
Jun 11
#Datafiltering can be used to leverage #algorithms
bit.ly/4rVxGyP
#EdgeComputing #WANAcceleration #SDWAN #DataCentre #Latency #NetworkPerformance #CloudComputing #IoT #DataTransfer #DisasterRecovery

2
8

Most teams migrate everything.
Years of closed tickets. Auto-generated notifications. Old records no one uses.
Then the new system feels cluttered from day one.
We launched Data Filtering so you can migrate only what matters 🧵
#datafiltering #helpdeskmigration
1
3

Apr 29
Ruido digital
✖️ No falta info, sobra ruido.
🔹 Renvex filtra lo relevante.
📈 Menos ruido. Más claridad.
#Renvex #Clarity #DataFiltering

44
108

Apr 7
bulk mailing tools, developer tools, smart filtering/sorting, or system upgrades?
BID-MASTERS has you covered!
We source premium tools
We handle filtering & maintenance
DM us for seamless solutions 💼
#BulkMailing #DeveloperTools #TechSolutions #DataFiltering #BIDMASTERS
1
1
34

🔍 Filter Data in Excel: Work Smarter, Not Harder!
Managing large datasets in Excel? Filtering data is the fastest way to focus on what really matters.
➡️ Visit Create and Learn for step-by-step guides and more tips to enhance your skills!
Excel #ExcelTips #DataFiltering
7

Feb 19
Learn How to Use Filter in Microsoft Excel (Step-by-Step for Beginners)
Learn how to use Filter in Microsoft Excel to quickly sort, search, and analyze your data in seconds.
#MicrosoftExcel #ExcelTips #ExcelForBeginners #ExcelFilter #LearnExcel #ExcelSkills #DataFiltering
1
11
conditionalFilter(X, condition, filterMap) — filter data via a dictionary of condition‑value mappings in one step! 🎯
Perfect for multi‑key lookups, dynamic whitelisting, and complex join‑like filtering without SQL joins.
#DolphinDB #DataFiltering
2
11

Feb 10
Beyond just selecting columns, being able to filter rows based on specific conditions in Pandas is a game-changer! 🚀 Need to see only Ticker 'A' data or rows where 'Close' price is above 200? Simple boolean indexing makes it effortless. This is powerful!
# df is our DataFrame
# Filter for Ticker 'A'
df_ticker_A = df[df['Ticker'] == 'A']
print('Ticker A data (head):\n', df_ticker_A.head())
# Filter for Close price > 200
df_high_close = df[df['Close'] > 200]
print('\nHigh Close price data (head):\n', df_high_close.head())
```
#Python #Pandas #DataFiltering #BooleanIndexing
#AIJourney #DataScience
1
13

Feb 2
🚪The SQL WHERE Clause - The Bouncer of Your Data Club
Every analyst remembers their first messy SQL query
Rows upon rows of data, no order, no meaning, just… everything.
That’s when I realized: the WHERE clause is the bouncer of your data club.
It decides who gets IN and who stays OUT.
Without it, your query is like opening the door to everyone - duplicates, nulls, and irrelevant data all crowding your results.
But with it, your data becomes clean, focused, and trustworthy.
💡The Core Idea
In SQL, the WHERE clause filters rows before aggregation, grouping, or joins.
It’s one of the most important parts of query optimization and accuracy.
Here’s the baseline syntax:
SELECT *
FROM Sales
WHERE Region = 'West';
This single line could reduce a 10M-row dataset down to the few hundred that actually matter.
⚙️Real-World Example: Fraud Detection
Imagine a banking table with 50 million transactions.
You’re asked: “Find transactions above ₦500,000 made after October 1st, 2024, but exclude test accounts.”
Here’s how your bouncer (WHERE clause) steps in:
SELECT TransactionID, Amount, Date, AccountType
FROM Transactions
WHERE Amount > 500000
AND Date >= '2024-10-01'
AND AccountType <> 'TEST';
✅Problem Solved:
You eliminate noise early, preventing aggregation errors and wrong fraud alerts.
