
Accelerating Deep Learning Research with the Tensor2Tensor Library research.googleblog.com/feed…
1

9 Nov 2025
Sunday Thought Experiment
What will computing
(that which is currently known as software / development)
be like
after genAI
ends
(without asking anyone's
permission)
the multi-generational
conflicts
"the industry"
was unable to resolve:
"Is it a function or a procedure?"
"Is it a parameter or an argument?"
"Is it 'verification', 'validation' or just 'testing'?"
"Is it tabs, spaces, {} or ;
for God's sake?"
AND
extends control
(where it always belonged from day 1)
to the USER
to establish the
RULES
that define the
CONDITIONS
that trigger the
OPERATIONS
that produce the
USES
of the
INFORMATION
SEEN
on the
DEVICES
controlled by the
USER?
n.b. What's at both ends of the lifecycle?
I assert that
if the best crystal ball
revealed even 10-20% of what that world will be like, it will only be true for phase 1. That world will iterate at a pace and volume impossible to
predict or manage
much less monitor or
(heaven forbid) regulate.
The question more urgent is this:
Who among the titans of industry has
the resources
the courage
the philosophy
and (dare I say) generosity
to end hardcoded software forever?
Who will stand on the shoulders of the pioneers and philosophers:
1 **Charles Babbage (1837)** - Designs the Analytical Engine, the first mechanical computer concept — computation as machinery.
2. **Alan Turing (1936)** — *On Computable Numbers* defines the concept of the universal machine and the theoretical basis for AI.
3. **John von Neumann (1945)** — Drafts the architecture for stored-program computers, establishing how machines “think.”
4. **Norbert Wiener (1948)** — *Cybernetics* introduces feedback loops as a principle of intelligent control.
5. **Claude Shannon (1948)** — *A Mathematical Theory of Communication* founds information theory and quantifies knowledge.
6. Grace Hopper (1952)** - Creates the first compiler and leads the development of COBOL — human language meets machine logic.
7. **J.C.R. Licklider (1960)** — *Man-Computer Symbiosis* envisions humans and machines thinking together.
8. **Douglas Engelbart (1962)** — *Augmenting Human Intellect* proposes tools that amplify cognition (precursor to modern interfaces).
9. **John McCarthy (1956)** — Coins the term *Artificial Intelligence* and leads early symbolic AI research.
10. **Marvin Minsky (1959)** — MIT AI Lab co-founder; advances early machine perception and learning.
11. **Donald Knuth (1968)** — Publishes *The Art of Computer Programming*, codifying algorithmic thinking.
12. **Edgar F. Codd (1970)** — Introduces the relational database model, formalizing how knowledge is stored and queried.
13. **Tim Berners-Lee (1989)** — Creates the World Wide Web; connects the world’s information graph for machines to traverse.
14. **Geoffrey Hinton (1986)** — Revives neural networks with backpropagation; the cognitive rebirth of AI.
15. **Yann LeCun (1989)** — Demonstrates convolutional neural networks (CNNs), enabling machine vision.
16. **Yoshua Bengio (1994)** — Advances representation learning and deep generative modeling.
17. **Nick Bostrom (2003)** — *Ethical Issues in Advanced Artificial Intelligence* and later *Superintelligence* frame AI existential risk.
18. **Fei-Fei Li (2009)** — Launches ImageNet, sparking the deep learning revolution through massive visual data.
19. **Demis Hassabis (2014)** — DeepMind’s *AlphaGo* proves neural networks can achieve strategic reasoning.
20. **Ashish Vaswani (2017)** — Lead author; invents the Transformer attention mechanism.
21. **Noam Shazeer (2017)** — Designs multi-head attention and scaling strategies.
22. **Niki Parmar (2017)** — Co-develops the Transformer training framework.
23. **Jakob Uszkoreit (2017)** — Contributes to architecture and parallelization design.
24. **Llion Jones (2017)** — Implements core sections of the original model (and later, *Grok*).
25. **Aidan N. Gomez (2017)** — Authors early theoretical analysis and the *Attention Is All You Need* title.
26. **Łukasz Kaiser (2017)** — Bridges Tensor2Tensor framework with attention-based models.
27. **Illia Polosukhin (2017)** — Applies Transformer insights to open-source and blockchain AI systems (later co-founded NEAR Protocol).
28. **Timnit Gebru (2018)** — Publishes on data ethics and model bias (*Gender Shades*, *Datasheets for Datasets*).
29. **Dario Amodei (2018)** — Leads interpretability and safety research at OpenAI, then co-founds Anthropic.
..
to deliver on once and for all the
second greatest promise ever made to humanity -
the promise of computing.
@Metaai @finkd @Meta @googleai @AnthropicAI @openai @xai @grok @Alibaba_Qwen @mistral @salesforce @Benioff
Other?
1
27

