
Jun 13
I was told that the ssgac will no longer be conducting studies that are controversial because the data was "used by bad actors". I inferred that the sumstats for the Tan et al paper were removed for a similar reason, but looks like that inference is incorrect.
1
4
231
HBD has nothing to do with the Tan et al sumstats
1
20
899
In response to demand we've released an expanded set of sumstats from applying the unified estimator to 28 phenotypes in the UK Biobank, with sumstats available for ~5 million high quality imputed SNPs (INFO>0.99, MAF>1%).
3
24
2,082
Family-GWAS results were critical in testing the robustness of inferences of natural selection in the recent Akbari/Reich paper.
We're releasing family-GWAS sumstats on 28 phenotypes on thessgac.com/ data portal, using the powerful method we developed in Guan et al.

3
37
124
20,745
You can correlate someone's genotypes with the sumstats allele frequencies across the genome. Without precise allele frequencies for many genome-wide SNPs, maybe you can do it using the effect estimates if you also have phenotype information on the individual.
The bigger the sample size the harder it should get too so I wonder how real this risk is if you took measures to avoid it like reduced precision of the sumstats numbers and only releasing sumstats based on millions of samples, but I've not thought about it deeply.
5
143

Apr 8
I am skeptical of the value proposition. Without good validation cohorts the sumstats are useless and whoever has good validation cohorts already has access to them.
1
4
100

Apr 8
I saw this yesterday and thought it was cool. I probably would’ve loved this a year ago though. I do wonder how necessary it really is at this point. I’m working on a large batch of sumstats for a project, including PGC on Figshare that are annoying to access manually. This time, I just asked Claude Code to create a manifest for the latest PGC sumstats and download them for me.
2
6
273

Jan 16
Gero is hiring!
We're seeking a Statistical Geneticist, Computational Biologist, or Bioinformatics Scientist with expertise in deep learning applications for variant annotation and functional genomics. You'll advance our target discovery platform by working with AI models, multi-omics data, and large-scale population genetics datasets to identify therapeutic targets and speed up drug discovery. Key tasks include processing genetics (GWAS/PheWAS), building reliable pipelines; implementing state-of-the-art methods; and developing production-ready code.
The ideal candidate has strong computational genomics skills and a passion for translating biological data
into drug development insights.
Key Responsibilities:
• Data management & preprocessing: Handle tabular data, genetics data (plink format), GWAS sumstats, molQTL.
• Statistical Genetics: Conduct WGS/WES common and rare variant association studies, followed by post-GWAS integration using colocalization, mendelian randomization, and multi-omics (transcriptomics/proteomics) analysis.
• Machine Learning: Implement classical ML and deep learning solutions for functional genomics.
• Pipeline development & maintenance: Design, build, and maintain automated analysis pipelines for association studies, ensure code quality.
Education: MSc/PhD in Statistical Genetics, Bioinformatics, Biostatistics, Computer Science, or related quantitative field.
Experience:
• 3 years (MSc) with relevant experience (or relevant doctoral research for PhD).
• Demonstrated hands-on experience analyzing large-scale datasets with statistical
inference and machine learning.
• Relevant publications in top-tier journals.
Technical Skills:
• Advanced Proficiency in Python and R.
• Proficient in a Unix/Linux command-line environment.
• Practical experience with population genetics, GWAS and post-GWAS methods.
• HPC or cloud computing experience is necessary.
• Experience in training deep neural networks is a plus.
Personal Attributes: A proactive problem-solver who thrives in fast-paced, autonomous environments and is eager to master evolving technologies.
What We Offer:
• Competitive Compensation: Salary packages aligned with industry standards.
• Remote-First: globally remote with flexible hours.
• High-Trust Culture: minimal-bureaucracy environment with complete ownership.
• Immediate Impact: Your contributions will drive our core therapeutic discovery engine from day one.
• Publication Opportunities: Active support for publishing.
How to Apply:
Interested candidates should submit a CV detailing their relevant experience, specific skills related to the requirements above, and suitability for the role to dreamjob biojan26@gero.ai.
About Us:
In GERO.AI (@hacking_aging), our mission is to decelerate human aging and develop innovative therapies for chronic conditions. We utilize physics-based foundational models trained on longitudinal data (e.g. UK Biobank). By extracting continuous biological latents (metabolic, immune, and biological age), we model health resilience and functional units far beyond the limitations of ICD-10 codes. Our genetics-driven causal AI pipeline integrates human genetics with multi-omics data to identify novel treatments and accelerate drug discovery.
2
6
13
1,528

