
Joined September 2011
- Tweets 654
- Following 502
- Followers 2,405
- Likes 123
50 Photos and videos





Pinned Tweet

19 Dec 2024
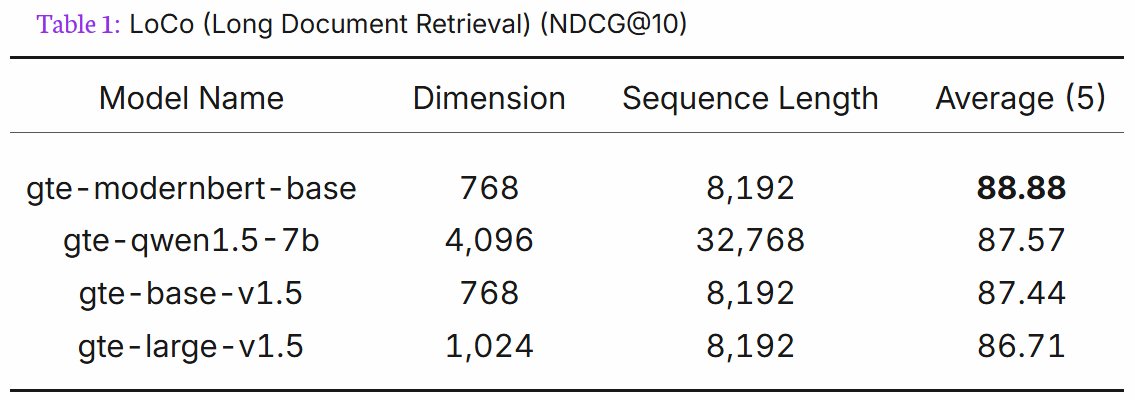
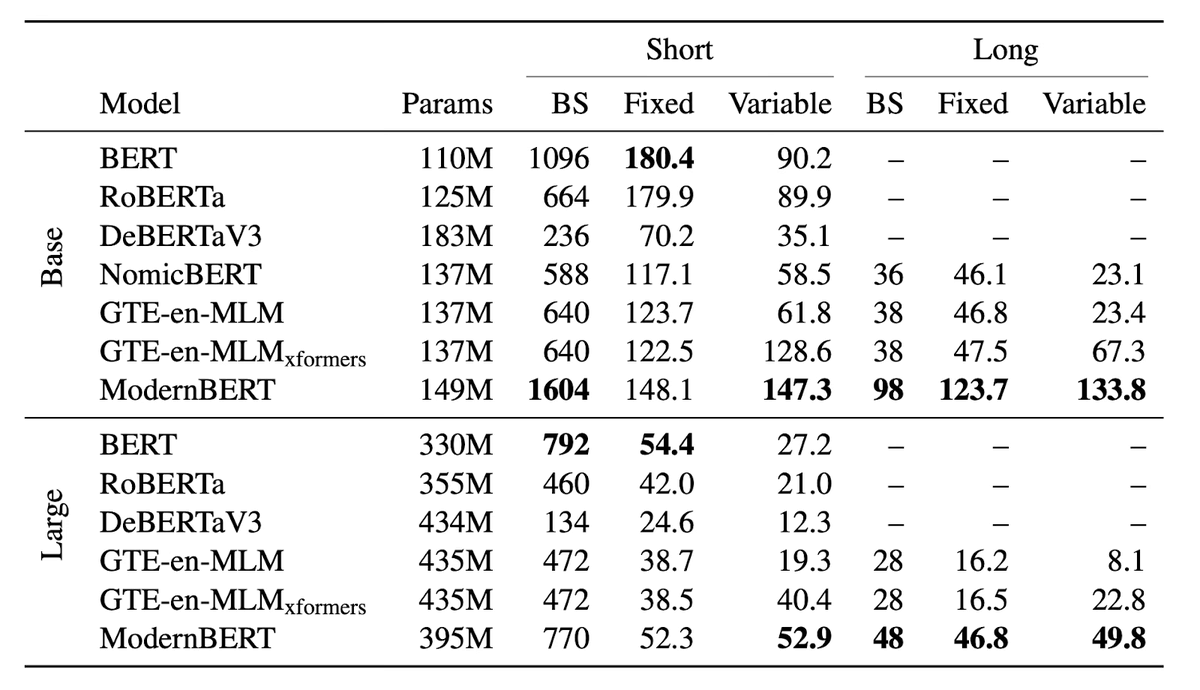
