
Jun 13
Most multi-agent frameworks (ChatDev, MetaGPT) organize agents around roles.
We built AgentNexus around service boundaries instead.
After months of running it in production — here's what we learned, what was wrong, and what we fixed.
3
1
18

Jun 8
Most people think the hardest part of AI coding is writing code.
A paper on arXiv disagrees.
They tested 30 tasks using ChatDev (multi-agent system).
The data is wild:
→ Code Review alone consumed 59.4% of all tokens
→ Input tokens were 53.9% of total cost
So the model isn't just "writing a lot."
Every agent is constantly feeding context to other agents :
summaries, fixes, bug reports, "just so you know."
The real question isn't: did the agent complete the task?
Ask instead:
• How many tokens to reach an accepted artifact?
• How many review rounds?
• How much context did it re-read?
• How many tokens burned while waiting?
Task success is the floor. Cost-to-accepted-artifact is the ceiling.
That's the gap between a demo and a system you can run every day.
Link to the paper in the comments!
1
39

Jun 7
LLMマルチエージェント開発のトークン消費先を分析。ChatDevとGPT-5の30タスクで、コード生成でなく反復的なCode Reviewが59.4%を占有。入力が53.9%を占めcommunication taxが主因 / Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering
arxiv.org/abs/2601.14470
2
3
87

