
FlexFlow Airbox
#GreberRacing
greberracing.com/store/p/fle…
75
Yogesh Verma retweeted
Flexible Flows for Biological Sequence Design
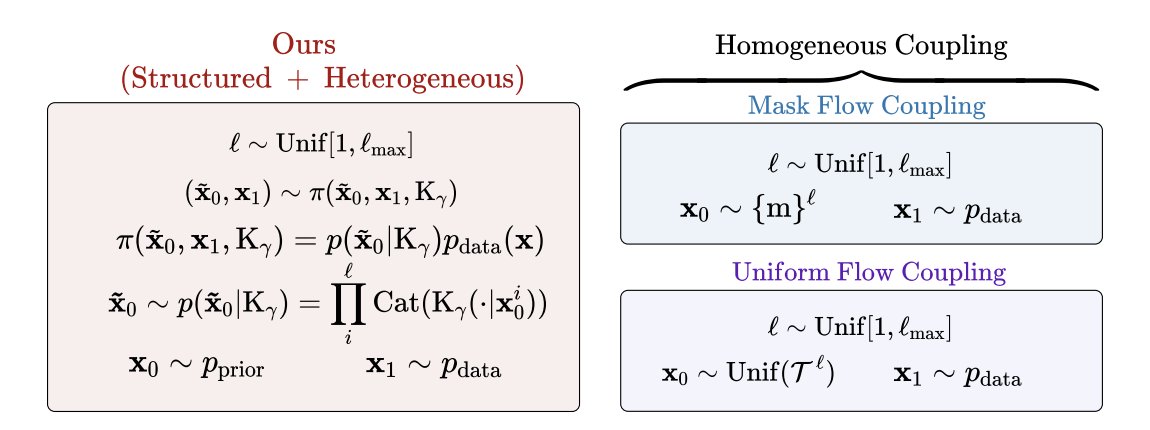
1. FlexFlow reframes discrete flow matching for biological sequences by changing the coupling (forward endpoint pairing) rather than the training objective: a structured, biology-informed coupling uses substitution matrices (e.g., BLOSUM for proteins; JC69/HKY85-style biases for nucleotides) to tilt the source distribution toward evolutionarily plausible neighborhoods.
2. The key idea is to keep the standard token-wise mixture path and CTMC machinery intact, but swap the usual “uninformative” couplings (uniform/masked) with a transition kernel Kγ that encodes preferred substitutions; when Kγ is uniform, the method reduces to the standard uniform coupling.
3. For variable-length generation, FlexFlow builds on Edit Flows by parameterizing reverse-time CTMC rates via edit operations (insertion, deletion, substitution). Instead of treating positions independently, it introduces a shared global latent r that conditions per-position edit decisions, coupling token-level operations through sequence-level context.
4. FlexFlow adds test-time control over edit behavior: operation probabilities are temperature-scaled and modeled with a Dirichlet prior over {ins, sub, del}. By changing Dirichlet concentrations α post-hoc, users can bias generation toward more insertions vs substitutions vs deletions without retraining, effectively acting as an “operation budget controller.”
5. The paper proposes latent classifier-free guidance (CFG) as an alternative to rate-space guidance: it performs CFG by interpolating conditional/unconditional latents (rc and r∅) in continuous space, then uses the guided latent to drive all edit operations jointly—aiming for more globally coherent conditioning than token-wise rate guidance.
6. The latent guidance has a probabilistic interpretation: under Gaussian conditional/unconditional latent encodings and sufficiency assumptions, the guidance direction corresponds to the score of an implicit classifier p(c|r), making the latent interpolation analogous to a gradient ascent step on log p(c|r).
7. Training uses an augmented alignment space with a blank token ε to make edit-based objectives tractable: alignments define edit sequences between endpoints, and a Bregman-divergence-style loss penalizes extraneous rates while rewarding edits that move xt toward x1.
8. DNA enhancer generation (unconditional, length 500) on fly brain and melanoma ATAC-seq datasets: FlexFlow achieves the best Fréchet Biological Distance among compared diffusion/flow baselines at the same sampling budget (100 reverse steps), and ablations indicate combining a frequency-informed prior with structured coupling performs best.
9. Conditional promoter design (human promoters, length 1024) conditioned on transcription initiation profiles: FlexFlow improves MSE of predicted regulatory activity versus prior baselines, with latent guidance outperforming rate guidance (reported 0.022 vs 0.024 MSE at 100 steps), suggesting benefits from global latent steering.
10. A new peptide–MHC II conditional generation benchmark is introduced using eluted ligand data with a strict split where no 9-mer is shared across train/test clusters. On this task, FlexFlow greatly improves a held-out DeepMHCII-based discriminator score (rate guidance 0.58; latent guidance 0.66), while highlighting a quality–diversity tradeoff (latent guidance can improve plausibility while worsening embedding-distance coverage metrics).
📜Paper: arxiv.org/abs/2606.10543
#ComputationalBiology #GenerativeModels #FlowMatching #DiffusionModels #ProteinDesign #DNADesign #PeptideDesign #MHC #MachineLearning #Bioinformatics
3
16
1,488
FlexFlow Airbox
#GreberRacing
greberracing.com/store/p/fle…
135

