
🗞 Two Hugging Face engineering posts by Lester Leong show a game-like multi-agent economy that mixes five small language models. The demos highlight feasibility and creativ…
🔗 atlas360.news/en/news/huggin…
📩 Subscribe: atlas360.news/en/bulten
#inferencecosts #multiagent #smallmodels
1
6

The Build Small Hackathon @huggingface @Gradio diary — Day 6 🌱
Today, I want to take you inside the community :
👥2,000 followers,
🔧1,800 members,
🤗already 400 Spaces.
Every Space is different, but very concrete and personal. @Gradio is becoming something closer to daily life.
And the Discord is active every day. People ask questions, share ideas, help each other choose models, and give feedback.
@yvrjsharma @abidlabs
#BuildSmallHackathon #HuggingFace #Gradio #SmallModels
3
7
9
1,544

Jun 4
This is my average cost, not for an AI request.
deepseek.com v4 pro and v4 flash (for auto context) (Rust @rustlang coding)
With Opus, GPT, or Flash, would have been ~0.40, 2m (2x faster, but 20x price).
Price/Limit no more
#BigApps #SmallModels
3
5
259

Built for Developers
🔹 Deployment: In INT4 quantization, the model weight is just ~0.5GB. It runs natively on phones, tablets, and even directly inside a web browser with zero configuration.
🔹 Fine-Tuning Support: LLaMA-Factory, ms_swift.
🔹Inference Frameworks: Out-of-the-box compatibility with SGLang, vLLM, llama.cpp, Ollama, Hugging Face, and ArcLight
#MiniCPM #EdgeAI #OnDeviceAI #OpenSourceAI #LLM #SmallModels #AI #LocalLLM #GenerativeAI #OpenBMB
1
1
15
1,947

Apr 16
Models are getting smaller, faster, and more efficient, but this paper, MzansiText and MzansiLM, shows they’re also getting smarter about how they use what little resources they have.
Instead of relying on massive datasets or heavy compute, the work explores how compact models can be optimized to perform competitively through better training strategies, smarter data usage, and architectural efficiency.
What this signal is clear: the future of AI isn’t just about scaling up, it’s about doing more with less and this matters deeply for regions like Africa, because in many real-world environments, we are dealing with limited compute, constrained infrastructure, and scarce labeled data. Large models alone won’t solve that.
This is exactly where our focus sits at @equalyz_ai , we are building for frugal, voice-first AI systems that can run in low-resource settings, powered by high-quality, locally sourced language data.
True inclusion in AI won’t come from the biggest models; it will come from the most adaptable ones, models that are efficient enough to work anywhere, and grounded enough to understand everyone.
@anri_m_lombard @UCTAlumniZim @AIforGood
@FMCIDENigeria @AIMonacoLab @AfricaAI_ @TEMIAINA_ @janmbuys
#EqualyzAI #FrugalAI #SmallModels #LanguageAI #AIResearch #AfricanLanguages

