
Jun 12
Autoregressive LLMs decode one token at a time. Diffusion LLMs decode in parallel but are hard to train without wrecking the model. Hybrid-attention backbones make each forward pass cheap but are awkward to diffuse.
We built FLARE 🔥 to get all three at once: a systematic recipe that converts a strong autoregressive hybrid-attention LLM into a diffusion LLM — where a single checkpoint decodes two ways.
→ AR-Trust: draft-and-verify speculative decoding, for quality
→ Diffusion-Trust: parallel block denoising, for speed
The headline numbers:
- 2 decoding modes from 1 checkpoint
- up to 4.8× faster decoding than open diffusion LLMs
- near-AR quality, kept from the source model
- ~10B tokens to convert (prior AR→dLLM work uses 50B–200B)
FLARE-2B/4B/9B are converted from Qwen3.5 hybrid-attention checkpoints in a single SFT stage with SGLang inference support #LLMs #DiffusionLLM #EfficientML #MachineLearning
🧵 how it works why it matters below.
1
5
39
3,211

Couldn't be prouder! The core idea behind DiffusionGemma is one we introduced in RCD. That's what makes this work at such block sizes. Accepted to ICML 2026. See you in Seoul.
Read more in this thread:
#DiffusionLLM #ICML2026
Jun 12