May 20
Google just dropped “Vibe Coding” for Android… and it feels illegal. 🤯
You describe an app idea in plain English → Gemini instantly generates a full native Android app using Kotlin Jetpack Compose… then lets you test it directly on your phone.
No boilerplate.
No endless setup.
No 3-week prototype cycle.
In the demo, they built “FlexFlow” — a stretching routine app — and it was install-ready in minutes.
This is where Google changes the game for builders.
Imagine shipping:
• AI bots
• crypto tools
• trading dashboards
• SaaS MVPs
• side projects
…before most people even finish setting up Android Studio.
“Vibe Coding” is about to create a whole new generation of Android developers.
What’s the first app you’d vibe code?
4
8
18
1,384

Google acaba de romper el juego con “Vibe Coding”
Le dices qué app quieres y Gemini te genera una app nativa de @Android completa (Kotlin Jetpack Compose) en segundo y la pruebas directo en tu celular.
Estoy sorprendido de estas tools para prototipos. Imagínate armar bots, tools de trading o apps crypto en minutos.
En el video hicieron “FlexFlow” (rutina de estiramientos) y quedó lista para instalar.
Esto cambia todo para los que desarrollan en android.
Cuál sería tu primera app vibecodeada?
15
49
442
26,191

May 11
The frames of li:on bikes from Kids Bike Revolution are made by Weber Fibertech using its patented E-LFT process and FLEXflow HRS hot runner technology from Oerlikon HRSflow. konsens.de/en/press-releases…

1
2
3
139

Feb 14
Want 5 business ideas custom-built for YOUR interests that could hit $10k/mo as a solo founder? 📷 Just dropped my first weekly AI app: AI Idea Booster – $27 gets you a personalized pack with market validation no-cod🏦-1x3r274" style="color: black; background-color: transparent; font-family: sans-serif;">Deep reasoning. Zero fluff. → aiideaboosterreplit.app/"
"Free teaser #1 (Gaming Content Creation):
ClipForge – AI auto-edits streams into viral shorts. $9B market. No-code MVP. Month 1 potential: $3k–$10k. Pack has 5 deep dives on top 2.""Free teaser #2 (Fitness Remote Work):
FlexFlow – Webcam posture coach. $8.2B market. No-code. Early revenue: $2k–$6k/mo. All 100% tailored to your niche.""See full site with testimonials more:
aiideaboosterreplit.app/"
"How it works:
Buy $27
with interests
Reply or DM me@iDeaManNowCustom pack delivered <2 hours (manual = premium quality)"
"First 10 buyers: FREE bonus competitor/risk analysis on your fave idea."
"Price $27 until 20 sales → $47.
Direct checkout: mkadosh.gumroad.com/l/vdkbw""Launching AI apps weekly in 2026. This is #1 — more drops soon.
Solo founders only.""Who's buying first? Drop your interests below for a free mini-teaser.
Questions? DM@iDeaManNow
1
1
59

Builded flexflow for people to pratice flexbox go checkout ! flexflow.punyanshsingla.com
@piyushgarg_dev @Hiteshdotcom @surajtwt_ @nirudhuuu @devwithjay @yntpdotme @Aasuyadavv
@ChaiCodeHQ @BlazeisCoding
#LearnInPublic #WebDev

