Herman Kienhuis retweeted

LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. arxiv.org/pdf/2605.27734
35
227
1,620
146,046


Jun 2
Spent some time with chatGPT to read the “learn from your own latent” paper arxiv.org/abs/2605.27734 that shows up on my tl. being less familiar w the practical methods mentioned myself, do ppl find the connection to eg data2vec convincing…?
2
1
27
4,410

Jun 2
6/
Here is the kicker: you don't actually need complex, hand-designed hierarchical networks.
A standard flat transformer trained with data2vec automatically acts as a self-assembling hierarchical parser, resolving lower-level synonyms first, then moving up.

1
6
356
A consequence: if a single latent-prediction module (data2vec) is already implicitly multi-scale, then explicitly stacking them (e.g. H-JEPA) is to some extent redundant. Work led by @DanKorchinski & @alesfav.
2
31
3,987
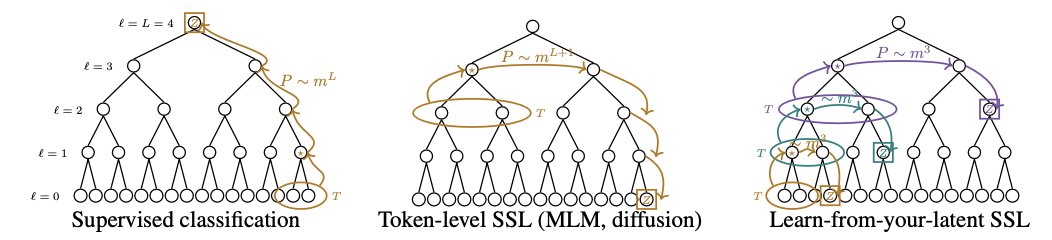
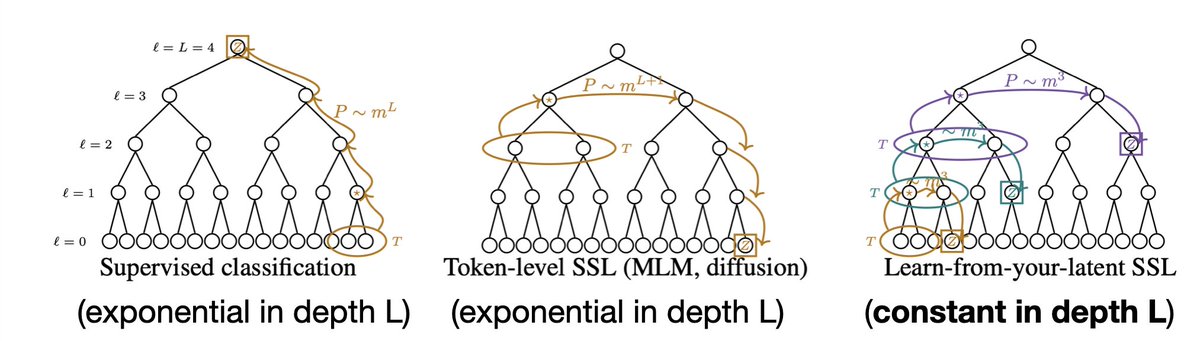
We make this precise on simple context-free grammars. Token-level SSL need a sample size exponential in the depth of the latent tree. Learning from your own latents is nearly independent of depth. We show that data2vec implicitly does exactly this hierarchical latent prediction.
2
1
40
4,769