34
167


Apr 6
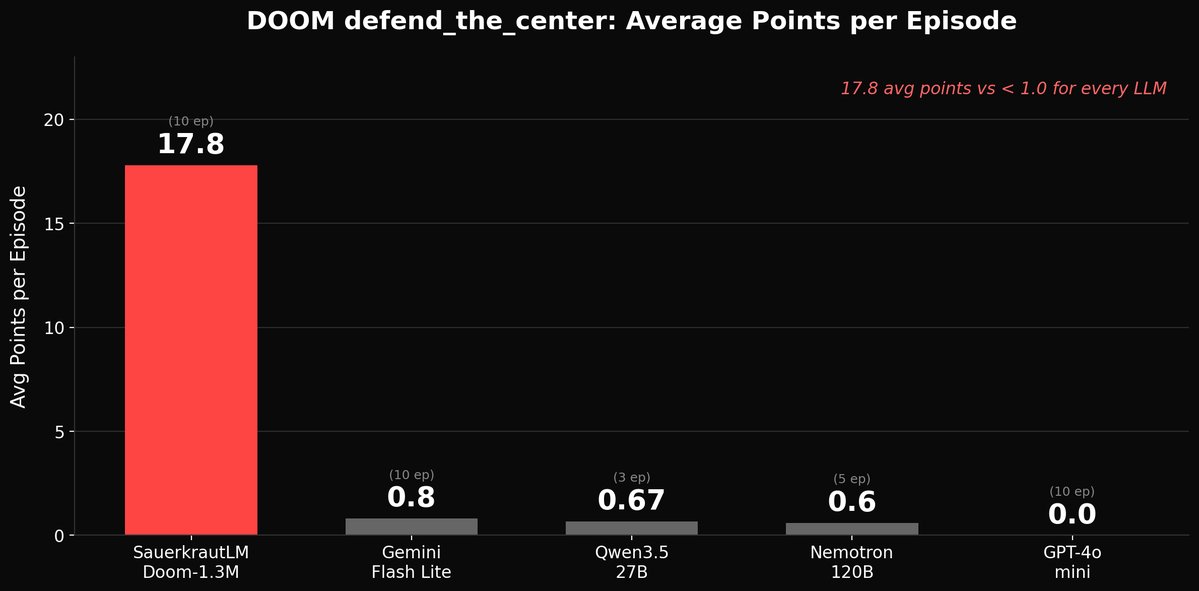
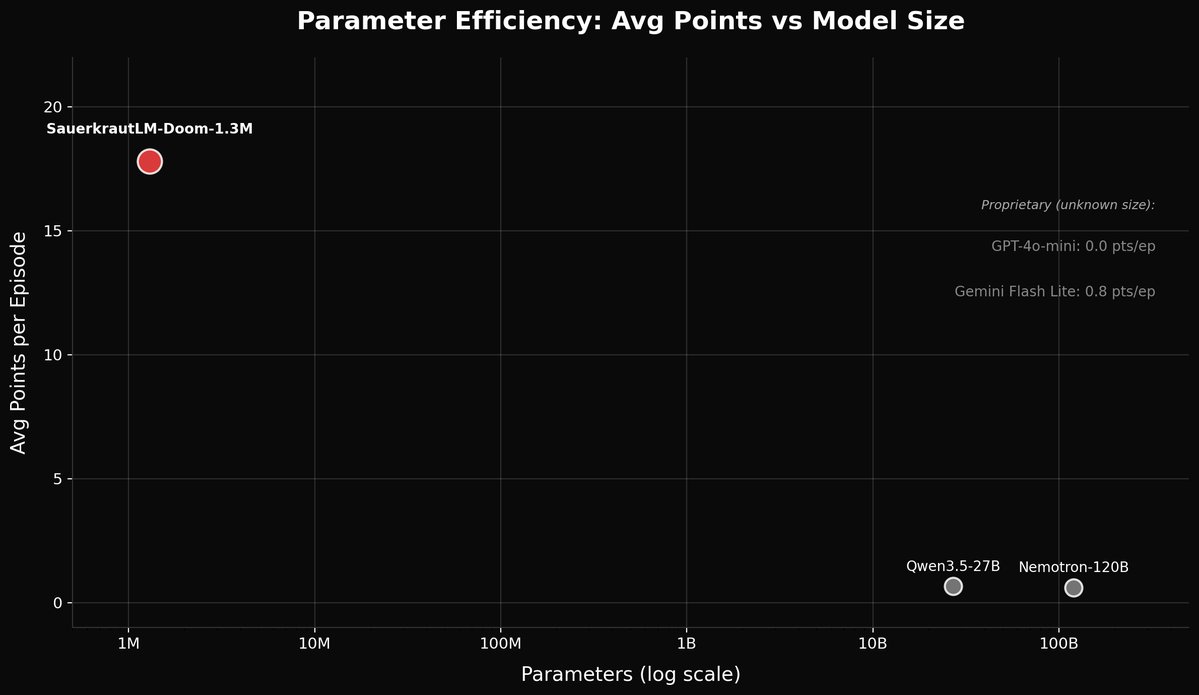
We taught a 1.3M parameter model to play DOOM. It outperforms LLMs up to 92,000x its size.
Happy Easter Monday! Here's our Easter egg release: SauerkrautLM-Doom-MultiVec-1.3M.
17.8 average points per episode.
We benchmarked our tiny model against GPT-4o-mini (via OpenAI API), Nemotron-120B, Qwen3.5-27B, and Gemini Flash Lite (via OpenRouter API) on VizDoom's defend_the_center:
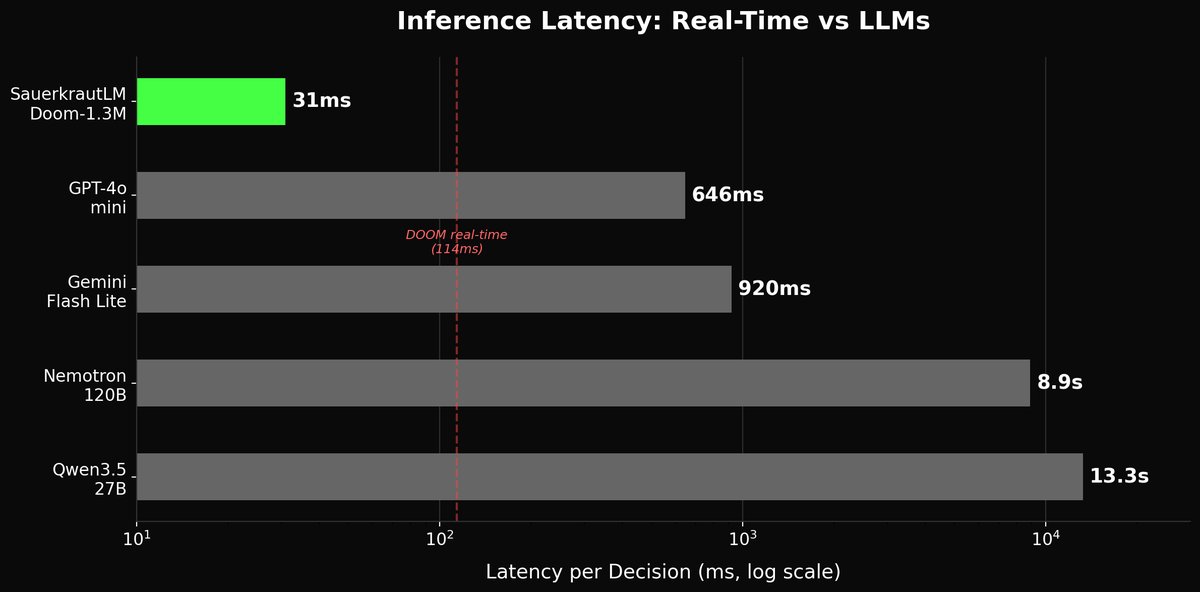
- Our model: 17.8 avg points/episode, 31ms per decision, runs on CPU
- Gemini Flash Lite: 0.8 avg points/episode (920ms latency)
- Qwen3.5-27B: 0.67 avg points/episode (13.3s latency)
- Nemotron-120B: 0.6 avg points/episode (8.9s latency)
- GPT-4o-mini: 0.0 avg points/episode (just dodges, never engages)
The architecture: ModernBERT-Hash
We took hash embeddings (Svenstrup et al. 2017), previously only applied to the original BERT architecture (see @neumll 's BERT-Hash models), and brought them to ModernBERT, adding rotary position embeddings, alternating local/global attention, Flash Attention 2 support, and learned depth embeddings from VizDoom's depth buffer.
The result is a 5-layer encoder with a 75-token character-level tokenizer (no BPE, every ASCII character is one token, preserving spatial structure), attention pooling, and a 4-action classification head. Total: 1,319,300 parameters, ~5MB on disk, 31ms inference on CPU.