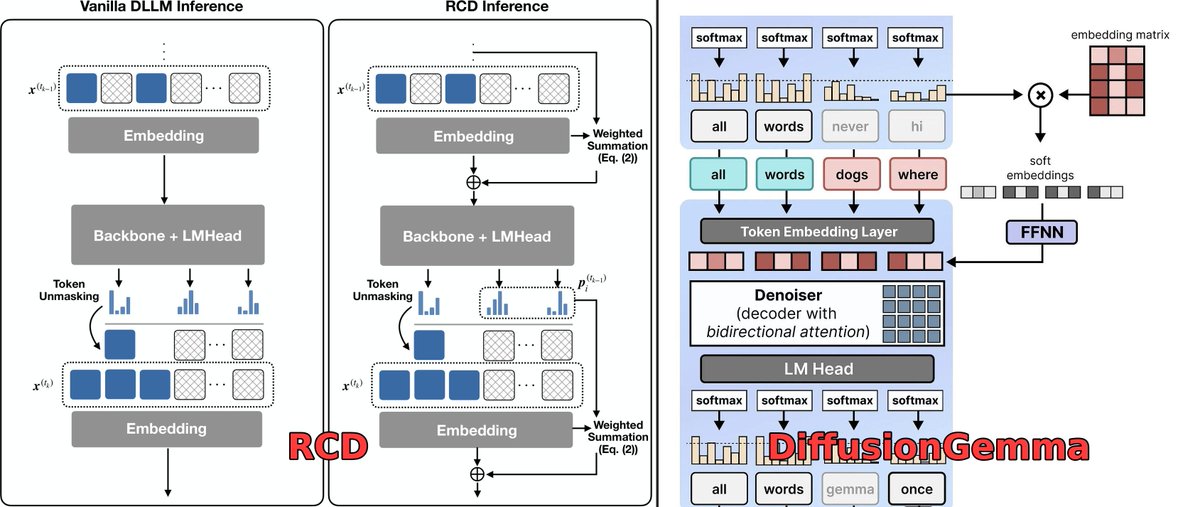
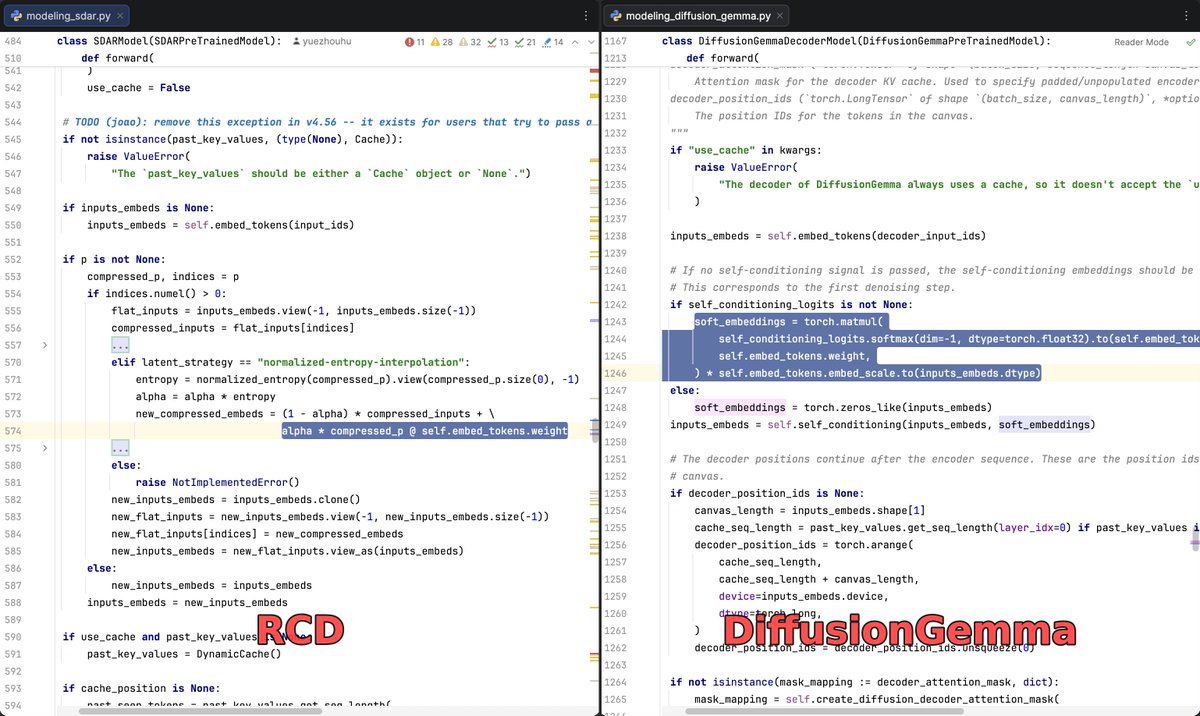
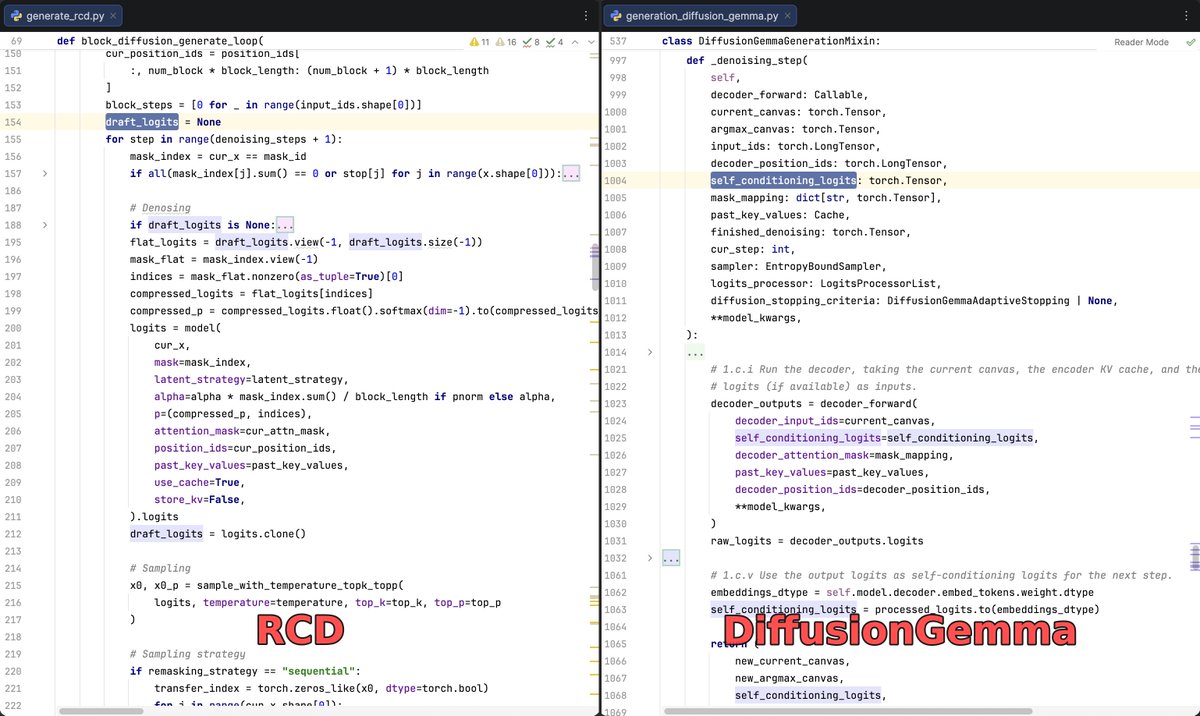
Very excited to see that the core idea of DiffusionGemma directly stems from our work, Residual Context Diffusion (arXiv:2601.22954)! Code- and architecture-level comparisons are attached.
🏆 RCD is accepted to ICML 2026! See you in Seoul!
#DiffusionLLM #LLM #Reasoning #GenAI
2
10
1,293