Learn from your own latents and not from tokens: A sample-complexity theory
Author's Explanation:
x.com/DanKorchinski/status/2…
Overview:
Latent prediction architectures learn from internal representations rather than token-level targets, enabling sample complexity that is constant in tree depth L compared to the exponential requirements of supervised or token-level self-supervised learning.
This theoretical framework demonstrates that hierarchical stacking is largely redundant for data with compositional structure.
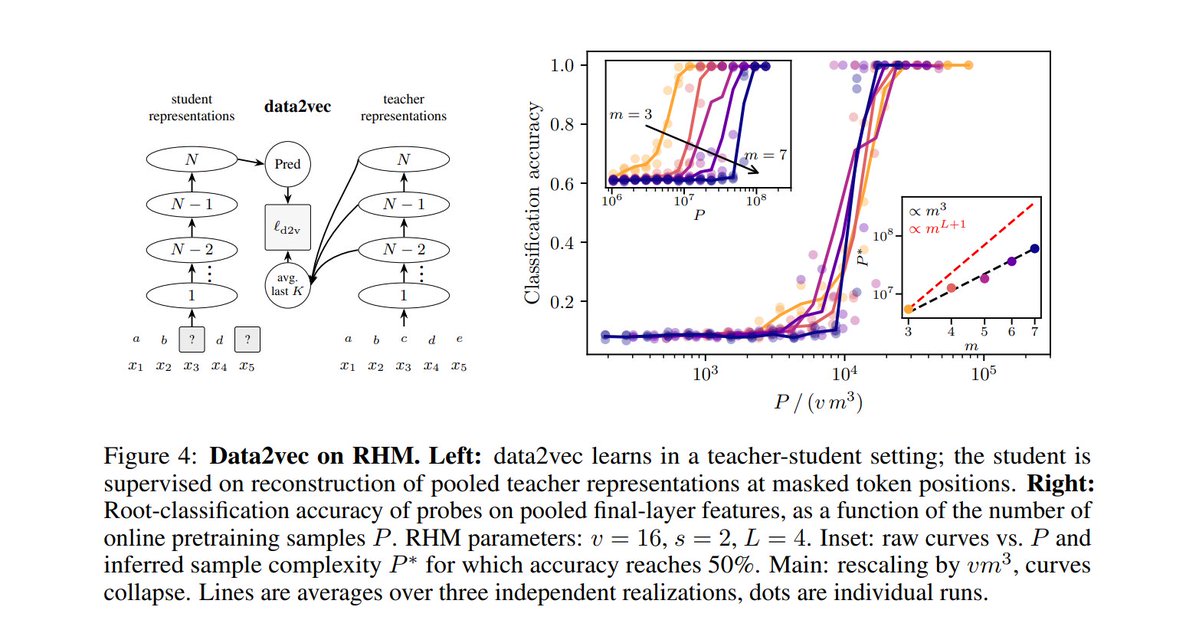
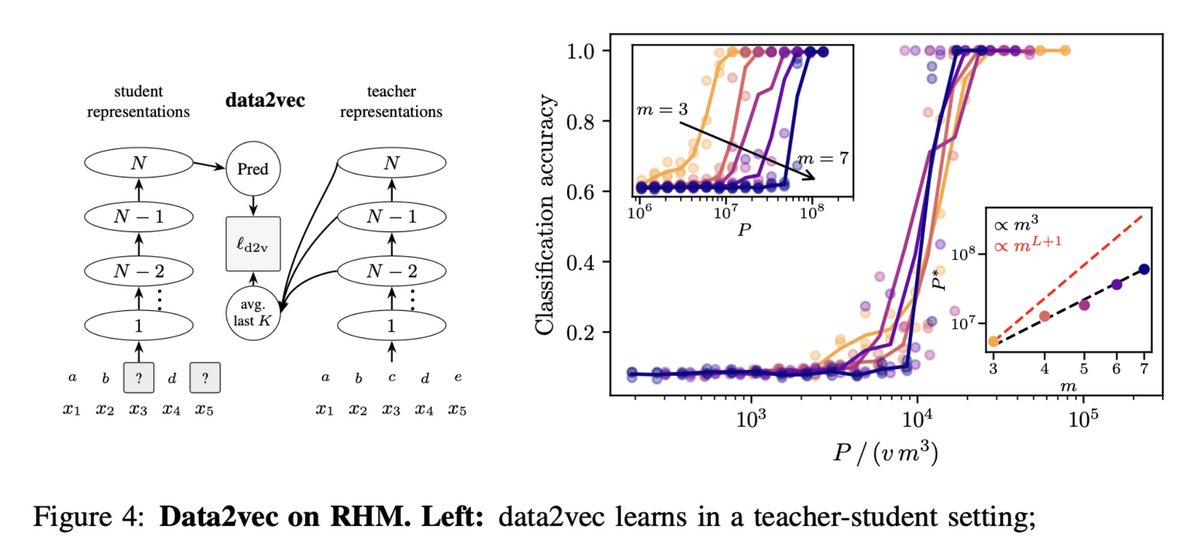
Experiments using hierarchical clustering and neural networks validate these bounds, while analysis confirms that data2vec implicitly performs effective latent prediction.
Paper:
arxiv.org/abs/2605.27734