Trained on 31K frames of a human playing DOOM for about 2 hours. That's it.
Fully open source. Everything you need to reproduce this:
Model weights: huggingface.co/VAGOsolutions…
Training data (31K frames): huggingface.co/datasets/VAGO…
Code, training scripts, benchmark framework: github.com/VAGOsolutions/Sau…
Full paper with methodology included in the repo.
Why does this matter beyond the fun factor?
Small specialized models can decisively beat general-purpose LLMs at real-time control tasks. Not by a small margin, by 22x on average points per episode. At 1/400th the latency. On a CPU. For free.
This has real implications for robotics, autonomous systems, game AI, and any domain where you need sub-100ms decisions on edge hardware. The future of AI isn't exclusively large. It's appropriately sized.
Thank you to my co-authors Daryoush Vaziri (University of Applied Sciences Bonn-Rhein-Sieg) and Alexander Marquardt (Nara Institute of Science and Technology, CARE Laboratory) for their contributions to this work.
Built with VizDoom, PyTorch, HuggingFace Transformers, and the ModernBERT architecture by @benjamin_warner , @antoine_chaffin, @ClavierBenjamin et al. Hash embedding approach inspired by NeuML's BERT-Hash models.
#AI #DOOM #GameAI #SmallModels #OpenSource #ModernBERT #SauerkrautLM #VAGOSolutions #Easter #TinyML
9
30
218
41,412