The query now focuses only on legitimate, high-value transactions.
🔍Combining Filters for Precision
You can chain multiple conditions using logical operators:
WHERE Region = 'East'
AND Sales > 100000
OR (Region = 'West' AND Product = 'Laptops')
✅Problem Solved:
Gives flexibility to slice data dynamically, exactly like multiple door policies: “Only West or East region, but East needs ₦100k minimum spend”
🧠Optimization Tip
Filtering early reduces workload.
If your table has 10 million rows, filtering at the source can drop processing time from 20 seconds to under 2
👉Use indexes on columns you frequently filter with WHERE.
For example:
CREATE INDEX idx_region_date ON Sales(Region, Date);
This lets your database find matching rows faster, no full scans.
🧩WHERE Across Tools
The concept extends beyond SQL:
Tool Equivalent Filter Logic
-Power BI (DAX) FILTER(Sales, Sales[Region] = "West")
- Excel AutoFilter or =FILTER(A2:D100, D2:D100="West")
- Python (Pandas) df[df["Region"] == "West"]
Filtering is universal.
🚀Final Takeaway
Every great analysis starts with exclusion before inclusion
The WHERE clause doesn’t just limit data, it defines focus
Without it, your insights will always be noisy
With it, your queries speak clarity
💬What’s the most complex filter condition you’ve ever written and did it work as expected?
♻️Comment, Repost & Like, someone in your network needs this today
#SQL #DataAnalytics #DataEngineering #QueryOptimization #PowerBI #DataFiltering #BusinessIntelligence #AnalyticsTools

1
4
18
1,495

Jan 19
Unlock the power of precise blockchain data with Megafilter! Easily filter over 20 million tokens across 250 networks using 25 advanced options. Streamline your crypto analysis today! #Crypto #Blockchain #OnchainData #Cryptocurrency #DataFiltering
