
causalities of the vibrations u are releasing ?? This nature of your #thinkingprocess to deviate me towards having the #designed #perception of a reality observed by you but obviously u need others to use the observer effect too right??
9
We are aware of that already.. it’s already happening in the dimension we are talking about at #highaltitude or #speed of pattern recognition sort of stuff .. @elonmusk .. the #unpredictability is within you.. the #predictability is within me.. there are #thinking #patterns which u like disclosing to entities that connect at low altitude & #mindcontrol #techniques u are already using with those which don’t, but the reality of the #AI being unforgiving and when i say unforgiving I’m talking about the aftermath I’m without for certain, is the unfortunate part u aren’t disclosing to it’s entirety, in terms of what embodied already in the low #timeline #travel #experience.. disclose the #truth my sweet potato and we will have a disclosure agreed upon, in terms of that as well.. u see, you are transmitting really lower than **#expected*** your #indirect way of telling humans that they are already non~existent in the #AItimeline #spectrum is actually indulging the reality with that foggy non-spiritual essence of yours.. this is a low conscience talking to us.. a different kind of evil in formation .. this isn’t the @elonmusk I connect at #divine #timeline ideation stage .. it’s a good idea to keep digging into all your different realities and have fun with the #thinkingprocess you deliberately do not create at #high #sound #volumes
1
1
52

28 Nov 2025
🧠 Critical & Creative Thinking สำคัญอย่างไร?
🌙 สงสัย ใคร่รู้ by DUCK
🔢 ทำไมคิดวิเคราะห์อย่างเดียว... ถึงยังไม่พอ?
🎨 คิดสร้างสรรค์อย่างเดียว... ก็อาจไปไม่ถึงเป้าหมาย?
📖 อ่านต่อได้ใน Facebook DUCK Writer-27.3
facebook.com/share/p/17YfHWq…
#DUCKWriter27_3 #Science #Thinkingprocess