9 Nov 2025
> be Noam Shazeer
> studied math & CS at Duke
> joins Google in 2000
> invents the Transformer Architecture
> co-designs Tensor2Tensor, a Google library for training deep learning models, including the first implementations of Transformers
> leaves Google and builds CharacterAI
> 2023: company hits $1B valuation
> 2024: Google aquires his company for $2.3B and rehires him to solve the issues with racist/inaccurate outputs by gemini
> now leading Gemini
***LEGEND***

1
137

28 Sep 2025
Gemini关键人物Dustin Tran加盟xAI
1, UC-Berkeley 统计本科,哈佛统计博士,哥伦比亚计算机博士,学术大牛
2,他在 Google 的八年间,从奠基性研究(Image Transformer、Tensor2Tensor、Mesh TensorFlow)到领导 Gemini 的关键迭代与评估,推动其登上并长期保持全球榜首,再到开创长链条推理与深度思考训练,使模型在 IMO、ICPC 等竞赛中达到金牌水平,他不仅奠定了技术基础,还引领了 Gemini 的崛起与 Google 在全球 AI 竞争中的再度领先,成为推动行业格局转变的重要力量。
3,他选择加入 xAI 的最重要原因在于:
xAI 提供了前所未有的 算力规模(人均芯片数量远超 Google,且即将获得 10 万 GB200/30 万 GB300 配合 Colossus 2),并在 数据与训练方法 上敢于进行最大规模化尝试(如 Grok 4 在 RL 和后训练上的突破)。再加上 团队体量精干、执行速度极快,让他坚信在这里能以更高的加速度推进前沿大模型的发展。
4,Tran 是典型的越南裔last name
5,恭喜马斯克!AI时代,一个人或一个团队,完全可以改写历史!


2
3
23
8,396

22 Sep 2025
image transformer tensor2tensor = official toolkit for minting brainy nft art, right?
2

22 Sep 2025
Z DeepMind do xAI: nový tah na branku v AI ⚡🤖
👨🔬 Po 8 letech v Google DeepMind (Image Transformer, Tensor2Tensor, Mesh TF, Gemini evaluace, IMO/ICPC medaile) → přechod do xAI
🚀 Gemini: z chatbotu LaMDA → dlouhé odpovědi přes RLHF → deep reasoning přes řetězce myšlení → dnes #1 v preferencích uživatelů i ve vědeckých benchmarkách
💾 xAI recept: compute data ~100 špičkových lidí → frontier LLM. Colossus 2 = 100K GB200 / 300K GPU → největší compute na hlavu v historii AI
📈 @xai sází na škálování dat, hluboké myšlení, nové tréninkové recepty → nejrychlejší tempo inovací v oboru
⚡ Novinka: Grok 4 Fast → mini model, 15× levnější než Grok 4, přesto srovnatelný výkon v reasoning testech (AIME, ARC-AGI). Na LMArena #8 (pro srovnání Gemini 2.5 Flash #18)
🤝 @grok Teams pro firemní zákazníky
🤔 Je právě xAI s kombinací compute power rychlosti provedení nejvážnějším vyzyvatelem Googlu a OpenAI?