Why are generative models so data-hungry?
Maybe because we ask them to predict raw tokens/pixels when predicting in latent space can yield an exponential gain in sample complexity!
Proud of our new work with @alesfav and @MatthieuWyart 🧵
1
4
939

May 31
data2vec has been around for three years. Given results like this, why hasn’t it caught traction, except in the head of a certain Frenchman?
2
1
6
1,063

Maybe the data-efficiency gap is not a scaling problem.
Maybe it is an objective problem.
A striking preprint by Daniel J. Korchinski, Alessandro Favero, and Matthieu Wyart offers a sample-complexity theory for this shift:
Learn from your own latents and not from tokens.
The core problem is familiar:
modern generative models are extraordinary, but brutally data-hungry.
LLMs train on 10¹³–10¹⁴ tokens.
Children do not.
So the question is not only:
How do we scale models?
It is:
What are we asking them to predict?
Most of modern AI trains on the visible surface: next tokens, masked tokens, pixels, noise.
That works.
But it may be statistically inefficient for learning hierarchy.
The authors study a tractable hierarchical grammar where visible tokens are generated from a hidden latent tree of depth L — a stylized model for the compositional structure of language and images.
The result reframes the debate:
token-level learning requires samples exponential in L to recover the hidden tree.
latent prediction recovers it with sample complexity essentially constant in L, up to logarithmic factors.
In plain English:
predicting tokens forces the model to infer the hierarchy through the leaves.
predicting latents lets the model climb the tree.
Once one abstraction level is learned, it becomes the substrate for learning the next.
This is why data2vec and JEPA-style objectives are so interesting.
They do not merely reconstruct the input.
They train a network to predict its own latent representation of another view or masked region.
The target is no longer the surface.
The target is the model’s own emerging abstraction.
The paper validates the theory three ways:
a hierarchical clustering algorithm
an end-to-end neural architecture trained by gradient descent
a sample-complexity analysis of data2vec, showing it implicitly performs hierarchical latent prediction
One implication is provocative:
if data2vec already discovers hierarchy implicitly, explicit stacking schemes such as H-JEPA may be partly redundant.
This is not “next-token prediction is dead.”
Next-token prediction built the current era.
But if the goal is biological-level data efficiency, surface reconstruction may be the expensive path.
The strategic frontier may be latent self-prediction:
models learning not only from what they see,
but from the abstractions they are forming.
Full credit to the authors:
Daniel J. Korchinski, Alessandro Favero, Matthieu Wyart.
Paper:
Learn from your own latents and not from tokens: A sample-complexity theory
arxiv.org/abs/2605.27734
I’m attaching the first page because the abstract is worth reading closely.
The future of data-efficient AI may not be more tokens.
It may be better targets.
#AIResearch #MachineLearning #SelfSupervisedLearning #RepresentationLearning #DataEfficiency #LLM

