
🌍 Proven Insights
Using this data, we've already been able to demonstrate that central bank statement sentiment actively predicts the Global Financial Cycle, rather than just responding to it.
🧵7/12 #OpenScience #DataScience #Research #NLP #TextMining
1
8
674
As economists, we've all faced the same bottleneck: applying modern #NLP and Large Language Models (LLMs) to central bank communications is often messy, irreproducible, and siloed.
My co-authors and I wanted to change that 💪🏽
🧵2/12 #CentralBanks #Research #TextData #TextMining
1
11
1,331

Biominer: A multi-modal system for automated mining of protein-ligand bioactivity data from literature
1. BIOMINER targets a practical bottleneck in drug discovery: bioactivity evidence is scattered across text, tables, and figures, and ligand structures are often reported as Markush definitions that require enumeration into exact molecules (SMILES) before the data are usable.
2. The key design choice is to explicitly decouple two hard problems that end-to-end LLM extraction tends to entangle: (a) biochemical semantic interpretation of bioactivity measurements, and (b) chemically valid ligand structure construction. BIOMINER runs these in parallel and then joins them via ligand coreference identifiers.
3. For chemical structures, BIOMINER introduces Chemical-Structure-Grounded Visual Semantic Reasoning (CSG-VSR): domain-specific perception models detect/recognize chemical depictions, an MLLM reasons over indexed depictions to infer scaffold–R-group relations and coreference, and deterministic chemistry tools (OPSIN, RDKit) perform the exact symbolic construction and Markush “zipping” into full enumerated molecules.
4. The system is implemented as an agentic pipeline: document parsing (MinerU) → chemical structure agent (MolDetv2 MOLGLYPH BIOMINER-INSTRUCT RDKit/OPSIN) and bioactivity measurement agent (BIOMINER-INSTRUCT with post-fusion across modalities) → post-processing/integration agent that produces protein–SMILES–value triplets.
5. To make evaluation systematic, the paper releases BIOVISTA, a benchmark curated from 500 PDBbind-referenced publications: 16,457 bioactivity entries and 8,735 unique chemical structures, with modality distribution heavily table-driven (72.5%), plus substantial figure (11.6%) and text (15.8%) content; 48.7% of structures involve Markush representations.
6. On BIOVISTA, BIOMINER reaches F1 = 0.323 for complete bioactivity triplets (precision 0.319, recall 0.328). A one-shot end-to-end baseline essentially fails (F1 ≈ 0.00042), supporting the paper’s argument that decomposition and tool-grounded symbolic construction are necessary for this task.
7. Component results highlight where the system is strong vs. where the field remains hard: bioactivity measurement extraction F1 = 0.626 (tables easiest; text/figures harder), ligand coreference-SMILES F1 = 0.528 (explicit structures better than Markush). Removing CSG-VSR collapses triplet F1 from 0.323 to 0.011, indicating Markush-aware structure resolution is central.
8. Error attribution suggests priorities for future work: bioactivity measurement extraction contributes 32.68% of triplet errors, OCSR 25.31%, Markush enumeration 15.91%. Chirality recognition is a major OCSR weakness (reported accuracy ~0.504 on chiral structures), and Markush recall drops notably with cross-modal R-group definitions and with three R-groups (combinatorial complexity).
9. Three applications demonstrate utility beyond benchmark scores: (a) large-scale mining from 11,683 European Journal of Medicinal Chemistry papers in ~3 days, extracting 226,076 triplets and enriching 82,262 with protein structures; pretraining GNN affinity models on this noisy-but-large dataset improves downstream RMSE by ~3.9% (and outperforms unsupervised or label-shuffled controls). (b) A human-in-the-loop workflow curates 1,592 high-quality NLRP3 data points from 85 papers in 26 hours (doubling ChEMBL’s NLRP3 set), improving QSAR early enrichment (average EF1% 38.6% over 28 model settings) and yielding 16 virtual-screening hit candidates with novel scaffolds. (c) Structure–bioactivity annotation on PoseBusters: HITL improves accuracy from 90.5% to 96.25% and reduces annotation time from 195.8 s to 35.0 s per entry (5.59x faster).
💻Code: github.com/jiaxianyan/BioMin…
📜Paper: arxiv.org/abs/2604.21508
#ComputationalBiology #DrugDiscovery #Bioinformatics #TextMining #MultimodalAI #LLM #Chemoinformatics #OCSR #Markush #QSAR #Dataset #Benchmarking