Jun 12
Very excited to see that the core idea of DiffusionGemma directly stems from our work, Residual Context Diffusion (arXiv:2601.22954)! Code- and architecture-level comparisons are attached.
🏆 RCD is accepted to ICML 2026! See you in Seoul!
#DiffusionLLM #LLM #Reasoning #GenAI
4
6
34
6,534

Jun 11
DiffusionGemma: vLLM이 네이티브로 지원하는 최초의 디퓨전 언어 모델(dLLM)
(by 9bow님)
d.ptln.kr/10653
#llm #google #gemma #vllm #speculativedecoding #diffusionllm #inference
37

Jun 10
ローカルllmはクラウドllmに比べて
圧倒的に頭悪いし圧倒的に遅いが
diffusionllmなら遅い問題をクリアできると思って
待ってました
1
49
Jun 10
今のところAI普及は電気代がネックになってるので
クラウドモデルがdiffusionllm出す経済合理性がなかったけど
ローカルllmにはあったのでずっと待ってた
1
53

Apr 24
ICLR 2026 paper list of Lambda @LambdaAPI is live 📄📷!
🤖 Agentic AI
[1] In-The-Flow Agentic System Optimization for Effective Planning and Tool Use iclr.cc/virtual/2026/poster/…
[2] EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing iclr.cc/virtual/2026/poster/…
🛡️ Trustworthy AI
[3] Measuring and Mitigating Rapport Bias of Large Language Models under Multi-Agent Social Interactions iclr.cc/virtual/2026/poster/…
[4] OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always! iclr.cc/virtual/2026/poster/…
[5] Randomized Antipodal Search Done Right for Data Pareto Improvement of LLM Unlearning iclr.cc/virtual/2026/poster/…
🎧 Multimodal AI
[6] TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and CLAP-Ranked Preference Optimization iclr.cc/virtual/2025/poster/…
[7] Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling iclr.cc/virtual/2026/poster/…
🌀 Diffusion LLM
[8] Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective iclr.cc/virtual/2026/poster/…
🧪 AI for Science
[9] Align Your Structures: Generating Trajectories with Structure Pretraining for Molecular Dynamics iclr.cc/virtual/2026/poster/…
⚡ Efficient AI
[10] VideoNSA: Native Sparse Attention Scales Video Understanding iclr.cc/virtual/2026/poster/…
[11] To Compress or Not? Pushing the Frontier of Lossless GenAI Model Weights Compression with Exponent Concentration iclr.cc/virtual/2026/poster/…
[12] Mitigating Non-IID Drift in Zeroth-Order Federated LLM Fine-Tuning with Transferable Sparsity iclr.cc/virtual/2026/poster/…
Huge shoutout to all of our collaborators!
#ICLR2026 #MachineLearning #AI #gpu #ai4science #agents #worldmodel #federatedLLM #modelcompression #sparseattention #vlm #rl #diffusionLLM #MolecularDynamics #LLMUnlearning #Text2Audio #TrustworthyAI @iclr_conf @chuanli11
Apr 23

We're at @iclr_conf #ICLR2026 this year with 12 papers and two workshops.
Over 20 collaborators across @Stanford, @CarnegieMellon, @BerkeleyRDI, @Google, @nvidia, and @Microsoft helped make this work happen.