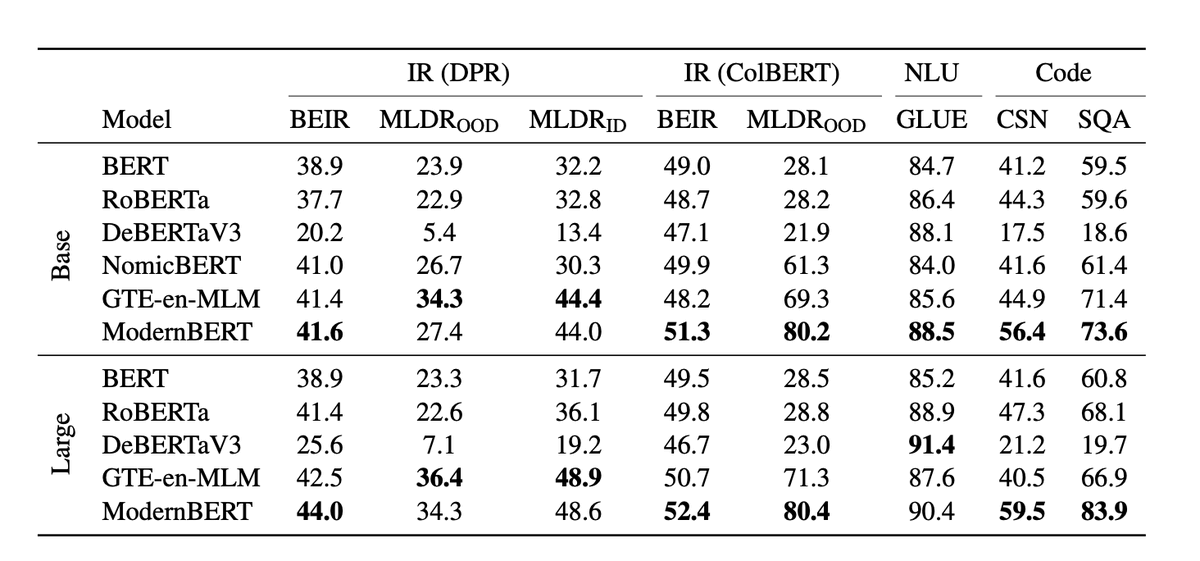
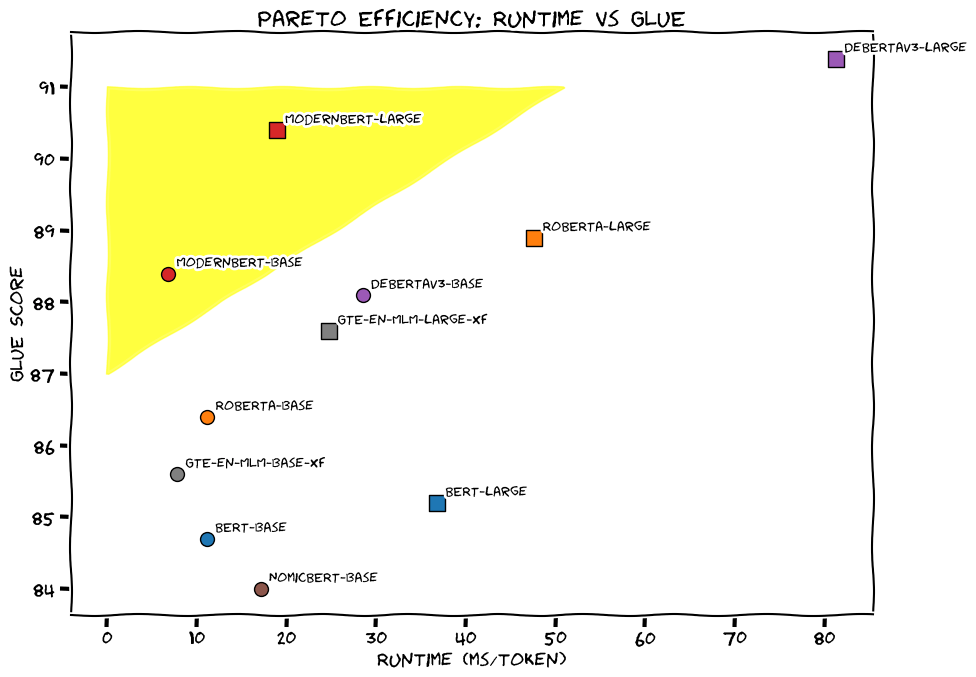
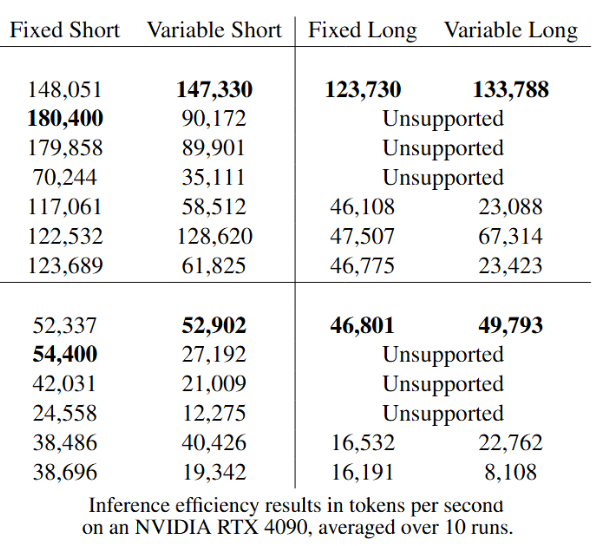
Today we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
2
12
80
11,488
Benjamin Warner retweeted

