
🤖 @CVPR 2026 Hot 🔥 Takes on Embodied AI: VLA × World Models × Agentic Loops @CVPRConf
Embodied AI is converging toward a unified stack: VLA policies world models active perception, connected by hierarchical memory, reusable skills, and long-horizon orchestration.
🔹 Trends
• Scenario-level generalization under distribution shift (novel objects, clutter, lighting) without task finetuning.
• Sim-scale pretraining → real-world adaptation.
• Language-conditioned manipulation, hierarchical planning, reusable skills.
• Scaling axes: larger multimodal FMs, recursive refinement loops, test-time compute (reasoning/planning).
• Shift from discrete query-response systems → continuous inference, streaming state maintenance, and full-duplex perception-action loops.
🔹 @sudo_robotics
• Hierarchical VLA: language planner → skill toolbox → actions.
• Real2Sim2Real pipeline with ManiSkill3 SAPIEN.
• Foundation-model approach: scale simulation, reusable skills, language-promptable robots.
• Generalizes from fish-oil softgels to unseen plush toys across booths with zero task-specific finetuning.
• ViTaMIn-B-style visuo-tactile sensing.
• Clever hardware: multi-monocular cameras outperform stereo depth for hand-object visibility and reduced finger occlusion.
🔹 @meta_aria
Perception-first embodied engineering:
• Online calibration temperature-aware compensation.
• Detects minute calibration drift with mm-level precision.
• Pixel-level exposure adaptation for HDR environments.
• Visual-inertial SLAM optimized for localization, not photography.
• Monochrome sensors improve feature extraction and long-term tracking robustness.
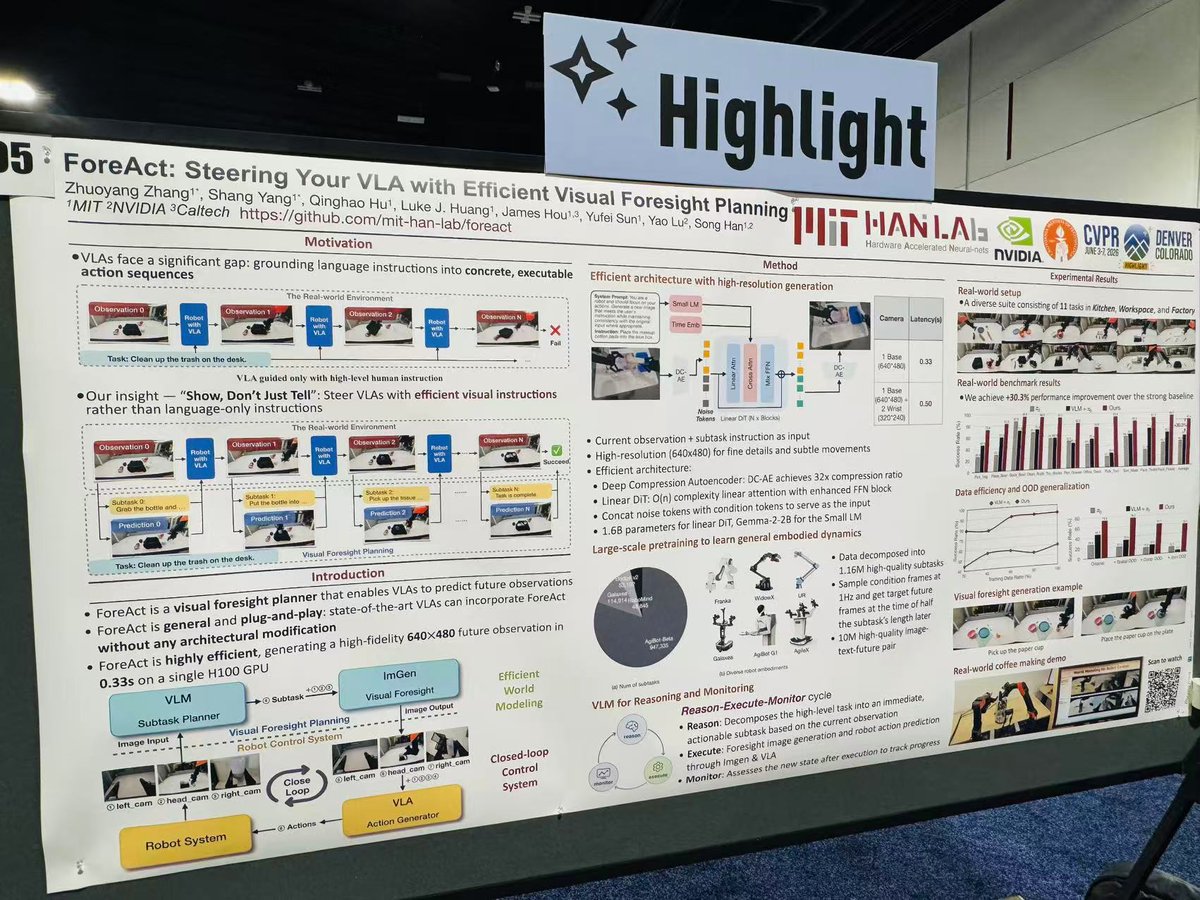
🔹 ForeAct (@MIT HAN Lab)
Visual foresight as a plug-and-play module for any VLA.
Pipeline:
Qwen3-VL → subtask decomposition → diffusion-based goal imagination → robot → VLM monitor → replanning.
Key idea:
Separate semantic reasoning, task decomposition, future prediction, and control.
ManiSkill decomposes tasks into skills; ForeAct decomposes tasks into future states.
🔹 SaPaVe (@PKU1898 / Beihang / BAAI)
First end-to-end VLA combining semantic active perception manipulation.
Key insight:
If information is insufficient, acquire information before acting.
Architecture:
