectDetection #NeuralNetworks

1
1
4
440
How Well Do Large-Scale Chemical Language Models Transfer to Downstream Tasks?
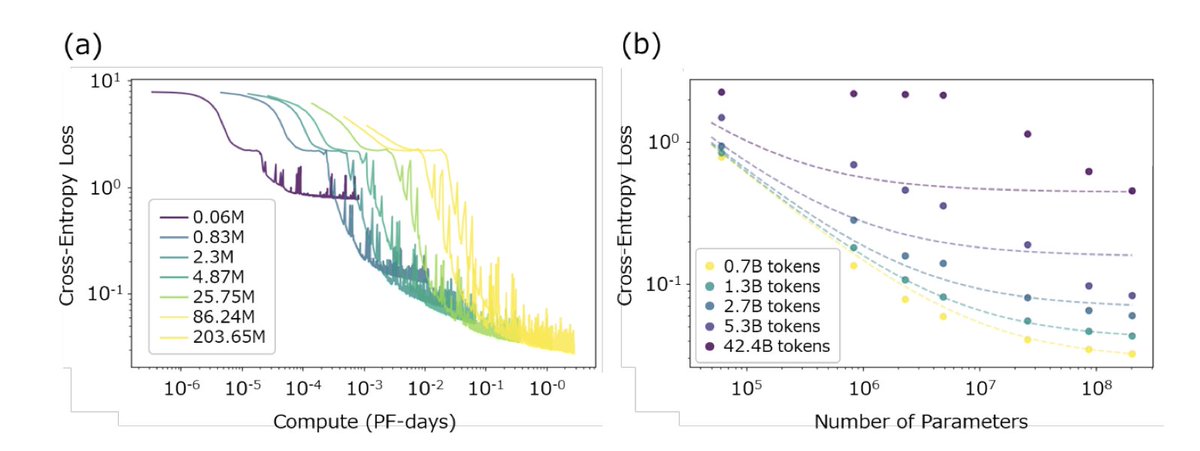
1. A new study challenges the assumption that bigger is always better for chemical language models (CLMs), revealing that scaling model size, data, and compute consistently reduces pre-training loss—but this doesn't reliably translate to better downstream task performance.
2. The researchers systematically evaluated 36 molecular property prediction tasks across three scaling dimensions: model size (0.06M to 203M parameters), data size (0.7B to 42.4B tokens), and training compute, finding that downstream performance often saturates or even degrades while pre-training loss keeps improving.
3. In compute scaling experiments, downstream performance frequently peaked before completing a single epoch, suggesting that common practices like multi-epoch pre-training and early stopping based on pre-training loss may be suboptimal for transfer learning.
4. Alternative metrics based on Hessian trace and Principal Gradient-based Measurement (PGM) distance also failed to reliably predict downstream performance, indicating that no single pre-training metric adequately captures transferability across diverse chemical tasks.
5. Parameter space visualizations revealed that fine-tuning updates remain largely local to initialization checkpoints, with substantial task-dependent variation—explaining why global metrics struggle to predict downstream outcomes and highlighting the need for task-aware evaluation strategies.