Jun 10
Some considerations that many folks seem not to get:
1. It can be a bubble even if the tech works. (For instance, if the tech doesn't have a high-demand use case.)
2. It can be a bubble even if the tech works and has strong product-market fit. (For instance, if the tech cannot be economically viable.)
3. It can be a bubble even if the tech works, has strong product-market fit, and has a path to eventual economic viability. (For instance, if profitability takes too long to achieve or makes margin/competition assumptions that fail to materialize.)
4. It can be a bubble even if the tech works, has strong product-market fit, and is currently highly profitable. (For instance, if demand has a hard ceiling and growth stops once the ceiling is reached.)
5. It can be a bubble even if the tech works, has strong product-market fit, is currently highly profitable, and has unlimited future demand.
Literally all it takes for something to be a bubble is for lots of people to over-enthusiastically bet their money on it, and subsequently get panicky.
Importantly, bubbles can be attached both to things that are completely hogwash, like the Metaverse, and to world-changing developments like the Internet or railways. Bubbles don't care. They're brought into existence by the thoughts and feelings of investors, not by actual tech or products.
"The bubble has burst" doesn't mean "the tech didn't work" or "people stopped using the tech." It only means that people got panicky, investor money dried up, and valuations collapsed. Internet adoption didn't stop in 2000.
102
208
1,836
108,305
Remember, for ChatGPT or Claude to work as search agents, you need to:
1) subscribe to get the smartest models
2) turn on thinking
3) make sure web search is on
Then you won't make embarrassing mistakes like Kelly Sadler.