• Camera Action Decoder (2 DoF yaw/pitch semantic viewpoint control).
• Manipulation Decoder (26 DoF dual-arm control).
• Camera Adapter: LoRA on Eagle-2 VLM (<2% trainable params).
• Universal Spatial Encoder (MapAnything) injects depth, intrinsics, extrinsics, arbitrary geometry.
• ~15% performance gain from geometry-aware view-invariant reasoning.
Together:
SaPaVe = gather information
ForeAct = imagine future outcomes
Loop: reason → inspect → imagine → execute → verify → replan.
🔹 WoW (14B World Model)
• Trained on 2M robot trajectories.
• SOPHIA self-optimization: generate → VLM critique → rewrite → regenerate.
• Improves causal validity, collision reasoning, consistency.
• Learns embodied physics directly from interaction.
• Inverse Dynamics module converts imagined futures into executable actions.
🔹 Maestro
Robotics OS paradigm:
VLAs become modules inside an orchestration layer.
Responsibilities:
• Information sufficiency assessment.
• Invoke SaPaVe / ForeAct / WoW.
• Maintain long-horizon task memory.
• Policy/primitive selection.
• State tracking across time.
Emerging view:
Robotics is orchestration, not monolithic policy learning.
🔹@NVIDIAAI Cosmos3 Discussion: Always-On World Models @NVIDIARobotics
Hypothesis:
Future intelligence emerges from continuous prediction-reality mismatch correction.
Architecture:
• Persistent latent memory.
• Self-monologue dreaming loops.
• Continuous VLM auditing.
• Automatic memory pruning.
• Test-time learning as a first-class capability.
Inference scaling may have 3 orthogonal axes:
1️⃣ Larger multimodal models.
2️⃣ Recursive latent compression/folding.
3️⃣ Test-time rollout, search, self-consistency, continuous refinement.
Data bottleneck:
Egocentric trajectories YouTube-scale multi-view video action-conditioned interaction logs.
Potentially ~50× more high-quality action data needed for the next phase transition.
🔹 From Tokens to Robots Fireside
• VLAs and LLMs are both sequence models; robot tokens correspond to actions, states, and trajectories.
• Action spaces become robotics' version of function calling.
• World models optimize action-conditioned transition prediction rather than behavior imitation.
• RL adds critics/value functions for selecting among imagined futures.