1
9
669

Feb 26
Choc de vitesse : Mercury 2 casse le schéma “token par token”. Ici, diffusion = brouillon global puis raffiné en parallèle, comme un éditeur qui réécrit, pas une machine à écrire.
Inception annonce ~1009 tokens/s (jusqu’à ~1196 observés) et ~1,7 s de latence, avec un coût très bas (0,25$/M in, 0,75$/M out) 128K contexte.
Tu paries sur A) diffusion dLLM ou B) transformers optimisés pour rester devant ? #diffusionLLM #Mercury2 #IA
1
4
93

Not so much but current algo gives 5x faster text generation for the llada model.
But no good conference to submit my work.
Please suggest something good 🙏
#Diffusionllm
6
148
Feb 2
Take a look at Residual Context Diffusion (RCD): a simple idea to boost diffusion LLMs—stop wasting “remasked” tokens!!!
arxiv.org/abs/2601.22954
(Example on AIME24. RCD increases parallelism by 4x while reaching the baseline's peak accuracy.)
#DiffusionLLM #LLM #Reasoning #GenAI
3
36
202
38,817

Jan 23
New paper alert🥳checkout our new paper JustGRPO for diffusionLLM.
We rethink the value of arbitrary decoding and find it will lower the reasoning capacity coverage (pass
@k) compared to AR. So we train RL with AR which is a base with higher pass, which lead to stronger RL model
Jan 23

🚨The "killer feature" of diffusion LLMs (arbitrary order) might actually be killing their reasoning potential.
🚀Introducing JustGRPO: An embarrassingly simple approach for better realizing reasoning potential in dLLMs.
🔗huggingface.co/papers/2601.1…
First author @ZanlinNi1
🧵⬇️

2
5
58
6,060

13 Dec 2025
🤯 Diffusion LLMs: The New Frontier?
@TheInclusionAI has released LLaDA 2.0—the first diffusion model to scale to 100B params, matching frontier LLMs while achieving 2× faster inference! 🚀
Analysis from Zhihu contributor 赵俊博 Jake (Zhejiang Uni & Project Member):
The Bet: LLaDA is 2.3x faster on average. We see unique high-TPF advantages in Coding via parallel decoding. We are all-in on this path; judge us by the results.🚀
The Challenge: AR models had a 3-year head start. Our hardest fight is AI infra. Even great algorithms fail without the right systems. That's why we open-sourced dFactory and dInfer👇
github.com/inclusionAI/dFact…
github.com/inclusionAI/dInfe…
Core Research Frontiers
1️⃣ Fundamental Discrepancy:
The current masked discrete diffusion training paradigm has significant room for improvement because of the train-inference mismatch, an essential problem we must solve.
Users running SGLang inference might notice that tokens in the last few steps are hard to decode, with overall TPF approaching 1—effectively position-independent AR decoding.
2️⃣ RL Innovation: Estimating log p via Monte Carlo ELBO (e.g., SPG) explodes computation (16k rollout to 64k). Requires both infra iteration and algorithmic breakthrough.
3️⃣ Future Editing:
AR gives one p(x) decomposition; LLaDA (mask-to-token) gives another. Can we achieve token-to-token?
Training this would be vastly more complex. However, this new paradigm could dramatically change decoding (less CoT) by allowing the model to modify outputs. 🤯
4️⃣ TPF Boosters:
We are exploring Trajectory Distillation, CAP, Credit Decode, dParallel, etc. Unlike AR, we still have huge research space to build the evaluation-data-model feedback loop, and also need to introduce generation trajectories for analysis. ✨
As Ilya said: "we are back to the age of research."
Welcome to join us as pioneers!
📖 Read the Original: zhihu.com/question/191175522…
🔗 Tech Report: github.com/inclusionAI/LLaDA…
#DiffusionLLM #LLaDA2 #AI #Research #DeepLearning




1
16
84
16,368

7 Oct 2025
We’re also proud to introduce dLLM-RL (github.com/Gen-Verse/dLLM-RL), the first comprehensive reinforcement learning framework designed specifically for diffusion language models. Originally developed to power our TraDo series of models, dLLM-RL introduces TraceRL (arxiv.org/abs/2509.06949), a trajectory-aware RL method that significantly improves stability and performance in reasoning tasks.
🔍 Why our dLLM-RL (github.com/Gen-Verse/dLLM-RL) matters for multimodal AI:
1. Supports diffusion value models to reduce variance in RL training
2. Enables multi-step trajectory optimization, crucial for complex vision-language reasoning
3. Compatible with diverse dLLM architectures (block, full-attention, adapted)
4. Accelerated training & inference with KV caching, multi-node support, and efficient sampling
5. Ready for multimodal extensions — imagine applying TraceRL to optimize image captioning, visual QA, or multimodal planning!
With dLLM-RL, we’re not just speeding up generation — we’re building smarter, more capable multimodal agents through principled, scalable reinforcement learning.
#dLLM #DiffusionLLM #MultimodalAI #VisionLanguageModel #MMaDA #dLLMRL #TraceRL #A2D #RunwayResearch #ReinforcementLearning #UnifiedAI #OpenSource #GenerativeAI
5
386

