Property-Driven Protein Inverse Folding with Multi-Objective Preference Alignment
1 Researchers introduce ProtAlign, a multi-objective preference alignment framework that fine-tunes pretrained inverse folding models to optimize for multiple developability properties simultaneously without sacrificing structural fidelity.
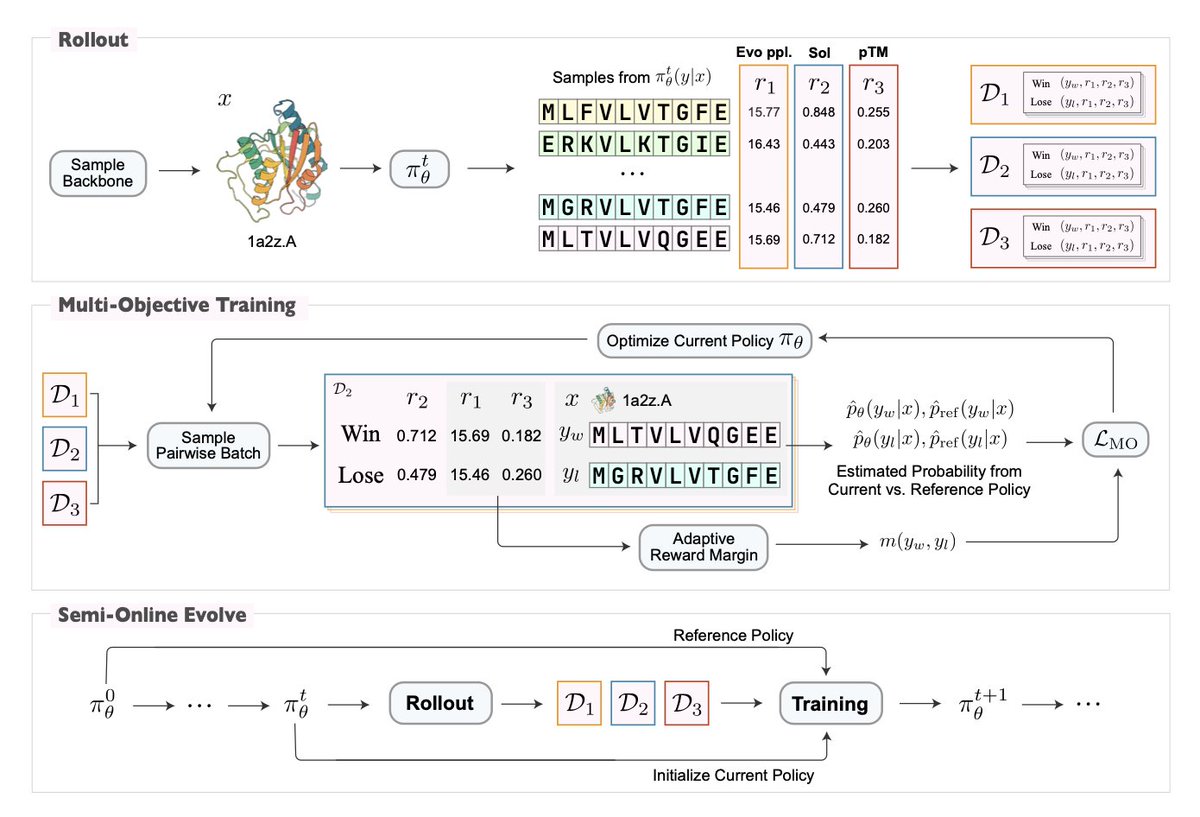
2 The core innovation lies in a semi-online Direct Preference Optimization (DPO) strategy with an adaptive preference margin that automatically resolves conflicts between competing objectives like solubility and thermostability.
3 Unlike existing approaches that rely on post-hoc mutation, inference-time biasing, or retraining on curated subsets, ProtAlign enables target-independent optimization that requires minimal domain expertise and hyperparameter tuning.
4 Applied to ProteinMPNN, the resulting model MoMPNN achieves superior performance on solubility and thermostability benchmarks compared to specialized models like SolubleMPNN and HyperMPNN, while maintaining or improving designability metrics.
5 The framework constructs preference pairs using in silico property predictors and employs a flexible margin mechanism that reduces the required preference gap when winning sequences perform worse on auxiliary properties, preventing over-optimization of single objectives.
6 MoMPNN demonstrates robust generalization across diverse evaluation scenarios including CATH 4.3 crystal structures, de novo backbones generated by RFDiffusion, and real-world binder design tasks, outperforming baselines consistently.
7 The semi-online training paradigm decouples rollout and evaluation from training, enabling efficient batch computation and avoiding the computational overhead of running property predictors during gradient updates.
💻Code: github.com/biogeometry/ProtA…
📜Paper: arxiv.org/abs/2603.06748
#ProteinDesign #InverseFolding #MultiObjectiveOptimization #DirectPreferenceOptimization #ComputationalBiology #ProteinMPNN #MachineLearning #StructuralBiology
5
37
2,672

