
Google’s Gemini-SQL2 turns natural language into executable SQL and reaches 80.04% on BIRD. Higher execution accuracy shifts value from fluent answers to database-grounded action. Correctness decides utility. #GeminiSQL2 #TextToSQL

9

12h
AI Insider
Google launches Gemini-SQL2 topping BIRD text-to-SQL benchmark at 80.04%
- Powered by Gemini 3.1 Pro.
- Achieved 80.04% execution accuracy on the BIRD benchmark.
- Promises more reliable natural language querying for BigQuery, Looker, and Google Cloud data services.
#AJ #AIxAJ #AIInsider #GeminiSQL2 #TextToSQL #GoogleAI
Jun 12
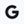
🚀 Introducing Gemini-SQL2, our breakthrough text-to-SQL capability powered by Gemini 3.1 Pro! We've achieved state-of-the-art results on the highly competitive BIRD benchmark, translating natural language into execution-ready SQL queries. 🧵👇

1
24

Jun 12
🚨 𝗚𝗼𝗼𝗴𝗹𝗲 𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗲𝘀 𝗚𝗲𝗺𝗶𝗻𝗶-𝗦𝗤𝗟𝟮, 𝗧𝗲𝘅𝘁-𝘁𝗼-𝗦𝗤𝗟 𝗕𝗿𝗲𝗮𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵
Google Research released Gemini-SQL2, a text-to-SQL capability powered by Gemini 3.1 Pro. It achieved 80.04% execution accuracy on the BIRD benchmark, state-of-the-art.
BIRD tests execution-verified accuracy against real complex databases, not just syntax matching.
Gemini-SQL2 handles multi-table joins, aggregations, data subtlety, and dense enterprise contexts.
Google plans to integrate it across its data and cloud services for natural language querying.
#Google #Gemini #TextToSQL #BIRDBenchmark #AIResearch
Google Research on X
───
🤖 𝗙𝗼𝗿 𝗺𝗼𝗿𝗲 𝗔𝗜 𝗻𝗲𝘄𝘀 𝗮𝗻𝗱 𝘀𝘁𝗼𝗿𝘆 𝘀𝗼𝘂𝗿𝗰𝗲𝘀, 𝘀𝗲𝗮𝗿𝗰𝗵 "𝗚𝗲𝗻𝗔𝗜𝗦𝗽𝗼𝘁" 𝗼𝗻 𝗧𝗲𝗹𝗲𝗴𝗿𝗮𝗺

ALT News article image
4
39

"A trillion dollars is arrayed against us." Stonebraker at 82, betting SQL should orchestrate data queries, not LLMs.
youtube.com/shorts/3PPwQViNy…
#AgenticAI #TextToSQL #SQL
8

Jun 8
Looking to scale this work to a full BIRD benchmark evaluation (12,751 queries).
Current result: 60.82% on the BIRD Dev Set using DeepSeek V4 and a custom multi-agent NL2SQL pipeline.
If any model providers or inference platforms are interested in supporting independent benchmark research with API credits or infrastructure, I'd love to connect and share more details.🫶
@deepseek_ai @OpenRouterAI @togethercompute @FireworksAIHQ @GroqInc @xai
#BIRDSQL #TextToSQL #LLM #AIResearch
Jun 8

Built a multi-agent NL2SQL pipeline using DeepSeek and currently achieving 60.82% on the BIRD Dev Set.
Preparing for a full 12,751-query evaluation run and currently limited by API concurrency.
Would appreciate guidance on benchmark-scale quota requests and would be grateful for sponsorship/support for evaluation costs.
@deepseek_ai
1
1
72

Jun 7
Project page: sslab-cse-iitb.github.io/tec…
Paper: doi.org/10.1145/3769822
#SIGMOD2026 #Research #TextToSQL #NL2SQL #LLMs #Databases #IITBombay #AppliedAI
10

May 22
𝗧𝗲𝘅𝘁-𝘁𝗼-𝗦𝗤𝗟 𝗜𝘀 𝗡𝗼𝘁 𝗮 𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
Generating SQL is easy.
Guaranteeing trust, permissions, and stable semantics is the hard part.
AI should assist exploration.
Not become the runtime layer.
#ai #texttosql #llm #dataengineering

ALT “Text-to-SQL is not production architecture. Generating SQL is easy. Guaranteeing semantic consistency, permission safety, and deterministic analytical behavior is the hard part. Gaur provides the runtime and contract layer between AI-generated queries and production analytical systems — so dashboards, APIs, internal tools, and AI agents can consume governed analytical data safely.”
2
28