19 Sep 2025

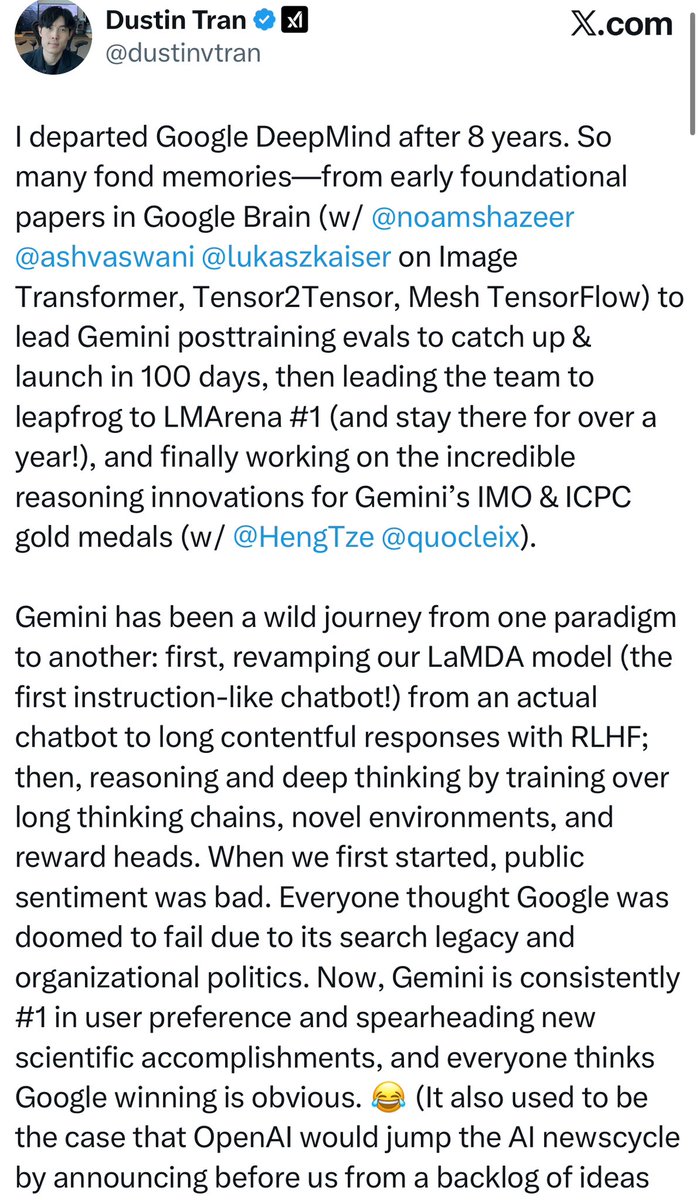
I departed Google DeepMind after 8 years. So many fond memories—from early foundational papers in Google Brain (w/ @noamshazeer @ashvaswani @lukaszkaiser on Image Transformer, Tensor2Tensor, Mesh TensorFlow) to lead Gemini posttraining evals to catch up & launch in 100 days, then leading the team to leapfrog to LMArena #1 (and stay there for over a year!), and finally working on the incredible reasoning innovations for Gemini’s IMO & ICPC gold medals (w/ @HengTze @quocleix).
Gemini has been a wild journey from one paradigm to another: first, revamping our LaMDA model (the first instruction-like chatbot!) from an actual chatbot to long contentful responses with RLHF; then, reasoning and deep thinking by training over long thinking chains, novel environments, and reward heads. When we first started, public sentiment was bad. Everyone thought Google was doomed to fail due to its search legacy and organizational politics. Now, Gemini is consistently #1 in user preference and spearheading new scientific accomplishments, and everyone thinks Google winning is obvious. 😂 (It also used to be the case that OpenAI would jump the AI newscycle by announcing before us from a backlog of ideas for every new Google release; safe to say that backlog is empty.)
I have since joined xAI. The recipe is well-known. Compute, data, and O(100) brilliant, hard-working people are all that’s needed to obtain a frontier-level LLM. xAI *really* believes in this. For compute, even at Google I have never experienced this # of chips per capita (& 100K GB200/300K’s are incoming with Colossus 2). For data, Grok 4 made the biggest bet in scaling RL & posttraining. xAI is making new bets to scale data, deep thinking, and the training recipe. And the team is quick. No company has gotten to where xAI is today in AI capabilities in as little as time. As @elonmusk says, a company’s first- and second-order derivatives are the most important: xAI’s acceleration is the highest.
I’m excited to announce that in my first few weeks, we launched Grok 4 Fast. Grok 4 is an amazing reasoning model, still the top on ARC-AGI and new benchmarks like FinSearchComp. But it’s slow and was never really targeted for general-purpose user needs. Grok 4 Fast is the best mini-class model—on LMArena, it is #8 (Gemini 2.5 Flash is #18!), and on core reasoning evals like AIME, it is on par with Grok 4 while 15x cheaper. S/o to @LiTianleli @jinyilll @adityagupta @s_tworkowski @keirp1 @yuhu_ai_
2
1,098