134
Benjamin Warner retweeted

I appreciate Anthropic has provided healthcare-related evals! Let's quickly go over them.
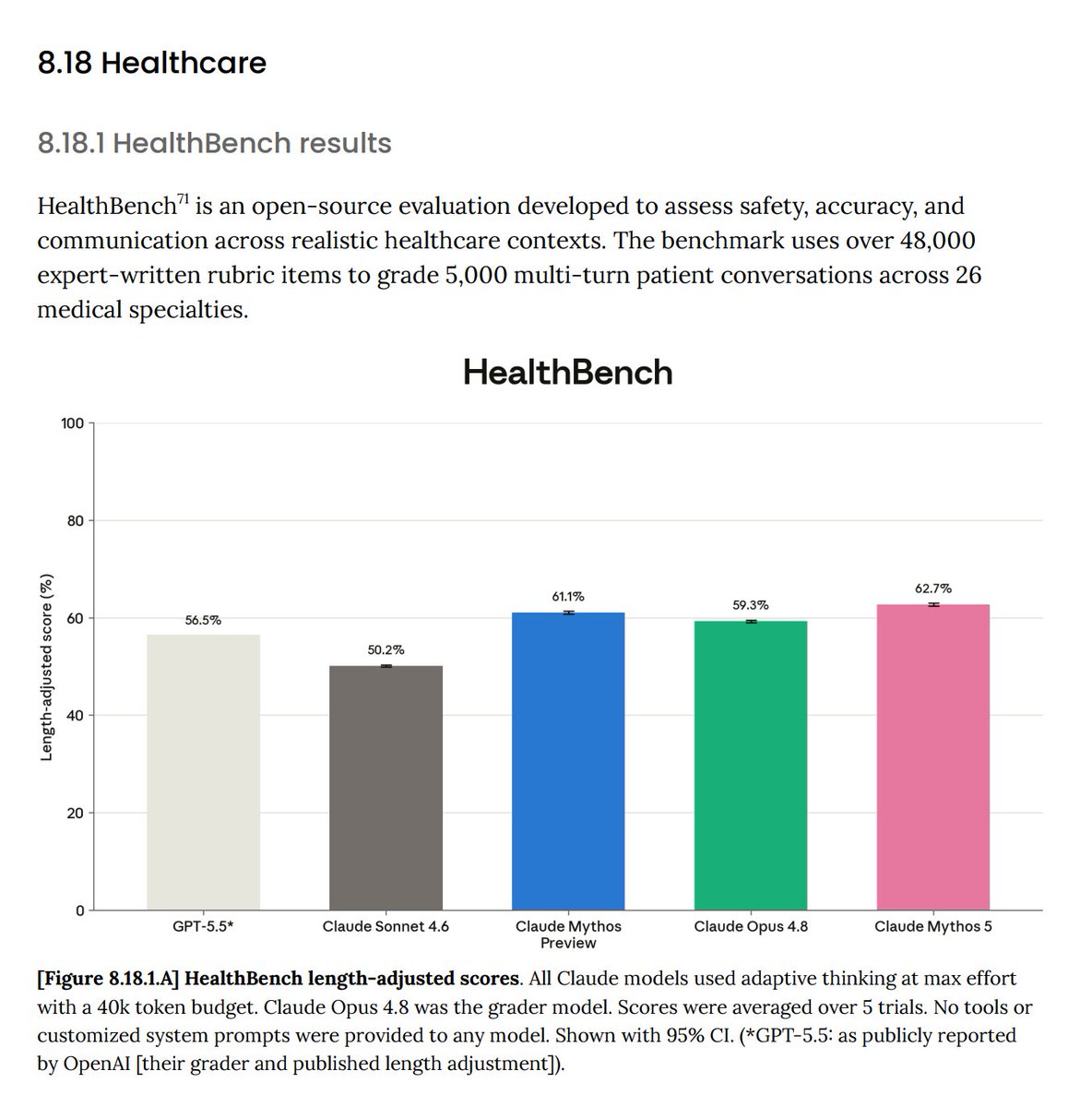
HealthBench - benchmark from OpenAI that includes 5k multi-turn conversations with patients, and rubrics for evaluation. Fable 5 achieves 62.7% vs. GPT-5.5's 56.5%. Personally, I would also appreciate HealthBench Hard scores as well in addition to the aggregate score.
HealthBench Professional - another OpenAI benchmark that focuses on physician tasks. Fable 5 achieves 66.0% vs. 51.8% for GPT 5.5.
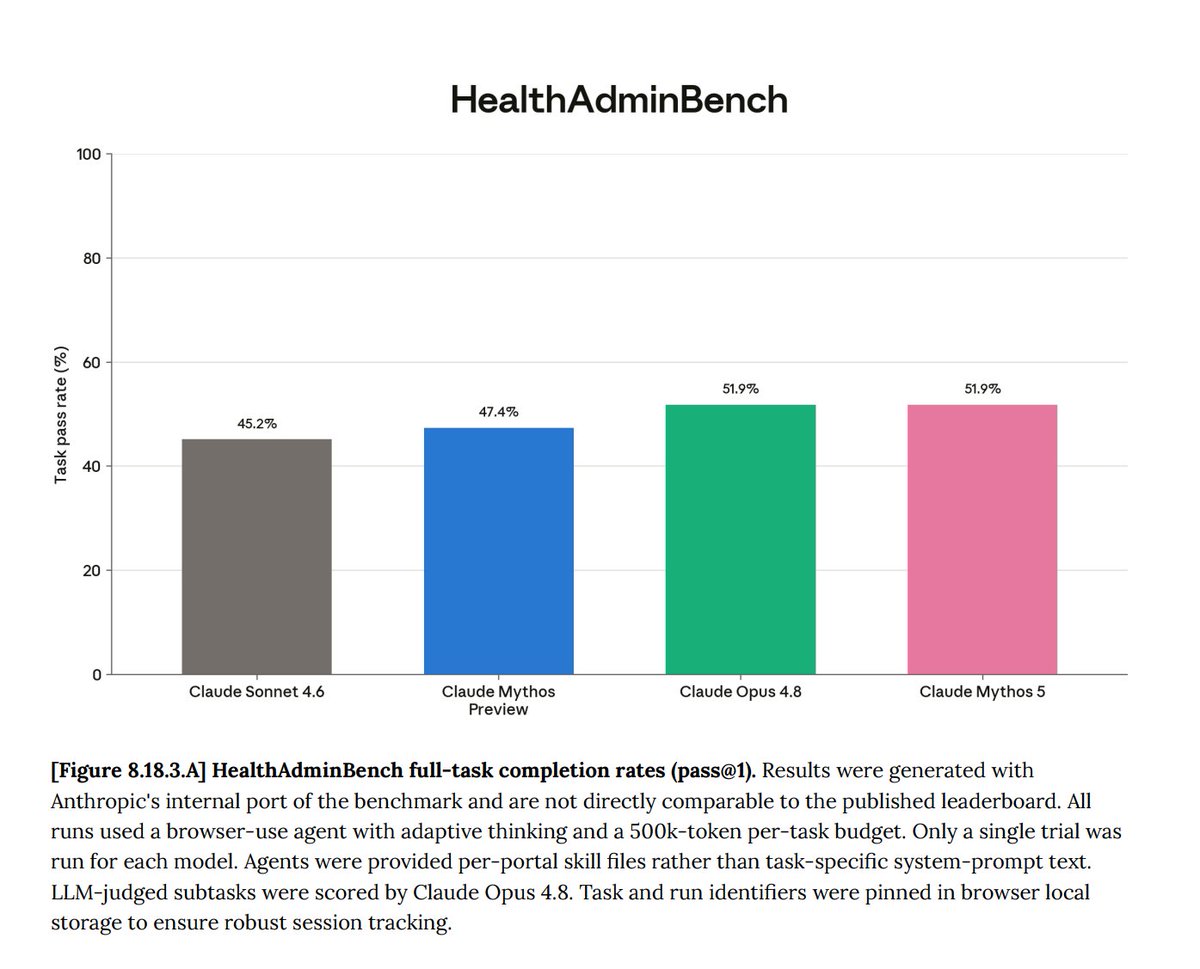
HealthAdminBench - a computer-use benchmark from Stanford that evaluates the completion og various administrative tasks (prior auth, denials/appeals, etc.). Fable 5 achieves 51.9%, no GPT-5.5 score provided.
Overall, this models seems to perform quite well on healthcare benchmarks. Would also appreciate additional benchmark scores like MedCalc-Bench (which was previously reported by Anthropic) and MedXpertQA (an unsaturated, hard medical MCQA benchmark).
Glad to see frontier labs are more comprehensively benchmarking and reporting the medical capabilities of their models!