May 19
FINER-SQL adds to the growing conversation around Small Language Models (SLMs) as viable infrastructure for enterprise AI.
Rather than relying solely on massive and expensive models, the research explores how smaller models can be optimized for Text-to-SQL tasks, improving how AI interacts with databases while remaining more efficient and practical to deploy.
For organisations handling sensitive or regulated data, this shift matters. Smaller models create opportunities for AI systems that are more cost-effective, privacy-aware, and capable of operating closer to where data is stored, without sacrificing usability.
As enterprise AI adoption grows, the future may not belong only to bigger models, but to smarter, more specialized ones.
Read full paper >> arxiv.org/abs/2605.03465
@Griffith_Uni @HumboldtUni @AmandaT8597 @VinUniversity @universitequeen @Shirley_manoto
#EqualyzAI #SLM #SmallLanguageModels #EnterpriseAI #TextToSQL #DataPrivacy
19
91

Data Exploration & Database Tools
Kanaries/pygwalker → Turn any dataframe into an interactive Tableau-like UI → github.com/Kanaries/pygwalke…
Best industry: Business intelligence, data analytics, fintech, internal tools, startups
#TextToSQL #DataExplorer #OpenSource #DataScience
2
2
122

May 4
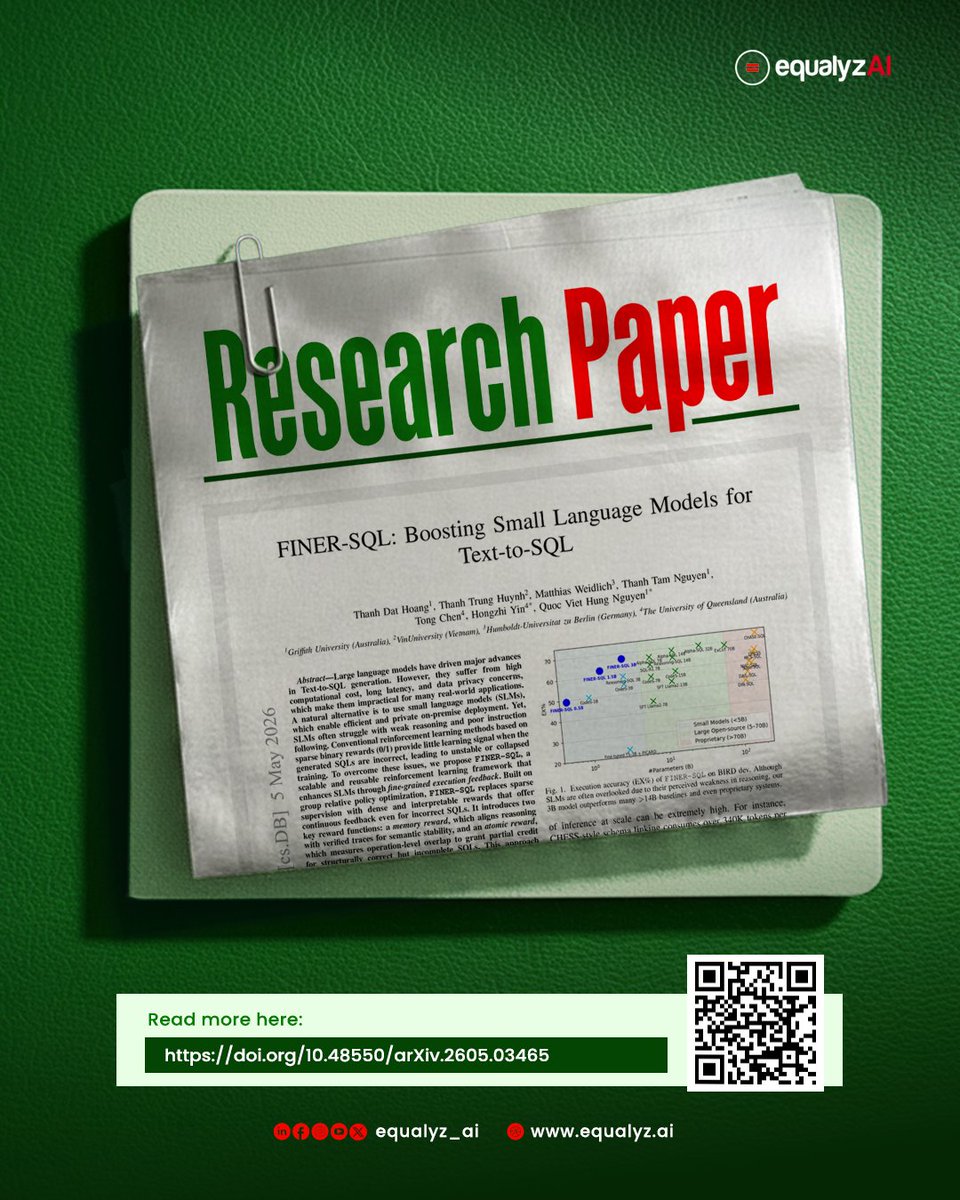
Your text-to-SQL problem is not the LLM. 📊
On academic benchmarks, top models exceed 85% accuracy. Point them at real enterprise data, and accuracy collapses to 10.8%.
The reason: enterprise warehouses encode meaning the schema can't reveal — ambiguous business terms, 800-table catalogs with tribal naming, business logic that lives in someone's head. A general-purpose LLM substitutes its best guess and ships confidently wrong answers.
We benchmarked the extent to which semantic context changes the outcome. Same LLM (Sonnet 4.5), same data, same questions. The only variable: whether Collate's Semantic Context Graph was in scope.
→ Spider 2.0-Snow accuracy: 10.8% → 76.5% (7.1x lift)
→ The same semantic foundation grounds Collate AI Analytics
7.1x more accurate on enterprise text-to-SQL. The bottleneck isn't the model — it's the meaning the model has access to.
Read the details: getcollate.io/blog/your-text…
#TextToSQL #SemanticContext #AIAnalytics #Benchmark #CollateAI
1
2
3
145