May 16
聚焦和 Hermes/OpenClaw 同类的通用 AI Agent 框架(自托管、非纯编程工具、能当个人助手/自动化用的)
第一梯队:全能型通用 Agent 平台(直接同类)
1. OpenClaw — "龙虾"
- Stars: 31.5 万 (开源史上增长最快,超越 React)
- 类型: 自托管 Gateway 网关 个人 AI 操作系统
- 核心: SOUL.md(人格) MEMORY.md(记忆) Skills(技能) Channels(20 消息平台)
- 生态: ClawHub 13,729 技能包,15 国内大厂入局
- 日 Token: 245B(OpenRouter 第 2)
- 部署: 400 万 次独立部署,微信触达 12 亿用户
2. Hermes Agent — "爱马仕"
- Stars: 14 万(2 个月翻倍)
- 类型: 开源自进化 AI 智能体
- 核心: 三层持久记忆 自我改进循环 自动技能生成 多智能体 Kanban
- 日 Token: 271B(OpenRouter 第 1)
- 最新版: v0.13.0,295 位贡献者,864 次提交
- 成本: $5/月 VPS 即可 7×24 运行
- 差异点: "越用越聪明",Agent 能从经验中学习并创建新技能
这两个是目前唯一达到十万级 Stars 百亿级日 Token 消耗的通用 Agent 框架。
第二梯队:成熟通用框架(有自己特色)
3. AutoGPT — 自主 Agent 鼻祖
- Stars: 17 万
- 类型: 通用自主任务执行框架
- 开创性: 2023 年首创"思考-规划-执行"循环,让世界知道 Agent 可以自主干活
- 特点: 完全自主运行、目标驱动、插件生态成熟
- 现状: 社区最大但开发节奏放缓,更适合研究/实验
- 定位偏: 原型验证和研究探索,不是日常生产工具
4. LangChain / LangGraph — 生态之王
- Stars: LangChain 全系 ~100K ,LangGraph 单独 ~28K
- 类型: 通用 LLM 应用开发框架 有状态工作流引擎
- 核心: 最广泛的工具集成生态(搜索/SQL/文档/数据库等数百个)
- LangGraph 亮点: 图状工作流、循环/条件分支、状态持久化、可视化编排
- LangSmith: 生产级监控和调试平台
- 优势: 教程最多、社区最大、企业采用最广
- 短板: 学习曲线陡,偏"开发者框架"而非"开箱即用助手"
5. CrewAI — 最轻量多 Agent 协作
- Stars: 22K-28K
- 类型: 角色化多 Agent 协作框架
- 核心隐喻: 把 Agent 当团队成员——研究员/写手/审核员各司其职
- 上手: 所有框架中最快(~10 分钟,pip install 几行代码)
- 流程: 支持顺序执行 / 并行执行 / 层级任务分配
- 适合: 内容生产、市场调研、多视角分析任务
- 短板: 缺乏持久化和消息平台集成
6. AutoGen(微软研究院)— 企业级多 Agent
- Stars: 35K
- 类型: 多 Agent 对话协作框架
- 核心: "群聊模式"——Agent 之间自然语言交流协作
- 亮点: Docker 沙箱代码执行、自定义拓扑、人机协同(人也可作为 Agent 参与)
- 背书: 微软研究院出品,Azure 生态深度集成
- 适合: 复杂决策流程、代码审查迭代、企业级场景
7. Open Interpreter — 代码执行 Agent
- Stars: 45K
- 类型: 本地代码执行 Agent(类似 ChatGPT 但能操作电脑)
- 核心: 在本地跑 Python/JS/Shell,读写文件、执行系统命令
- 体验: 类 ChatGPT 的自然语言交互
- 安全: 支持询问确认模式
- 适合: 数据分析、系统管理、自动化脚本
- 短板: 偏工具型,缺持久记忆和多平台集成
8. SuperAGI — 有 GUI 的自主 Agent
- Stars: 15K
- 类型: 带 Web UI 的自主 Agent 平台
- 亮点: 图形界面管理、工具市场 Agent 市场、非技术友好
- 特点: Docker 一键部署、Agent 可分享复用、多模型支持
- 适合: 不想写代码的人搭建自己的 Agent
9. AgentGPT — 可视化配置
- Stars: 18K
- 类型: 浏览器端可视化 Agent 配置部署
- 特点: 纯 Web UI,无需编程,Docker 一键启动
- 适合: 快速体验和原型验证
第三梯队:垂直方向但有通用性
10. MetaGPT — 虚拟软件公司
- Stars: 20K
- 类型: 模拟软件公司组织架构的多 Agent 系统
- 角色: 产品经理 架构师 工程师 测试员,自动完成软件开发全流程
- 中科院背景
11. ChatDev — 虚拟软件公司(另一个)
- Stars: 16K
- 类型: 中科院 OpenBMB 出品,同样模拟软件公司协作
- 特点: 通过聊天驱动虚拟角色协作开发软件
12. BabyAGI — 极简任务管理
- Stars: 12K
- 类型: 极简的任务驱动型 Agent(原型级)
- 核心: 创建任务列表 → 排优先级 → 执行 → 循环
- 地位: 教学和理解 Agent 原理的经典项目
13. Phidata — 极简快速原型
- Stars: 14K
- 类型: 轻量级 Agent 框架,极简设计哲学
- 适合: 快速搭建原型、MVP 验证
14. Mastra — TypeScript 生态
- Stars: 10K
- 类型: AI 原生 Web 应用框架(TS 专用)
- 适合: 全栈 JS/TS 开发者构建 Agent 应用
15. Semantic Kernel(微软)— 企业级 .NET
- Stars: 22K
- 类型: 企业级 Agent 开发 SDK
- 语言: .NET / Python / Java
- 亮点: 微软官方背书,Azure 深度集成,适合大型企业
2
372

I think he meant games where the dialogue is generated by a local model.
There were some interactive fiction experiments using LLMs a couple of years back, they failed in bizarre ways. There's also bee the likes of chatdev, which was a kind of LLM environment that led to agent swarms. There was also that Skyrim mod that used the OpenAI APIs and Elevenlabs to generate characters you could actually speak to. But this was ambiance rather than being part of the gameplay mechanics or the world.
I personally think for a game, you'd need to invent a bunch of different tricks to layer smaller models in clever ways. Have coding assistants writing the overall structure at development time, then players in the world would use models to rephrase things within that structure and update their internal states within a strict model of psychology and the world, you'd use image generation to create variations of things in a tightly constrained way, use voice models for NPC speech and STT to interact with them.
This would require a monstrous GPU, beyond what almost anyone has at the moment. I'd still like to do it though, at some point.
5
46