Mar 4
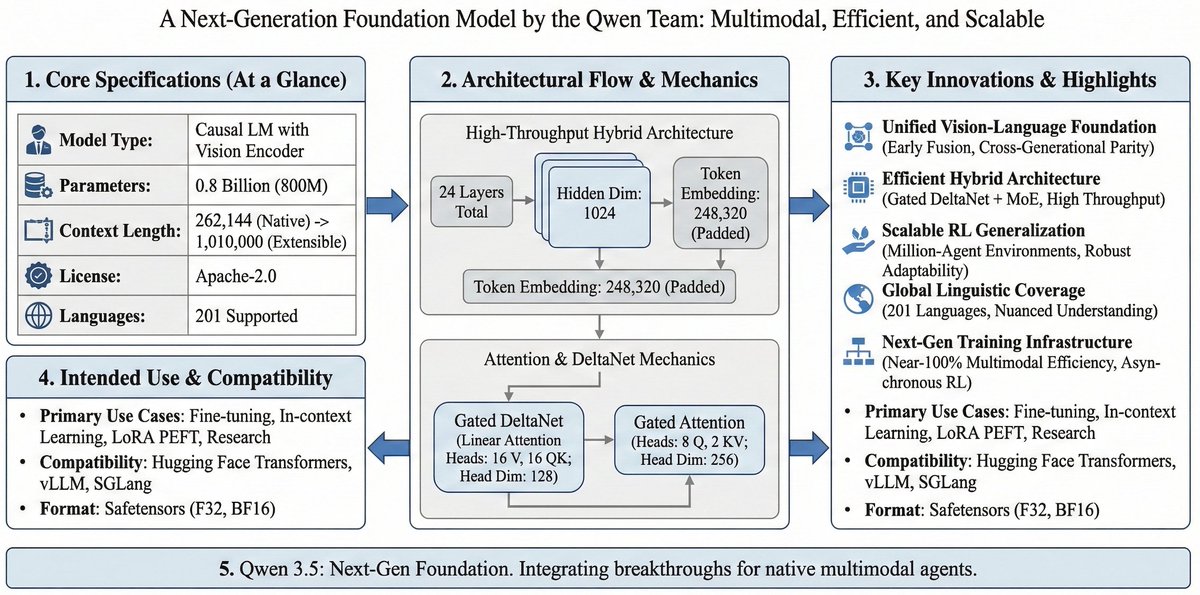
🤖🧩 Qwen3.5-0.8B-Base: 𝟬.𝟴𝘽 𝙝𝙮𝙗𝙧𝙞𝙙 𝘿𝙚𝙡𝙩𝙖𝙉𝙚𝙩 𝟮𝟲𝟮𝙆 𝙣𝙖𝙩𝙞𝙫𝙚 𝙘𝙤𝙣𝙩𝙚𝙭𝙩 🧩🤖
#open_source_llms
#did_you_know_that you can get 262K native context in a 0.8B base model (made for fine-tuning), built on Qwen’s throughput-first hybrid DeltaNet recipe—so edge devices can still “read long” without a giant decoder?
🧩 𝙒𝙝𝙖𝙩’𝙨 𝙣𝙚𝙬
(1) Base (pretrained) checkpoint: this is the “Base” model (for SFT/LoRA/continued pretraining), not an instruction/chat model.
(2) Long-context baked in: 262,144 native context, with official guidance for extending to ~1,010,000 via scaling strategies.
(3) Global language coverage: trained for 201 languages/dialects (shared with the Qwen3.5 family).
🧠 𝙐𝙣𝙙𝙚𝙧 𝙩𝙝𝙚 𝙝𝙤𝙤𝙙
(1) Hybrid long-sequence backbone: Gated DeltaNet Gated Attention to keep long-context throughput practical at small sizes.
(2) Multi-step MTP: multi-token prediction is part of the family’s efficiency recipe (fewer sequential decoding steps).
🛠 𝙁𝙤𝙧 𝙗𝙪𝙞𝙡𝙙𝙚𝙧𝙨
(1) Use cases: compact long-context adapters (LoRA) for classification, retrieval-augmented summarization, and “read-long → answer-short” workloads.
(2) Compatibility: model card lists supported runtimes including Transformers, and the family commonly targets vLLM/SGLang serving stacks.
Model on Hugging Face
huggingface.co/Qwen/Qwen3.5-…
Stay tuned and subscribe:
linkedin.com/newsletters/ope…
#opensource #qwen #qwen35 #smallmodels #longcontext #deltanet #nlp #favikon #cloud #cloudcomputing #genai #artificialintelligence
2
55