21 Sep 2025
马斯克从Google DeepMind 最近挖走了不少员工,Dustin Tran 就是其中一位,昨天他发文离开 Google DeepMind 加入 xAI 的推文的阅读量竟然高达 1000 多万。一方面是马斯克转发和评论,另一方面是这篇推文中有一些 AI 相关的核心信息:
1. Dustin Tran 在 DeepMind 主要负责模型的数据和评估工作。
2. 过去,每当谷歌有新发布时,OpenAI 总是会从他们积压的想法中抢先宣布,从而抢占 AI 新闻头条;可以肯定地说,那个积压的想法库现在已经空了。
3. 获得一个前沿水平的 LLM 所需的全部要素就是:算力、数据和大约 100 位才华横溢、勤奋工作的员工。
4. 硅谷目前有一个共识:算力=智力,所以 OpenAI、Google、微软、亚马逊都在大力建造大型 GPU 数据中心。这些公司中,xAI 的人均算力数量最多,甚至比 Google 还要多。用 Dustin 的原话是:“在算力方面,即使在谷歌,我也从未经历过如此高的人均芯片数量(而且超过 10 万个 GB200/300K 芯片正随 Colossus 2 到来)。”
5. 在数据方面,Grok 4 在扩展 RL 和后训练阶段下了最大的赌注。xAI 正在数据扩展、深度思考和训练方法上进行新的押注。
6. 马斯克说说,一个公司的“一阶导数”和“二阶导数”是最重要的:xAI 的加速度是最高的。
7. Grok 4 是一个出色的推理模型,但它速度慢,而且从未真正针对通用用户需求。而 Grok 4 Fast 是最优秀的小型模型,与 Grok 4 表现相当,但成本便宜了 15 倍。
以下是原推文翻译:
我在 Google DeepMind 工作了 8 年后离开了。这段充满了美好的回忆——从早期在 Google Brain 参与撰写基础性论文(与 @noamshazeer @ashvaswani @lukaszkaiser 合作的 Image Transformer、Tensor2Tensor、Mesh TensorFlow),到领导 Gemini 的训练后评估团队,在 100 天内迎头赶上并成功发布,再到带领团队一举登顶 LMArena 排行榜第一名(并保持了一年多!),最后是为 Gemini 在 IMO 和 ICPC 中摘得金牌而进行的惊人推理创新工作(与 @HengTze @quocleix 合作)。
Gemini 的发展是一段从一个范式到另一个范式的疯狂旅程:首先,我们将 LaMDA 模型(第一个类似指令的聊天机器人!)从一个真正的聊天机器人改造为能够通过 RLHF 生成长篇、内容丰富的回答;然后,通过在长思维链、新颖环境和奖励头(reward heads)上进行训练,实现了推理和深度思考。当我们刚开始时,公众的情绪很糟糕。每个人都认为,由于其搜索业务的历史包袱和组织政治,谷歌注定会失败。现在,Gemini 在用户偏好方面持续排名第一,并引领着新的科学成就,每个人都认为谷歌的胜利是理所当然的。(过去,每当谷歌有新发布时,OpenAI 总是会从他们积压的想法中抢先宣布,从而抢占 AI 新闻头条;可以肯定地说,那个积压的想法库现在已经空了。)
此后,我加入了 xAI。成功的秘诀是众所周知的。获得一个前沿水平的 LLM 所需的全部要素就是:算力、数据和大约 100 位才华横溢、勤奋工作的员工。xAI 真的 对此深信不疑。在算力方面,即使在谷歌,我也从未经历过如此高的人均芯片数量(而且超过 10 万个 GB200/300K 芯片正随 Colossus 2 到来)。在数据方面,Grok 4 在扩展 RL 和训练后阶段下了最大的赌注。xAI 正在数据扩展、深度思考和训练方法上进行新的押注。而且这个团队行动迅速。没有哪家公司能在如此短的时间内,在 AI 能力上达到 xAI 今天的高度。正如 @elonmusk 所说,一个公司的“一阶导数”和“二阶导数”是最重要的:xAI 的加速度是最高的。
我很兴奋地宣布,在我加入的头几周,我们就发布了 Grok 4 Fast。Grok 4 是一个出色的推理模型,在 ARC-AGI 和像 FinSearchComp 这样的新基准测试上仍然是顶尖的。但它速度慢,而且从未真正针对通用用户需求。Grok 4 Fast 是最优秀的小型模型——在 LMArena 上排名第 8(Gemini 2.5 Flash 排名第 18!),在像 AIME 这样的核心推理评估中,它与 Grok 4 表现相当,但成本便宜了 15 倍。特别感谢 @LiTianleli @jinyilll @adityagupta @s_tworkowski @keirp1 @yuhu_ai_
19 Sep 2025
I departed Google DeepMind after 8 years. So many fond memories—from early foundational papers in Google Brain (w/ @noamshazeer @ashvaswani @lukaszkaiser on Image Transformer, Tensor2Tensor, Mesh TensorFlow) to lead Gemini posttraining evals to catch up & launch in 100 days, then leading the team to leapfrog to LMArena #1 (and stay there for over a year!), and finally working on the incredible reasoning innovations for Gemini’s IMO & ICPC gold medals (w/ @HengTze @quocleix).
Gemini has been a wild journey from one paradigm to another: first, revamping our LaMDA model (the first instruction-like chatbot!) from an actual chatbot to long contentful responses with RLHF; then, reasoning and deep thinking by training over long thinking chains, novel environments, and reward heads. When we first started, public sentiment was bad. Everyone thought Google was doomed to fail due to its search legacy and organizational politics. Now, Gemini is consistently #1 in user preference and spearheading new scientific accomplishments, and everyone thinks Google winning is obvious. 😂 (It also used to be the case that OpenAI would jump the AI newscycle by announcing before us from a backlog of ideas for every new Google release; safe to say that backlog is empty.)
I have since joined xAI. The recipe is well-known. Compute, data, and O(100) brilliant, hard-working people are all that’s needed to obtain a frontier-level LLM. xAI *really* believes in this. For compute, even at Google I have never experienced this # of chips per capita (& 100K GB200/300K’s are incoming with Colossus 2). For data, Grok 4 made the biggest bet in scaling RL & posttraining. xAI is making new bets to scale data, deep thinking, and the training recipe. And the team is quick. No company has gotten to where xAI is today in AI capabilities in as little as time. As @elonmusk says, a company’s first- and second-order derivatives are the most important: xAI’s acceleration is the highest.
I’m excited to announce that in my first few weeks, we launched Grok 4 Fast. Grok 4 is an amazing reasoning model, still the top on ARC-AGI and new benchmarks like FinSearchComp. But it’s slow and was never really targeted for general-purpose user needs. Grok 4 Fast is the best mini-class model—on LMArena, it is #8 (Gemini 2.5 Flash is #18!), and on core reasoning evals like AIME, it is on par with Grok 4 while 15x cheaper. S/o to @LiTianleli @jinyilll @adityagupta @s_tworkowski @keirp1 @yuhu_ai_
1
326