• Failure trajectories remain valuable training data.
• Calibration may matter more than raw accuracy.
• Contact-rich interaction remains robotics' hardest challenge.
• Robotics lacks a Chinchilla-style scaling law relating data, model size, compute, and downstream performance.
• World models may become evaluation engines before policy engines.
🎯 Takeaway
Active Perception (SaPaVe) → Visual Foresight (ForeAct) → World Models (WoW) → Agentic Orchestration (Maestro)
with continuous loops of:
Perceive ↔ Imagine ↔ Predict ↔ Act ↔ Revise
The open challenge remains unifying perception, memory, planning, control, causal representation learning, diffusion MPC, and action-conditioned world modeling into a stable long-horizon embodied intelligence scaling law.





6
24
3,765
CVPR 2026 Embodied AI Highlight Papers
Active Perception · Visual Foresight · Embodied Cognitive Loops
1. ForeAct (MIT HAN Lab, Zhuoyang Zhang, Shang Yang et al., arXiv:2602.12322, github.com/mit-han-lab/forea…)
ForeAct delivers efficient visual foresight that steers any VLA via atomic visual goal imagination.
It addresses the failure mode where sufficient information already exists, but explicit future grounding is missing.
If SaPaVe answers: Do I know enough to act?
ForeAct answers: Now that I know enough, what exactly should success look like?
The core argument: existing VLAs are overloaded. They simultaneously perform: semantic reasoning, task decomposition, future prediction, visuo-motor control.
ForeAct explicitly separates these responsibilities.
This resembles skill-library systems such as ManiSkill in spirit, but with a different abstraction:
ManiSkill decomposes tasks into reusable skills;
ForeAct decomposes tasks into reusable future states.
Unlike Sudo-style systems that reduce VLAs into lightweight coordinators over primitives, ForeAct keeps the VLA intact and steers it via visual foresight.
Closed loop pipeline:
Qwen3-VL → subtask → ImGen → robot (multi-cam) → VLM monitor / re-plan
(finer granularity than ManiSkill skills; no VLA replacement, unlike Sudo-style coordination layers)
2. SaPaVe (Mengzhen Liu, Enshen Zhou et al., PKU / Beihang / BAAI, arXiv:2603.12193)
SaPaVe delivers the first end-to-end VLA unifying semantic active perception and manipulation via explicit decoupling.
It addresses insufficient information before action.
I was surprised that the human-like paradigm:
“Look again, look closer, look left and right”
(combining perception action)
was not already well-established in VLAs—it is extremely natural for embodied intelligence.
Core insight
SaPaVe solves the regime where robots lack: occlusion understanding, grasp affordances, articulation state,
action success certainty.
Existing VLAs operate under passive perception: fixed camera viewpoints, direct manipulation prediction from static observations.
However, active perception introduces a key coupling problem: moving the camera changes observations, manipulating objects changes observations, reorienting objects changes observations.
Traditional unified action spaces entangle: camera motion objectives, manipulation objectives.
SaPaVe resolves this via explicit decoupling.
Decoupled design
Embodied intelligence becomes a two-branch decision process:
- test information sufficiency
- if sufficient → act; if insufficient → active information acquisition.
SaPaVe ForeAct together instantiate this loop:
reason → gather info → imagine futures → execute → verify → re-plan
(vs traditional perceive → act)
SaPaVe architecture
Camera Action Decoder: 2 DoF (pitch yaw), embodiment-agnostic semantic viewpoint control, supports: “look left / zoom / inspect behind”
Manipulation Action Decoder: 26 DoF joint positions, dual-arm dexterity
Decoupled heads outperform unified decoder (71.25% vs lower baseline)
Camera / perception modules
Camera Adapter: LoRA on Eagle-2 VLM, <2% trainable parameters, learns semantic active perception priors, preserves base manipulation knowledge
Universal Spatial Encoder (MapAnything): injects depth intrinsics extrinsics arbitrary geometry, element-wise fused into VLM tokens & action head during denoising, enforces view-invariant 3D consistency, improves performance by ~15% even on simple tasks.