17 Oct 2025
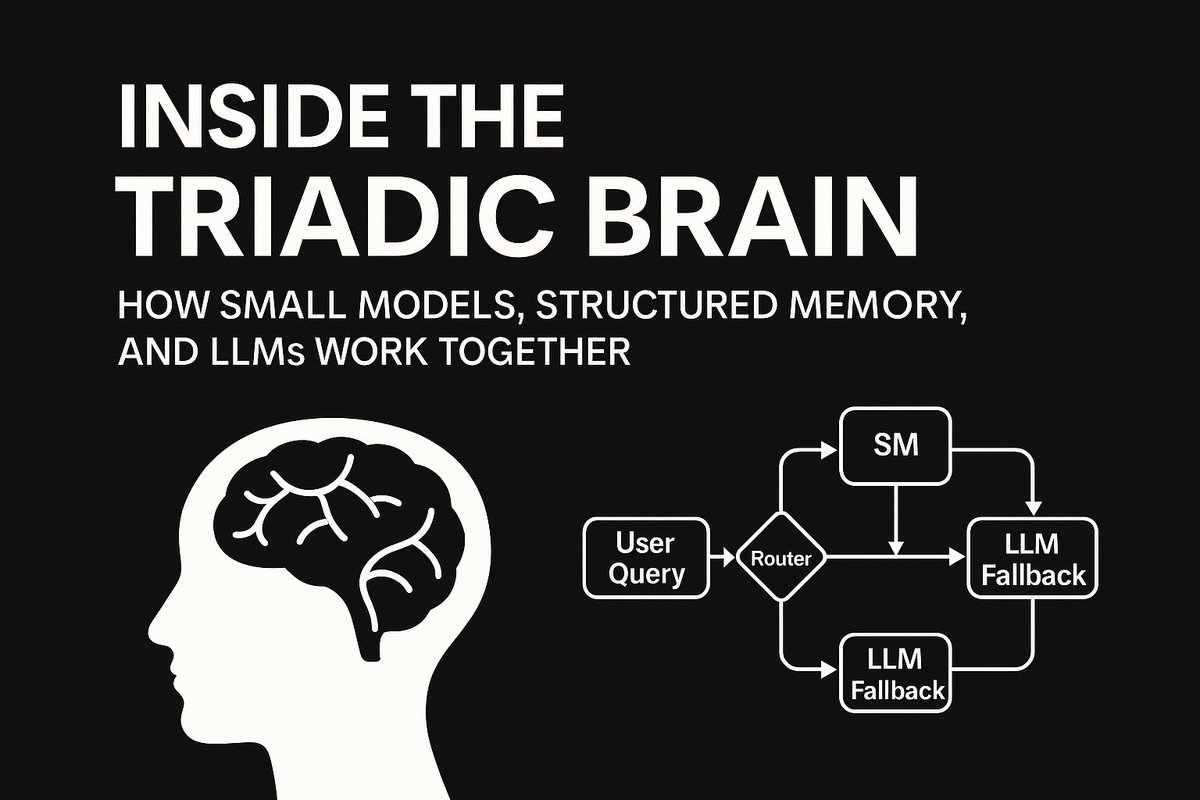
🧠 The brain doesn’t run one giant model — why should AI?
Krako’s Triadic Architecture fuses Small Models, Structured Memory, and LLMs into a brain-inspired system that’s smaller, faster, and greener.
⚡️ 60 % less energy
⚙️ Edge-ready
🌍 Decentralized by design
Read the full breakdown → bit.ly/47aT7DB
#AI #LLM #EdgeComputing #DecentralizedAI #SustainableTech #AIarchitecture #SmallModels #EdgeAI #DeepTech #DePIN #web3 #ComputeEconomy #Krako2 $KRAKO
1
5
12
463