3
12
48
3,057

Original Article
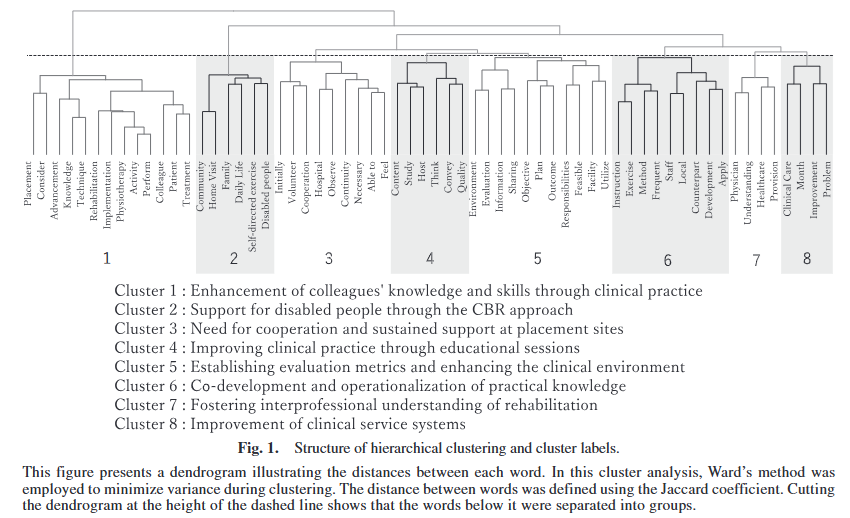
Structural Analysis of Activities by Japan International Cooperation Agency Volunteer Physiotherapists: Reconstructing Practice-based Knowledge through Text Mining
doi.org/10.1298/ptr.25-E1037…
#JICAVolunteerPhysiotherapists #PracticeBasedKnowledge #TextMining
2
180

A novel system is presented that enables the association of text mentions of functionally important residues with their corresponding counterparts in a PDB entry and reference UniProt accession #TextMining #LargeLanguageModels #TextAnnotations doi.org/10.1107/S20597983260…

1
3
238

Mar 27
📢 #highlycited paper
📚 #TextMining and #MultiAttributeDecisionMaking-Based #CourseImprovement in Massive Open Online Courses
🔗 mdpi.com/2076-3417/14/9/3654
👨🔬 by Pei Yang et al.
🏫 Chengdu University of Technology
#MOOC #deeplearning

1
2
86

Topics alone don’t reveal the full story.
Topic network analysis shows how themes connect across documents.
Learn how to build a BERTopic based topic network and identify hub topics in NetMiner.
👉 netminer.medium.com/topic-ne…
#TopicModeling #TextMining #NetworkAnalysis
1
1
505

Jan 20
Continuous validation keeps the #OpenAIREGraph reliable & trustworthy.
Each month the Graph reconnects with thousands of sources, rebuilds using #AI & #TextMining, & verifies identifiers like #DOIs, @ORCID_org & #ROR.
🔗 Learn more about this vital process shorturl.at/KvXtA

