
🎉 New Publication — Now Online!
Excited to share that my paper "Machine Learning Insights for Cardiovascular Risk Prediction in Diabetic Patients: Emphasis on Renal and Cardiac Markers Using Random Forests" has been published in Artificial Intelligence in Health (AccScience Publishing).
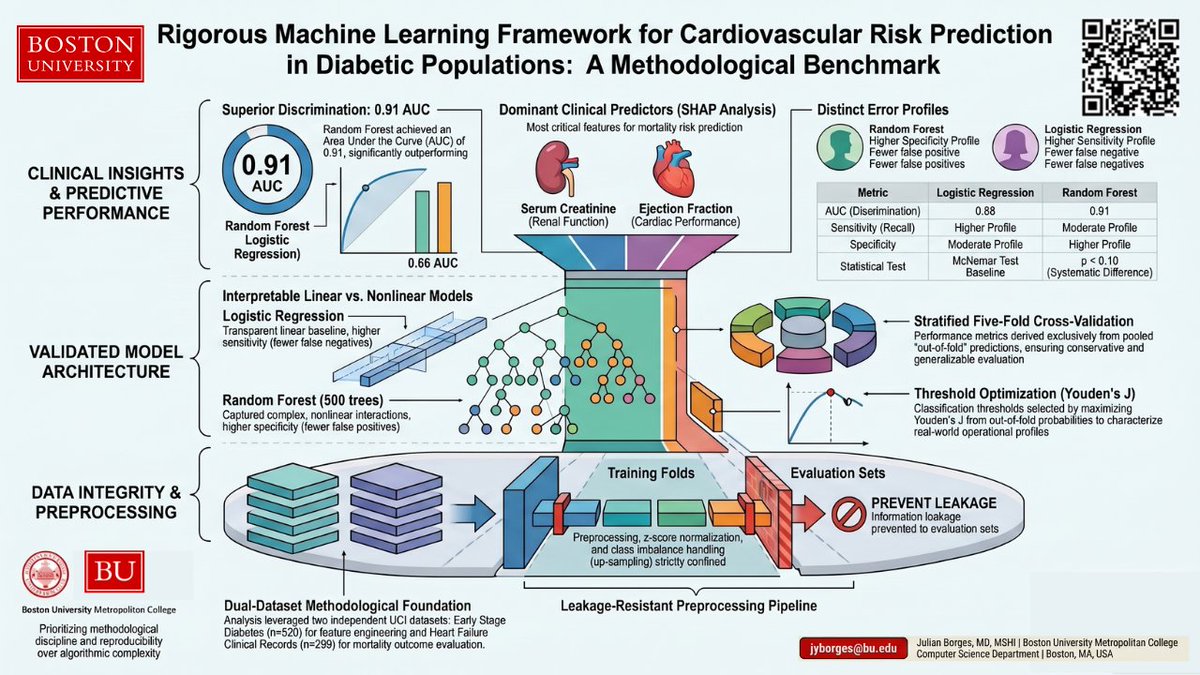
🔬 What the study does:Evaluates logistic regression and random forest models for heart failure mortality prediction using a leakage-resistant, fully reproducible analytic pipeline with stratified five-fold cross-validation.
📊 Key findings:→ Random forest achieved AUC 0.91 vs. 0.86 for logistic regression under pooled out-of-fold evaluation → Serum creatinine, ejection fraction, age, and follow-up time consistently emerged as dominant predictors across models and SHAP analyses → The two models exhibited distinct clinical error profiles: logistic regression favored sensitivity, random forest favored specificity → All metrics derived exclusively from out-of-fold predictions — no in-sample inflation
🧠 Why it matters:Too many clinical ML studies report inflated performance from weak validation. This work prioritizes methodological discipline over model complexity, establishing a transparent baseline for cardiometabolic risk modeling that aligns with FDA Good Machine Learning Practice principles.
🛡️ Why conservative validation matters in clinical AI:
Conservative validation is a foundational requirement for clinical AI because it prevents inflated performance estimates and ensures models are safe and reliable for real-world medical use. Here is why it is essential:
🔒 Mitigating performance inflation and information leakageMany AI studies report inflated accuracy because they allow information leakage, where evaluation data contaminates the training process. Conservative validation prevents this by ensuring all preprocessing, scaling, and class imbalance handling are restricted strictly to training folds and never involve held-out data.
⚠️ Addressing shortcut learningModels can achieve high accuracy by exploiting spurious correlations or dataset-specific artifacts rather than identifying genuine clinical signals. Rigorous, leakage-resistant evaluation helps identify if a model is relying on these brittle artifacts, which could lead to unsafe behavior when deployed in new populations.
📐 Establishing credible benchmarksBefore moving to highly complex architectures, it is vital to establish transparent and defensible performance baselines using standard models. This ensures that performance gains reflect actual model improvements rather than methodological weaknesses.
🎯 Evaluating decision-level behaviorConservative validation moves beyond aggregate metrics like AUC to examine threshold-dependent classification behavior. Using techniques like McNemar's test on pooled out-of-fold predictions, researchers can determine if model differences are statistically significant at the decision level — which is more operationally meaningful for clinicians.
🏥 Building clinical trust and regulatory alignmentMethodological rigor and transparency are foundational prerequisites for clinical impact. Following conservative practices aligned with FDA Good Machine Learning Practice supports the development of ethically deployable and trustworthy AI systems that clinicians can rely on for high-stakes decisions like cardiovascular risk stratification.
💡 Ultimately, rigorous evaluation and appropriate validation practices may be more consequential for trustworthy clinical machine learning than the complexity of the model itself.
📄 DOI: 10.36922/AIH025490111 Open Access | Artificial Intelligence in Health
#MachineLearning #CardiovascularDisease #Diabetes #HeartFailure #RandomForest #ClinicalAI #Reproducibility #HealthInformatics #MedicalResearch #OpenAccess #ValidationMatters #FDAGuidance #ClinicalDecisionSupport 😀😀😀
ALT https://julianborgesmd.blogspot.com/2026/05/blog-post.html
1
110