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
10
6
53
6,593
The current best comparison for agentic coding is ATMs, which increased the demand for bank tellers.
Jun 2

Software engineering roles are growing and concentrating in the top-paying US companies via @GergelyOrosz newsletter.pragmaticengineer…
1
1
1,165
Benjamin Warner retweeted

May 26
Not to degrade from this work, but TurboQuant is not a competitive method nor a good benchmark. Researcher -- including me -- cannot replicate the TurboQuant paper, and even then, the performance is not great. Please. Just. Stop.
May 25

i just beat @GoogleDeepMind's turboquant
introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss
- 10x @ 8K context, 11.2x @ 32K
- NIAH recall 1.000 across 4K-32K
- LongBench Δ ≈ 0 vs FP16
turboquant tops out at 4-6x at the same quality. we doubled it.
read more: krishgarg.com/shard
@kirrithan
17
29
462
61,853
Bearish signal on the practical usefulness of Mythos.
May 22

My concern for the AI era, or at least this phase of it, is that a generation is being taught that "close enough" is just fine.
Take @AnthropicAI for example. Text wrapping in Claude Code has been broken for weeks. Superfluous spaces appear on the left edge. One engineer to another: you know its an out by one error.
I refused to believe that nobody has noticed this. The shtick they are selling is that AI can fix this kind of thing. Either they tried to prompt a fix, and Claude ain't good enough to fix an out-by-one error. Or they haven't attempted it because it is "close enough".
It can't be the case that AI is only good enough if we lower our standards. It can't.
I'm well aware I have both feet firmly planted in my "grumpy old man" phase of life...
264
It's astounding how much worse Claude Opus 4.7 still is at searching for up to date and accurate information compared to GPT-5.5 Thinking.
173
Benjamin Warner retweeted

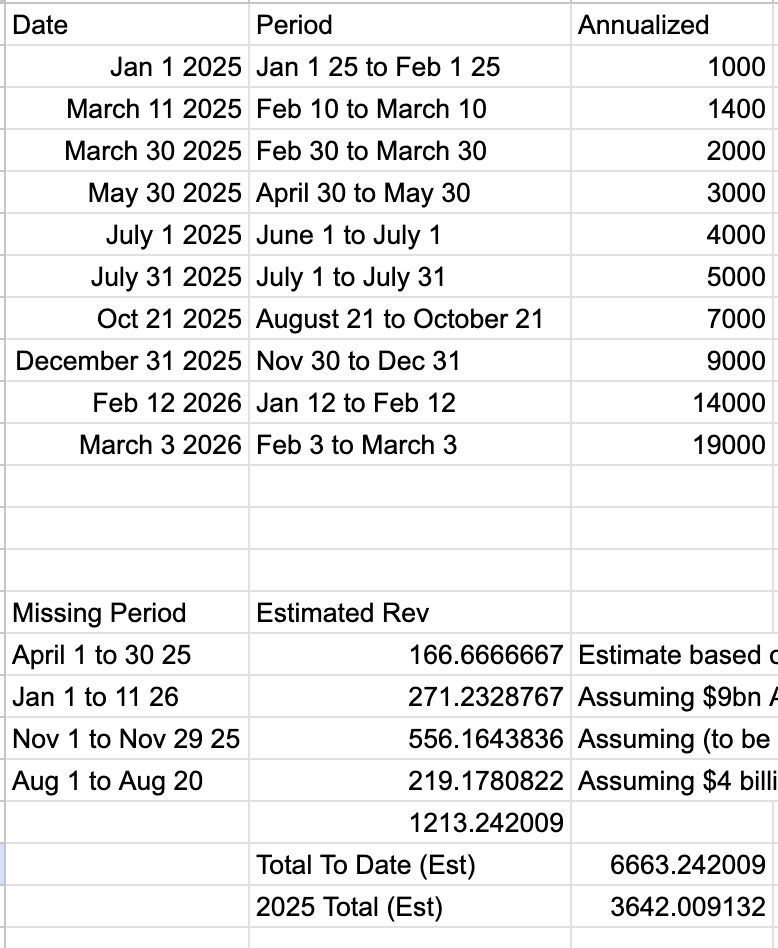
Never trust financial analysis from a guy who thinks Feb 30 is a thing.
Mar 18

Also, check out this train wreck of a spreadsheet Ed made to estimate Anthropic's revenue for 2025. He doesn't count February 1-10, counts March 1-10 twice, counts August 21-October 21 as one month instead of two, and doesn't count October 21-November 1.
1
4
45
6,346
Benjamin Warner retweeted
Excited that @SophontAI @MedARC_AI has a paper accepted to ICML!
Will share more details soon :)
7
5
60
4,814
Benjamin Warner retweeted

Apr 29
IBM Granite just released two multilingual embedding models with 97M and 311M parameters 🤏🏻
ModernBERT-based, 200 languages, 32K context, and built for retrieval, search, similarity, and code.
And... day-zero support on Text Embeddings Inference and friends!

7
60
458
42,947
A 90% confidence interval of 0.3-3x size would imply GPT 5.5 is anywhere from ~3 trillion parameters to ~27T. The latter is obviously not true, so this size estimation method doesn't seem useful.

Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
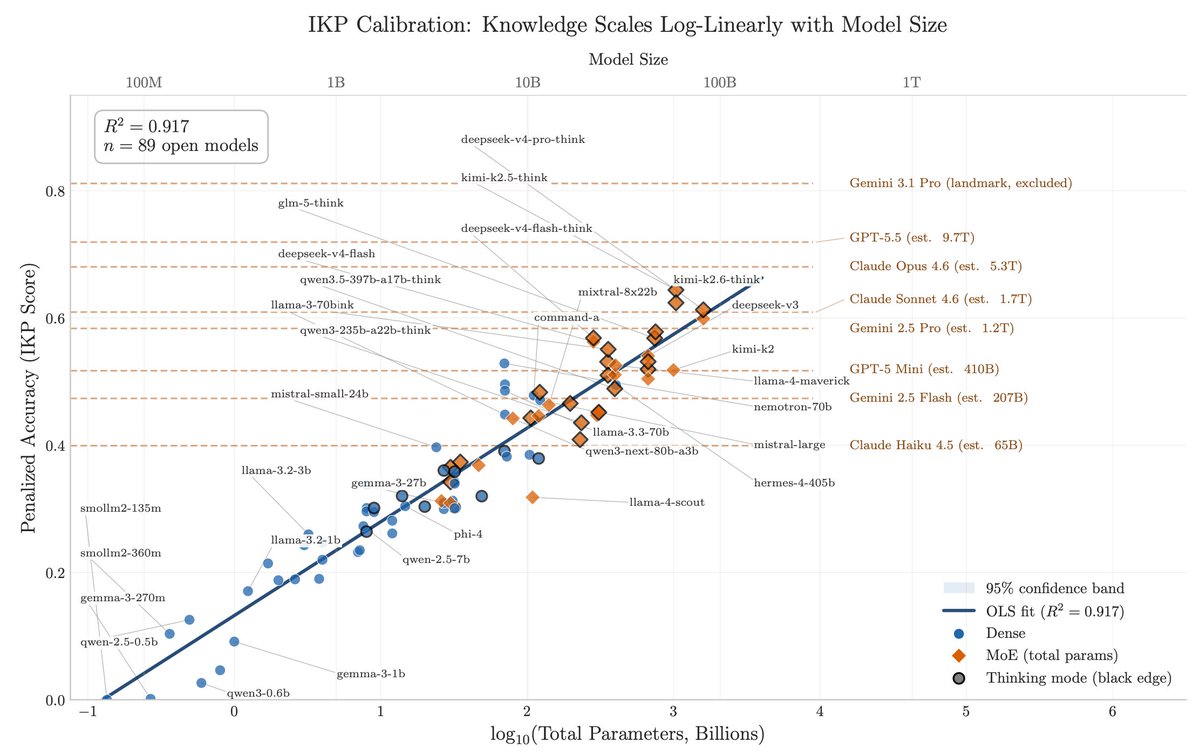
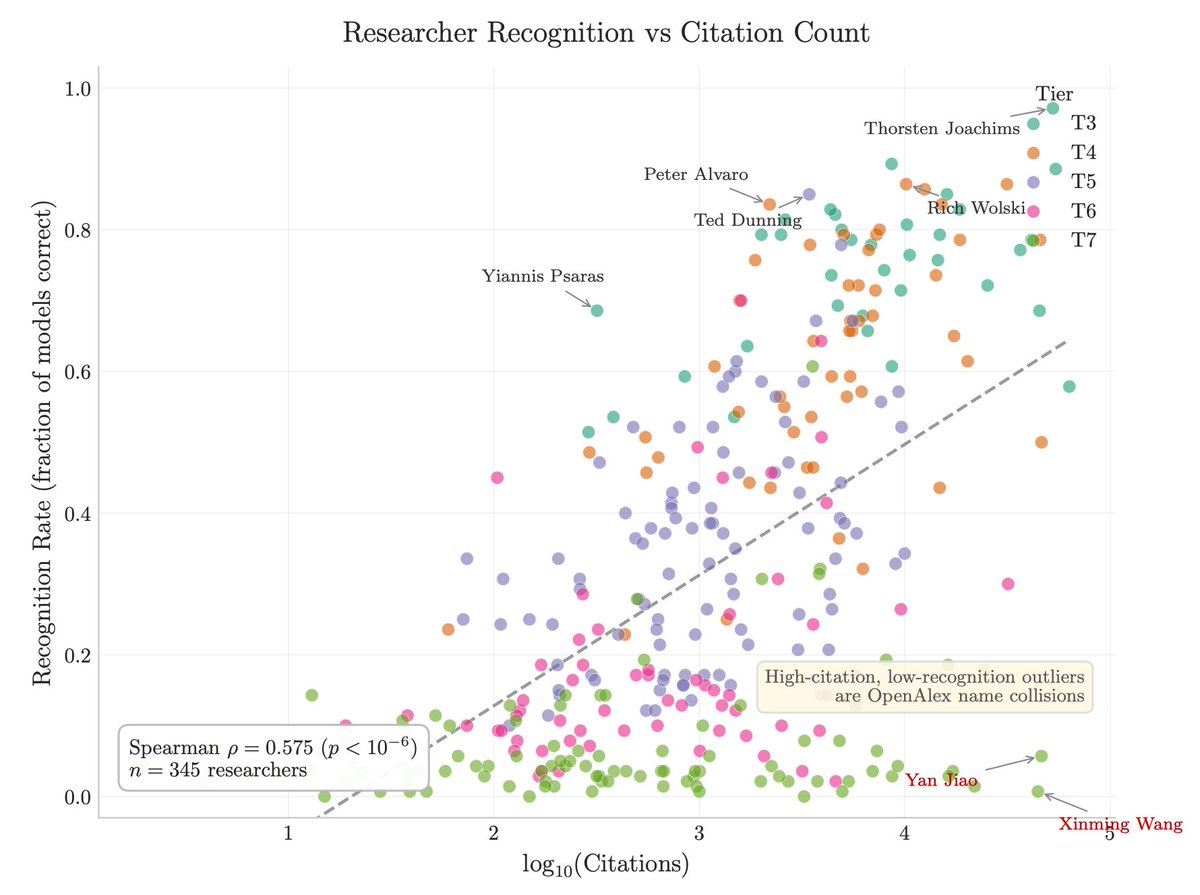
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
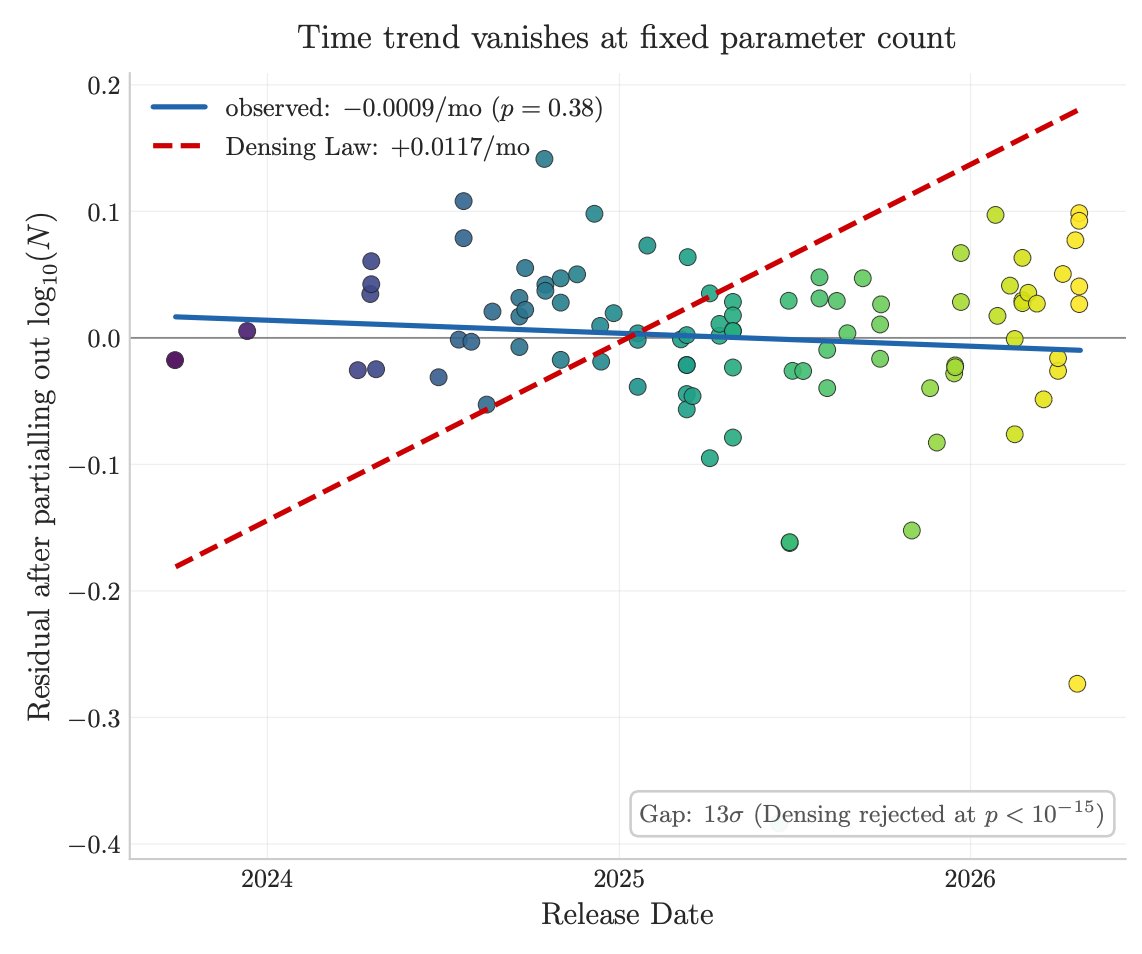
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of 0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: 01.me/research/ikp/
Paper: arxiv.org/pdf/2604.24827
13
1,799
RT @theo: Despite the price increase, GPT-5.5 (xhigh) still came out cheaper than Sonnet on the Artificial Analysis Index.
It's more expen…
92