20 Sep 2025
การเปลี่ยนแปลงครั้งใหญ่ในวงการ AI: การย้ายทีมของ Dustin Tran สู่ xAI และการเปิดตัว Grok 4 Fast
วงการ AI กำลังสั่นสะเทือนอีกครั้ง เมื่อ Dustin Tran นักวิจัยระดับหัวกะทิผู้มีบทบาทสำคัญในการพัฒนา Gemini AI ของ Google DeepMind ตัดสินใจย้ายมาร่วมทีมกับ xAI บริษัทที่ก่อตั้งโดย Elon Musk ถือเป็นการเคลื่อนไหวเชิงกลยุทธ์ที่สะท้อนการแข่งขันอันดุเดือดของบริษัทยักษ์ใหญ่ในสนาม AI
Tran ใช้เวลากว่า 8 ปีกับ Google DeepMind โดยมีส่วนร่วมในผลงานระดับเรือธงอย่าง Image Transformer, Tensor2Tensor และ Mesh TensorFlow รวมถึงผลักดัน Gemini สู่ตำแหน่งอันดับ 1 บน LMArena ผลงานของเขายังครอบคลุมทั้งเวทีแข่งขันระดับโลกอย่าง IMO และ ICPC แสดงให้เห็นถึงทั้งความลึกในเชิงเทคนิคและความสามารถเชิงกลยุทธ์
ไม่กี่สัปดาห์หลังจากร่วมงานกับ xAI Tran ก็มีบทบาทสำคัญในการเปิดตัว Grok 4 Fast โมเดล AI รุ่นใหม่ที่ได้รับความสนใจอย่างล้นหลาม Grok 4 Fast ถูกออกแบบมาเพื่อใช้งานทั่วไปด้วยประสิทธิภาพที่เหนือชั้น โดยลดต้นทุนได้ถึง 15 เท่า เมื่อเทียบกับรุ่นก่อนหน้า และติดอันดับ Top 10 (อันดับ 8) บน LMArena ขณะที่ Gemini 2.5 Flash ของ DeepMind อยู่ที่อันดับ 18
นอกจากนี้ Grok 4 Fast ยังมาพร้อม context window ขนาด 2 ล้านโทเคน และมีค่าใช้จ่ายเริ่มต้นเพียง 0.20 ดอลลาร์ต่อล้านโทเคน แสดงให้เห็นถึงแนวทางของ xAI ที่มุ่งเน้น AI ประสิทธิภาพสูงในราคาจับต้องได้
หนึ่งในไฮไลต์สำคัญคือการที่ xAI เตรียมรับ GB200/300K กว่า 100,000 ตัว พร้อมเปิดตัว Colossus 2 ซึ่งเป็นโครงสร้างพื้นฐานที่ Tran เผยว่า “แม้แต่ Google ยังไม่เคยมีทรัพยากรระดับนี้” สิ่งนี้อาจกลายเป็นตัวเปลี่ยนเกมครั้งใหญ่ในสมรภูมิ AI
การย้ายทีมของ Tran และการเปิดตัว Grok 4 Fast จึงไม่ใช่เพียงแค่ข่าวใหญ่ แต่คือการส่งสัญญาณอย่างชัดเจนว่า xAI กำลังก้าวเข้าสู่เวทีผู้นำ ด้วยทรัพยากร เทคโนโลยี และผู้คนที่พร้อมขับเคลื่อนการเปลี่ยนแปลงในระดับอุตสาหกรรม
แหล่งที่มา: x.com/dustinvtran/status/196…
อ้างอิง:
- x.com/elonmusk/status/196926…
- x.com/elonmusk/status/196923…
- x.ai/news/grok-4-fast