📜Paper: arxiv.org/abs/2602.11618
#ChemicalLanguageModels #MolecularPropertyPrediction #ScalingLaws #TransferLearning #ComputationalChemistry #DeepLearning #Cheminformatics #FoundationModels #NegativeTransfer #AIforScience
4
10
1,447
Transfer Learning TransferLearning.io allows you to utilize knowledge already learned with a machine-learning technique where better performance in tasks is achieved with much less data and compute- brought to you by PITN.ai 👁️ . #MachineLearning #transferlearning #datascience #edgecomputing #Compute #Fintech #fintechcommunity #fintechsolutions #DeepLearning #AIEthics #DigitalMarketing #Domain #io #input #output #startupcollaboration
1
8
132
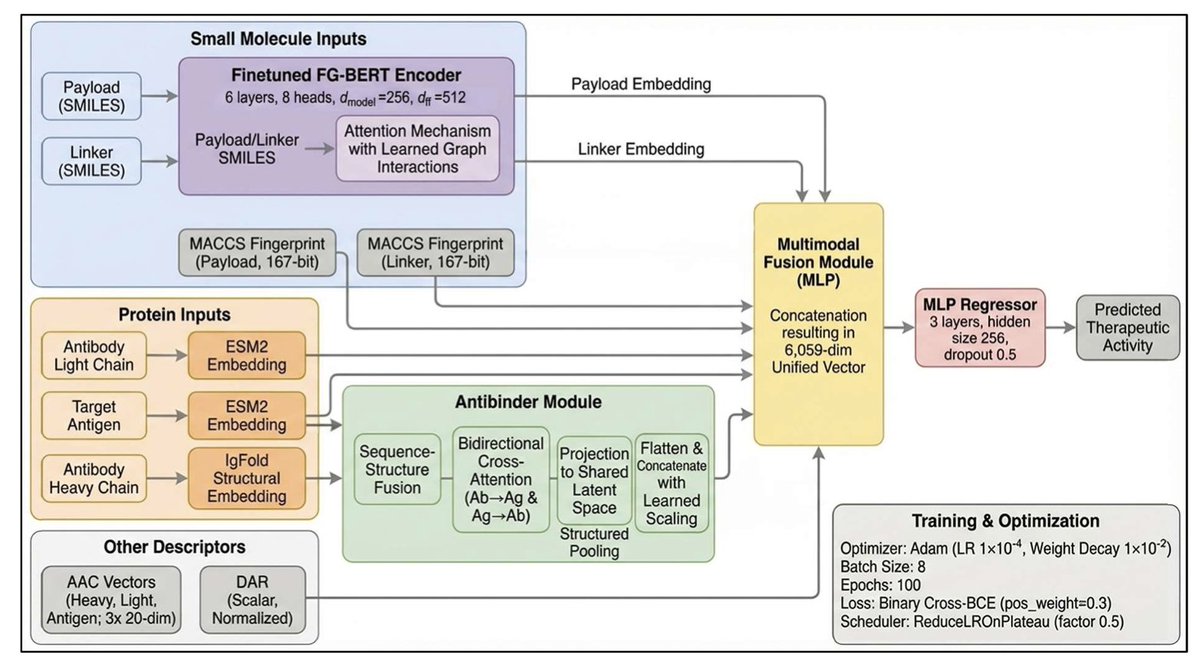
ABFormer: A Transformer-based Model to Enhance Antibody-Drug Conjugates Activity Prediction through Contextualized Antibody-Antigen Embedding
1 ABFormer achieves 100% accuracy on an independent benchmark of 22 novel ADCs, while baseline models including ADCNet severely miscalibrate and fail to distinguish negative controls, demonstrating genuine out-of-distribution generalization capability.
2 The core innovation lies in replacing naive feature concatenation with contextualized antibody-antigen embeddings through transfer learning from AntiBinder, a pretrained bidirectional attention network that captures high-resolution binding interface information.
3 Unlike prior approaches that treat antibody, antigen, linker, and payload as independent features, ABFormer explicitly models the antibody-antigen interaction context which is primarily responsible for ADC targeting and uptake.
4 The model employs a selective fine-tuning strategy where AntiBinder, ESM-2, and IgFold remain frozen as feature extractors, while FG-BERT for chemical encoding and the MLP prediction head are trained, balancing transfer learning with task-specific adaptation.
5 Ablation studies confirm that antibody-antigen interaction embeddings are the primary driver of predictive success (MCC drops from 0.70 to 0.22 when removed), while fine-tuned chemical encoders are critical for maintaining specificity and reducing false positives.
6 Latent space analysis reveals that AntiBinder embeddings trained solely on MET data generalize to 62 diverse cancer antigens with strong cluster separation (Silhouette = 0.685), indicating transferable binding recognition patterns across receptor tyrosine kinase families.
7 The leave-pair-out validation strategy ensures rigorous assessment by preventing any antibody-antigen pair from appearing in both training and test sets, simulating true cold-start discovery scenarios for novel therapeutic targets.
8 Despite limited training data (340 ADCs), ABFormer successfully transfers knowledge from single-antigen pretraining to diverse targets, highlighting the effectiveness of interaction-centric transfer learning in low-data biomedical settings.
💻Code: github.com/drugparadigm/ABFo…
📜Paper: biorxiv.org/content/10.64898…
#ABFormer #AntibodyDrugConjugates #ADC #DeepLearning #Transformer #ComputationalBiology #DrugDiscovery #MachineLearning #Bioinformatics #TransferLearning
5
13
1,283