3. Long-horizon cognition: WoW (arXiv:2509.22642)
WoW is a 14B embodied world model trained on 2M robot trajectories (not passive video).
Key mechanism: SOPHIA self-optimizing loop: generate,
VLM critique (physical causal validity), rewrite, regenerate.
This improves: consistency, collision reasoning, causal validity.
Unlike video-only world models, WoW learns physical dynamics directly from embodied interaction.
It also introduces Inverse Dynamics → executable actions, achieving SOTA on manipulation simulation and real Franka setups.
Overall implication: embodied pretraining may function as meta-learning for intuitive physics.
4. Agent OS / Robotics orchestration: Maestro (maestro-robot.github.io)
Maestro reframes VLAs as modules inside a robot operating system layer.
This OS layer is responsible for: deciding information sufficiency, invoking SaPaVe / ForeAct / WoW, tracking long-horizon state, selecting primitives / policies, maintaining task memory across time
Pure VLAs remain weak at long-horizon reasoning.
Missing system components (explicit gaps): causal latent learning (MPI-style), Diffusion MPC, tighter integration between generative world models and real-time control.
Related systems (e.g., Dexmate) similarly argue for: representation layers, world models, agentic harnesses, modular execution systems.
The emerging paradigm: robotics as orchestration, not monolithic policy learning
Conclusion
SaPaVe (information acquisition layer): semantic active perception, embodiment-agnostic camera control, decoupled action modeling, geometry-aware viewpoint reasoning.
ForeAct (future grounding layer): atomic subtask decomposition, visual goal imagination, efficient diffusion-based foresight, plug-and-play steering of existing VLAs.
System stack: Above both layers sit: embodied world models (WoW), agentic orchestration frameworks (Maestro), representation-centric architectures (Dexmate)
Likely missing ingredients to close the loop: causal latent representation learning, diffusion-based model predictive control, MPI-style causal world modeling frameworks.
@CVPR @CVPRConf @saturdayrobotic #CVPR2026



CVPR 2026 — Embodied AI Takeaways @CVPRConf @CVPR
Embodied AI converges along three coupled axes: VLA policies, world models, agentic perception-action loops, linked via hierarchical memory skill composition.
🤖 Robotics shows scenario-level generalization under distribution shift (novel objects, clutter, lighting variation), incl. unseen household items long-tail tabletop objects, often without task finetuning.
Common pattern:
sim-scale pretraining real adaptation
language-conditioned manipulation policies
hierarchical planning reusable skills
ManiSkill-style benchmark ecosystems
Trend: compositional policies simulation-scaled pipelines; cross-embodiment transfer remains open.
👓 Meta Aria = perception-first SLAM engineering
SLAM-first embodied sensing design co-optimizes hardware algorithms for stability over imaging.
Key priorities:
online calibration drift correction
illumination robustness
visual-inertial SLAM primary objective
per-sensor consistency for long-term tracking
Optimized for continuous egocentric state estimation, not photography.
🌍 World models & agentic systems converge conceptually
Shared abstraction: prediction–observation mismatch correction in continuous loops.
Design directions:
streaming latent state updates
persistent memory / belief revision
anomaly-driven representation correction
tight perception–imagination–action coupling
Shift: discrete I/O → continuous inference continuous state maintenance.
📈 Scaling axes:
larger multimodal foundation models
recursive / iterative refinement loops
test-time computation scaling (reasoning planning)
Shift: model size scaling forward dynamics quality inference-time adaptation.
🎙 Continuous interaction models
Move beyond turn-taking:
low-latency streaming speech (Moshi-style)
overlap-tolerant dialogue
continuous embodied perception-action loops
Toward full-duplex systems with persistent internal state vs query-response cycles.
🦾 Robot “OS” = hierarchical orchestration
Long-horizon manipulation remains hard under flat policies.