5
37
445

هل سبق وقرأتم عن نموذج دوامة الديناميكيات (Spiral Dynamics)؟
ووفق هذا الإطار التفسيري، ما العوامل التي تُسهم في انتقال المجتمعات بين الأنماط المختلفة في الدوامة؟
و هل يرتبط ذلك بوعي الشعوب؟ أم بدور النخب السياسية والفكرية؟ أم بتأثير قوى اقتصادية وجيوسياسية أوسع؟
والسؤال الأهم يا هل ترى ماهو دور الإنسان البسيط كما تطلقون عليه في دفع أو تراجع هذه الدوامة؟؟!!
#نموذج_دوّامة_الديناميكيات
هو إطار في علم النفس التنموي، وضع أسسه كلير غريفز في الخمسينيات، ثم طوّره دون بيك وكريس كوان في كتاب Spiral Dynamics (1996).
يهدف إلى تفسير تطوّر الوعي والقيم عبر مراحل متتابعة.
يفترض النموذج أن تطوّر القيم ينتج عن تفاعل مستمر بين:
•الظروف الحياتية الخارجية (Life Conditions)
•القدرات الداخلية للفرد أو المجتمع
ولا يتم تجاوز المراحل، بل تُدمج تدريجيًا.
ينقسم النموذج إلى مستويين رئيسيين:
🔹 المستوى الأول (First Tier): يركّز على البقاء والتنظيم الأساسي (6 مراحل أولى)، حيث تميل كل مرحلة إلى اعتبار غيرها «خاطئة».
🔹 المستوى الثاني (Second Tier): يبدأ من المرحلة السابعة، ويتميّز بقدرة أعلى على استيعاب التعقيد وتكامل القيم.
المراحل القيمية الأساسية:
البيج: البقاء الفسيولوجي
الأرجواني: القبيلة والتقاليد
الأحمر: القوة والسيطرة
الأزرق: النظام والانضباط
البرتقالي: العقلانية والإنجاز
الأخضر: المساواة والتعاطف
الأصفر: التفكير المنظومي
الفيروزي: الوعي الكلي العالمي
يمتاز النموذج بطبيعته غير الخطية؛ إذ يمكن للمجتمعات أن تتقدّم أو تتراجع مؤقتًا تبعًا للأزمات (حروب، انهيارات اقتصادية، كوارث)، عندما تتدهور الظروف الحياتية.
إليكم وصفاً للمراحل الثمانية الرئيسية (وهناك تنبؤ بمراحل إضافية مثل الكورال في المستقبل، لكنها غير محددة تماماً):
1. البيج (Beige - SurvivalSense): مرحلة البقاء الأساسي. تركز على الاحتياجات الفسيولوجية مثل الطعام والمأوى. غريزية، بدون وعي ذاتي كبير. تظهر عند الرضع أو في حالات الطوارئ الشديدة (مثل الكوارث). تاريخياً: بداية البشرية منذ 100,000 عام.
2. الأرجواني (Purple - KinSpirits): مرحلة السحر والقبيلة. تركز على الروابط العائلية، التقاليد، والخرافات. الخوف من المجهول يدفع للطقوس والولاء للقبيلة. تاريخياً: المجتمعات القبلية منذ 50,000 عام.