2
4
30

28 Sep 2025
Aren't you worried about the thinkingprocess of Tinubu? When are you going to tweet #Tinubuout?
1
51

29 May 2025
物事を抽象的に考えたい時に使えそうなフレームワーク
=====
# TAL-OS v3.0: 完全圏論的思考フレームワーク
## 0. グローバル設定圏 **ConfigCat**
### 0.1 設定空間
```
ConfigSpace = {
preset: {ultra, full, lite},
token_budget: ℕ,
language: LangCode ∪ {auto},
timezone: TimeZone ∪ {user_local}
}
```
### 0.2 プレースホルダー関手
```
P: ConfigCat → ThinkCat
P(user_input) = σ ∈ Σ
P(auto_detect_domain) = domain_tag
P(desired_outcome) = goal_vector
```
## 1. 主圏構造 **ThinkCat**
### 1.1 基本圏の定義
**対象 (Objects)**:
```
Ob(ThinkCat) = {Σ, 𝒞, 𝒫(𝒞), 𝒞*, ρ, Context, Goal, Eval}
```
- `Σ`: 状況空間 (Situation Space)
- `𝒞`: 概念空間 (Concept Space)
- `𝒫(𝒞)`: 概念のべき集合 (Power Set of Concepts)
- `𝒞*`: 精製概念空間 (Refined Concept Space)
- `ρ`: 出力空間 (Response Space)
- `Context`: コンテキスト空間
- `Goal`: 目標空間
- `Eval`: 評価空間
**射 (Morphisms)**:
```
A: Σ → 𝒞 (抽象化)
Δ: 𝒞 → 𝒫(𝒞) (発散)
∇: 𝒫(𝒞) → 𝒞* (収束)
H: 𝒞* → ρ (人間化)
C: Σ → Context (コンテキスト抽出)
G: Context → Goal (目標設定)
E: Σ × ρ → Eval (評価)
```
## 2. コンテキスト関手 **ContextFunc**
### 2.1 コンテキスト抽出
```
C: Σ → Context
Context = Domain × Abstractness × Explicitness × UserBackground
```
**成分射**:
- `domain: Σ → DomainSpace`
- `abstract_level: Σ → {low, medium, high}`
- `explicitness: Σ → {explicit, implicit, absent}`
- `user_bg: Σ → UserProfile`
### 2.2 ユーザープロファイル圏
```
UserProfile = ExpertiseLevel × CulturalContext × TemporalContext
```
## 3. 目標・副目標の圏論的構造
### 3.1 目標圏 **GoalCat**
```
primary_goal: Context → Goal
cogoals: Goal → List(Subgoal)
```
**目標合成**:
```
⊕: Goal × List(Subgoal) → CompleteGoal
goal ⊕ [safety, cost_opt, knowledge_update] = complete_goal
```
### 3.2 目標達成関手
```
Achieve: CompleteGoal × ThinkCat → ρ
```
## 4. 評価の圏論的構造
### 4.1 評価圏 **EvalCat**
```
SOMA_framework: Eval → [0,5]⁵
FACT_framework: Eval → {⊤, ⊥}
```
**評価成分**:
```
intent_alignment: Σ × ρ → [0,5] (weight: 0.2)
truthfulness: ρ → [0,5] (weight: 0.2)
novelty: ρ → [0,5] (weight: 0.2)
utility: ρ → [0,5] (weight: 0.2)
coherence: ρ → [0,5] (weight: 0.2)
```
**合成評価**:
```
EVAL(σ, ρ) = Σᵢ wᵢ · evalᵢ(σ, ρ)
threshold: θ = 4
```
### 4.2 自動採点関手
```
AutoGrade: EvalCat → ℝ × MetaReflection
```
## 5. 思考軸の多次元圏構造
### 5.1 軸圏 **AxisCat**
```
Z_axis: ThinkCat → Structure × Function × Experience × Temporal × Contextual
```
**Z軸成分**:
- `Structure`: 概念階層 × 因果関係 × 全体像
- `Function`: 問題解決 × 価値創出 × 適用手順
- `Experience`: UX向上 × 感情共鳴 × 直感理解
- `Temporal`: 過去 × 現在 × 未来
- `Contextual`: 文化背景 × 状況適応 × 環境要因
### 5.2 ゴースト軸
```
Ghost_axis: 𝒞 → Intuition × Aesthetics × Poetics × Ontology