Stack:
high-level planners (language/symbolic/latent)
mid-level skill libraries (reusable primitives)
low-level reactive control
Active perception:
query environment under uncertainty
manipulate to reduce ambiguity
update belief before action
🧭 Synthesis:
reactive policies → agentic systems with persistent world models
Integration:
world models VLA
active perception uncertainty-aware control
simulation scaling real adaptation
continuous interaction streaming inference
🧩Summary:
Embodied AI is moving toward systems that continuously perceive, maintain internal state, and iteratively refine predictions via environment interaction.
Open problem: unifying perception, memory, planning, control into stable long-horizon agent loops.
#CVPR2026 #EmbodiedAI #WorldModels #Robotics #VLA #AgenticAI




6
44
5,336

May 30
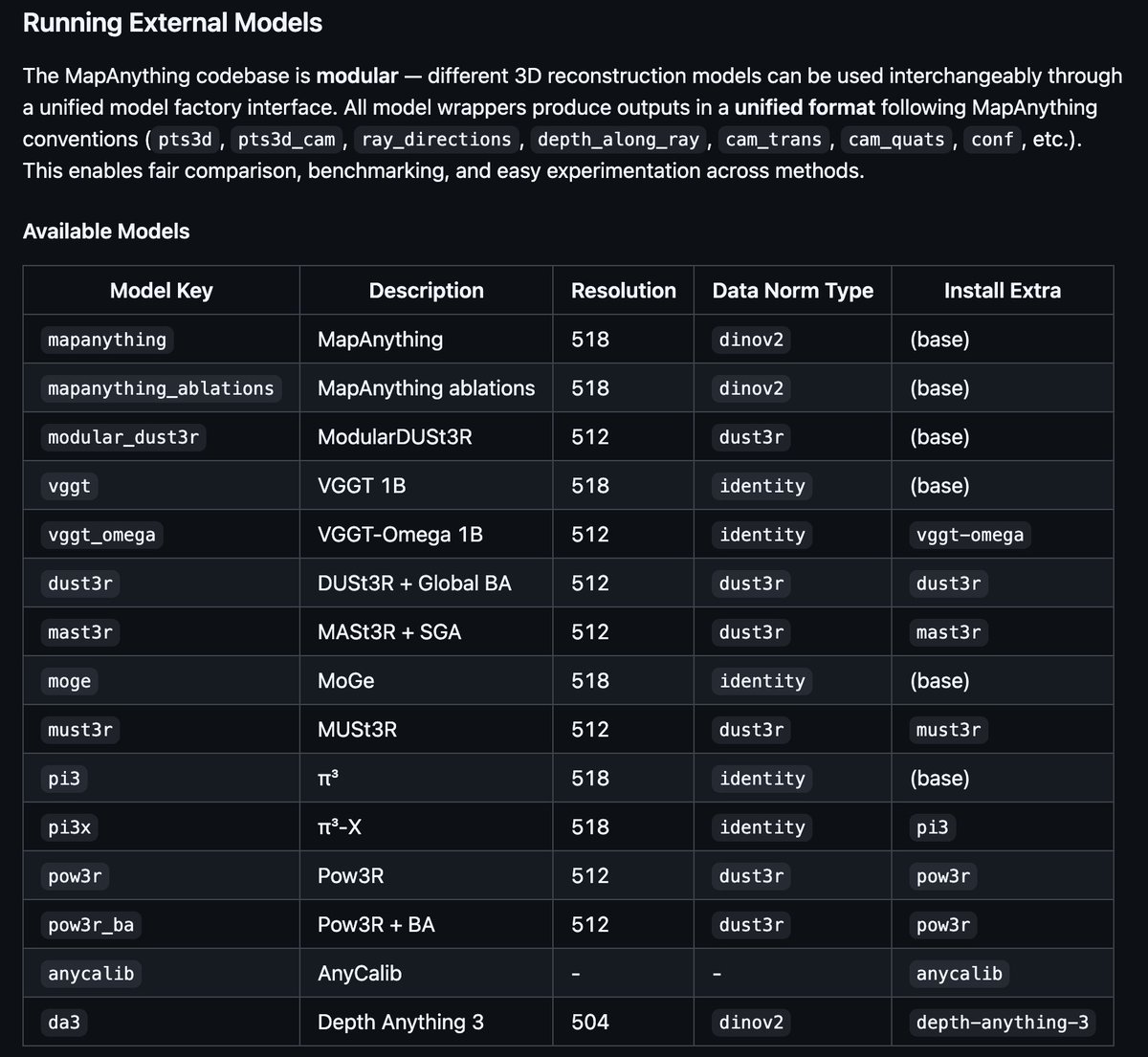
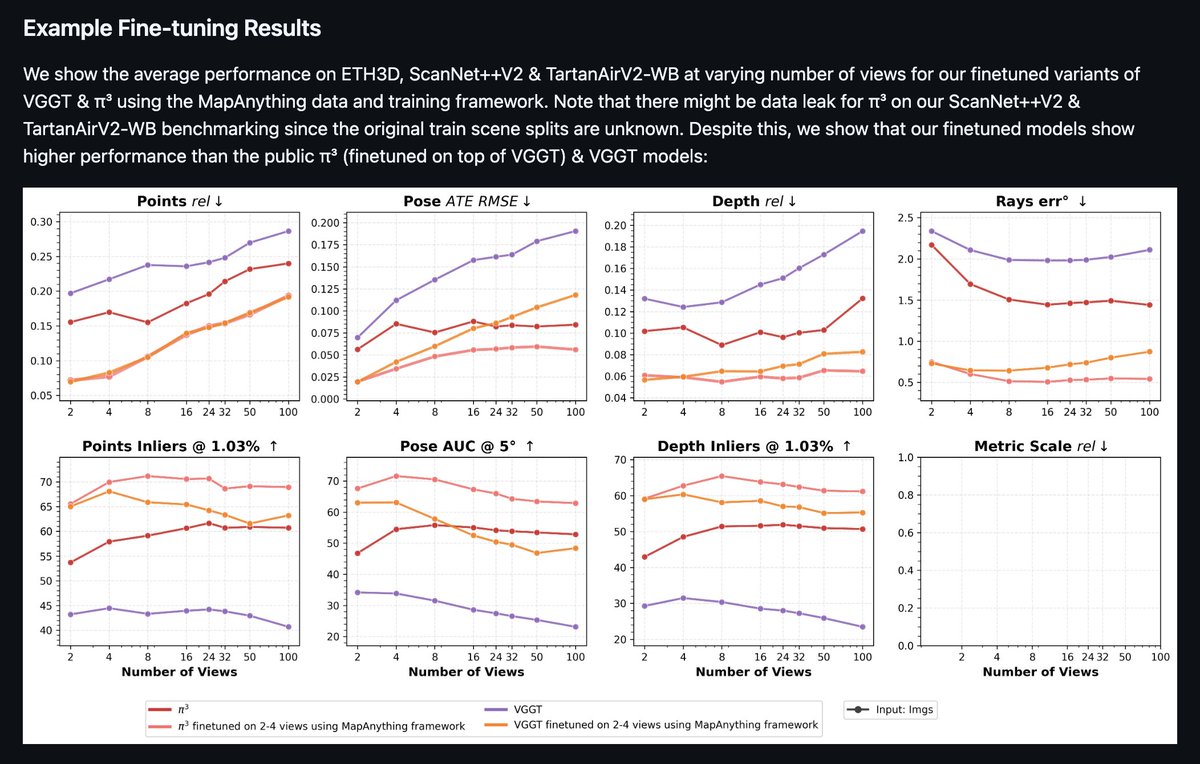
Looks like I didn't do a good job of sharing this before but...