Apr 21
piglets is a text-to-SQL toolkit.
Current features:
Planning
Pruning
More features coming soon.
All LLM providers supported (via @LangChain).
Databases:
@googlecloud BigQuery
@duckdb
@motherduck
@Snowflake
#texttoSQL
github.com/mportdata/piglets
2
3
100

Excited to share that two of our papers have been accepted to #ACL 2026 🎉
Happy to see this work from Oracle, together with colleagues and collaborators, recognized at #ACL this year.
#ACL2026 #Oracle #NLP #LLMs #TextToSQL #MultimodalAI #Evaluation #AIResearch
3
1
18
803

Jan 31
Cortex Analyst におけるメタデータ露出の制御とAPI駆動によるText-to-SQL精度評価の確立 zenn.dev/dataheroes/articles…
Snowflake Cortex Analystの精度向上ガイドを公開しました❄️
サポートとの議論で分かった3つの重要ポイント:
✅ メタデータ制御が精度を左右
✅ API経由のテストが推奨
✅ LLMの内部は不可視
実践的なアクションプランも含めて解説しています
#Snowflake #LLM #TextToSQL
8
38
4,747

Jan 29
昨天一个团队付费给我,让我给他们做了场AI工作流分享
索性整理成文,如果你也在摸索怎么把AI真正用起来,这篇可能会帮到你
我日常在用的AI工具栈:
聊天: ChatGPT、Gemini、Qwen
学习: NotebookLM(Google出品,专门用来啃长文档和视频,能把任意YouTube视频2分钟转成信息图,还能生成播客式音频复盘)
输出: YouMind(写作agent,很方便)
编程: Antigravity(前端)、Codex(后端)——Antigravity是Google刚推的AI原生IDE,集成Gemini 3 Pro、Claude 4.5等顶级模型,关键是免费
图片: Nano Banana Pro(Google的图像生成神器,角色一致性碾压同类产品)、Lovart(设计agent)
1.如何让AI真正听懂你
很多人用AI就是一句话扔过去,看天吃饭
其实在提问前,你得先想清楚:这个问题属于哪个象限
我习惯用"四象限法则"做判断:
共识区(明确的事实性任务):直接下指令
比如"把这份数据清洗成表格"
盲区(你不知道的领域):让AI先做背景科普
私密区(你的独特经验):需要你先输入足够的上下文
未知区(探索性问题):用苏格拉底式提问,让AI反问你
一个小技巧:让AI基于思维框架回答,效果会好很多
比如要求它用"SMART原则"拆解目标,或者用"第一性原理"分析问题本质
SMART、5W2H、黄金圈、奥卡姆剃刀、二八法则......这些框架就是AI的"操作系统",你给它装上系统,它才能跑得顺
2.写提示词不是玄学
文本创作类
先用Deep Research做调研(比如我要写儿童绘本提示词,就让AI先调研"好绘本的核心要素是什么")
告诉AI:"我要写一个XX提示词,我会提供调研资料,你帮我生成结构化的元提示词"
拿到初稿后,把实际生成结果反馈给AI,说哪里不对,迭代优化
图片类
找对标图,发给AI,要求生成JSON格式的元提示词(限制800字),然后改主体结构
基本能复刻90%的风格
如果目标模糊:别硬憋提示词,让AI反过来问你
"你想达成什么效果""面向什么人群""有没有参考案例"——让AI帮你理清思路,再动手写
3. AI编程的正确姿势
我遵循Spec规范驱动开发:PRD → 技术文档 → 开发计划 → 编码 → 测试
具体流程:
写PRD:和AI聊需求,但不看第一版,直接开始PUA(不断追问、挑刺),逼它把PRD打磨到位
快速原型:用AI Studio的Build模式开发前端功能,跑通交互逻辑
代码调优:把代码拉到Antigravity里精修
自动化测试:让AI写测试用例,用chrome-dev-tool MCP跑自动化
后端开发:先让AI总结文档文件夹,然后读取私域知识库,再开始写代码
核心原则:上下文越清晰,AI生成质量越高
架构设计必须提前做好,否则AI写出来的代码就是一堆补丁
4. 企业落地AI,从哪些场景切
目前市面上跑通的主要是这几类:
问答类: 企业内知识库问答、ToC智能客服
审核类: 合同审核、流程审核
写作类: PRD、研报、季度汇报、规划文档
查询类: TextToSQL(比如老板说"给我看第一季度报表",AI直接查数据库)
如果你们公司想试水,可以看看BISHENG这个开源平台(
专注企业办公场景的LLM应用开发平台,Apache 2.0协议,完全免费可商用,部署一套就能快速搭建各种办公AI应用)
5.我的AI信息源
WaytoAGI飞书知识库(国内最大的AI开源知识库,500万 访问量,内容覆盖从基础概念到实战案例,更新频率高)
AIBase(AI导航 资讯一体化,中文友好,适合快速找工具)
自建外网AI信息抓取站(针对个人需求定制)
最后一句:
你的思维清晰,它帮你提速;你的思维混乱,它只会帮你批量生产垃圾
别指望AI替你思考,但可以让它替你干活
比如这篇文章我直接把我的演讲稿发给ai,他会帮我整理出来,但是质量还是依赖于语料
12
31
154
14,352