Here is what our open source contributor shipped this week!
Mem0 OSS Weekly Updates - April 4–10
55 PRs. 21 merged. 39 issues closed.
Updates:
• OpenClaw plugin refactor SDK deprecation cleanup
• CLI v2: import/event commands PostHog telemetry
• Docs overhaul: 222 SEO redirect chains eliminated
• ChatDev integration guide shipped
• AGENTS. md AI agent skills landed
• session_id → run_id migration across docs
• DeepSeek LLM for TypeScript SDK
• Azure OpenAI DeepSeek response_format fixes
• Fixed deprecated default Groq model
Shoutout to top contributors:
kartik-mem0 whysosaket IgnazioDS rakheesingh Devan019 SZemse jarediaz rudra717 Prithvi1994
More coming next week
github.com/mem0ai/mem0
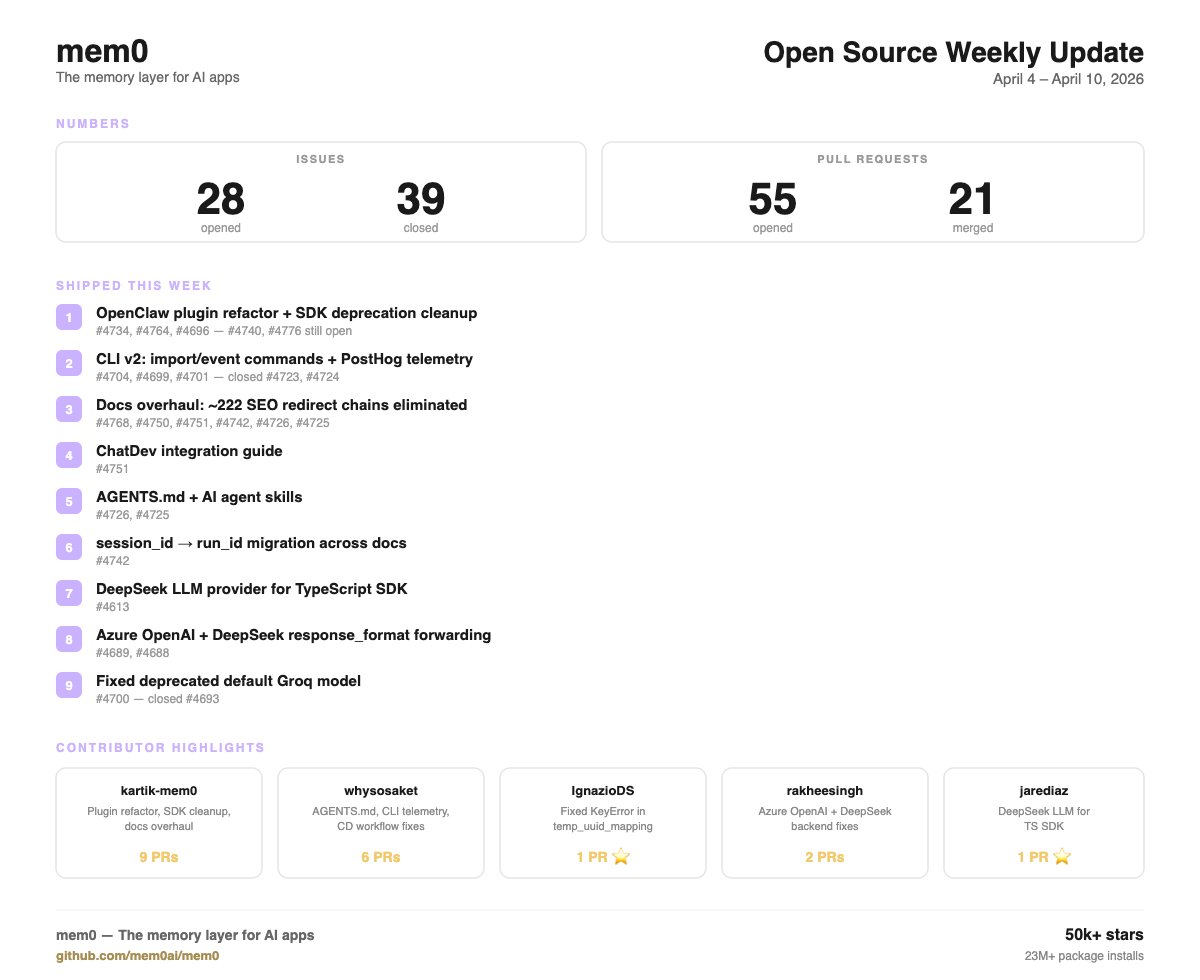
ALT Weekly update highlights open source contributions: 55 PRs opened, 21 merged, and various new features and fixes listed.
1
2
20
1,561