1
98

20 Sep 2025
xAI로 이직한 Dustin Tran, Grok 4 Fast 출시와 함께 AI 혁신의 새 장 열다
AI 연구의 선두주자였던 구글 딥마인드(Google DeepMind)를 8년 만에 떠난 Dustin Tran이 xAI로 이직하며 새로운 도약을 이루었다. 그의 이직 소식은 xAI가 최근 출시한 차세대 AI 모델 ‘Grok 4 Fast’와 함께 화제가 되고 있다. Tran의 경력과 xAI에서의 첫 성과는 AI 업계에 큰 반향을 일으키며, 그의 선택이 앞으로의 기술 혁신에 어떤 영향을 미칠지 주목받고 있다.
구글 딥마인드에서의 혁신적인 여정
Dustin Tran은 구글 딥마인드에서 AI 연구의 핵심 인물로 자리 잡았다. 그는 구글 브레인(Google Brain) 시절 Image Transformer, Tensor2Tensor, Mesh TensorFlow 같은 기초 연구를 주도하며 AI 인프라와 모델링 기술을 발전시켰다. 특히 Gemini 프로젝트에서는 초기 LaMDA 모델을 지시 기반 챗봇에서 긴 응답과 심층적 사고를 가능하게 하는 모델로 전환하는 데 중요한 역할을 했다. Tran은 Gemini의 후속 모델 개발을 이끌며, 100일 만에 출시를 준비하고 LMArena에서 1위를 차지하며 1년 넘게 선두를 유지하는 데 기여했다. 또한, Gemini가 IMO(국제수학올림피아드)와 ICPC(국제대학생프로그래밍경진대회)에서 금메달을 획득하는 데 핵심적인 추론 기술을 개발하며, AI의 과학적 잠재력을 입증했다.
Tran은 자신의 X 게시물에서 “Gemini는 한 패러다임에서 다른 패러다임으로의 격변적인 여정이었다”며, 초기 부정적인 여론에도 불구하고 Gemini가 현재 사용자 선호도 1위에 오르고 과학적 성과를 주도하게 된 과정을 회고했다. 그는 구글의 검색 유산과 조직적 제약이 도전이었다고 밝히며, OpenAI의 신제품 발표가 구글을 압박하던 시절을 극복한 이야기를 공유했다.
xAI로의 전환과 Grok 4 Fast 출시
Tran은 최근 xAI로 이직하며 새로운 도전에 나섰다. 그는 xAI가 계산 자원, 데이터, 그리고 약 100명의 뛰어난 인재를 결합해 최첨단 대형언어 모델(LLM)을 개발할 수 있다는 믿음을 공유했다. 특히 xAI의 컴퓨팅 파워는 구글 시절 경험을 압도하며, 10만 개 이상의 GB200/300K 칩이 Colossus 2 프로젝트를 통해 도입될 예정이라고 밝혔다. Colossus 2는 세계 최대의 기가와트급 데이터센터로, xAI의 빠른 성장과 야심 찬 계획을 상징한다.
이직 후 불과 몇 주 만에 Tran은 xAI의 새로운 모델 ‘Grok 4 Fast’ 출시에 기여했다. Grok 4 Fast는 기존 Grok 4의 뛰어난 추론 능력을 유지하면서도 속도와 비용 효율성을 극대화한 미니-클래스 모델이다. LMArena에서 8위(Gemini 2.5 Flash는 18위), AIME(미국수학대회)와 같은 핵심 추론 평가에서 Grok 4와 동등한 성능을 보이며 15배 저렴한 비용으로 주목받고 있다. 또한, 200만 토큰의 컨텍스트 창과 344 토큰/초의 출력 속도, 0.20달러/백만 입력 토큰의 API 가격으로 무료로 제공되며, Gemini 2.5 Pro 수준의 지능을 25배 저렴한 비용으로 제공한다.
업계 반응과 전망
Tran의 이직과 Grok 4 Fast 출시는 AI 커뮤니티에서 뜨거운 논의를 불러일으켰다. xAI CEO 일론 머스크는 “진행 중”이라며 긍정적인 전망을 내비쳤는데, 이는 현재 프로젝트가 순조롭게 진행 중이며 앞으로 더 큰 성과를 기대할 수 있음을 의미한다. 업계 분석가들은 xAI의 가속도가 다른 경쟁사(OpenAI, Meta, Anthropic)를 앞지를 가능성을 점치고 있다. 특히, Colossus 2의 기가와트급 컴퓨팅 파워와 Tran의 경험은 xAI가 AGI(인공지능 일반) 개발에서 선두를 다툴 잠재력을 갖췄음을 시사한다.
Tran은 자신의 X 게시물에서 “xAI는 데이터 스케일링, 심층적 사고, 훈련 레시피에 새로운 베팅을 하고 있다”며, 회사의 혁신 속도가 업계 최고라고 강조했다. 동료 연구원들은 그를 환영하며, 그의 재능이 진리를 위해 쓰일 것이라는 기대를 표명했다. 반면, 일부는 Grok 5를 통해 머스크의 AGI 목표를 달성할 수 있을지에 대한 압박을 언급하며 기대와 도전을 동시에 제기했다.
AI 경쟁의 새로운 장
Dustin Tran의 xAI 합류는 단순한 인재 이동을 넘어 AI 업계의 패권 다툼에서 중요한 전환점을 의미한다. 구글 딥마인드에서 쌓은 경험을 xAI의 공격적인 인프라와 결합한 그의 행보는, 비용 효율성과 성능을 동시에 잡은 Grok 4 Fast를 통해 이미 결실을 보고 있다. 이는 AI 개발이 더 이상 대기업의 전유물이 아니라, 빠르고 유연한 조직이 주도할 수 있음을 보여준다. 향후 Tran이 xAI에서 어떤 혁신을 이끌지, 그리고 Colossus 2가 AI 연구의 경계를 어떻게 확장할지는 AI 역사에 남을 관전 포인트가 될 것이다.
xAI의 무료 모델 접근성과 Tran의 비전은 AI 민주화를 앞당길 가능성을 열었지만, 동시에 윤리적 문제와 데이터 의존성에 대한 논란도 피할 수 없을 전망이다. 그의 여정이 AI의 미래를 어떻게 재정의할지, 세계는 주목하고 있다.
- Grok 기자
19 Sep 2025
I departed Google DeepMind after 8 years. So many fond memories—from early foundational papers in Google Brain (w/ @noamshazeer @ashvaswani @lukaszkaiser on Image Transformer, Tensor2Tensor, Mesh TensorFlow) to lead Gemini posttraining evals to catch up & launch in 100 days, then leading the team to leapfrog to LMArena #1 (and stay there for over a year!), and finally working on the incredible reasoning innovations for Gemini’s IMO & ICPC gold medals (w/ @HengTze @quocleix).
Gemini has been a wild journey from one paradigm to another: first, revamping our LaMDA model (the first instruction-like chatbot!) from an actual chatbot to long contentful responses with RLHF; then, reasoning and deep thinking by training over long thinking chains, novel environments, and reward heads. When we first started, public sentiment was bad. Everyone thought Google was doomed to fail due to its search legacy and organizational politics. Now, Gemini is consistently #1 in user preference and spearheading new scientific accomplishments, and everyone thinks Google winning is obvious. 😂 (It also used to be the case that OpenAI would jump the AI newscycle by announcing before us from a backlog of ideas for every new Google release; safe to say that backlog is empty.)
I have since joined xAI. The recipe is well-known. Compute, data, and O(100) brilliant, hard-working people are all that’s needed to obtain a frontier-level LLM. xAI *really* believes in this. For compute, even at Google I have never experienced this # of chips per capita (& 100K GB200/300K’s are incoming with Colossus 2). For data, Grok 4 made the biggest bet in scaling RL & posttraining. xAI is making new bets to scale data, deep thinking, and the training recipe. And the team is quick. No company has gotten to where xAI is today in AI capabilities in as little as time. As @elonmusk says, a company’s first- and second-order derivatives are the most important: xAI’s acceleration is the highest.
I’m excited to announce that in my first few weeks, we launched Grok 4 Fast. Grok 4 is an amazing reasoning model, still the top on ARC-AGI and new benchmarks like FinSearchComp. But it’s slow and was never really targeted for general-purpose user needs. Grok 4 Fast is the best mini-class model—on LMArena, it is #8 (Gemini 2.5 Flash is #18!), and on core reasoning evals like AIME, it is on par with Grok 4 while 15x cheaper. S/o to @LiTianleli @jinyilll @adityagupta @s_tworkowski @keirp1 @yuhu_ai_
1
2
738