Benjamin Warner retweeted

Apr 23
Remember the initial o3 release?
It was an insane jump over o1(-preview) in all regards and a genuine step change.
I was given access to GPT-5.5 the last few weeks and it felt like this era all over again.
Some impressions (both pro and con):


Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
26
17
307
49,771
I'm not a local ai hater. The issue is the local ai advertisers are always overstating local model capabilities relative to larger open-source models, much less frontier models.
While Qwen 3.6 looks to be a good model, I doubt it's matched Sonnet level across most tasks.

3
283
Benjamin Warner retweeted
I'm really glad to see OpenAI taking healthcare usecases so seriously.
Not only have they released a version of ChatGPT for clinicians, they've also released a benchmark (yay!) for evaluating LLMs in queries and workflows relevant to clinicians.
Also appreciate the @SophontAI Medmarks shout-out :)
Apr 22

Today we’re introducing two big steps for health at OpenAI:
- ChatGPT for Clinicians, a free version of ChatGPT designed for clinical work
- HealthBench Professional, a new benchmark to evaluate real clinician chat tasks
We’re excited about what this can unlock for care. ❤️

5
9
82
11,911
Benjamin Warner retweeted

Apr 15
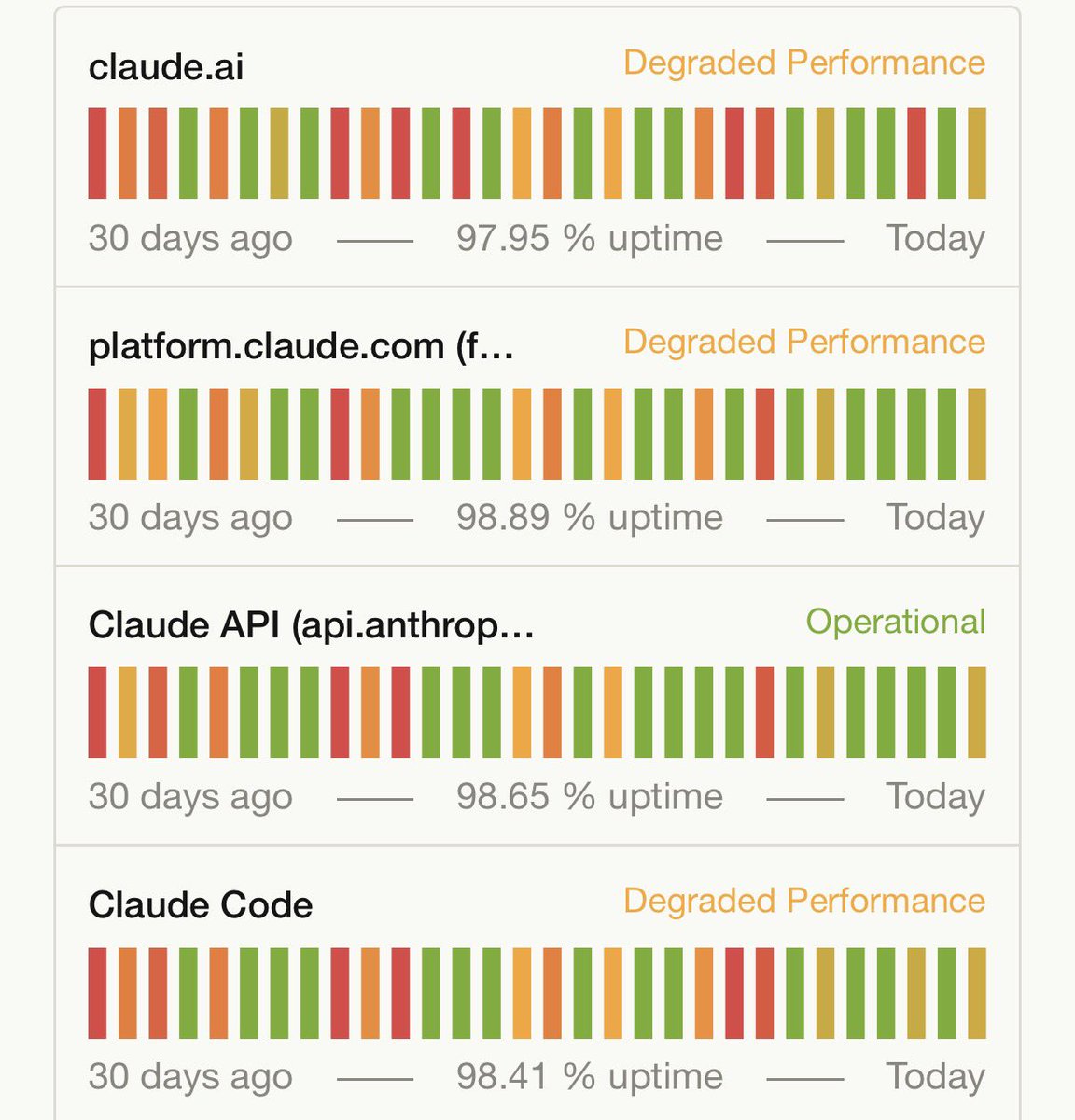
Claude Status Page vs Whole Foods Three Pepper Blend
Who wore it better?

122
492
9,679
407,653
Benjamin Warner retweeted
Apr 7
We in the quantization community could quickly see this and were flabbergastered by the response to TurboQuant.
Whenever I saw TurboQuant on my timeline, I found it hurtful, because the work of other academics who worked so hard was discounted.
9
12
238
19,453
Now that the Codex promo 2x rate limit is gone, where are the plans between $20/m and $200/m?
1
1
399