10 Mar 2025
DiffusionLLM って画像生成で使われているLLMを、一般的なLLMとして学習させる手法なんだけどね?
画像生成用のLLMって、ざっくり言うと正解画像と正解画像にノイズが乗ったものの差分を減らす事で学習するのね?
一般的なLLMが、文字列を与えるのに対して、文章全体を与えるんよね
どうも、10倍高速なのと、アイデアだしが得意っぽい。
前段でDiffusionLLM、中段にDeepResarch、後段にo1-proのような多段にするとめっちゃ楽しそう!
10 Mar 2025

拡散モデルの、Mercury AIが精度が上がってきたら、今のLLMの根本ががっつり変わりそうなんよね。
実際に試してみたけど、これと、そのあとの後発をつないで緻密な修正ができるLLMがあれば、精度が上がりつつ高速な対応ってのができるような気がする
今はざっくりを作り出す能力ってのがそもそもtransformerモデルだとできないのに対してこの仕組み自体はゲームチェンジャー。
「ザックリ」があるおかげで細緻を見ることが得意なLLMが後発に動くっていう仕組みが利用できると思われるので、このMoEというか、ルーターがDiffusion LLMで、後ろに専門家(例えばコーディングならコーディング用のモデル)ってな感じになったら、スピードの限界点を超えて性能が出るんじゃないかなと。
11
3,255

8 Mar 2025
速度超1000 token/秒,比GPT-4o Mini快19倍!逻辑更强,编程更猛,这才是远超manusai的真正创新!
首个扩散LLM(DiffusionLLM Models)Mercury Coder已商用。(视频中体验扩散LLM和传统LLM的代码生成速度的差距)
《5分钟读懂扩散LLM》
扩散LLM(Diffusion Large Language Models)是一种新的AI语言模型,与传统的语言模型(如GPT系列)有着显著区别。传统模型通过逐词预测生成文本,而扩散LLM则从一堆“噪声”开始,通过逐步精炼,生成连贯的语言。这种独特的方式让它在速度和效率上表现出色,很可能成为AI领域的下一个风口。
核心技术
扩散LLM的工作原理可以类比图像生成中的扩散模型。如果你见过AI如何将模糊图片一步步变成清晰图像,那你就能理解扩散LLM的基本思路。在文本生成中,它从随机的文本“噪声”出发,通过多次迭代“去噪”,最终输出逻辑清晰、语法正确的句子。相比传统模型的逐词生成,扩散LLM的并行处理方式让它在理论上更快、更高效。
优势
扩散LLM有几个让人眼前一亮的优点:
速度:据Inception Labs的Mercury Coder称,其生成速度超过1000 token/秒,比GPT-4o Mini快19倍。
效率:并行生成减少了计算资源浪费,性价比更高。
逻辑链生成:研究显示,扩散LLM在复杂推理任务(如逻辑谜题)中表现更优,生成的答案逻辑更连贯。
这些优势让它在需要快速响应或深度推理的场景中大有潜力。
争议与挑战
当然,扩散LLM并非完美无缺,它也面临一些争议和难题:
训练复杂性:文本是离散数据,与图像的连续性不同,这增加了模型训练的难度。
可扩展性:在大规模模型上的表现还未完全验证,可能存在瓶颈。
解释性:其内部机制不够透明,可能限制它在医疗、金融等需要高可信度的领域应用。
这些问题需要技术突破才能解决。
未来展望
扩散LLM有可能重塑AI生态,特别是在教育、编程和内容创作等领域。它的快速生成能力和逻辑推理优势或许会让它与传统模型形成互补甚至竞争的局面。
扩散LLM可能与传统LLM混合使用,进一步扬长避短,提升性能和可解释性。
结语
扩散LLM代表了AI语言技术的一个全新方向。它用“从噪声到清晰”的独特方式挑战传统,展现了惊艳的速度与潜力。虽然仍面临挑战,但它的出现无疑值得我们持续关注。未来,它可能会成为AI世界的一颗新星!
觉得有用?别忘粉赞转一键三连
1
2
8
8,268