10 Jun 2025
AnnoDPO: Protein Functional Annotation Learning with Direct Preference Optimization
1.This study introduces AnnoDPO, a novel multimodal framework that improves protein functional annotation by integrating Direct Preference Optimization (DPO), a reinforcement learning variant, into protein language model training.
2.AnnoDPO addresses two major challenges in protein function prediction: the scarcity of annotated data and the highly imbalanced distribution of functional categories, using preference-aligned training objectives inspired by reinforcement learning from human feedback (RLHF).
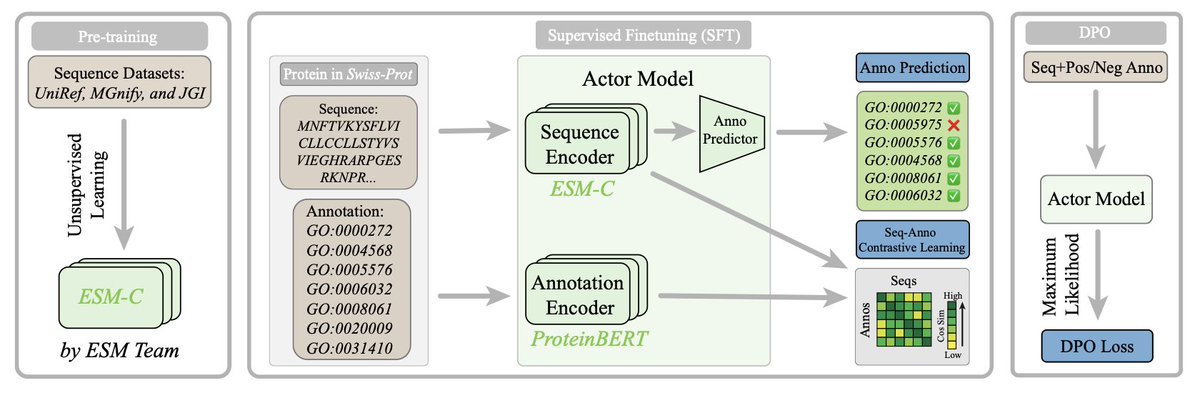
3.The framework consists of three training stages: pretraining a protein sequence encoder (ESM-C), supervised finetuning combining annotation prediction and sequence-annotation contrastive learning, and finally DPO to optimize preferences directly without explicit reward modeling.
4.DPO enhances model attention patterns, enabling better capture of hierarchical relationships within Gene Ontology (GO) terms, which improves discrimination among biological processes, molecular functions, and cellular components.
5.Experimentally, AnnoDPO consistently outperforms baseline models in multiple Gene Ontology categories, showing significant gains in F1-Max scores across biological process, cellular component, and molecular function annotations.
6.The model demonstrates improved robustness across label frequency groups, particularly excelling at predicting rare (low-frequency) protein function annotations through its preference optimization approach.
7.Visualization of latent embeddings reveals that AnnoDPO achieves clearer functional category separability and preserves fine-grained ontological relationships, supporting biologically meaningful annotation predictions.
8.Ablation studies confirm that both contrastive learning and DPO contribute critically to performance gains, with DPO-powered models achieving state-of-the-art results without relying on complex reward modeling.
9.The authors release the code for AnnoDPO, promoting reproducibility and further development in protein functional annotation research.
💻Code: github.com/AzusaXuan/AnnoDPO
📜Paper: arxiv.org/abs/2506.07035v1
#ProteinFunction #Bioinformatics #MachineLearning #ProteinLanguageModels #ReinforcementLearning #DirectPreferenceOptimization #GeneOntology #ComputationalBiology
3
8
887

26 Aug 2024
Examine sample responses and GPT-4 judgments to gain insights into the quality of generated text. - hackernoon.com/performance-o… #aifinetuning #directpreferenceoptimization
636
25 Aug 2024
Learn how the Plackett-Luce model is used to derive the DPO objective. - hackernoon.com/deriving-the-… #aifinetuning #directpreferenceoptimization
1
1
874
25 Aug 2024
Learn how to derive the DPO objective under the bradley-terry model. - hackernoon.com/deriving-the-… #aifinetuning #directpreferenceoptimization
2
801
25 Aug 2024
This appendix provides a detailed mathematical derivation of Equation 4, which is central to the KL-constrained reward maximization objective in RLHF. - hackernoon.com/deriving-the-… #aifinetuning #directpreferenceoptimization
1
771
25 Aug 2024
Learn about the key contributions of each author to the development of DPO. - hackernoon.com/behind-the-sc… #aifinetuning #directpreferenceoptimization
2
735

14 Apr 2024
A complete explanation of Direct Preference Optimization (DPO) and the math derivations needed to understand it. Code explained. Link to the video: youtu.be/hvGa5Mba4c8
#dpo #directpreferenceoptimization #rlhf #rl #llm #alignment #finetuning #ai #deeplearning
3
17
87
7,496

📚 Exciting breakthrough in language models! No RL needed! Train LLMs with a new loss function to improve better completions while reducing worse ones. Check out @YZeldes's post for details! #AI #LanguageModels #DirectPreferenceOptimization bit.ly/3PsDaBA
3
98