
May 12
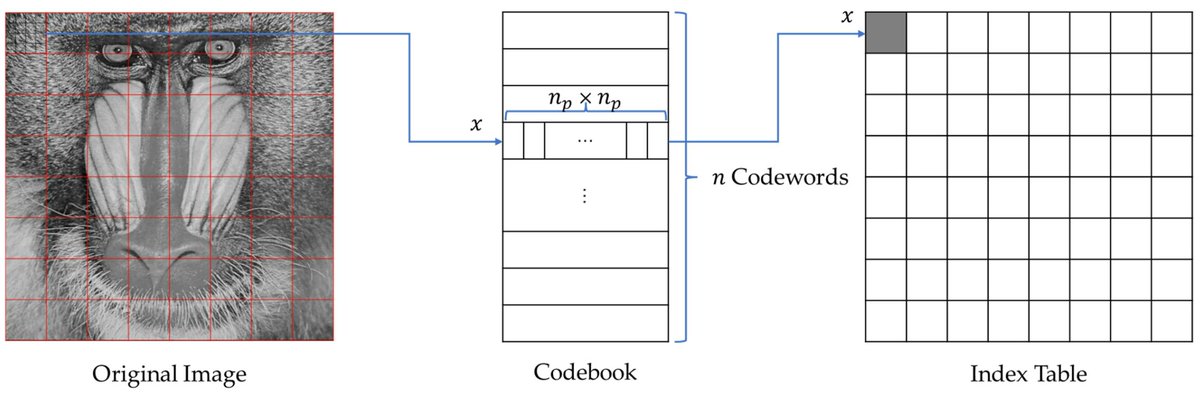
Lossless Recompression of Vector Quantization Index Table for Texture Images Based on Adaptive Huffman Coding Through Multi-Type Processing
✏️ Yijie Lin et al.
🔗 brnw.ch/21x2p2Z
Viewed: 1686; Cited: 4
#mdpisymmetry #vectorquantization #HuffmanCoding
@ComSciMath_Mdpi
3
2
23

Jan 4
Stop calling `.transcribe()` and start understanding the math. Purusharth Malik @master_dragon19’s latest guide builds an ASR system from the ground up, connecting Signal Processing directly to Deep Learning. #ASR #SignalProcessing #VectorQuantization
ai.gopubby.com/automatic-spe…
1
2
65

14 Jul 2025
شرحت كل الرياضيات اللي ورا الarcheticture وكل المشاكل وكيف حلوها 😢دعمكم لايك وشير وسبسكرايب.
واعتذر عن التخاذل سحبت الاسبوع الماضي المفروض علي😂
#VQVAE #VectorQuantization #VariationalAutoencoders #Generative_AI