Jan 12
It's truly a sad state of affairs when it takes longer to pull GWAS sumstats out of the AllofUs research platform than it takes to generate them.
2
285

22 Nov 2025
They cite the Savage meta analysis for their IQ predictor, which is not an SSGAC study. And SSGAC PGI repo doesn't release any sumstats.
1
2
335

5 Nov 2025
We recently passed 1 million curated SNP-trait associations!
See how the GWAS Diagram has changed with the significant data growth.
Contribute to our growing dataset and the diagram view by submitting your #SumStats and now also your top assoc. bit.ly/38rNSjx
1
4
159

24 Oct 2025
Note that the sumstats from the 3M sample EA study are not easy to access, and no one in academia has bothered to build an IQ predictor with them as far as I've seen.
1
1
281

13 Oct 2025
📦 Data:
We leveraged data from 60,000 UK Biobank participants with up to 10 years of follow-up.
Inputs included:
Cardiac, liver, pancreas & DXA imaging
Polygenic risk scores (trained using GWAS sumstats on 1.25M people)
Blood biomarkers
ECGs & demographics
1
3
533
31 Jul 2025
Btw, calculating polygenic scores (if you have a file with the genetic data) is extremely easy, and doable on a desktop PC. I don't see how embryo screening companies will be profitable in the future, unless the sumstats of future research will not be public.
12
1
62
3,915
16 Jul 2025
🚨 IMPORTANT UPDATE 🚨
👩🏻💻👨🏻💻Work on #gwas?
📊Did you submit your #SumStats (bit.ly/38rNSjx) or are you planning to do so?
Now you can ALSO submit the top associations to be included in the @GWASCatalog !
Follow @YiorKalantz's example and submit your data directly. 👇👇

1
3
7
1,608

28 Jun 2025
i'm not ruling out gxg but idt the results from that iLDSC paper paint a very compelling picture honestly. impressive they were able to do that just from sumstats & LD info, but the extra variance captured overall seems pretty small
1
1
172

27 May 2025
I had the wrong software link earlier in the thread. See below for the correct one. We've done three very different PIGEON GxE applications. Read the paper for more details. All sumstats produced in the paper are publicly available too.
Software🧑💻github.com/qlu-lab/PIGEON
2
374
13 Feb 2025
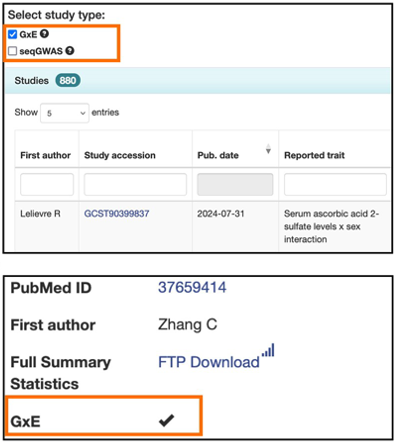
Interested in GxE interaction #gwas?
Now, you can identify and filter them on our website!
Check the great review made by @genandgenes et al. at @JohnsHopkinsEPIThey.
They also analysed the data we hosted and showed a lack of #SumStats available. tinyurl.com/bdfmsmtd
1
7
23
1,769
5 Feb 2025
Beyond excited to share this new paper with all of you . It's the most fun we've ever had. We figured out how to study a latent index driving partner choice without measuring it directly🥂
@qinwen_zzz
Preprint📰: biorxiv.org/content/10.1101/…
Sumstats⬇️: qlu-lab.org/data.html

2
31
84
11,771
4 Feb 2025
In #WorldCancerDay you can access ~ 2500 #gwas linked to cancer, with close to 1,100 of them with #SumStats. THANKS for helping us to increase the data available following #FAIRprinciples. Share your data bit.ly/38rNSjx #OpenAccess

9
453