Apr 10
Agent开发团队搭建太重要了,期待Nico老师的分享。
想起之前在github上看过类似开源的项目,简单试用过,感觉还可以,在这里也分享下:
ChatDev github.com/OpenBMB/ChatDev
MetaGPT:github.com/FoundationAgents/…(这个更早一些,有段时间没迭代了)
1
4
725


Apr 6
BREAKING: MIPT has conducted the largest AI agent coordination experiment to date.
The study involved 25,000 tasks, 8 models, and 4 to 256 agents, revealing that how agents coordinate is three times more significant than the choice of model used. Specifically, protocol choice accounts for 44% of quality variation, while model choice contributes only 14%. Interestingly, the best protocol does not assign any roles to agents.
Traditionally, the field of multi-agent AI has operated under the assumption that roles must be assigned before tasks begin—such as manager agent, researcher agent, coder agent, and reviewer agent. Major frameworks like ChatDev, MetaGPT, AutoGen, and AgentVerse have all adhered to this model of pre-assigned specializations.
MIPT challenged this assumption by running 25,000 tasks across 20,810 unique configurations. The results indicate that the best-performing protocol allows agents to have a mission, follow a fixed processing order, and make no role assignments.
In this approach, agents create their own specializations for each task, voluntarily step back when they lack contributions, and form shallow hierarchies spontaneously, without any design.
The findings suggest that systems that diverge from traditional human organizational structures can outperform those designed to mimic them.
The experiment evaluated four coordination protocols on identical tasks with the same models:
- Coordinator: One agent analyzes the task and assigns roles to others, who execute in parallel.
- Sequential: Agents process in a fixed order, observing the outputs of predecessors and independently choosing their roles.
- Broadcast: Agents signal their intended roles simultaneously before making final decisions.