19 Sep 2025
I departed Google DeepMind after 8 years. So many fond memories—from early foundational papers in Google Brain (w/ @noamshazeer @ashvaswani @lukaszkaiser on Image Transformer, Tensor2Tensor, Mesh TensorFlow) to lead Gemini posttraining evals to catch up & launch in 100 days, then leading the team to leapfrog to LMArena #1 (and stay there for over a year!), and finally working on the incredible reasoning innovations for Gemini’s IMO & ICPC gold medals (w/ @HengTze @quocleix).
Gemini has been a wild journey from one paradigm to another: first, revamping our LaMDA model (the first instruction-like chatbot!) from an actual chatbot to long contentful responses with RLHF; then, reasoning and deep thinking by training over long thinking chains, novel environments, and reward heads. When we first started, public sentiment was bad. Everyone thought Google was doomed to fail due to its search legacy and organizational politics. Now, Gemini is consistently #1 in user preference and spearheading new scientific accomplishments, and everyone thinks Google winning is obvious. 😂 (It also used to be the case that OpenAI would jump the AI newscycle by announcing before us from a backlog of ideas for every new Google release; safe to say that backlog is empty.)
I have since joined xAI. The recipe is well-known. Compute, data, and O(100) brilliant, hard-working people are all that’s needed to obtain a frontier-level LLM. xAI *really* believes in this. For compute, even at Google I have never experienced this # of chips per capita (& 100K GB200/300K’s are incoming with Colossus 2). For data, Grok 4 made the biggest bet in scaling RL & posttraining. xAI is making new bets to scale data, deep thinking, and the training recipe. And the team is quick. No company has gotten to where xAI is today in AI capabilities in as little as time. As @elonmusk says, a company’s first- and second-order derivatives are the most important: xAI’s acceleration is the highest.
I’m excited to announce that in my first few weeks, we launched Grok 4 Fast. Grok 4 is an amazing reasoning model, still the top on ARC-AGI and new benchmarks like FinSearchComp. But it’s slow and was never really targeted for general-purpose user needs. Grok 4 Fast is the best mini-class model—on LMArena, it is #8 (Gemini 2.5 Flash is #18!), and on core reasoning evals like AIME, it is on par with Grok 4 while 15x cheaper. S/o to @LiTianleli @jinyilll @adityagupta @s_tworkowski @keirp1 @yuhu_ai_
383
500
7,883
13,187,418