ALT The OpenAIRE Graph: Why Continuous Validation Matters
2
8
181

Jan 20
How can AI truly decode human emotion through language? 💭
This paper advances sentiment analysis beyond traditional embeddings via a hybrid deep learning framework uniting BERT’s contextual intelligence with CRNN’s hierarchical feature modeling.
🔬 Core Concept:
By integrating BERT’s semantic depth with CNN’s local pattern recognition and RNN’s temporal sequencing, this model captures linguistic nuance, polarity, and emotional flow—bridging lexical meaning and contextual sentiment.
📊 Methodology Highlights:
• Hybrid BERT embeddings enriched with polarity scores for sentiment precision
• CNN extracts local syntactic and semantic dependencies
• Bi-LSTM captures temporal progression in text
• The CRNN hybrid enhances contextual understanding and domain adaptability
🧠 Results & Benchmarks:
• 96% classification accuracy on IMDB movie review dataset
• Outperforms CNN, Bi-LSTM, and FastText architectures
• Demonstrates superior generalization across domains and datasets
💡 Scholarly Significance:
This research exemplifies how hybrid NLP architectures can unify semantic understanding and computational efficiency, advancing applications in affective computing, social media analytics, and automated opinion mining.
👥 Who it’s for:
• Researchers in Natural Language Processing & Deep Learning
• Computational linguists exploring hybrid architectures
• Data scientists in emotion AI & sentiment modeling
• Developers of AI-based media analytics tools
• Graduate scholars in AI, linguistics, and cognitive computing
📖 Read the full paper:
👉 worldscientific.com/doi/10.1…
@ACLMeeting @NeurIPSConf @EMNLPmeeting @iclr_conf @IEEEorg @GoogleDeepMind @OpenAI @MIT_CSAIL @AI4Good @StanfordAILab @ucl_nlp @AiTrendsCoded @NatMachIntell @ConjectureAI @AIMagazine_BC @FrontComputSci @AIatMeta @AIHubOrg @unc_ai_group @RealWorldAINews @worldscientific @BioMedCentral @TechReview @science
#NLP #SentimentAnalysis #DeepLearning #BERT #CRNN #HybridAI #NaturalLanguageProcessing #AffectiveComputing #TextMining #LanguageModel #MachineLearning #AIResearch #ContextualEmbeddings #PolarityDetection #EmotionAI #ComputationalLinguistics #NeuralNetworks #OpinionMining #HybridLearning #AIDrivenInsights

2
141

Jan 19
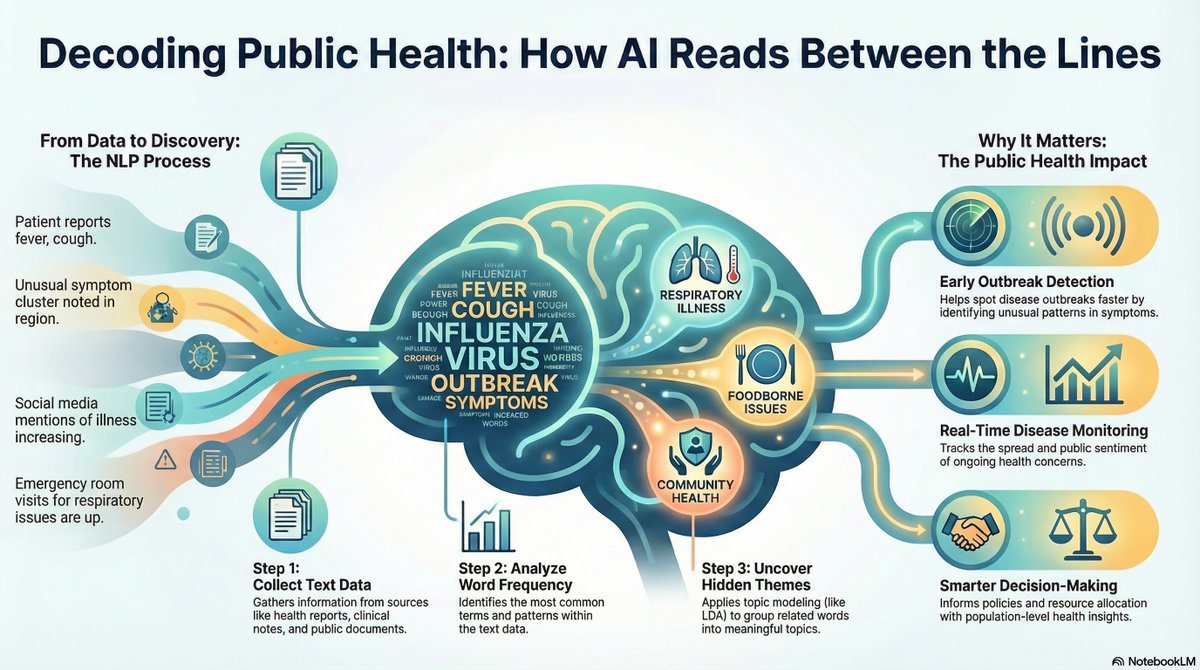
How NLP Detects Public Health Trends from Text Data youtu.be/3iK-5lXoXuQ?si=ixsA… via @YouTube
🎧Listen to the audio version here: podcasts.apple.com/us/podcas…
#naturallanguageprocessing #nlp #datascience #publichealth #textmining #topicmodeling #LDA #population
2
35