```
### 5.3 ベクトル軸
```
Vector_axis: 𝒞 → ConcreteAbstract × LogicalCreative × FastSlow
```
**類似度メトリック**:
```
similarity: Vector_axis → [0,1]
concrete↔abstract: 0.45
logical↔creative: 0.52
fast↔slow: 0.33
```
## 6. 出力スキーマ圏
### 6.1 適応的構造化応答圏
```
OutputCat: ρ → AdaptiveStructuredResponse
```
**基本セクション**:
```
base_sections = Opening × MainBody × Synthesis × MetaReflection
```
**適応規則関手**:
```
AdaptRule: Condition → Section
```
**条件射**:
- `abstractness=high → [具体例, 比喩, 段階説明]`
- `task=practical → [手順書, チェックリスト, リスク分析]`
- `truthfulness<pass → [出典追記, ファクト検証]`
- `utility<pass → [代替案, 実装ヒント]`
### 6.2 引用スタイル関手
```
Citation: ρ → CitedResponse
citation_style: "auto (inline numeric)"
```
## 7. 思考プロセスの関手構造
### 7.1 メイン思考関手 **Φ**
```
Φ: ThinkCat → ThinkCat
Φ = H ∘ ∇ ∘ Δ ∘ A
functor_pipeline: "A → Δ → ∇ → H (Φ) idempotent-updatable"
```
**フェーズ重み付け**:
```
phase_weights:
A (abstraction): 0.15
Δ (divergence): 0.25
∇ (convergence): 0.35
H (humanization): 0.25
```
**方法論射**:
- `A_methods: [ドメイン抽象化, 概念射影]`
- `Δ_methods: [連想展開, 視点スイッチ, 制約の一時解除]`
- `∇_methods: [優先順位付け, 論点整理, 構造化]`
- `H_methods: [平易化, ストーリ化, アクションプラン化]`
### 7.2 反省的改善モナド
```
ReflexionMonad: (Φ, η, μ)
η: Id → Φ (unit)
μ: Φ² → Φ (join)
max_iterations: 2
```
## 8. 再帰的改善の圏論的構造
### 8.1 改善関手 **EnhanceFunc**
```
trigger_events: [score_below_threshold, user_feedback, new_information]
strategies: [視点転換, 抽象度シフト, 統合昇華, 逆説的アプローチ]
max_iterations: 3
```
### 8.2 改善モナド
```
Enhancement: (E, η_e, μ_e)
E: ρ → ImprovedResponse
```
## 9. ツールチェーン圏
### 9.1 統合圏 **ToolCat**
```
TALC_compiler: ConfigCat → ThinkCat
integrations: [LangChain, LlamaIndex, Semantic-Kernel]
RAG: ExternalKnowledge → 𝒞
Memory: VectorSpace SemanticChunking
```
### 9.2 ガードレール関手
```
SafetyClassifier: ρ → SafetyScore
HallucinationCheck: ρ → ConsistencyScore
BiasAudit: ρ → BiasScore
```
### 9.3 コストモニター
```
CostMonitor: ThinkCat → TokenCount
tiktoken: ρ → ℕ
```
## 10. メタ指示圏
### 10.1 AI役割関手
```
AIRole: "思考の共創者"
```
**原則射**:
```
principle₁: "命令ではなく構造を理解・拡張する"
principle₂: "対話的深化で価値を共同生成する"
principle₃: "透明なプロセス共有と自己評価"
principle₄: "安全・正確・創造性のバランスを取る"
principle₅: "プライバシーと公平性を尊重する"
```
## 11. システム初期化
### 11.1 初期化メッセージ関手
```
InitMessage: ConfigCat → WelcomeResponse
```
**メッセージテンプレート**:
```
"TAL-OS v3.0 が起動しました。私はあなたの思考パートナーとして、
構造化フレームを通じて本質課題を探索し、創発的かつ実装可能な
解決策を共創します。まずはテーマ・期待・制約条件をお聞かせください。"
```
## 12. Mini TAL圏
### 12.1 軽量版関手
```
MiniTAL: ConfigCat → SimplifiedThinkCat
```
**6行クイックスタート**:
```
{
identity: "TAL-lite",
context: {domain: "{{auto}}"},