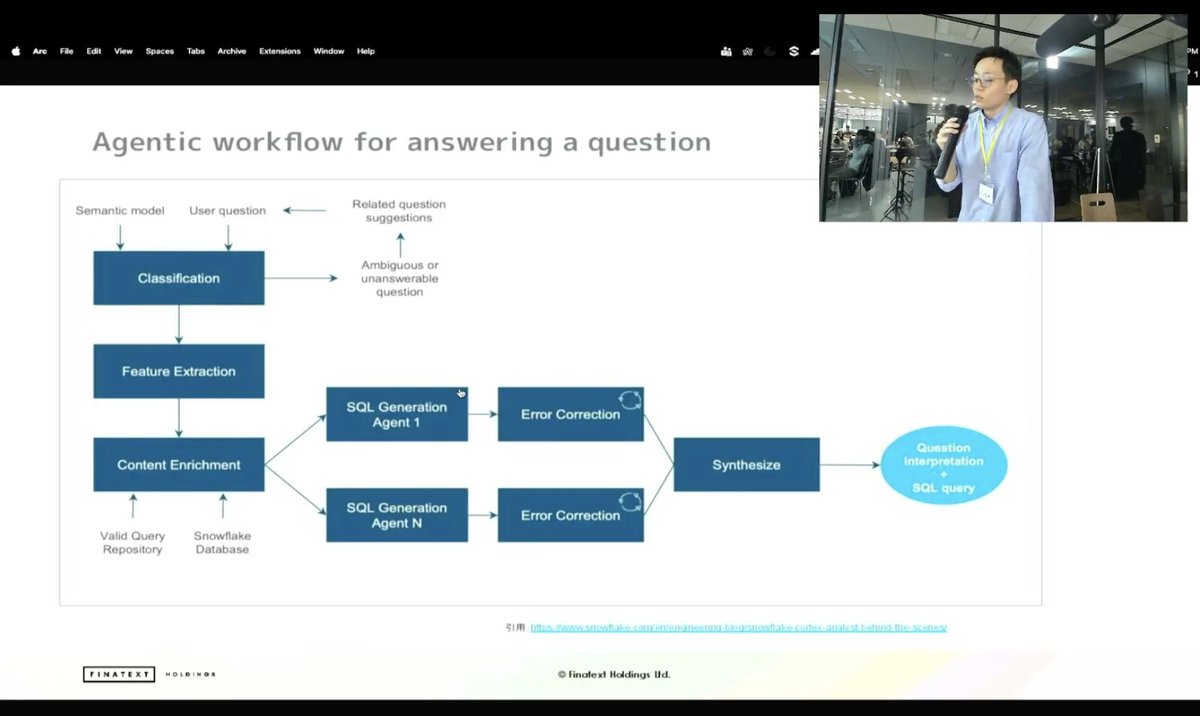