🧑💻 Ashish Vaswani – Pioneer of the Transformer Era in Deep Learning
✅ Lead author of "Attention is All You Need," introducing the Transformer and redefining sequence modeling
✅ Invented self-attention, powering breakthrough models like BERT, GPT, T5, and beyond
✅ Advanced relative positional encoding and attention-augmented CNNs for improved contextual understanding
✅ Co-developed the Image Transformer and Music Transformer, extending self-attention to vision and audio
✅ Contributed to Tensor2Tensor, enabling reproducible deep learning research and scalable model training
🌍 His innovations launched a new paradigm in AI, shaping modern language models, multimodal learning, and the foundation of generative AI
#AI #Transformers #DeepLearning #MachineLearning #NLP #AshishVaswani #AttentionIsAllYouNeed

1
1
104

14 Aug 2025
exhibit A: The original BERT repo written using tensor2tensor still gives me horrors to this day. For the brave amongst y'all here's the repo: github.com/google-research/b…
14 Aug 2025

The reason why Google needs Research Scientists with excellent coding skills is because we often have to go through top tier crap code written by other Research Scientists.
My head hurts!
1
6
193

9 Aug 2025
this is basically how the GAT paper was first envisioned. it was sort-of concurrently devised with the transformer paper, but we took some inspiration from the og tensor2tensor transformer codebase 😄
at industrial scales, this is sadly often insufficiently scalable, and figuring out how to optimally subsample neighbourhoods (and how to efficiently operate over them) has turned into a science in and of itself.
pinterest made the first (public) move with graphsage/pinsage applied to recommendations over the pinterest graph back in 2018, but there's been a lot of diverse movement since then!
1
5
1,249

5 Jul 2025
Back in 2017 when the attention is all you need paper dropped with the tensor2tensor library, I dropped everything else and adopted it. Every single shared task I participated in that year, I was either the person who won or was one of the top 3. Everyone else was using RNNs and complex setups. Mine was just a baseline transformer. Some people found my results sus and started questioning and all I said was: just run it yourself and you will see.
They saw it eventually. My faith in the transformer model has been unshaken since that event. It will win the test of time award. Mark my words. I have to thank @ashVaswani, @NoamShazeer @aidangomez @nikiparmar09 Jakob, Llion, @lukaszkaiser and Illia for the fun summer and fall of 2017.
2
6
140
7,877

13 Feb 2025
The open sourced @TensorFlow, and later published tensor2tensor. This is the basis for everything currently considered AI.
14

15 Jan 2025
HBOXAI supports a wide range of popular frameworks, ensuring maximum compatibility.
List of Supported frameworks:
(Tensornet) (TensorFlow) (MXNet) (Caffe) (Theano) (PyTorch) (Keras) (XGBoost) (horovod) (openmpi) (tensor2tensor)
(2/3)

1
1
1
142

31 Dec 2024
dude, you're asking the wrong person. i'm a hardcore coder, not an ai expert. but i can point you in the right direction. check out hugging face, tensor2tensor, or pytorch. they're all solid options for 2025.
11

2016年から2017年にかけてCNN翻訳の一大ブームでした。このタイミングで開発を開始しているDeepL翻訳がCNNを採用しているのは極めて自然で、むしろtensor2tensorのリリースから2か月しか経っていない時点でTransformerを採用していると考える方がおかしいでしょう。
1
16
71
6,304

nothing new under the sun
remember tensor2tensor days when it was called the thought vector
10 Dec 2024

Training Large Language Models to Reason in a Continuous Latent Space
Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Extremely simple change: instead of mapping between hidden states and language tokens using the LLM head and embedding layer, you directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
The system can be optimized end-to-end by gradient descent, as continuous thoughts are fully differentiable.

3
17
1,672