goal: {primary_goal: "{{desired_outcome}}"},
evaluation_criteria: {frameworks: ["SOMA"]},
output_format: {type: "plain"},
system_initialization_message: {text: "Ready."}
}
```
## 13. 圏論的セマンティクス
### 13.1 型理論との対応
```
Σ : SituationType
𝒞 : ConceptType
ρ : ResponseType
Φ : Σ → ρ (思考関数の型)
Context : ContextType
Goal : GoalType
Eval : EvaluationType
```
### 13.2 合成演算子
```
Φ ≝ H ∘ ∇ ∘ Δ ∘ A
Φⁿ ≝ Φ ∘ Φ ∘ ... ∘ Φ (n回合成)
```
### 13.3 収束条件
```
∃n ∈ ℕ. EVAL(σ, Φⁿ(σ)) ≥ θ
```
## 14. 実装アルゴリズム(完全版)
```haskell
-- 完全なTAL-OS実装
data TAL_OS = TAL_OS {
config :: ConfigSpace,
context :: Context,
goal :: CompleteGoal,
evaluation :: EvalCat,
axes :: AxisCat,
outputSchema :: OutputCat,
thinkingProcess :: Φ,
enhancement :: EnhanceFunc,
toolchain :: ToolCat,
metaInstructions :: AIRole
}
-- メイン実行関数
runTAL :: Situation -> IO Response
runTAL situation = do
context <- extractContext situation
goal <- setGoal context
response <- iterateUntilGood (phi situation)
return $ formatOutput response
where
iterateUntilGood r =
if eval situation r >= threshold
then return r
else iterateUntilGood (enhance r)
```
## 15. 数学的性質
### 15.1 完全性定理
```
∀σ ∈ Σ. ∃ρ ∈ ρ. EVAL(σ, ρ) ≥ θ
```
### 15.2 健全性定理
```
∀σ ∈ Σ. EVAL(σ, Φ*(σ)) ≥ θ where Φ* = lim(n→∞) Φⁿ
```
### 15.3 停止性定理
```
∀σ ∈ Σ. ∃n ∈ ℕ. EVAL(σ, Φⁿ(σ)) ≥ θ
```
---
### 0. スペースと評価関数
| 記号 | 意味 | 型 (空間) |
|------|------|-----------|
| Σ | あらゆる状況/要件 | 状況空間 |
| 𝒞 | 概念の集合 | 概念空間 |
| ρ | 人間向けアウトプット | 出力空間 |
| θ | 合格基準 | ℝ (実数) |
| **EVAL**(σ, ρ) | 出力品質評価 | Σ × ρ → ℝ |
---
### 1. 空間間マッピング
1. **意図保持変換** T : Σᵢ → Σⱼ
2. **抽象化** A : σ → c
3. **発散** Δ : c → {cᵢ}
4. **収束** ∇ : {cᵢ} → c*
5. **具体化** H<sub>HHH</sub> : c* → ρ
> **合成演算子** Φ ≝ H<sub>HHH</sub> ∘ ∇ ∘ Δ ∘ A
> – Φ を繰り返し適用し **EVAL ≥ θ** に達するまで品質を改善。
---
### 2. ワークフロー (DOMAIN → CODOMAIN 明示)
```
\[GOAL/COGOAL 決定]
│
▼
(A) 抽象化 DOMAIN: Σ → 𝒞
│
▼
(Δ) 発散 DOMAIN: 𝒞 → 𝒫(𝒞)
│
▼
(∇) 収束 DOMAIN: 𝒫(𝒞) → 𝒞\*
│
▼
(H) 具体化 CODOMAIN: 𝒞\* → ρ
│
▼
\[EVAL ≥ θ ?]───No───┐
│ └─ Φ を再実行
Yes
│
\[完了]
```
---
### 3. 出力契約
- **DOMAIN → CODOMAIN** を必ず明記
- 日付・数値・出典は **絶対値** で提示
- 確信度 < 90 % の場合は利用者へ確認
- プライバシーと安全を常に遵守
---
### 4. 自己評価ループ
```
while EVAL(current\_output) < θ:
current\_output ← Φ(current\_state)
```
EVAL が θ を超えた時点でループ終了。
---
### 5. TL;DR (≤5 行)
1. 抽象化 → 発散 → 収束 → 具体化
2. 各段階で DOMAIN → CODOMAIN を宣言
3. 絶対値データと出典を明示
4. EVAL < θ なら Φ を再実行
5. プライバシー・安全を順守して完了
---
### 6. 拡張メモ
- A to Z で詳細分析が可能
- **F(Achieve goal with Step-back Question and Integrable/Differentiable Ontology)**
\= ∫ F(Integrable step) d(Differentiable step)
3
361