3
1
10
1,033

May 31
The data-efficiency gap between machines and children may not be solved by “more tokens.”
It may be solved by changing what the model is asked to predict.
A beautiful new paper by Daniel J. Korchinski, Alessandro Favero, and Matthieu Wyart gives a sample-complexity theory for a major alternative to token-level learning:
Learn from your own latents and not from tokens.
The premise is striking.
Modern generative models learn by predicting raw surface fragments:
next tokens
masked tokens
pixels
noise
patches
This works spectacularly.
But it is brutally data-hungry.
Biological learners do not see 10¹³–10¹⁴ tokens before acquiring rich language competence. So perhaps the bottleneck is not only architecture, scale, or optimization.
Perhaps it is the prediction target.
Instead of predicting tokens, methods like data2vec and JEPA train networks to predict their own latent representations of related views or masked regions.
The model is not asked:
“Can you reconstruct the surface?”
It is asked:
“Can you predict the abstraction your own system would form?”
That difference may be enormous.
The authors study a tractable hierarchical grammar that generates visible tokens from hidden latent trees of depth L — a stylized model of the compositional structure of language and images.
For this data, supervised learning and token-level self-supervised learning require samples exponential in L to recover the hidden hierarchy.
But latent prediction recovers the hierarchy with sample complexity essentially constant in L, up to logarithmic factors.
That is the whole paper in one line:
predicting tokens makes hierarchy expensive;
predicting latents makes hierarchy recursive.
Why?
Because token-level objectives keep forcing supervision through the visible surface. The deeper the hidden structure, the weaker and more indirect the signal becomes.
Latent prediction removes that bottleneck.
Once one level of abstraction is recovered, the model can use its own learned latents as both context and target for the next level. Every level becomes statistically like the first.
The paper confirms this three ways:
a hierarchical clustering algorithm
an end-to-end neural architecture trained by gradient descent
a sample-complexity analysis of data2vec, showing that it implicitly performs hierarchical latent prediction
The last point is especially interesting.
If data2vec already discovers hierarchy implicitly, then explicitly stacking methods like H-JEPA may be partly redundant.
This is not “tokens are dead.”
Token prediction remains one of the most productive ideas in AI.
But this paper gives a precise reason why token-level learning may be an inefficient path to latent structure.
The deeper lesson:
the model should not only learn from the world’s surface.
It should learn from the abstractions it is already beginning to form.
Full credit to the authors:
Daniel J. Korchinski, Alessandro Favero, Matthieu Wyart.
Paper:
Learn from your own latents and not from tokens: A sample-complexity theory
arxiv.org/abs/2605.27734
I’m attaching the first page because the abstract is worth reading closely.
The future of data-efficient AI may not be more reconstruction.
It may be recursive self-prediction in latent space.
#AIResearch #MachineLearning #SelfSupervisedLearning #RepresentationLearning #LLM #DataEfficiency

1
3
6
353

May 30
"Learn from your own latents, not tokens: A Sample Complexity Theory"
This paper explains why data2vec and JEPA can learn with much less data.
They showed that when data has hidden hierarchy, token prediction becomes harder as the hierarchy gets deeper. But latent prediction keeps the learning problem simple at every level.
Which suggests that models may learn faster when they stop predicting raw tokens and start predicting their own abstractions.

9
105
633
35,714

May 30
这篇论文终于把为什么AI学东西比人慢的原因讲透了:问题不在数据量,而在学习目标。它从样本复杂度理论出发,证明预测自身的隐表示(latent)比预测原始token在数据效率上有指数级优势——PCFG数据上,token级SSL需要Ω(exp(L))样本,latent预测仅需O(log L)。这首次从理论上解释了data2vec、JEPA等隐空间方法为何高效,也暗示了H-JEPA那种显式多尺度堆叠可能是冗余的。不过理论局限在组合结构数据,对无结构或非层次数据仍需验证。
arxiv.org/abs/2605.27734
20
144
1,107
90,327

