
Jun 12
Autoregressive LLMs decode one token at a time. Diffusion LLMs decode in parallel but are hard to train without wrecking the model. Hybrid-attention backbones make each forward pass cheap but are awkward to diffuse.
We built FLARE 🔥 to get all three at once: a systematic recipe that converts a strong autoregressive hybrid-attention LLM into a diffusion LLM — where a single checkpoint decodes two ways.
→ AR-Trust: draft-and-verify speculative decoding, for quality
→ Diffusion-Trust: parallel block denoising, for speed
The headline numbers:
- 2 decoding modes from 1 checkpoint
- up to 4.8× faster decoding than open diffusion LLMs
- near-AR quality, kept from the source model
- ~10B tokens to convert (prior AR→dLLM work uses 50B–200B)
FLARE-2B/4B/9B are converted from Qwen3.5 hybrid-attention checkpoints in a single SFT stage with SGLang inference support #LLMs #DiffusionLLM #EfficientML #MachineLearning
🧵 how it works why it matters below.
1
5
39
3,219

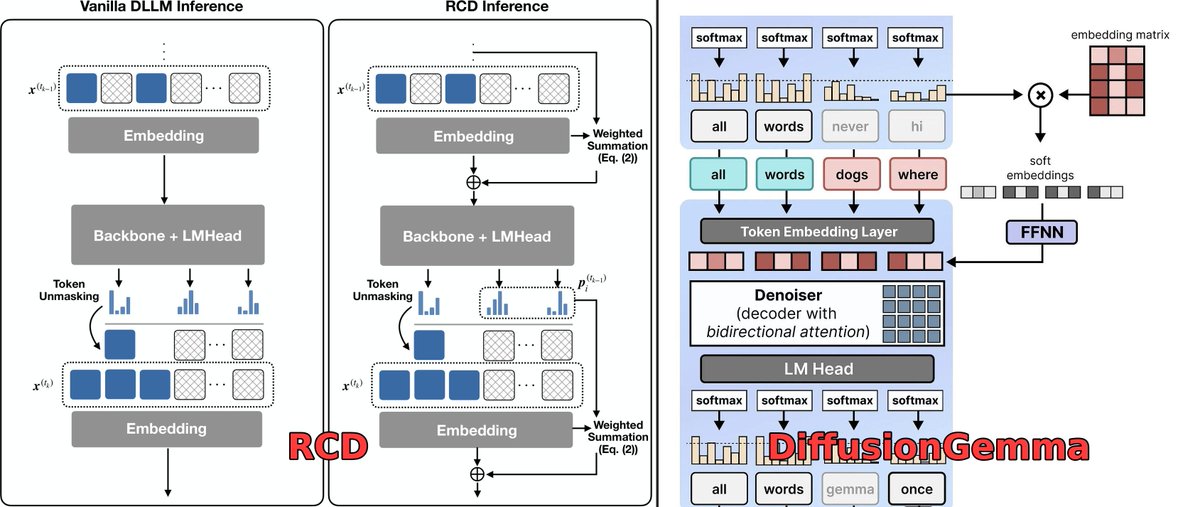
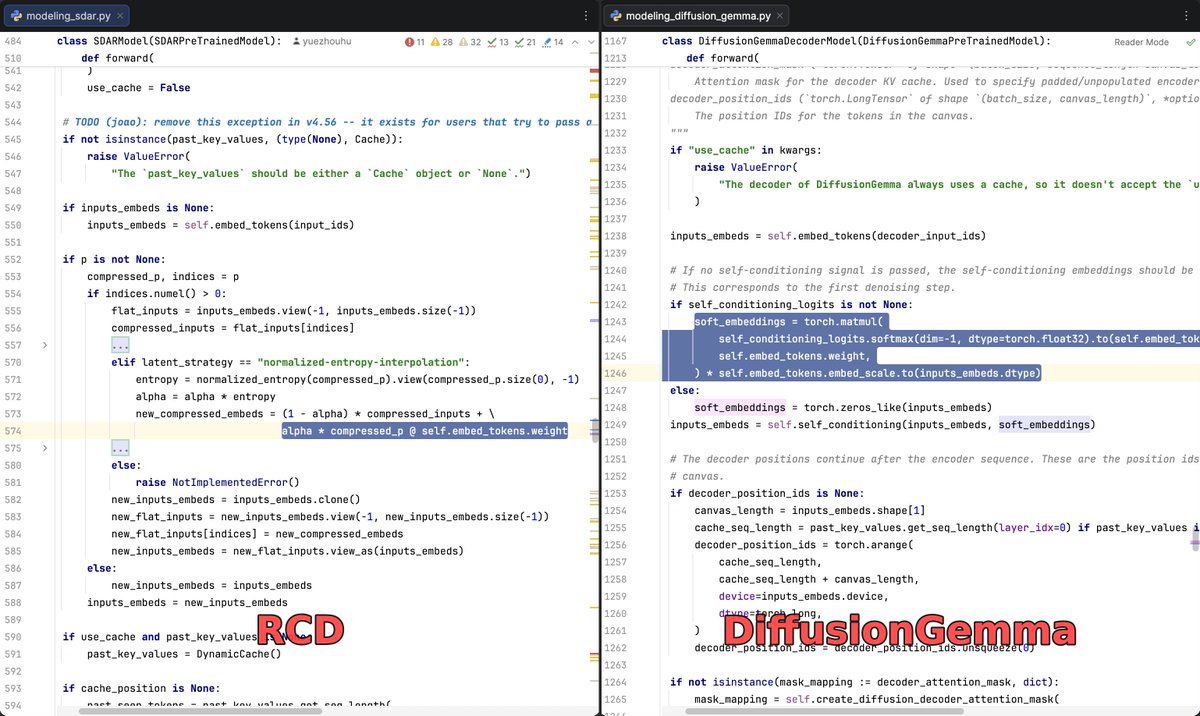
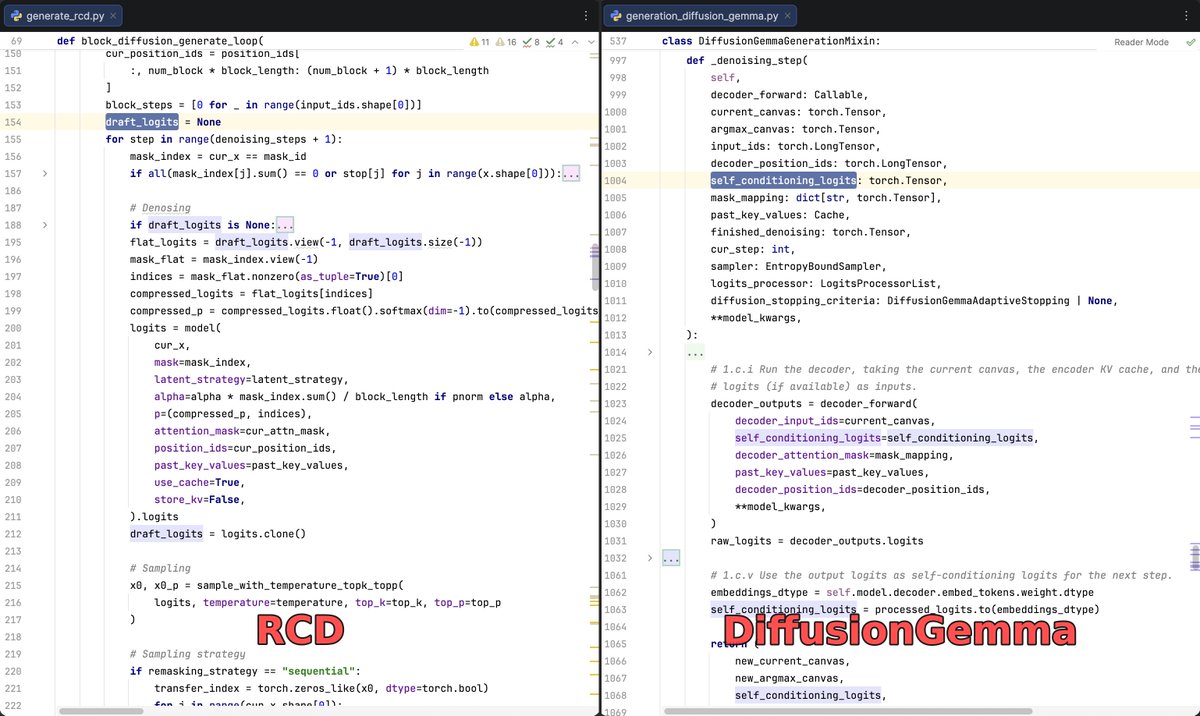
Couldn't be prouder! The core idea behind DiffusionGemma is one we introduced in RCD. That's what makes this work at such block sizes. Accepted to ICML 2026. See you in Seoul.
Read more in this thread:
#DiffusionLLM #ICML2026
Jun 12