12
768

21 Jun 2025
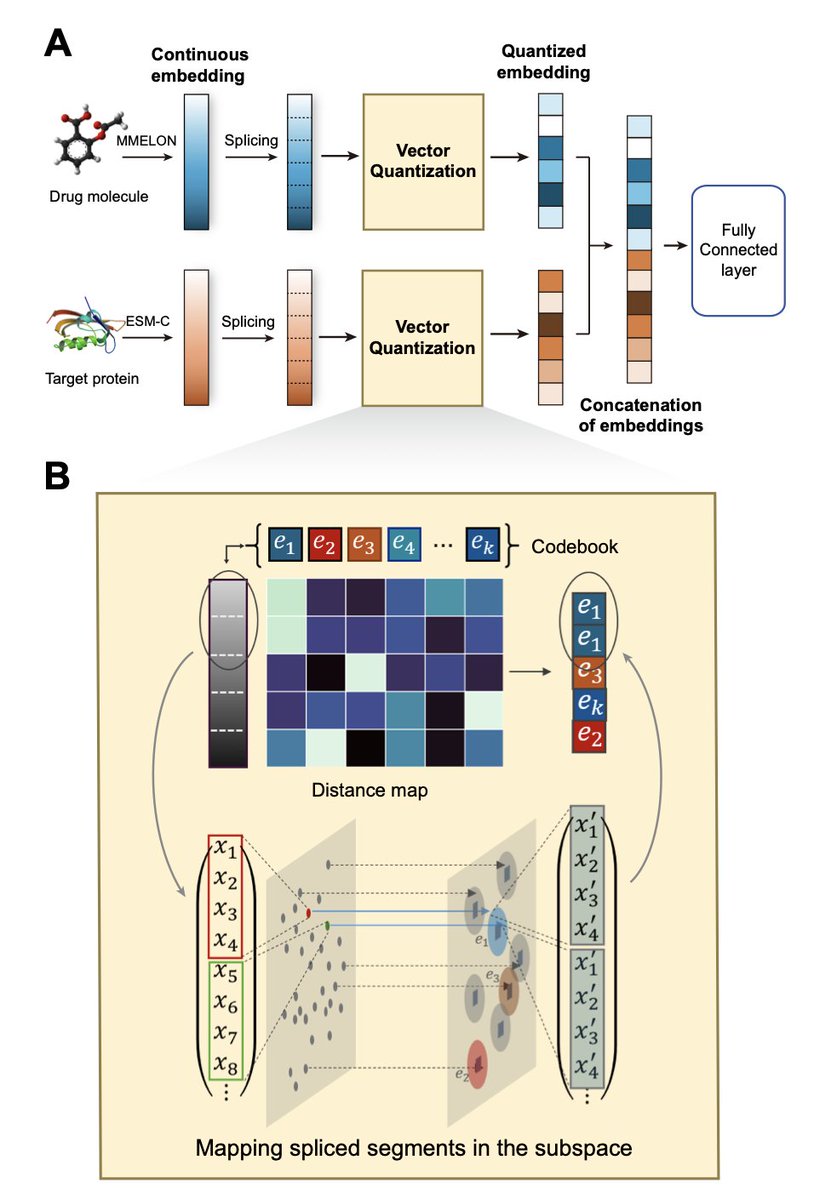
Rethinking Representation Complexity in Drug–Target Prediction via Supervised Vector Quantization
1.Most drug–target interaction (DTI) models use dense, high-dimensional embeddings from pretrained models, but this study shows that many of those features are redundant or irrelevant. It proposes a new plug-and-play supervised vector quantization (SVQ) module that filters out noise while enhancing performance and interpretability.
2.The SVQ framework uses a vector quantization layer to compress and discretize continuous drug/protein embeddings. These quantized features outperform existing models like ConPLex and MolTrans on multiple benchmarks, including BIOSNAP and BindingDB.
3.Interestingly, the best results were achieved by reducing features: over 70% of the original pretrained features were found to be uninformative. Feature selection with Random Forest Boruta kept only a fraction (e.g., 4.3% in DAVIS), yet performance increased, highlighting the danger of "more is better" in deep learning representations.
4.The SVQ module replaces manual feature selection with an end-to-end learnable codebook, making it compatible with modern deep learning pipelines. It discretizes the embedding space, reducing redundancy while preserving discriminative patterns via learnable codewords.
5.Compared to recent models, SVQ achieved top AUPR scores on BIOSNAP (0.928) and BindingDB (0.668), and remained competitive on DAVIS. Even in zero-shot tests with unseen drugs/targets, SVQ maintained robust generalization.
6.Beyond accuracy, SVQ enhances interpretability. Codeword usage patterns reveal domain-specific interactions. Drugs targeting similar protein domains (e.g., kinases, ion channels, immunoglobulins) share similar codeword activation patterns, suggesting the model learns biologically meaningful structure.
7.A simple bag-of-words (BoW) representation based on codeword frequency—without using any semantic embeddings—still preserved the structural clustering of drugs, as confirmed by t-SNE and Mantel tests. This suggests that co-occurrence patterns alone carry significant predictive signal.
8.Even with randomly initialized and frozen codebooks, the model was trainable and lost only minor performance (<5% on BIOSNAP), confirming that precise embedding semantics are not essential—it's the codeword usage patterns that matter.
9.This reframes representation learning in DTI: co-occurrence and structure of quantized features may matter more than high-dimensional continuous embeddings. The SVQ model represents a shift toward compact, interpretable, and efficient models in drug discovery.
💻Code: github.com/jdcc2098/SVQDTI
📜Paper: biorxiv.org/content/10.1101/…
#DTI #DeepLearning #DrugDiscovery #ProteinLanguageModel #VectorQuantization #Bioinformatics #InterpretableAI