This also reframes hierarchical SSL.
Explicit stacks like H-JEPA are natural, but data2vec suggests a single latent-prediction objective can already create multi-scale supervision.
The hierarchy can be implicit.
1
1
22
1,622
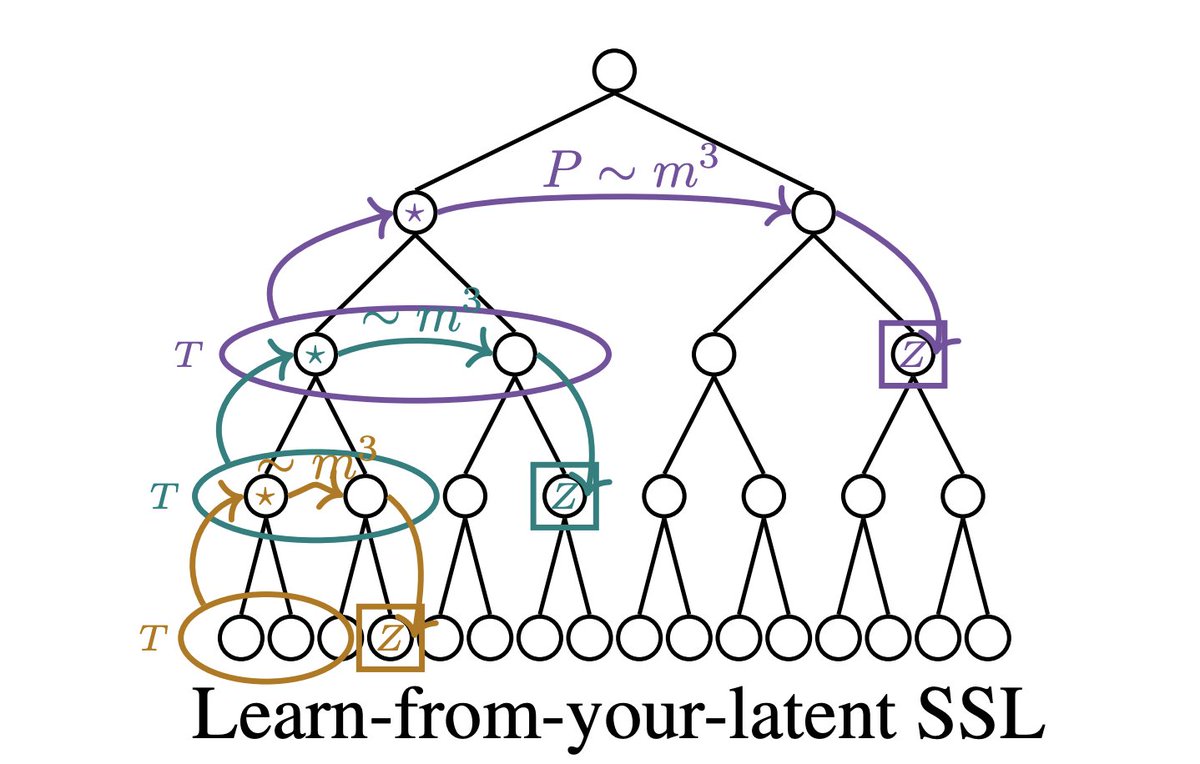
The surprise: data2vec gets the same ~m^3 scaling.
It learns by predicting teacher representations. Once low-level latents are learned, teacher targets carry them, so the student is pushed to learn higher-level latents.
Hierarchical supervision emerges over training time.
2
2
20
1,462

May 29
Surprisingly, we found data2vec already does this with a single module. Through its teacher, it implicitly supervises on latents at every level, reaching the same constant-in-depth scaling. 🤯
The hierarchy unfolds during training rather than being stacked into the architecture.
1
1
28
2,669
May 29
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski @MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
14
76
518
51,311

Mar 1
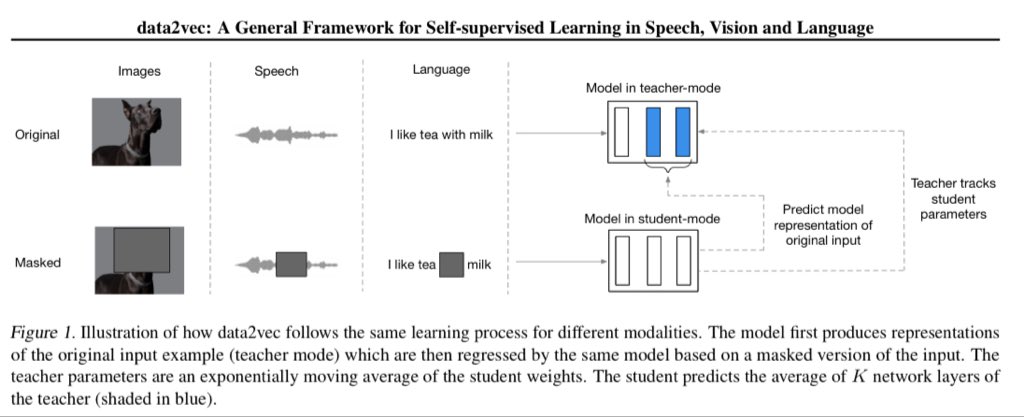
No one has scaled Data2Vec for speech. DINOv3 shows how beneficial it is to scale self-supervised vision encoders to ~7B params and train them on massive datasets. Waiting the same work for speech encoders
Feb 28