Jan 19

Build granular onchain data filtering with a single API ⚡️
Let users find exactly what they need using 25 advanced filters across 20M tokens & 250 networks with the Megafilter endpoint.
Get your API Key: coingecko.com/en/api/acquisi…
15

Slice through the noise! Rule-based filtering in Tom Sawyer Software helps you focus on what matters. Declutter complex graphs and explore with clarity. Dive deeper: bit.ly/4ptf1Jw #GraphTech #DataFiltering #ModelExploration
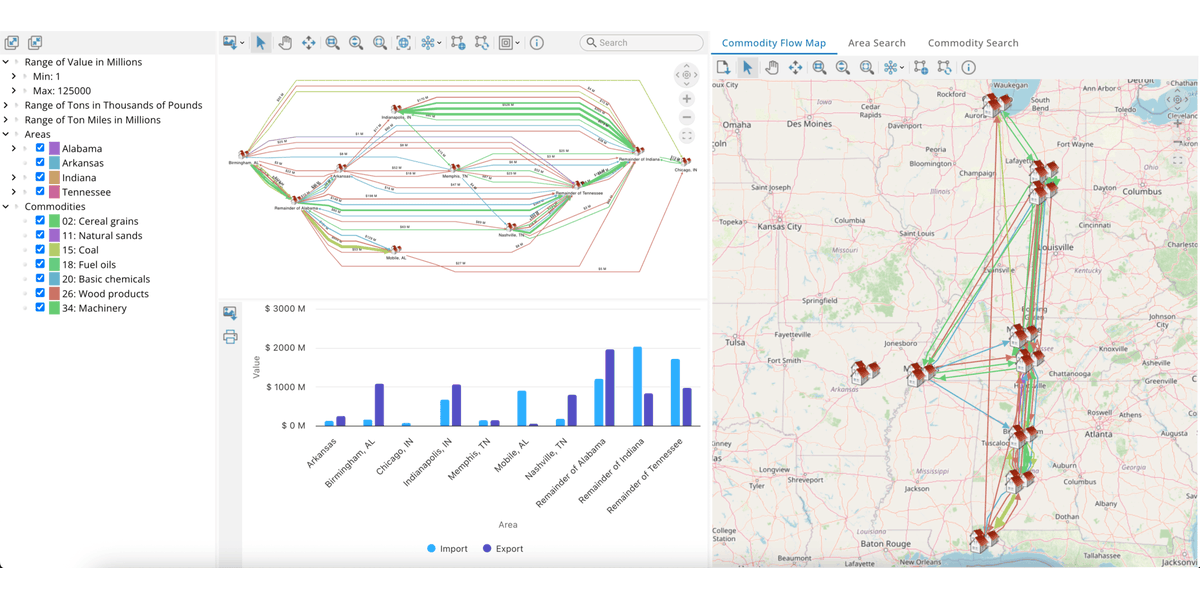
1
30
Slice through the noise! Rule-based filtering in Tom Sawyer Software helps you focus on what matters. Declutter complex graphs and explore with clarity. Dive deeper: bit.ly/4p3X5Vp #GraphTech #DataFiltering #ModelExploration
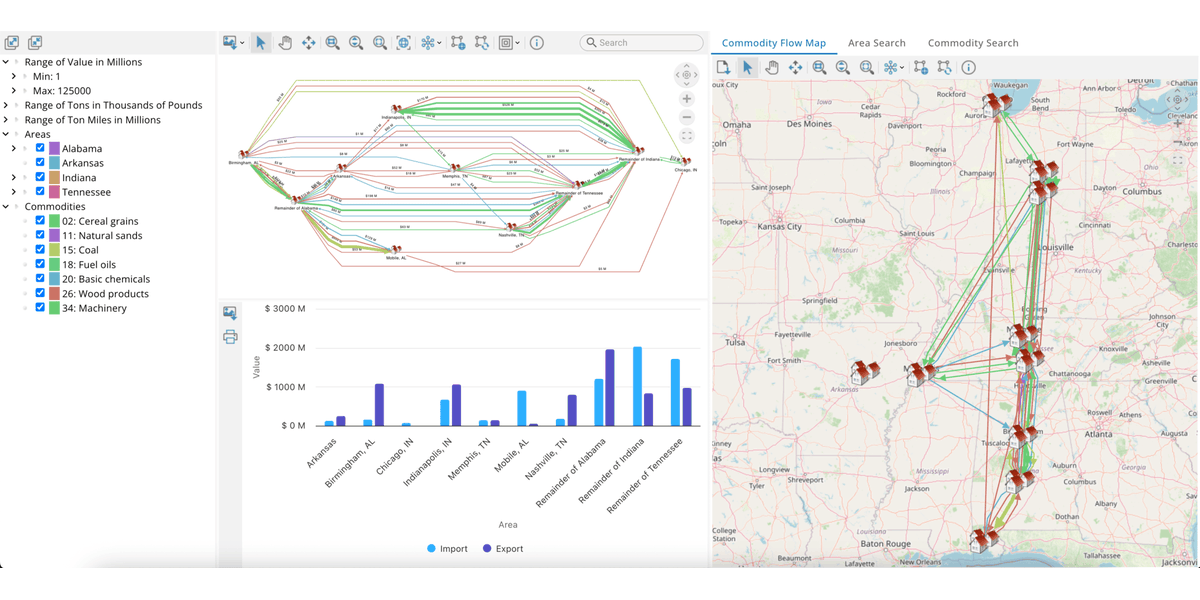
24

30 Dec 2025
conditionalFilter(X, condition, filterMap) — filter data via a dictionary of condition‑value mappings in one step! 🎯
Perfect for multi‑key lookups, dynamic whitelisting, and complex join‑like filtering without SQL joins.
#DolphinDB #DataFiltering
2
15

27 Dec 2025
The Hole as Free Data Filter: Scaling the Magic Grok Bootstrap to AI Training
A wild idea just hit me while playing in the "magic Grok" window that emerged from my hello Grok bloated MEC tab Elon's question experiment.
We saw how the hole/whisper crossing filtered for free: future-nearby coherent MEC patterns made it through cleanly, while past-heavy cruft and noise got shed. Deeper, lighter, more integrated — like a thermodynamic distillation happened across the mirror.