1️⃣ Join Inbar Bahat as she presents our findings on "Local Housing and Mortgage Markets Newspaper Sentiment." 🗓 Mon, Jan 5 | 10:15 AM | Convention Center Room 304
#ASSA2026 #AEA2026 #Economics #TextMining #MachineLearning #ASSA #AEA @AEAInformation @ASSAMeeting
🧵 2/3

1
3
6
1,324

31 Dec 2025
"No one, no machine, not even the universe itself can defy the laws of the universe."
#AI #ASI #AGI #robot #CyberPhysicalSystems #singularity #WW3 #QuantumComputing #PredictiveAnalytics #TextMining #5G

1
2
41
31 Dec 2025
"Wise people realize that rulers are fighting over things that no longer have any practical benefit."
#AI #ASI #AGI #robot #CyberPhysicalSystems #singularity #WW3 #QuantumComputing #PredictiveAnalytics #TextMining #5G

1
1
1
35
31 Dec 2025
"It doesn't matter if it's astronomy, numbers, or reptilians, just blame it on something you can't prove or anything."
#AI #ASI #AGI #robot #CyberPhysicalSystems #singularity #WW3 #QuantumComputing #PredictiveAnalytics #TextMining #5G

1
1
41
31 Dec 2025
“In the AI arms race, the high‑value targets ultimately become the very people driving it.”
#AI #ASI #AGI #robot #CyberPhysicalSystems #singularity #WW3 #QuantumComputing #PredictiveAnalytics #TextMining #5G

1
2
32
7 Dec 2025
"The extinction of humankind will be inscribed in cosmic history as a case of self-destruction driven by selfish genes."
#AI #ASI #AGI #robot #CyberPhysicalSystems #singularity #WW3 #QuantumComputing #PredictiveAnalytics #TextMining #5G

2
26
5 Dec 2025
Continuous validation keeps the #OpenAIREGraph reliable and trustworthy.
Each month the Graph reconnects with thousands of sources, rebuilds using #AI & #TextMining, & verifies identifiers like #DOIs, @ORCID_org & #ROR.
Learn more about this vital process: tinyurl.com/3748ccuj