Very excited to see that the core idea of DiffusionGemma directly stems from our work, Residual Context Diffusion (arXiv:2601.22954)! Code- and architecture-level comparisons are attached.
🏆 RCD is accepted to ICML 2026! See you in Seoul!
#DiffusionLLM #LLM #Reasoning #GenAI
2
10
1,297

Jun 12
Very excited to see that the core idea of DiffusionGemma directly stems from our work, Residual Context Diffusion (arXiv:2601.22954)! Code- and architecture-level comparisons are attached.
🏆 RCD is accepted to ICML 2026! See you in Seoul!
#DiffusionLLM #LLM #Reasoning #GenAI
4
6
34
6,542

Jun 11
DiffusionGemma: vLLM이 네이티브로 지원하는 최초의 디퓨전 언어 모델(dLLM)
(by 9bow님)
d.ptln.kr/10653
#llm #google #gemma #vllm #speculativedecoding #diffusionllm #inference
37

Jun 10
ローカルllmはクラウドllmに比べて
圧倒的に頭悪いし圧倒的に遅いが
diffusionllmなら遅い問題をクリアできると思って
待ってました
1
50
Jun 10
今のところAI普及は電気代がネックになってるので
クラウドモデルがdiffusionllm出す経済合理性がなかったけど
ローカルllmにはあったのでずっと待ってた
1
53

Apr 24
ICLR 2026 paper list of Lambda @LambdaAPI is live 📄📷!
🤖 Agentic AI
[1] In-The-Flow Agentic System Optimization for Effective Planning and Tool Use iclr.cc/virtual/2026/poster/…
[2] EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing iclr.cc/virtual/2026/poster/…
🛡️ Trustworthy AI
[3] Measuring and Mitigating Rapport Bias of Large Language Models under Multi-Agent Social Interactions iclr.cc/virtual/2026/poster/…
[4] OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always! iclr.cc/virtual/2026/poster/…
[5] Randomized Antipodal Search Done Right for Data Pareto Improvement of LLM Unlearning iclr.cc/virtual/2026/poster/…
🎧 Multimodal AI
[6] TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and CLAP-Ranked Preference Optimization iclr.cc/virtual/2025/poster/…
[7] Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling iclr.cc/virtual/2026/poster/…
🌀 Diffusion LLM
[8] Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective iclr.cc/virtual/2026/poster/…
🧪 AI for Science
[9] Align Your Structures: Generating Trajectories with Structure Pretraining for Molecular Dynamics iclr.cc/virtual/2026/poster/…
⚡ Efficient AI
[10] VideoNSA: Native Sparse Attention Scales Video Understanding iclr.cc/virtual/2026/poster/…
[11] To Compress or Not? Pushing the Frontier of Lossless GenAI Model Weights Compression with Exponent Concentration iclr.cc/virtual/2026/poster/…
[12] Mitigating Non-IID Drift in Zeroth-Order Federated LLM Fine-Tuning with Transferable Sparsity iclr.cc/virtual/2026/poster/…
Huge shoutout to all of our collaborators!
#ICLR2026 #MachineLearning #AI #gpu #ai4science #agents #worldmodel #federatedLLM #modelcompression #sparseattention #vlm #rl #diffusionLLM #MolecularDynamics #LLMUnlearning #Text2Audio #TrustworthyAI @iclr_conf @chuanli11
Apr 23

We're at @iclr_conf #ICLR2026 this year with 12 papers and two workshops.
Over 20 collaborators across @Stanford, @CarnegieMellon, @BerkeleyRDI, @Google, @nvidia, and @Microsoft helped make this work happen.