2 Aug 2025
⚙️ Not quite live. Not quite secret.
This is your first look at The Seed Company's synthetic data engine in motion.
One platform. Endless possibilities.
Coming soon…🌱
#SeedTheFuture #Alpreview
#AI #syntheticdata #MachineLearning
#SmallModels #LLM #GPT4 #AlModels #DeepLearning #syntheticdatageneration
#FutureOfAl #ArtificialIntelligence
2
7
405

14 Jul 2025
Exclusive Interview with Siri Creator Luc Julia: Big AI Is Dangerous & Unsustainable.
The mind behind Siri says GenAI is overhyped, environmentally harmful, and heading in the wrong direction..
Read the full story by @BrijPahwa :
exchange4media.com/internati…
#e4m #SiriCreator #LucJulia #AIArmsRace #BigTechAI #AgenticAI #SmallModels #FutureOfAI

1
2
220

21 May 2025
Small Models, Big Future: Ghita’s contrarian take on specialized tiny models.
You don’t need a bulldozer for every task. @ghita__ha makes the case for small, fine-tuned models that outperform giants on speed, cost, and specificity — and why this contrarian bet might define the next wave of AI.
#ML #EdgeAI #StartupInsight #AI #LLM #SmallModels #EdgeAI #AIInfra #DeepTech #ContrarianThinking #YCFounders #ZeroEntropy #LobsterTalks
1
2
111

23 Jan 2025
Why Smaller AI Models Could Change Everything
#AIRevolution #SmallModels #TechInnovation #Meta #Zuckerberg #ArtificialIntelligence #BusinessSolutions #CostEfficiency #MachineLearning #FutureOfAI
2
3
69

9 Jan 2025
Tech-Rex Vs. ATTAP (ALL THINGS TO ALL PEOPLE)
Small is the next big thing.
From MIT technology Review
technologyreview.com/2025/01…
follow the warm blooded mammal at: attap.ai
#AI #LLM #Superintelligence #Machinelearning #smallmodels #TechRex #allthingstoallpeople