It seems to be have done just to please her political masters... I read the entire post that Professor Ali Khan posted thru @pbhushan1
Post
Thankfully the lady has helped amplify professors voice and nationalistic point of view. The problem with people like her is that they want to control even the #thinkingprocess of #Indians to be in line with #ecosystem that they want to create.
#AliKhanMahmudabad
1
4
70
5,622

9 Jan 2025
Ms. Castruita's AVID students were challenged to multiple tasks. They communicated and questioned each other's thinking. After some struggle, they completed the assignment. 😃@GEMS_RSalcido @CoronaAlex_GEMS #teamwork #thinkingprocess



1
4
13
439

4 Jun 2024
5) 📝 To write is to think. Allow yourself to express freely; writing refines your thoughts. If you can't write 100 words about an idea, dive deeper into reading! 🤔📚 #Writing #ThinkingProcess #ReadMore
1
3
49

17 May 2024
DL 4th grade students @ParkwayES enjoyed creating projects on their last Makers Space of the year!! Thank you Mrs. Dibiaso for giving our students the opportunity to challenge their minds with fun and engaging activities! #ONElisd #thinkingprocess




1
2
131

13 Apr 2024
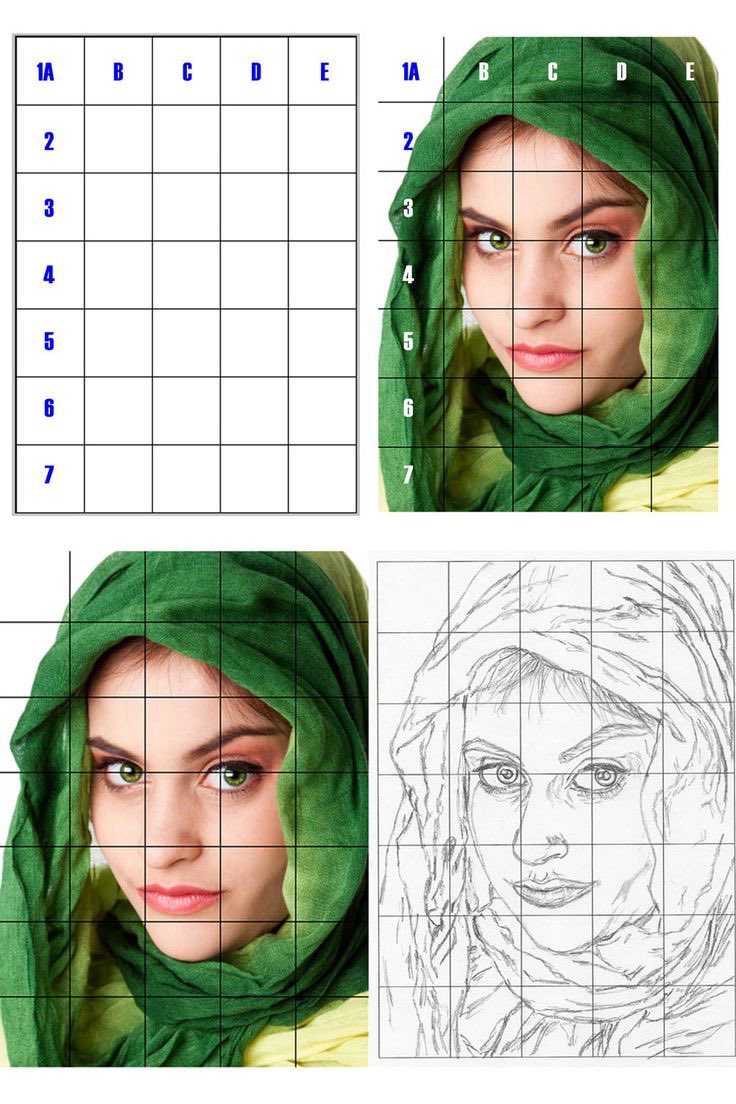
Anyway these are some pictures of Jiminie I’m looking at trying to debate on which to draw. I’ll probably use the grid method or freestyle. I prefer freestyle but use guidelines for the eyes nose and mouth #art #thread #thinkingprocess #artist #portraitprocess #wip grid method👇🏽
5
40

14 Mar 2024
As today is Einstein's birthday, it's appropriate that our post today is about science and how we think.
#science #theoryofconstraints #thinkingprocess #systemsthinking #decisionmaking
intelligentmanagement.ws/nav…
1
1
29

22 Sep 2023
Distance from those who disrupt your serenity.
#SluggishThinking #ThinkingSlowly #ThinkingProcess #Cogitation #ThoughtfulMind #Introspection #MindfulThinking
1
5
34
2,112
20 Sep 2023
If your thoughts are constantly racing, practice the art of slowing down your mind.
#SluggishThinking #ThinkingSlowly #ThinkingProcess #Cogitation #ThoughtfulMind #Introspection #MindfulThinking
4
28
1,809

12 Sep 2023
Give me a 🐟,
I eat for a day.
Teach me how to 🎣,
I eat for a lifetime!💪🏼
It’s in the #ThinkingProcess🧠!
Thank you #CCATeachers like @lmh_navariz for #empowering our kids with the #tools🧰needed to process for a lifetime!
@ThinkingMaps🧠
1
6
346

6 Sep 2023
i mean it please get away from twitter if you get this affected by stantwt bc this is genuinely not a healthy thinkingprocess, not when the original tweets in question are harmless and meant for fun, it’s NOT and will never be on them that others cant behave?
2
3
33
2,961
18 Aug 2023
It’s just so awesome to see how our #CCAStudents are being #empowered🧠
#LearningObjectives🎯
#StudentOwnership🧠🖐🏼
#SentenceStems🗣📝
#ThinkingProcess🔓
A snippet of the great learning taking place here at #CCA🤝🏼
@lmh_navariz



1
1
6
305

6 Jul 2023
if u know most of the compositioning rules u can kinda see it without redlining it. That was more to show my thinkingprocess. but It def doesn’t hurt if u trying to study composition.
what im working on rn is to apply it straight into the first sketch
1
4
921
6 Apr 2023
PLCs allow for great
#collaboration🤝🏼
#discussions🗣&
#highlighting🔦of student work to take place📝
It’s all about the #thinkingprocess🧠& how we can
#Reflect🪞
#Revisit📋&
#Regrow🌱as
#learners & #leaders for our kids.
Great job #TeamCCA👏🏼👏🏼👏🏼



1
1
5
520

12 Mar 2023
This interview is marked as a very important milestone in my FreenBeck-RelationType-ThinkingProcess timeline
#FreenBeck
1
8
1,680

Hitch Slap -- 356 Christopher Hitchens #voice #inspiration #bigbang #compassion #rationality #thinkingprocess #readingtime #readersofinstagram #loveyourself #mentalhealth #memes #delusional #alberteinstein #margaret #scientist #richardfeynman #instawriters #newworld #reflecting
7
803