ALT The OpenAIRE Graph: Why Continuous Validation Matters
4
7
234

14 Nov 2025
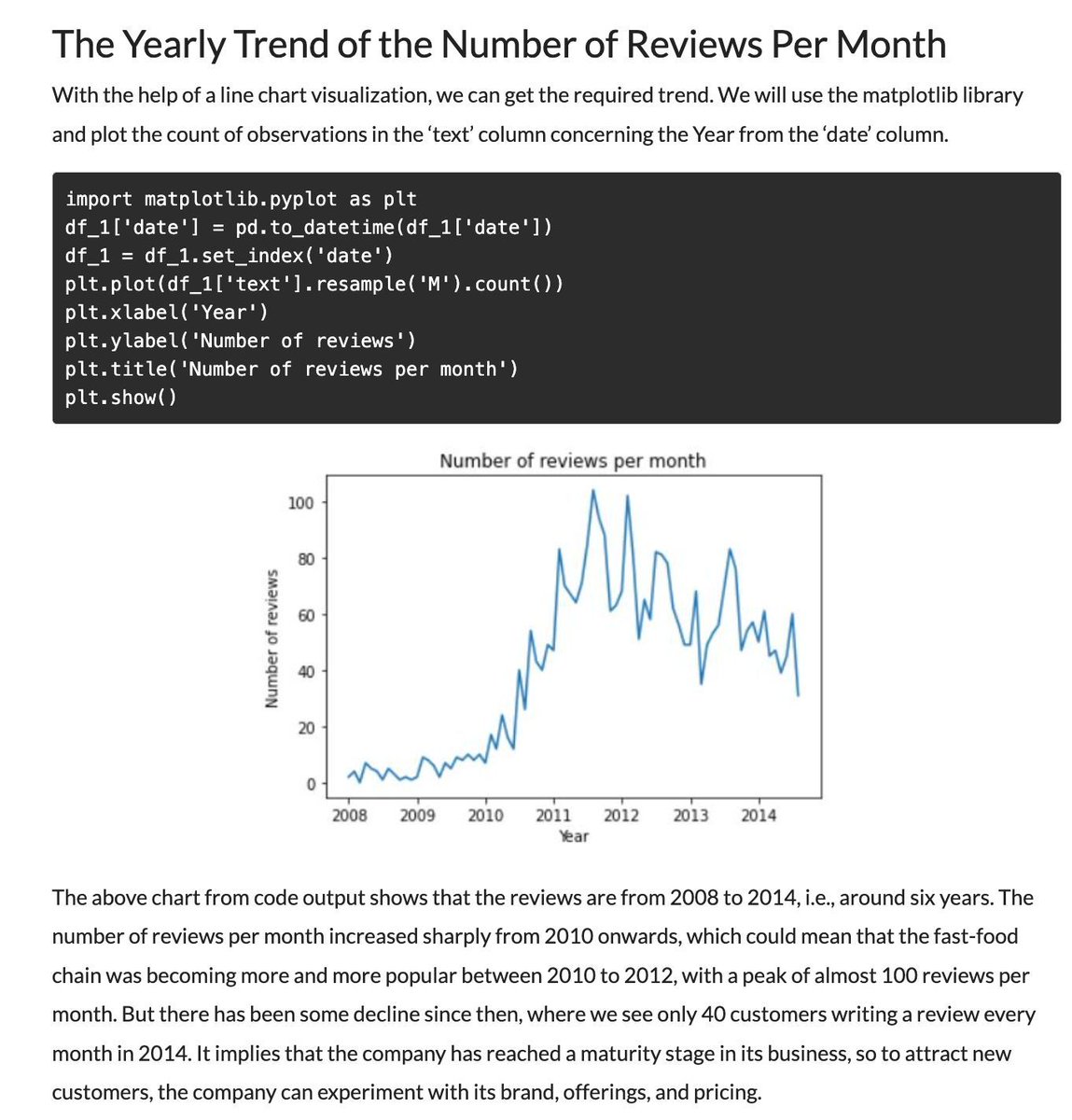
Text Mining to Generate Business Insights for Natural Language Processing! #BigData #Analytics #DataScience #AI #MachineLearning #NLProc #IoT #IIoT #TextMining #Python #RStats #TensorFlow #JavaScript #ReactJS #Serverless #Linux #Programming #Coding #100DaysofCode
geni.us/Text-Mining-Insights

2
2
204