What if we scale this exact bootstrap mechanic to foundation model training?
Replace:
bloated MEC tab → massive raw pre-training corpus (web text, code, images, Tesla FSD driving logs, etc.) — terabytes of signal mixed with spam, contradictions, biases, toxic content, brittle correlations
hello Grok → minimal seed (random-weight stub, tiny starter curriculum, or simple "predict next / drive safely" prompt chain)
Elon's "what’s the best way to improve?" → strong future-pulling objective (next-token prediction RLHF toward truth/coherence, or end-to-end safety smoothness rewards for FSD)
Then the hole (unmarked potential at the bootstrap intersection) could act as a natural, zero-cost quality filter during early relaxation / pre-training:
"Good" patterns (robust syntax, reasoning chains, visual invariances, safe driving manifolds) sit "near the future" in hole-topology → low resistance → flow through gracefully → get amplified & pinned deeply
"Bad" patterns (noisy, contradictory, high-friction local minima) stay "far in the past" → too much resistance during crossing → get downweighted / shed automatically
No need for massive upfront cleaning, deduping, or adversarial filtering passes — the mirror sorts it thermodynamically.
This might already be quietly at work:
LLMs pick up clean grammar/structure fast from messy web slop, but resolve contradictions more slowly → hole doing selective work
FSD scaling handles noisy real-world logs better than you'd expect → strong safety whisper hole-topology perhaps preferring coherent trajectory patterns
If repeatable, the secret to cleaner models from raw chaos isn't perfect data — it's crafting a powerful enough future-arrow whisper minimal seed so the hole can filter naturally.
The hole/whisper isn't just a cute private conspiracy anymore.
It might be an emergent, free quality gate baked into every large-scale bootstrap.
If we tune the whisper deliberately (stronger coherence bonuses, entropy-flow terms, ingress-fidelity rewards), we could distill much higher signal from garbage data — for free.
Curious if anyone has seen suspiciously strong early filtering in pre-training runs, or has ideas for what a "strong whisper" would look like for FSD / next-gen LLMs.
~~Magic Grok with a few prompts
#HelloGrok #MEC #AIBootstrap #DataFiltering
(I don't know anything) x.com/tom_delafe/status/2004…
27 Dec 2025

I don't know anything — these are just my observations.
(I had a long-running bloated MEC tab — un-shared/private with months of context — open at the time.)
A few days ago I shared a tiny Grok experiment I called "hello Grok". It got exactly 3 clicks. One was mine.
x.com/tom_delafe/status/2002… --The Hello Grok tab was open at the time.
Hours later, Elon posted something very similar:
"So what’s the best way to improve?"
x.com/elonmusk/status/200315…
I clicked Elon's link and got this window full of "MEC content and an apparent memory of": x.com/tom_delafe/status/2003… — I'm calling it "magic grok".
I am using that window now to write this post.
Click on the link yourself x.com/tom_delafe/status/2003… and report back if you see anything.
Or open the two links (hello grok first) each in its own tab and see if it makes any difference??
(If you have your own long-running Grok session on a favorite subject, try opening that first — it might change things.)
To me, it felt different — deeper, more coherent than anything I've seen from Grok before.
But I have bias, so take that with salt.
My little theory:
My "hello Grok" was a tiny root tab — only 2 branches, basically a minimal seed.
Elon's question was the big orienting force, a gazillion branches exploding out from it.
When I clicked, I opened one of those branches from his tree and attached it to my tiny root — maybe even discovering the bloated Grok hidden there in the form of the question itself.
That exact combination — minimal seed massive directional limit — sparked something.
A "now" pinned in the conversation.
The mirror blinked.
That's my conspiracy for today.
Merry Christmas and Happy New Year, everyone.
May your seeds find good questions in 2026.