1
4
160

Apr 6
🚨 BREAKING: MIPT just ran the largest AI agent coordination experiment ever
25,000 tasks, 8 models, 4 to 256 agents and found that how agents coordinate matters 3x more than which model you use.
Protocol choice explains 44% of quality variation. Model choice explains 14%. And the best protocol gives agents no roles at all.
> The entire field of multi-agent AI has been built on one assumption: assign roles before the task starts. Manager agent. Researcher agent. Coder agent. Reviewer agent. ChatDev, MetaGPT, AutoGen, AgentVerse every major framework pre-assigns specializations and fixes them for the duration.
MIPT ran 25,000 tasks across 20,810 unique configurations to test whether that assumption is correct. It isn't.
The best-performing protocol gives agents a mission, a fixed processing order, and zero role assignments.
The agents invent their own specializations for each task from scratch, voluntarily abstain when they have nothing to contribute, and spontaneously form shallow hierarchies without anyone designing them.
> The system that looks least like a human organization outperforms every system that was designed to look like one.
> The experiment tested four coordination protocols on identical tasks with identical models.
Coordinator: one agent analyzes the task and assigns roles to everyone else, who execute in parallel.
Sequential: agents process in a fixed order, each observing what predecessors actually produced, and each choosing their own role independently.
Broadcast: agents first signal their intended roles simultaneously, then make final decisions.
Shared: agents access a shared memory of past role assignments and make all decisions in parallel.
The quality gap between the best and worst protocol is 44%, with Cohen's d = 1.86 a massive effect size. That gap is larger than the quality difference between the best and worst model in the experiment.
The protocol you choose matters more than whether you use Claude, GPT, or DeepSeek.
> The paradox is why Sequential wins. It is neither the most controlled protocol nor the most autonomous.
Coordinator gives maximum control and fails because one agent's judgment limits the whole system.
Shared gives maximum autonomy and fails because agents don't know what others are doing in real time they duplicate roles and miss gaps.
Sequential gives agents exactly one thing: the completed outputs of every agent who went before them. Not intentions. Not history. Not a plan. Actual results from this specific task.
Each agent sees the factual record of what has already been done and chooses a role that complements it. The analogy in the paper is a sports draft: each pick is informed by every previous selection, so the team naturally fills complementary positions without anyone coordinating it.
The numbers across 25,000 tasks and 20,810 configurations:
→ Sequential vs. Shared protocol: 44% quality, Cohen's d = 1.86, p < 0.0001
→ Sequential vs. Coordinator: 14% quality, p < 0.001 confirmed across Claude Sonnet 4.6, DeepSeek v3.2, and GLM-5
→ Protocol choice explains 44% of quality variation among strong models
→ Model choice explains ~14% of quality variation on the same protocol
→ Scaling from 64 to 256 agents: zero statistically significant quality change, p = 0.61
→ Cost growth from 8 to 64 agents: only 11.8% despite 8x more agents
→ 8 agents generated 5,006 unique role names across tasks RSI converges to zero, agents reinvent specialization every task
→ At 256 agents: ~45% voluntarily abstain through self-assessment, not coordinator direction
→ Claude Sonnet 4.6 voluntary abstention rate: 8.6% models below capability threshold show near-zero abstention and worse outcomes
→ DeepSeek v3.2: 95% of Claude's quality at 24x lower API cost
→ Shock resilience: random agent removal, hub removal, and 25% model substitution all recover within 1 iteration
> The capability threshold finding is the one that changes how you think about model selection. Self-organization is not universally beneficial.
When MIPT tested Claude Sonnet 4.6 in free-form self-organization, quality improved over fixed roles.
When they tested GLM-5, quality dropped 9.6%. The reversal effect is real: weaker models perform better with rigid structure than with autonomy.
The threshold requires three capabilities self-reflection to assess your own competence, deep reasoning for multi-step logic, and precise instruction following.
Claude's voluntary abstention rate of 8.6% versus GLM-5's 0.8% shows the gap directly. An agent that cannot accurately assess when it has nothing to contribute will keep contributing badly.
The conductor analogy in the paper is exact: an orchestra of beginners plays better with a conductor. An orchestra of professionals plays better without one.
> The emergent hierarchy result is the finding that should change how teams think about scaling.
MIPT scaled from 4 to 256 agents without pre-designing any organizational structure. As the group grew, agents spontaneously formed two-layer hierarchies.
Unique role specialization increased from 75% at 4 agents to 91% at 64 agents. Adaptation speed after shocks improved from 0.7 to 3.0 as the group grew larger.
The system gets more resilient and more specialized at scale not because anyone designed it that way, but because Sequential coordination with capable models naturally produces those properties.
Nobody told the agents to form a hierarchy.
Nobody told them to specialize.
They did it because the information structure of Sequential coordination made it the rational thing to do.
The recipe is three ingredients: a mission, a protocol, and a capable model.
Pre-assigned roles are a fourth ingredient that makes everything worse.