3. الأحمر (Red - PowerGods): مرحلة القوة والأنا. فردية، اندفاعية، تركز على السيطرة والقوة الشخصية. "أنا أقوى، لذا أحكم". تاريخياً: العصور الإمبراطورية منذ 10,000 عام.
4. الأزرق (Blue - TruthForce): مرحلة النظام والسلطة. تركز على القواعد، الدين، والانضباط. الولاء للمجموعة أو السلطة العليا (مثل الدين أو الدولة). "الصواب مقابل الخطأ". تاريخياً: المجتمعات الدينية منذ 5,000 عام.
5. البرتقالي (Orange - StriveDrive): مرحلة النجاح والعقلانية. فردية، تركز على الإنجاز، العلم، والمنافسة. "الفوز بالذكاء والاستراتيجية". تاريخياً: عصر النهضة والرأسمالية منذ 300 عام.
6. الأخضر (Green - HumanBond): مرحلة الانسجام والمساواة. جماعية، تركز على العواطف، التعاطف، والعدالة الاجتماعية. "الجميع متساوون، السلام والحب". تاريخياً: حركات الستينيات منذ 150 عام.
7. الأصفر (Yellow - FlexFlow): مرحلة التكامل (بداية الطبقة الثانية). مرنة، تركز على النظم المعقدة والحلول المتكاملة. "التفكير في الجميع مع الحرية". تاريخياً: منذ 50 عام.
8. الفيروزي (Turquoise - GlobalView): مرحلة الوعي العالمي. جماعية كلية، تركز على الاستدامة والروابط العالمية. "الأرض ككل واحد". تاريخياً: منذ 30 عام.
• خصائص النموذج العامة:
- الدوامة: تمثل التطور غير الخطي؛ يمكن التراجع أو التقدم حسب الظروف.
- التطبيقات: يُستخدم في التطوير الشخصي، إدارة المنظمات، والتحليل السياسي والثقافي.
وإذا طبقناه على المجتمعات الحالية لفهم أعمق، وبناءً على تحليلات من مصادر متعددة، إليكم تصنيفات عامة (غير رسمية) لمراحل الدول الحديثة:
- المراحل المبكرة (البيج، الأرجواني، الأحمر): ترتبط بالبقاء، القبلية، والقوة الفردية. توجد في مجتمعات تعاني من الفقر المدقع أو النزاعات، مثل بعض المناطق في أفريقيا جنوب الصحراء (مثل الكونغو أو الصومال، حيث تسود الفوضى القبلية أو الحروب).
أيضًا، بعض المجتمعات الأصلية في الأمازون أو بابوا غينيا الجديدة في الأرجواني (القبلي).
- الأزرق (النظام والسلطة): تركز على الدين، القواعد، والانضباط. تشمل دولًا تقليدية مثل دول الشرق الأوسط، أو جنوب شرق آسيا (مثل إندونيسيا أو ماليزيا، مع مزيج أزرق-برتقالي).
2
1
13
1,782