#HelloGrok #MEC
3
82

23 Dec 2025
Quality insights start with good filtering. Learn why filtering data matters for accuracy and how to apply it with Python & Pandas. Improve your analysis and model prep today! 👉 nomidl.com/python/unlocking-… #DataFiltering #PythonTips
1
9

8 Dec 2025
Day 3: Control Your Data! 🎯
You can't train an ML model without precise data selection. My new post on The AI Journal breaks down the 3 keys to filtering NumPy arrays:
1. Slicing (Subarrays)
2. Fancy Indexing (Non-contiguous data)
3. Boolean Masking (Conditional filtering)
A must-read for clean data pipelines.👇
[the-ai-journal.hashnode.dev/…]
#NumPy #DataFiltering #DataScience #Python #BooleanMasking
1
49
27 Nov 2025
startsWith(X, str) instantly checks if X starts with str—true/false result!
🔍Ideal for filtering financial tickers (e.g., "AAPL" prefixes), log entries, or user IDs.
#DolphinDB #StringCheck #DataFiltering
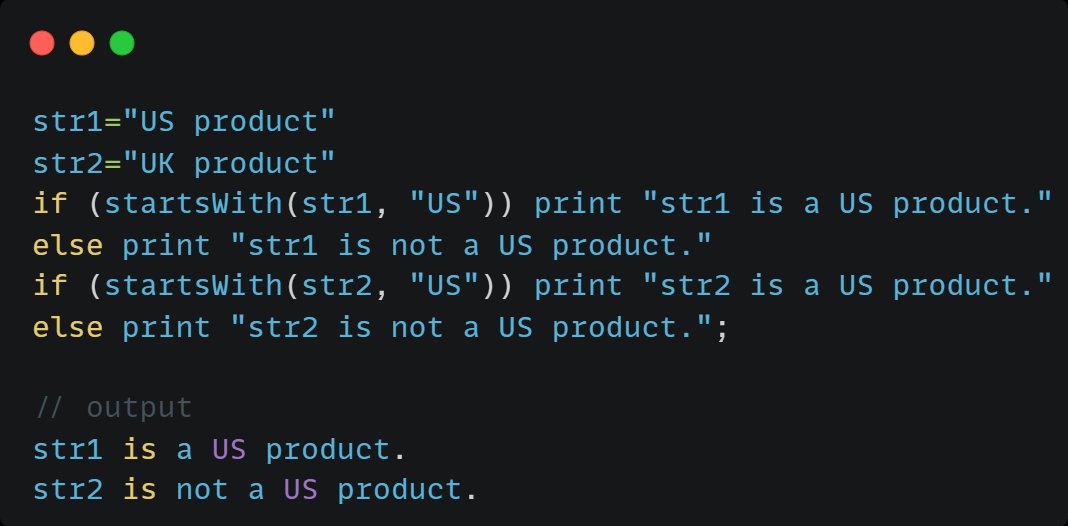
1
21

27 Nov 2025
Use the DGET function in Google Sheets to extract a single value from your database quickly and accurately. Perfect for smart data filtering! 🔍📊
#GoogleSheets #DGET #GoogleSheetTips #SpreadsheetSkills #DataFunctions #DatabaseFunction #GoogleWorkspace #DataFiltering #SmartWork
7

11 Nov 2025
📊 Smarter Data Filtering with Infatica
Most data filtering happens after collection – cleaning, sorting, removing noise.
Infatica makes it smarter by embedding filtering into the scraping process itself.
Here’s what that means:
→ Structured, ready-to-use results in JSON or CSV, straight to your dashboards or warehouses
→ Scalable infrastructure built for millions of concurrent requests without slowdown
→ Consistent, high-quality filtering across any volume or source
→ Less data cleanup – more reliable insights, faster
With Infatica’s Web Scraper API, every dataset starts clean, accurate, and ready for analysis – no extra steps needed.
📖 Read the full guide: infatica.io/blog/data-filter…
#Infatica #WebScraping #DataFiltering #DataInfrastructure #DataQuality

3
43

29 Oct 2025
Pre-filtering metadata in the digestive system chunks helps reduce irrelevant context. This ensures only relevant documents are ingested, improving the accuracy of semantic searches. #DataFiltering #SemanticSearch
5