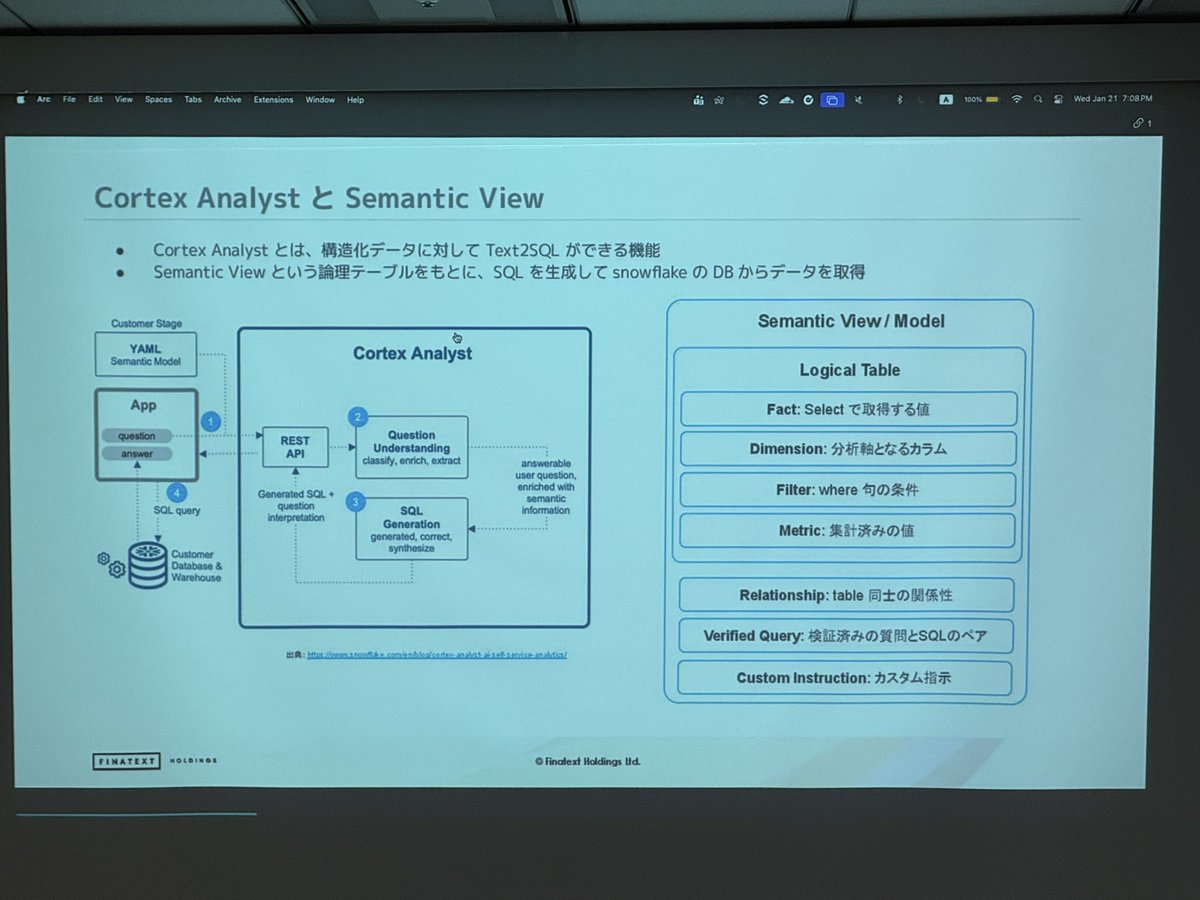