4
21
1,524
21 Jun 2025
Rethinking Representation Complexity in Drug–Target Prediction via Supervised Vector Quantization
1.Most drug–target interaction (DTI) models use dense, high-dimensional embeddings from pretrained models, but this study shows that many of those features are redundant or irrelevant. It proposes a new plug-and-play supervised vector quantization (SVQ) module that filters out noise while enhancing performance and interpretability.
2.The SVQ framework uses a vector quantization layer to compress and discretize continuous drug/protein embeddings. These quantized features outperform existing models like ConPLex and MolTrans on multiple benchmarks, including BIOSNAP and BindingDB.
3.Interestingly, the best results were achieved by reducing features: over 70% of the original pretrained features were found to be uninformative. Feature selection with Random Forest Boruta kept only a fraction (e.g., 4.3% in DAVIS), yet performance increased, highlighting the danger of "more is better" in deep learning representations.
4.The SVQ module replaces manual feature selection with an end-to-end learnable codebook, making it compatible with modern deep learning pipelines. It discretizes the embedding space, reducing redundancy while preserving discriminative patterns via learnable codewords.
5.Compared to recent models, SVQ achieved top AUPR scores on BIOSNAP (0.928) and BindingDB (0.668), and remained competitive on DAVIS. Even in zero-shot tests with unseen drugs/targets, SVQ maintained robust generalization.
6.Beyond accuracy, SVQ enhances interpretability. Codeword usage patterns reveal domain-specific interactions. Drugs targeting similar protein domains (e.g., kinases, ion channels, immunoglobulins) share similar codeword activation patterns, suggesting the model learns biologically meaningful structure.
7.A simple bag-of-words (BoW) representation based on codeword frequency—without using any semantic embeddings—still preserved the structural clustering of drugs, as confirmed by t-SNE and Mantel tests. This suggests that co-occurrence patterns alone carry significant predictive signal.
8.Even with randomly initialized and frozen codebooks, the model was trainable and lost only minor performance (<5% on BIOSNAP), confirming that precise embedding semantics are not essential—it's the codeword usage patterns that matter.
9.This reframes representation learning in DTI: co-occurrence and structure of quantized features may matter more than high-dimensional continuous embeddings. The SVQ model represents a shift toward compact, interpretable, and efficient models in drug discovery.
💻Code: github.com/jdcc2098/SVQDTI
📜Paper: biorxiv.org/content/10.1101/…
#DTI #DeepLearning #DrugDiscovery #ProteinLanguageModel #VectorQuantization #Bioinformatics #InterpretableAI