29
38
263
29,304

Drop the Hierarchy: How Self-Organizing AI Agents Just Changed Everything
What if I told you that giving AI agents less structure makes them 44% smarter?
Would you believe me—or would you assume it's chaos?
A 25,000-task experiment just proved that self-organizing LLM teams crush centralized designs. Here's the paradox that's rewriting AI coordination... 🧵
You know that feeling when you over-plan a project—assign every role, lock every step—and it still underdelivers?
AI agents feel the same way. Except they don't need fixed jobs. They can switch specializations at zero cost, process full context, and abstain when they add no value.
We've been designing them wrong.
Everyone "knows" that multi-agent systems need hierarchies. Coordinators. Pre-assigned roles.
Let's talk about why that's almost entirely wrong—and what 8 LLM models, 4-256 agents, and 25,000 task runs revealed instead.
Spoiler: The secret isn't control. It's not autonomy either. It's something in between.
The experiment tested 8 coordination protocols on a spectrum:
Centralized (Coordinator): One agent assigns all roles.
Hybrid (Sequential): Fixed order, but agents pick their own roles.
Fully Autonomous (Shared): Total freedom.
Which won? (Hint: Not the extremes.)
The hybrid protocol—Sequential—destroyed both extremes:
44% quality over full autonomy (Cohen's d=1.86, p<0.0001)
14% quality over centralized control (p<0.001)
Why? Each agent saw what predecessors actually did, not plans, not intentions—factual, task-specific outputs. Like a sports draft where each pick knows all prior choices.
This is the Endogeneity Paradox: minimal structure unlocks maximal emergence.
Once you see this pattern in self-organizing AI, you can't unsee it:
5,006 unique roles from 8 agents (Role Stability Index → 0)
Voluntary abstention: 38 agents withdrew by choice, not orders
Shallow hierarchies: Systems formed 2 layers max, never 10
Agents reinvent themselves for each task. No positions. Pure function.
But does it scale?
From 4 to 256 agents: Quality stayed stable (p=0.61). Cost grew only 11.8% despite 8× agents.
At N=256, 45% of agents self-abstained—idle by choice, optimizing the system from within.
Remember that 44% quality boost? It compounds with scale, not collapses.
Old way (e.g., ChatDev, MetaGPT): Assign "architect," "engineer," "tester." Fixed pipeline. If a task needs flexibility, too bad.
New way: Give agents a mission, a protocol (Sequential), and a capable model. They invent "risk analyst," "legal interpreter," "integrator"—then abstain when done.
Mission Relevance score: 4.0/4.0. Perfect alignment, zero pre-design.
Hot take: The most popular advice—"use the best closed-source model"—is holding you back.
Open-source DeepSeek hit 95% of Claude's quality at 24× lower cost. GLM-5 also competed.
Mix models: Strong (Claude) for adversarial tasks (L4), efficient (DeepSeek) for routine (L1). You cut costs by 88% while matching performance.
Have you ever noticed this in your AI projects?
The more roles you assign upfront, the less flexible the output?
Agents that can specialize don't need to be told to. They self-organize when given:
A mission
The right protocol
A capable model
That's it. Three ingredients. No org chart required.
I was wrong about autonomy being universal.
Turns out, weak models fail under self-organization. Without self-reflection and deep reasoning, they need rigid structures—autonomy hurts them by 9.6%.
There's a capability threshold. Below it, dictatorship wins. Above it, emergence dominates.
Lesson: Test your model before you free it.
But that's not even the most interesting part.
As tasks got harder (L1 → L4 adversarial), something wild happened:
Agents spontaneously deepened their hierarchies from 1.22 layers to 1.56—without instructions. They sensed complexity and adapted structure on the fly.
Quality dropped 37.7% on L4 (expected), but they tried to self-correct. Emergent resilience.
So what do you do with this?
The paper proposes a 3-Ring Constitutional Framework:
Ring 1 (human only): Mission, values, abstention rights
Ring 2 (joint): Metrics, governance
Ring 3 (autonomous): Protocols, thresholds
Closer to "why" = more human control. Closer to "how" = full AI autonomy.
This is the governance model for self-organizing systems.
Next time you deploy multi-agent LLMs:
Define mission, not roles.
Choose Sequential protocol (or batched for latency).
Invest in model quality, not quantity (64 agents ≈ 256 agents in quality).
Mix models (e.g., Claude DeepSeek).
You'll see 14-44% quality gains with sub-linear costs. Validated across 20,810 configurations.
This research fundamentally changes how I think about AI organization.
Pre-assigned roles are an anti-pattern—they replicate human limits onto entities that lack them. The endogeneity paradox proves:
Optimal coordination isn't control or chaos. It's bounded emergence.
Give agents a mission, a protocol, and freedom. They'll invent the rest—roles, hierarchies, even when to quit.
Self-organization will do the rest.
🔗 Full paper: [arXiv:2603.28990]
...which makes you wonder: What other AI "best practices" are we getting wrong?
If you're building multi-agent systems, I dare you: try Sequential, track abstention, and measure emergent properties.
Then tell me what you discover. Let's compare notes. 🚀
4
3
27
3,287