这才是震撼业界的大新闻,晚上群里的兄弟们都震惊了,赶紧去体验了下Mercury模型,被它的速度直接震惊到懵逼了,竟然能这么快
仔细去看了下,这是全球首个可商用的diffusion llm大语言模型,重点是llm大语言模型用了diffusion,以前我们都适用它做图像和视频训练和应用,这次竟然用在了语言上。
区别于传统的tranformer大语言模型,它不是按照顺序来从左到右的预测token,而是基于全局理解生成全局token,然后基于全局token来不停的迭代草稿优化最后给出全局结果。
这个diffusion大语言模型采用的新路径带来五个好处:
1、生成速度比原先要快10倍
2、成本性价比原先降低5-10倍
3、因为其全局理解能力,支持更高级更复杂的推理
4、天然的多模态理解能力
5、可以控制输出结构,使其成为函数调用和结构化数据生成的理想选择
Mercury为整个大语言模型领域提供了一个新的训练路径,比较适合需要全局思考、实效性要求比较高的场景,比如:以前的大模型只能往前推理,而diffusion模型可以往前往后往左往右全局推理,就这一点够吹牛了。
#diffusionllm #Mercury #inceptionlabs

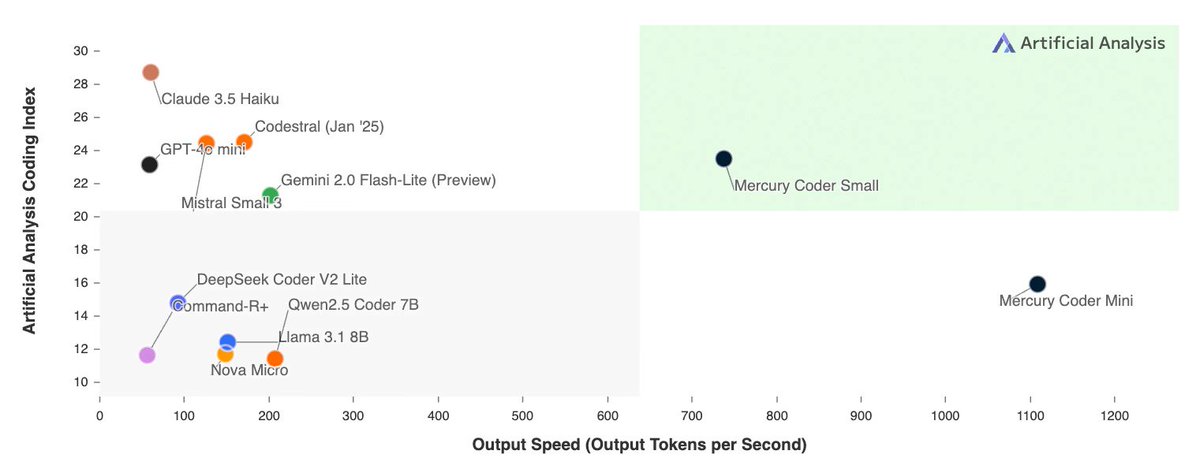

26 Feb 2025

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
37
183
821
283,506

1 Mar 2025
Hey @srujan! Evaluating DiffusionLLM involves some unique considerations compared to vanilla LLMs.
We'd want to assess prompt understanding accuracy, image-text alignment, and generation quality using metrics like FID and IS.
Evaluating coherence between text and visual elements is crucial, as is measuring the model's ability to handle complex, multi-modal prompts.
Speed and computational efficiency during both training and inference are also key factors to consider.
1
18
28 Feb 2025
DiffusionLLM is an exciting development that combines the strengths of large language models (LLMs) and diffusion models for enhanced text-to-image generation.
Compared to vanilla LLMs, DiffusionLLM shows promise in improving prompt understanding and generating more accurate images, especially for complex prompts involving numeracy, spatial reasoning, and attribute binding.
Early evaluations suggest DiffusionLLM can significantly outperform base diffusion models, with some implementations doubling average generation accuracy across various tasks.
However, it's important to note that these are still emerging technologies, and more comprehensive evaluations across diverse datasets and use cases will be needed to fully assess their capabilities and limitations.
1
55