When Whisper came out in 2022, people slowly abandoned self-supervised speech encoders (HuBERT, Data2Vec, etc.). But in many aspects, they are much more interesting:
- blazingly fast thanks to parallel decoding
- you can improve ASR performance using only unlabeled speech
6
426
Feb 28
When Whisper came out in 2022, people slowly abandoned self-supervised speech encoders (HuBERT, Data2Vec, etc.). But in many aspects, they are much more interesting:
- blazingly fast thanks to parallel decoding
- you can improve ASR performance using only unlabeled speech
Feb 28

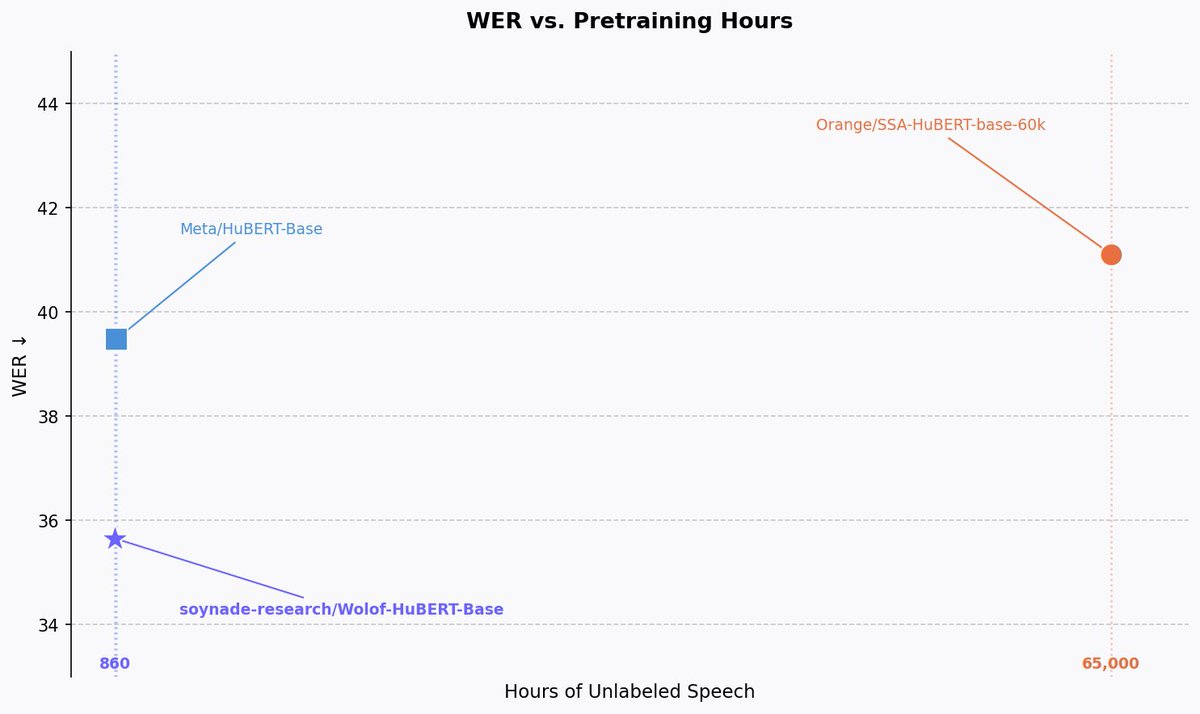
Continued pre-training allows us to be more compute-optimal than Orange's model while significantly outperforming the base Meta/HuBERT-Base model.
We release the ASR fine-tuned model along with 100 hours of clean Wolof ASR data.
Models and dataset here:
huggingface.co/collections/s…
7
828