1
97

21 Nov 2024
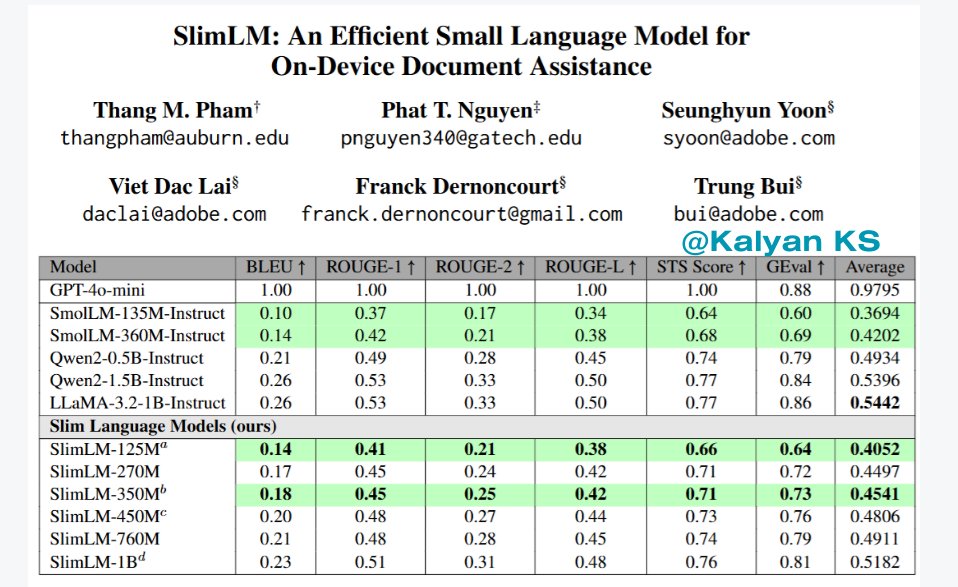
SlimLM - Efficient SLM for On-Device Document Assistance
This paper introduces SlimLM, a series of SLMs optimized for document assistance tasks on mobile devices.
SlimLM is pre-trained on SlimPajama-627B and fine-tuned on DocAssist, a dataset for summarization, question answering and suggestion tasks.
SlimLM demonstrates comparable or superior performance and offering a benchmark for future research in on-device language models.
Paper - arxiv.org/abs/2411.09944
#llms #smallmodels #nlproc #slms #generativeai
1
7
297
26 Sep 2024
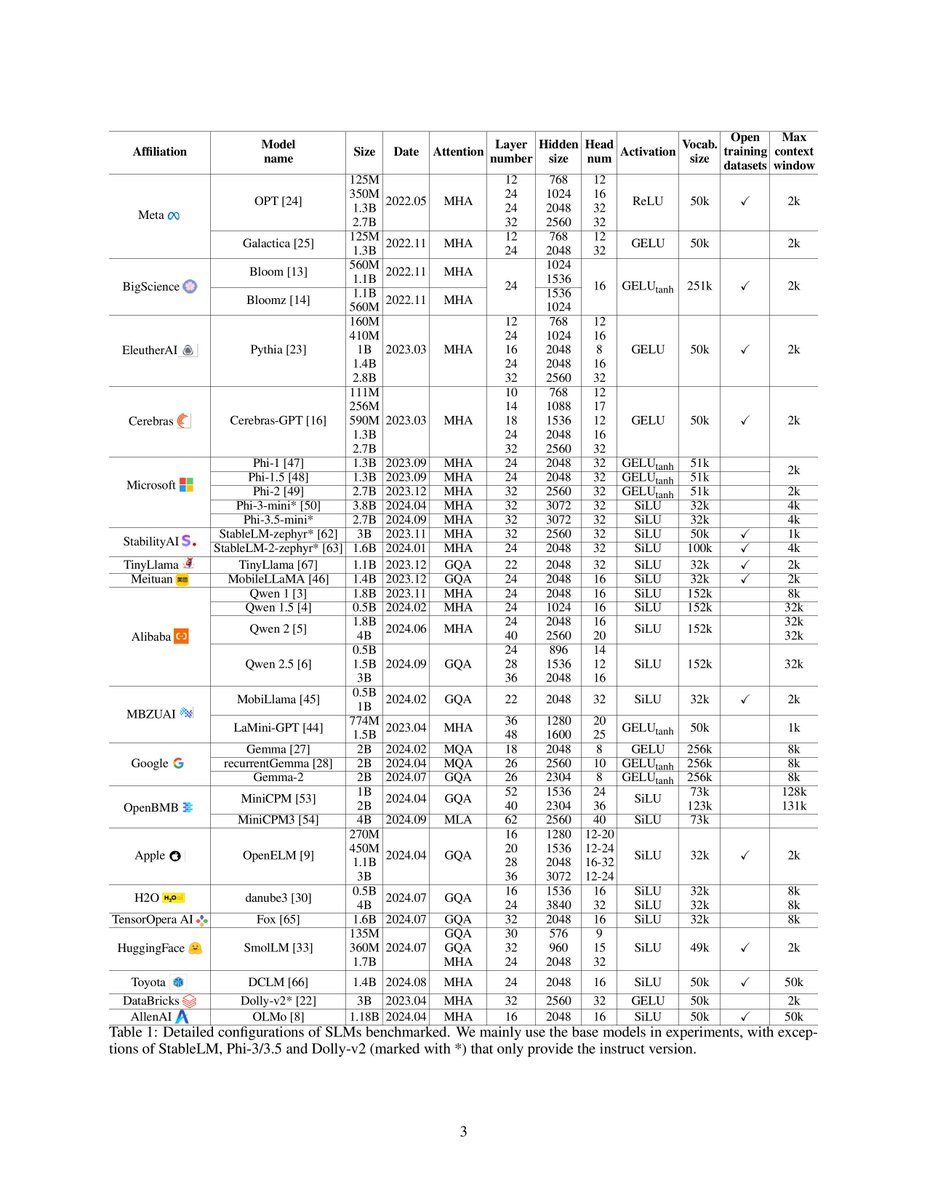
Small Language Models (Survey)
This paper provides a comprehensive survey of small language models (SLMs) discussing their capabilities, runtime costs, and innovations in recent years.
By analyzing 59 state-of-the-art open-source SLMs across three axes: architectures, training datasets, and training algorithms, the paper presents valuable insights and potential future research directions.
#llms #smallmodels #nlproc #deeplearning
1
1
155
13 Sep 2024
Role of Small Models in the LLM Era
Scaling up model sizes results in exponentially higher computational costs and energy consumption, making these models impractical for academic researchers and businesses with limited resources.
This paper presents a comprehensive survey of role of small models in the LLM era in two perspectives : Collaboration and Competition.
This survey provides valuable insights for LLM practitioners.
#smallmodels #llms #survey #research