7
738
3 Dec 2024
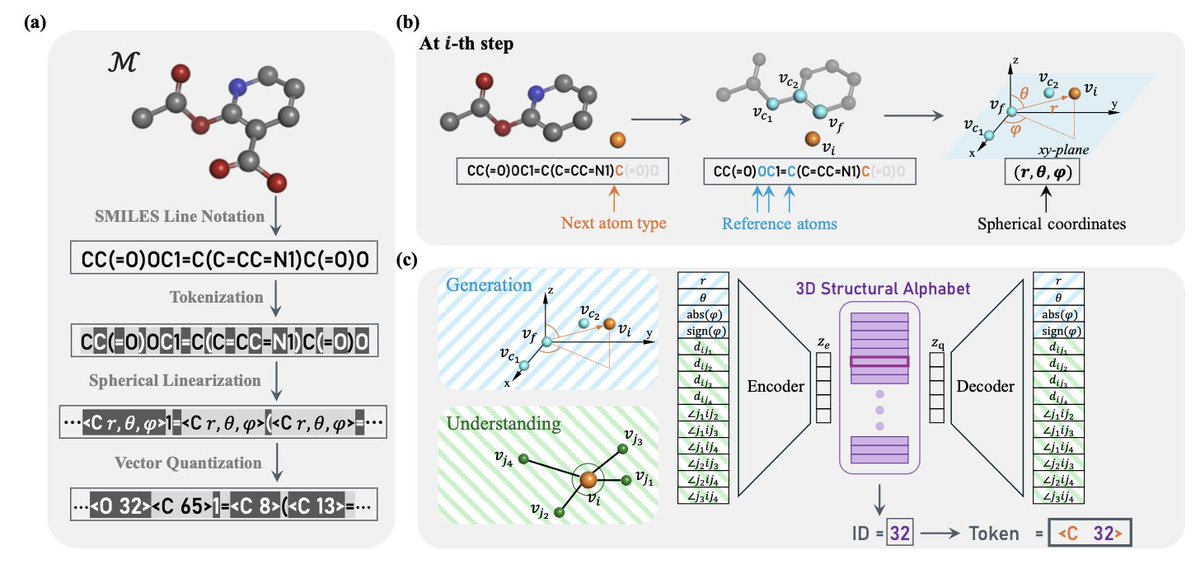
Tokenizing 3D Molecule Structure with Quantized Spherical Coordinates
• This study introduces Mol-StrucTok, a novel framework for tokenizing 3D molecular structures using spherical coordinate line notations and vector quantization. The approach resolves key challenges in applying language models (LMs) to 3D molecular data, such as ensuring SE(3)-invariance and discretizing continuous atomic coordinates.
• A standout innovation is the use of a spherical coordinate system to encode local atomic environments, preserving both molecular graph topology and spatial structure. By combining bond lengths and angles as understanding descriptors, Mol-StrucTok enhances representation quality.
• Leveraging a Vector Quantized Variational Autoencoder (VQ-VAE), the framework converts continuous coordinates into discrete tokens compatible with autoregressive models like GPT-2. This enables efficient and accurate 3D molecular generation.
• Experimental results demonstrate that Mol-StrucTok achieves high chemical validity (98%) and structural stability, outperforming existing diffusion and autoregressive models in generation speed—offering a 28x speedup compared to diffusion-based methods.
• The framework excels in conditional molecular generation, showing significant improvements in property-controlled tasks such as QM9 quantum mechanical properties. It also integrates seamlessly with Graphormer for property prediction, enhancing molecular understanding.
• Limitations include reduced performance in uniqueness metrics compared to diffusion models and reliance on predefined coordinate systems. Future directions include expanding to multimodal modeling and advanced molecular editing tasks.
💻Code: github.com/KyGao/Mol-StrucTo…
📜Paper: arxiv.org/abs/2412.01564
#3DMolecule #GenerativeModels #VectorQuantization #MachineLearning #DrugDiscovery
5
48
3,315

19 Aug 2024
LLMs are getting *massive*—but how do we bring this power to #EdgeDevices? ⚡️ The answer: #Quantization.
m.blog.naver.com/PostView.na…
Lowering precision without losing accuracy is the key to scaling AI. 🚀 Excited about #VectorQuantization like #GPTVQ, which shrinks models while keeping them sharp. 🧠 This tech will unlock AI's potential on smartphones & IoT, making our future smarter, faster, and more secure. #AIRevolution
1
2
109

27 Mar 2021
Breathing K-Means: a new algorithm that finds better solutions than k-means (almost always)
pypi: pypi.org/project/bkmeans/ preprint: arxiv.org/abs/2006.15666 sources examples: github.com/gittar/breathing-…
#MachineLearning #kmeans #clustering #VectorQuantization #ScikitLearn
1
1
3

4 May 2018
Our new article "Ultra-fast global homology detection with Discrete Cosine Transform and Dynamic Time Warping " brings the WARP speed among the alignment-free protein homology search algorithms!
Read more here academic.oup.com/bioinformat…
#starTrek #bioinformatics #vectorQuantization
3
4


17 Apr 2016
Learning #VectorQuantization for #MachineLearning machinelearningmastery.com/l… via @TeachTheMachine
1