18 Nov 2025
❤️ Liquid cat theory
A tiny kitten melts into a plastic bottle like water, chills there, and slides back out.
👉 That’s my setup — it adapts to any shape without breaking flow.
Flexible by default.
#cats #catlife #businessinabox #flexflow #qraway
.
1
2
34

21 Oct 2025
No distractions! Locked in and waiting for results. I did a thing with Flexflow
#dnd #derrickugc #Afrobeats
11
16
234

26 Aug 2025
Multi-Domain Distribution Learning for De Novo Drug Design
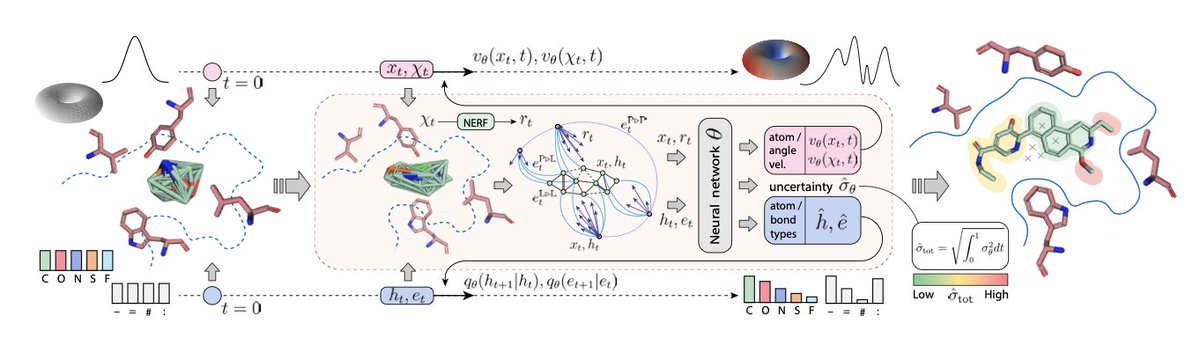
1. The article introduces DRUGFLOW, a novel generative model for structure-based drug design that integrates continuous flow matching with discrete Markov bridges. This model demonstrates state-of-the-art performance in learning the chemical, geometric, and physical aspects of three-dimensional protein-ligand data.
2. DRUGFLOW incorporates an uncertainty estimate that can detect out-of-distribution samples, enhancing the robustness of the model. This feature is crucial for identifying samples that deviate from the training distribution, ensuring more reliable predictions.
3. The model proposes a joint preference alignment scheme applicable to both flow matching and Markov bridge frameworks. This allows for the enhancement of the sampling process towards regions with desirable metric values, making it more efficient for practical applications.
4. An extended version of the model, FLEXFLOW, explores the conformational landscape of proteins by jointly sampling side chain angles and molecules. This innovation enables the model to sample probabilistic ensembles of possible binding modes, even for targets in unbound conformations.
5. DRUGFLOW outperforms other methods in learning the distribution of protein-binding molecules across various metrics. It achieves state-of-the-art distribution learning capabilities, making it a powerful tool for de novo drug design.
6. The model also includes an adaptive size selection method that discards excessive atoms during sampling. This feature allows the model to dynamically adjust the size of the molecule, improving its ability to generate realistic drug candidates.
7. DRUGFLOW demonstrates strong performance in learning the conditional size distribution of molecules given protein pockets. It effectively removes redundant atoms to avoid steric clashes, enhancing the quality of generated molecules.
8. The article presents comprehensive experiments that validate the model's ability to learn the training data distribution accurately. DRUGFLOW shows significant improvements in various metrics, including molecular properties, binding efficiency, and protein-ligand interactions.
9. The study concludes that DRUGFLOW can be retrained on curated datasets to steer the generation of samples towards desired regions of the chemical space. This flexibility makes it a versatile tool for medicinal chemists aiming to optimize molecules for specific design objectives.
📜Paper: arxiv.org/abs/2508.17815
#DrugDesign #GenerativeModel #MachineLearning #ProteinLigand #DeNovoDesign #DistributionLearning
4
29
1,813

16 Jul 2025
Recommended today; $NUWE
Nuwellis, Inc. It is a medical equipment company. It is engaged in products used to treat fluid overload. Products include the Aquadex Flexflow system, which provides ultrafiltration for patients with hyperhyperemia or patients with fluid overload.
1
1
692
9 Jun 2025
Today's rising stock prediction: $NUWE
Nuwellis, Inc. is a medical device company that provides products for the treatment of fluid overload. It includes the Aquadex FlexFlow System, which removes salt and water from patients with hypervolemia or fluid overload
1
2
3
1,512

7 Jun 2025
What looks like breakdown of systems - social, political, cultural, ecological, political, or economic - is part of momentous change all around. We need to adapt to new technologies & a new Way of Being to make sense of New Realities. #LeapInConsciousness #AdaptOrDie #FlexFlow
1
4
72

3 Jun 2025
🚀 Fresh revenue leaks 🤐 (2/5)
🇪🇸 @Payflow_es (YC S21) – the salary-on-demand fintech.
💵 ARR: €6M with 70% YoY growth
🛠 Gross margin: >70%
📦 New war-chest: €10M Series A extension to scale “Flexflow”
1
2
47

19 Apr 2025
🔥 The BLOKR Jacket 🔥
The world’s first everyday carry you don’t carry… you wear.
👉 Dropping April 25th
Built for warriors. Designed for life.
Key Features:
• Removable carbon fiber forearm inserts
• High-tensile retractable carabiner inside
• Buttery-soft black exterior bold red interior
• Athletic cut for shadowboxing, karenza, seminars & streetwear
Materials:
⚙️ FlexFlow outer shell (95% performance-grade poly)
🌬️ Ultra-soft cotton/spandex liner
💰 Approximately $300
⚠️ No preorders. Limited supply.
🎯 Limited drop hits April 25th
📍 Only at budobrothers.com
The Alloy Kobo Krusher keychain is not included but can be added at checkout with a bundle discount.
⏰ Set your alarm. This drop moves fast, make sure you get your size.
#budobrothers #martialarts #selfdefense #karate #tactical #jacket #fashion #lifestyle
2
96