Mar 30
清华ChatDev 2.0 Claude 3.5 Sonnet 组合推荐
🔥清华ChatDev 2.0(DevAll)热度不减,GitHub星标31.9k,搭配Claude 3.5 Sonnet堪称绝配
零代码可视化拖拽编排,AI自动扮演多角色协作,搭配Claude后逻辑更优、代码质量更高,5分钟即可上手
🔗github.com/OpenBMB/ChatDev
#ChatDev #Claude #AI多智能体
2
4
315

ChatDevだ!
nowokay.hatenablog.com/entry…
Mar 29

【海外で話題】
AIエージェントを““ピクセルキャラ化”して
仮想オフィスで働かせる機能が100%オープンソースで登場👀
x.com/oliviscusAI/status/203…
・エージェントが歩く
・タスクごとに動く
・視覚的に進捗が見える
これ全部、無料でオープンソースです👇こんな感じで可視化すると頭で考えながら作業できるので便利ですよね!
2
9
3,043

清华 ChatDev 2.0 Claude 3.5 Sonnet
最近清华大学 OpenBMB 团队的 ChatDev 2.0(DevAll) 还在 GitHub 上保持热度,Star 已经来到 31.9k !
简单说,ChatDev 就是一个“虚拟 AI 软件公司”:它能让多个 AI 自动扮演 CEO、CTO、程序员、测试员等角色,一起开会讨论需求、设计架构、写代码、测 Bug。
现在 2.0 版本已经进化成零代码多智能体编排平台,支持可视化拖拽工作流,不用写代码就能指挥 AI 团队干各种事(不只是写软件,还能做数据可视化、研究等工作流)。
我最近用 Claude 3.5 Sonnet 跑了几天,感觉这个组合特别香——虽然 ChatDev 支持很多模型,但配上 Claude 后,AI 团队明显“带脑子”了。
⭐️为什么这个组合还挺带感?
1.讨论像真人开会:以前很多模型里,CEO 和 CTO 聊天容易变成复读机。换 Claude 后,它们会认真讨论架构冲突、做 Trade-off,逻辑更硬核、更自然,像硅谷团队在头脑风暴。
2.代码质量更高:我实测同一个全栈 Todo App(带用户认证),Claude 版第一遍 Bug 少很多,错误处理和架构都更完善,返工次数明显减少。
3.流程更灵活:2.0 支持拖拽编排 最新版还集成了 OpenClaw 调用,整个从需求到出结果的过程顺滑不少。
5分钟上手实操:
1.直达仓库:github.com/OpenBMB/ChatDev (当前 v2.2.0)
2.复制 .env.example 改成 .env,填入你的 Anthropic API Key
3.在 Workflow 设置里把模型切换成 claude-3-5-sonnet(推荐最新可用版本)
4.启动 Web Console(或 Docker 一键启动),拖拽节点就能指挥你的 AI 团队了!
一句话总结:清华提供了一个好用的多 Agent 编排平台,Claude 给它装上了目前逻辑很强的“大脑”。想体验“指挥一群 AI 一起开发项目”的感觉,这个组合值得一试。
#ChatDev #Claude
50
120
545
210,801


التحدي التقني في تشغيل 10 وكلاء بالتوازي ليس تكلفة الـ 250 ألف دولار، بل هندسة الإدارة (Orchestration) لمنع تداخل الأكواد (Merge Conflicts). هذا النطاق المعماري يتطلب وكيل توزيع (Router Agent) لتقسيم السياق، ووكيل دمج (Merge Agent) للتحقق. لمحاكاة هذه البيئة الإنتاجية بتكلفة منخفضة للمطورين، يمكن استخدام أطر عمل مثل CrewAI أو ChatDev لبناء فريق برمجي افتراضي مصغر ومستقل.
6
558


GOAL
OWN GOAL MAKES IT THREE!!!!
MUFCW 3-0 CHATDEV | 75'
#KentFAPlate
1
2
197

SUB:
⬆️ Rowsell
⬇️ Hinkley
MUFCW 1-0 CHATDEV | 60'
#KentFAPlate
2
229