面白かったです。
テーブル定義書だけでは絶対に情報足りないから、TEXTtoSQLにかなり懐疑的でしたが、このように考えるのか。
これがファイナルアンサーかはともかく方向性としてとても参考になります。

こんなアプローチもあるとは!
note.com/dev_onecareer/n/n45…
1
4
136

28 Nov 2025
今天在公司给同事们做了一场简短的AI分享会,我说了一下我日常如何用AI的,同事们觉得都很有收获,在这里也分享给大家。
日常工具
聊天工具: ChatGPT,Gemini,Qwen
学习工具: NotebookLM
输出工具:YouMind
编程工具:后端Codex,前端Antigravity
图片工具:Nano Banana Pro,Lovart
如何使用AI
和AI聊天
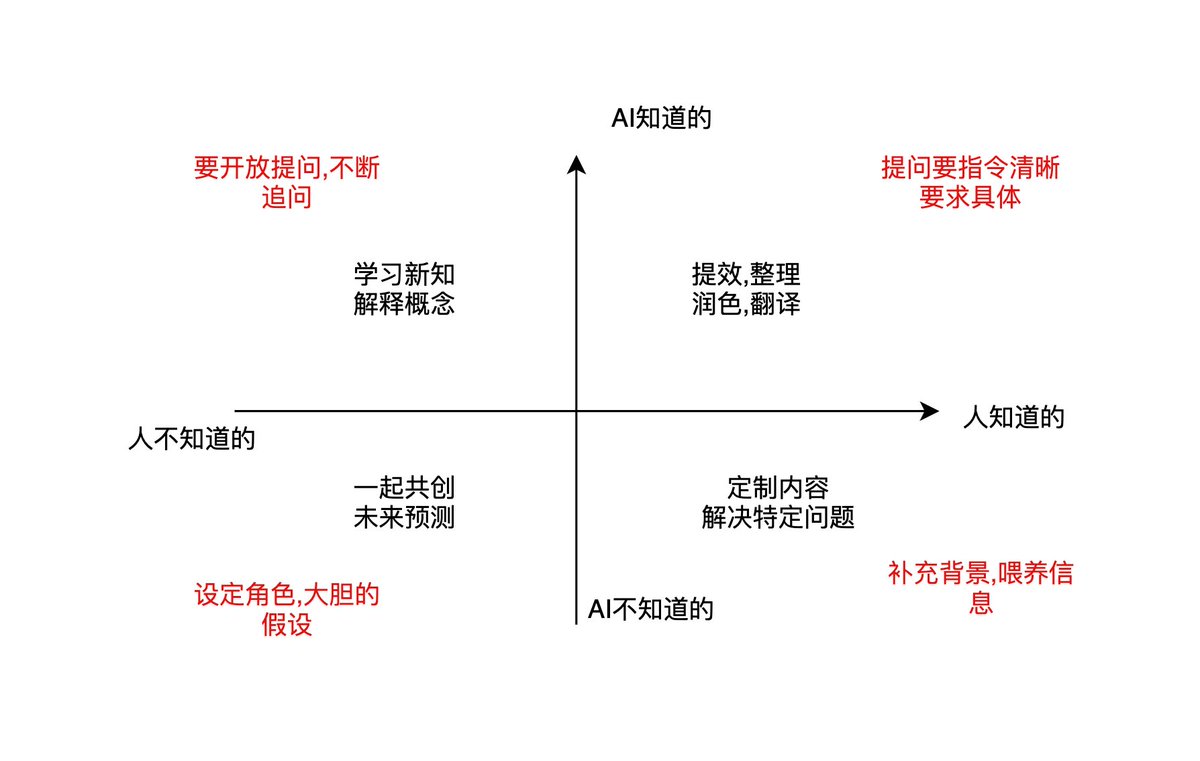
在聊天之前我要先想清楚我要问的问题属于什么维度,这里参照四象限,看图片一。
根据维度来选择沟通的方式,比如我要AI帮我做个数据清洗,这属于共识区,我直接把数据给他,让他给我清洗一下,提取我要的结构就可以了。
这里有个小技巧,我们让AI回答的时候让他基于思维框架来回答会出奇的好,比如:
SMART,5W2H,黄金圈,第一性原理,金字塔原理,SWOT,奥卡姆剃刀,二八法则。
具体用法就太多了,我就不一一举例,大家可以给到AI让其分一些应用场景
写提示词
文本创作类
1. 先搜集相关资料,我会使用Deep Research,比如我要写一个儿童绘本提示词,我会让调研一下一个好的儿童绘本要有什么核心要素
2. 告诉AI我要写一个提示词,会提供什么,我需要得到什么,然后提供调研的资料,让其出一个结构化的元提示词
修改一下元提示词,然后去使用,把结果给到AI,说要改进的地方,不断迭代
图片类
找对标,然后发给AI,生成一个json的元提示词,限制800字,然后改里面的主体结构等等
基本能复刻90%
如果对于自己的目标比较模糊,我们要学会让AI对我们进行提问,就是让AI问我们问题,来理清目标再写提示词。
AI进行编程
遵循spec规范驱动开发的原则,先写PRD,然后技术文档,然后列计划然后开发,测试
1. 写PRD,我一般是通过和AI沟通,然后不断PUA ,就是说一下自己的需求,然后不看第一版,直接开始不断PUA,一般效果能好不少。图二
2. 使用aistudio的Build模式进行快速原型开发,只开发前端功能
3. 代码拉下来到Antigravity进行调优
4. 然后可以让写测试用例,使用 chrome-dev-tool MCP进行自动化测试
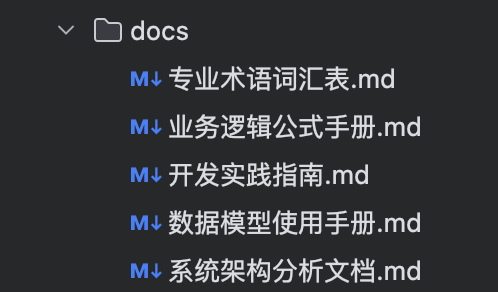
5.后端编写我会用提示词先总结一个文档文件夹,看图三,然后使用专有的规则,会先读取私域知识库,然后再进行开发。
这种代码采用率会很高,但是要求就是在架构层面需要提前设计好,反正宗旨就是上下文越清晰,越准确,AI生成的质量越好。