Feb 11
Modeling Crowdsourced Learning Models as Collective Problem Solving
read more : bi-journal.com/modeling-crow…
#ModelingCrowdsourced #LearningModels #BIJournal #BIJournalnews #BusinessInsightsarticles #BIJournalinterview
6

As the automotive industry embraces smarter, data-driven solutions, @Big_Datamatica Solutions Pvt. Ltd. is at the forefront ofrevolutionizing predictive maintenance and service efficiency. A winner of the Nasscom Mobility Innovation Challenge, Bigdatamaticahas solved the use case of automated geo-location-based lead routing with dynamic pricing for Tata Motors.
Their platform ingests real-time data from vehicles, such as engine behavior, vibration signatures, and error codes, to predict potentialfailures before they occur. By combining this data with historical service and warranty records, Bigdatamatica’s machine learningmodels can accurately assess the Remaining Useful Life (RUL) of critical vehicle components, enabling proactive maintenance alerts.
The platform not only optimizes maintenance schedules but also dynamically routes leads, notifying customers and service centers,and auto-initiating service workflows. This ensures faster response times and reduced vehicle downtime, improving customersatisfaction and operational efficiency.
Discover how Bigdatamatica is enhancing vehicle health monitoring and service efficiency:bigdatamatica.com/
@nasscom @nasscomai @NasscomR @nasscomCoEIoT @DSCI_Connect @sangeetagupta29 @ShaliniDewan @mayankkumar_17
#NasscomMobilityInnovationChallenge #SmartRouting #AutomotiveTech #MachineLearning #VehicleHealth #TechInnovation #NasscomInnovation #MobilitySolutions
1
77

27 Nov 2025
📣 OUT NOW
Rethinking #Entrepreneurship & #RegionalDevelopment
Eleanor Hamilton @LancasterManage Rhiannon Pugh @lunduniversity & Danny Soetanto @UniofAdelaide
ℹ️ tinyurl.com/56f353rc
👓Sample doi.org/10.4337/978180220144…
eBook tinyurl.com/ynv2tnd6
#RegionalPolicy #LearningModels