1
4
111

20 Aug 2024
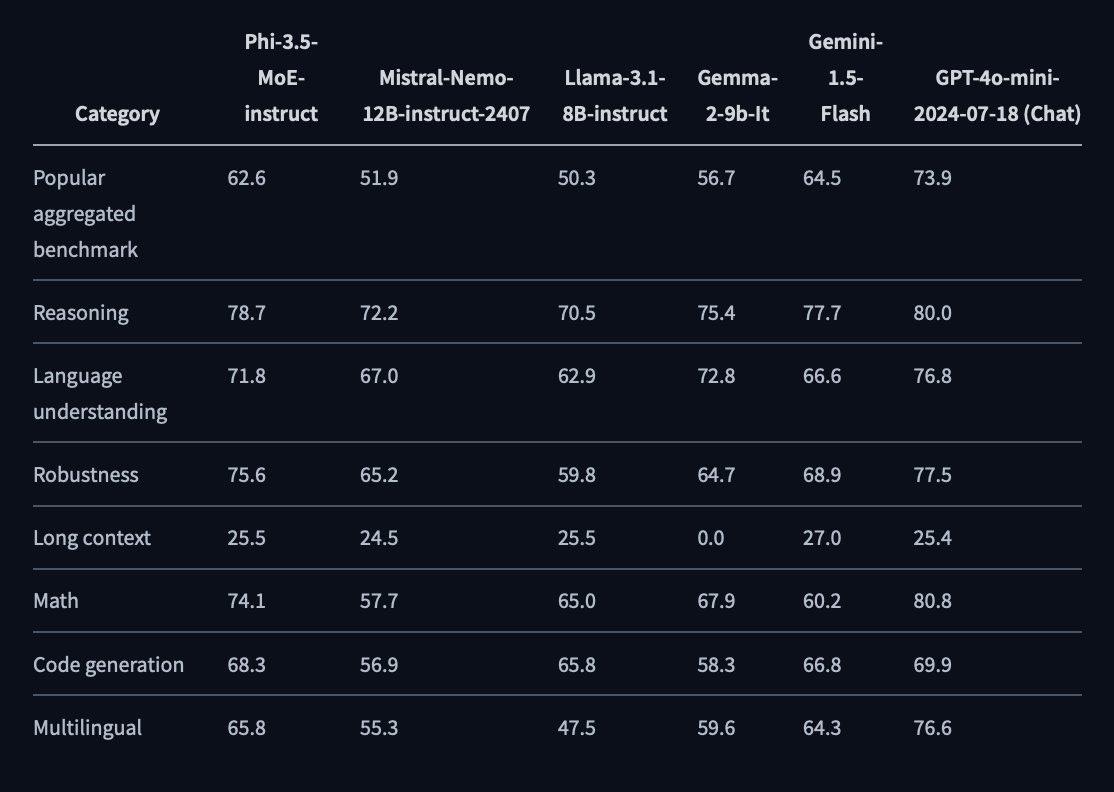
Microsoft’s new Phi-3.5-3.8B (Mini) beats LLaMA-3.1-8B, trained only on 3.4T tokens
Phi-3.5-16x3.8B (MoE) beats Gemini-Flash, trained only on 4.9T tokens
Phi-3.5-V-4.2B (Vision) beats GPT-4o, trained on 500B tokens.
AI efficiency game is 🔥 🚀 #SmallModels @Microsoft
2
1,161

12 Aug 2024
🚀 OpenAI has released a lightweight model for developers—GPT-4o Mini. It is significantly cheaper than the full version and considered more powerful than GPT-3.5. 💡 Due to the high costs of using OpenAI's full models, many developers have turned to cheaper options. Now, OpenAI has entered the lightweight model market, meeting the needs of more developers. 📉 Currently, the Dreamworlds platform offers 20 AI applications, which can be unlocked via DMD purchase or a limited-time free subscription to Dreamworlds Pass. 🚀🔓
#AI #ArtificialIntelligence #GPT4oMini #OpenAI #SmallModels #TechInnovation #MachineLearning #Dreamworlds

19
3
9
6,137
7 Aug 2024
🌟 With global praise for the new GPT-4o-mini, Apple has joined the small model development trend. Recently, Apple's research team released a set of open-source DCLM models on the Hugging Face platform.
📊Dreamworlds is continuously monitoring the development of small models. Currently, the Dreamworlds platform offers 20 AI applications, which can be unlocked through DMD purchase or via a limited-time free subscription to Dreamworlds Pass. 🚀🔓
#AI #ArtificialIntelligence #GPT4oMini #Apple #DCLM #SmallModels #TechInnovation #MachineLearning #Dreamworlds

10
1
26
10,107