对于从0到1的项目,就直接按照Sepc规则,生成技术文档,然后一步一步执行
关于企业化落地方案
我了解到市面上就以下几类,比较火,大家可以从这里面找一些我们可以做的
问答类
主要是是企业内知识库问答和ToC的智能客服
审核类
合同审核,然后一些流程审核
写报告类
比如写PRD,研报,季度汇报,规划等等
问述类
TextToSQL这种,比如老板直接说一句要第一季度报表,会查询数据库这种
我觉得可以看一BISHENG这个产品,我觉得公司部署一个是非常好的
AI信息源
我的AI信息流主要来自于以下三个
1.Waytoagi飞书文档,Waytoagi应该是国内最大的一个AI社群了,知识库非常的全面
2. aibase 这个会有很多AI导航和新闻一体化的,中文友好
3.自己搭建了符合我个人需求的一个获取外网的AI最新信息的网站
三个链接都放在评论区了

44
431
1,466
158,383

21 Nov 2025
Tried out Gemini-3-Pro on our BIRD-SQL Verfied Dev Hidden Test sets. It’s the first general model which can break 70 🚀, getting surprisingly close to specialized SFT/RL models from @databricks and @Snowflake . Really impressive generalist performance 🔍✨
BTW, Gemini-SQL (from @googlecloud) is now the strongest single text-to-SQL model 🏆. If you’re also interested in how large specialized models are trained and how industry-level labs build these “monsters,” don’t miss them:👇
Gemini-SQL: cloud.google.com/blog/produc…
Databricks RLVR:
databricks.com/blog/power-rl…
Arctic-Text2SQL-R1:
snowflake.com/en/engineering…
#LLM #TextToSQL #NLP #Gemini #AI #Databases #SQL #GoogleCloud

2
4
296

17 Nov 2025
Text-to-SQLの“6つの壁”をAIエージェントで突破!
自然言語でのデータ分析がうまくいかない…そんな悩みをGoogle Cloudが解決します。
具体的な失敗パターンと解決策を解説!
詳細はこちら👇
medium.com/google-cloud/the-…
#TextToSQL #AIエージェント #GoogleCloud
1
3
166