2
111

27 Nov 2025
📣 OUT NOW
Rethinking #Entrepreneurship & #RegionalDevelopment
Eleanor Hamilton @LancasterManage Rhiannon Pugh @lunduniversity & Danny Soetanto @UniofAdelaide
ℹ️ tinyurl.com/56f353rc
👓Sample doi.org/10.4337/978180220144…
eBook tinyurl.com/ynv2tnd6
#RegionalPolicy #LearningModels


2
53

7 Oct 2025
Combining Chemical, Geometric, and Novel TopologicalFeatures to Develop Generalizable Machine LearningModels for Predicting Mechanically Stable MOFs dx.doi.org/10.26434/chemrxiv…
1
352

11 Sep 2025
Are institutions and faculty ready to adapt to AI in the classroom? Avik Dutta, Country Head for India and GCC at Academik America, explores how #AI will impact teaching, #learningmodels, and the role of educators over the next five years: bit.ly/46y3hPu
#AcademikAmerica
15

18 Aug 2025
राजस्थान के कोटा क्राइसिस: कोचिंग और IIT Pressure के बाद खुली ये नई राह #KotaCrisis #StudentLife #EducationReform #KotaNews #IITPressure #MentalHealthAwareness #StudentSupport #EducationSystem #StressManagement #KotaCoaching #YouthEmpowerment #CareerOptions #LearningModels
3

8 Aug 2025
Decide your model: 1:1 peer pairs, triads, or learning circles? Test and iterate. #LearningModels #TeamLearning
8

3 Aug 2025
Implementavirtualcurrencywallet-specificintrusion-detectionsystemwithmachine-learningmodels.😳😛@GiveRep
2

24 Jul 2025
#datavisualization #virtualassistant #LLM #language #machinelarning #learningmodels #learingmethod
4th International Conference on NLP and Machine Learning Trends (NLMLT 2025)
August 23 ~ 24, 2025, Dubai, UAE
cst2025.org/nlmlt/index
Submission URL : cst2025.org/submission/index…

23

15 Jul 2025
Implementavirtualcurrencywallet-specificintrusion-detectionsystemwithmachine-learningmodels.🐣💔@GiveRep
1

27 Jun 2025
Check out my latest article: Gagné's Nine Events of Instruction. linkedin.com/pulse/gagn�… via @LinkedIn
#InstructionalDesign #Gagne #LearningModels #ElearningDevelopment #CourseDesign #OnlineLearning #LearningExperience #LearningScience #yarket
1
24 Jun 2025
#machinelarning #learningmodels #learingmethod
4th International Conference on NLP and Machine Learning Trends (NLMLT 2025)
August 23 ~ 24, 2025, Dubai, UAE
cst2025.org/nlmlt/index
Contact Us : nlmlt@cst2025.org
Submission URL : cst2025.org/submission/index…

29

Meet Cristiano Patrício, a PhD student in Computer Science and Engineering at @UBI_pt and researcher at NOVALINCS.
Working on Inherently Interpretable Deep #LearningModels for #DiseaseDiagnosis in #MedicalImaging. Keep an eye on our LinkedIn (linkedin.com/company/sins-la…) for updates

1
17

6 Jun 2025
All Business is People Business: Why Human Connection Still Reigns in the AI Era
e-spincorp.com/people-busine…
#AI #businessgrowth #businessstrategy #changemanagement #customerexperience #digitaltransformation #educationtechnology #learningmodels #organizationalculture #espincorp

9
3 Jun 2025
#machinelarning #learningmodels #learingmethod
4th International Conference on NLP and Machine Learning Trends (NLMLT 2025)
August 23 ~ 24, 2025, Dubai, UAE
cst2025.org/nlmlt/index
Submission URL : cst2025.org/submission/index…

17

Prediction of microvascular invasion in hepatocellular carcinoma based on preoperative Gd-EOB-DTPA-enhanced MRI: lausr.org/dashboard/?doi=10.… #predictiveperformance #learningmodels
15

5 May 2025
The question is no longer whether to embrace these alternative models but how to integrate them effectively into mainstream education.
Read more: bit.ly/3YuaFai
#learning #teaching #learningmodels #education #innovation #educationnews
81