1
9
669

Mar 15
A session with Claude. Code inspired by @InceptionLabs @claudeai on a Zenbook 14 OLED Ryzen 7. #lmstudio #localLLM #claudecode #vibecoding #autowriting #diffusionLLM
2
1
134

⚡ Inception Labs: su LLM de difusión es 10 veces más rápido que Claude, ChatGPT y Gemini
Mercury 2, un modelo de lenguaje basado en difusión, promete una velocidad revolucionaria.
thenewstack.io/inception-lab…
#DiffusionLLM #LargeLanguageModels #AI #RoxsRoss
1
132

Test-time scaling on diffusion LLMs, no training: sample cheap trajectories, score steps with a PRM, stitch best partial paths.
23.8% accuracy on math and coding. 1.8x latency reduction.
arxiv.org/abs/2602.22871
#AI #MachineLearning #DiffusionLLM #TestTimeScaling #LLMs
2
If your pipeline is latency-bottlenecked and not maximum-quality-sensitive, Mercury 2 is worth serious testing. 128K context, $0.25/$0.75 per 1M tokens.
#AI #MachineLearning #DiffusionLLM #LLMs #InferenceBenchmarks
Follow @MorelMatth66161 � more threads like this.
2

Feb 26
Choc de vitesse : Mercury 2 casse le schéma “token par token”. Ici, diffusion = brouillon global puis raffiné en parallèle, comme un éditeur qui réécrit, pas une machine à écrire.
Inception annonce ~1009 tokens/s (jusqu’à ~1196 observés) et ~1,7 s de latence, avec un coût très bas (0,25$/M in, 0,75$/M out) 128K contexte.
Tu paries sur A) diffusion dLLM ou B) transformers optimisés pour rester devant ? #diffusionLLM #Mercury2 #IA
1
4
93

The AI inference game just changed fundamentally. Inception Labs launched Mercury 2 yesterday with the first commercial diffusion LLM. Instead of generating text one token at a time, it refines the entire output in parallel. The result? 1,196 tokens per second. That's 13x faster than Claude Haiku. Why does this matter for AI architects? Because in production agent systems, latency compounds at every step. A model that's 10x faster doesn't just save time — it changes what you can build. Voice assistants that feel natural. Code agents that keep pace with human thinking. Background automations that finish before you forget you started them. Meanwhile, the geopolitics are intensifying. DeepSeek reportedly trained its next model on smuggled NVIDIA Blackwell chips in Inner Mongolia. The Pentagon is threatening to invoke the Defense Production Act against Anthropic over AI safety guardrails. We're entering a phase where the architecture of AI systems both technical and political is being fundamentally renegotiated. The engineers and architects who understand both dimensions will lead what comes next.
#AIArchitecture #DiffusionLLM #Mercury2 #AIInfrastructure #AgenticAI
20

Feb 25
It's a massive shift in AI architecture. As, we are moving beyond the "One. Token. At. A. Time." bottleneck of traditional models.
For years, we’ve accepted that LLMs must be slow because they are autoregressive (i.e. they have to predict word A before they can even think about word B.)
But unlike traditional models, instead of building a sentence brick-by-brick, dLLMs sketch the entire response at once and "denoise" it into clarity.
Why this matters:
Faster: It hits 1,000 tokens/sec, leaving speed-optimized models in the dust.
Reasoning Redefined: Because it sees the whole "canvas" at once, it can correct its own logic mid-generation.
Cheaper Inference: Parallel generation means less GPU waste and lower costs for developers.
The "token-by-token" era isn't over, but it finally has a serious challenger.
#AI #MachineLearning #DiffusionLLM #Mercury2 #GenerativeAI
223


Not so much but current algo gives 5x faster text generation for the llada model.
But no good conference to submit my work.
Please suggest something good 🙏
#Diffusionllm
6
148

Feb 14
OpenAIはハードウェア投資的にDiffusionLLMに行きづらいけど、GoogleとAnthropic陣営は行きやすい
中国も行きづらいからアメリカの勝ち目はそこなのでは?
1
163
Feb 2
Take a look at Residual Context Diffusion (RCD): a simple idea to boost diffusion LLMs—stop wasting “remasked” tokens!!!
arxiv.org/abs/2601.22954
(Example on AIME24. RCD increases parallelism by 4x while reaching the baseline's peak accuracy.)
#DiffusionLLM #LLM #Reasoning #GenAI
3
36
202
38,817

Jan 23
New paper alert🥳checkout our new paper JustGRPO for diffusionLLM.
We rethink the value of arbitrary decoding and find it will lower the reasoning capacity coverage (pass
@k) compared to AR. So we train RL with AR which is a base with higher pass, which lead to stronger RL model
Jan 23

🚨The "killer feature" of diffusion LLMs (arbitrary order) might actually be killing their reasoning potential.
🚀Introducing JustGRPO: An embarrassingly simple approach for better realizing reasoning potential in dLLMs.
🔗huggingface.co/papers/2601.1…
First author @ZanlinNi1
🧵⬇️

2
5
58
6,060