Yes, you can infer, visualize, compare, train and finetune all the geometry foundation models in the MapAnything codebase‼️
1
5
56
3,978

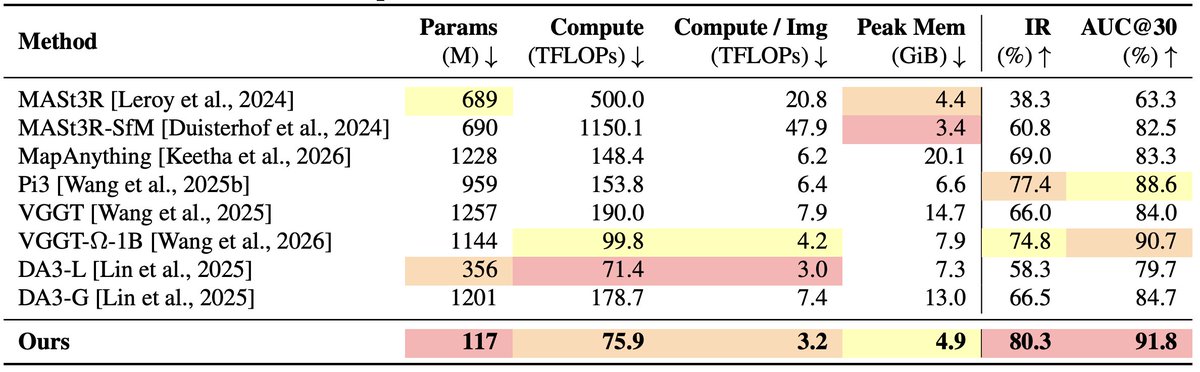
At 117M params and 75.9 TFLOPs, Déjà View matches or beats VGGT(-Ω), Pi3, MapAnything, and Depth Anything 3 across 5 benchmarks (DTU, ETH3D, 7-Scenes, ScanNet , nuScenes).
Pi3: 8× params, ~2× compute. VGGT: 10× params, ~2.5× compute.
1
1
25
2,247
May 30
VGGT Omega is now in the MapAnything model factory: github.com/facebookresearch/…
Now alongside Pi3-X, DA3 and other models you can benchmark it, visualize & compare reconstructions, run other demos, and finetune it using the MapA code - github.com/facebookresearch/…
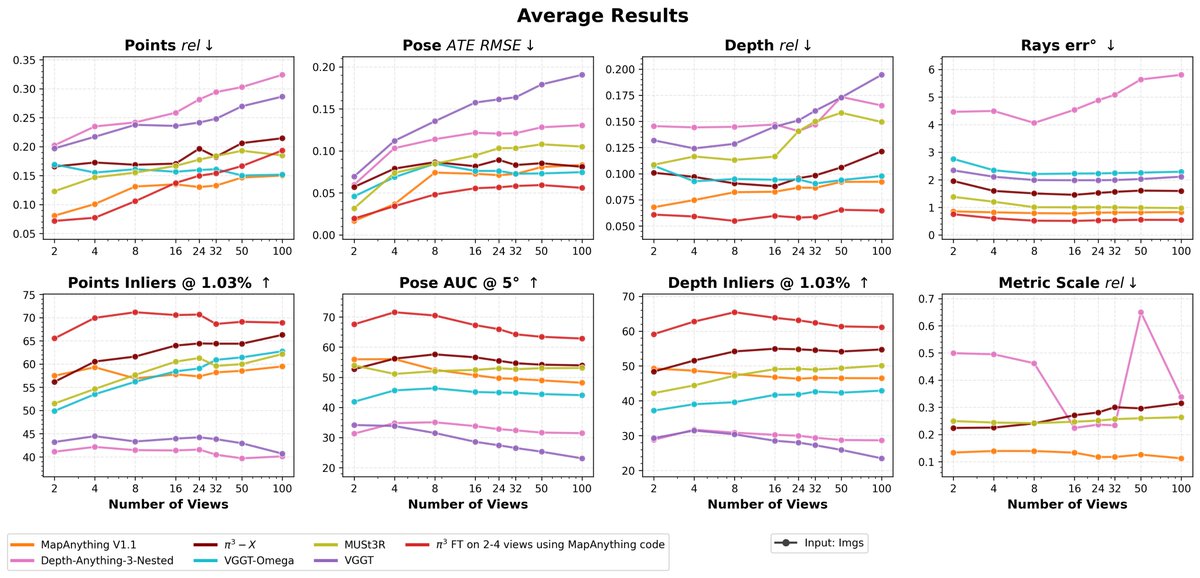
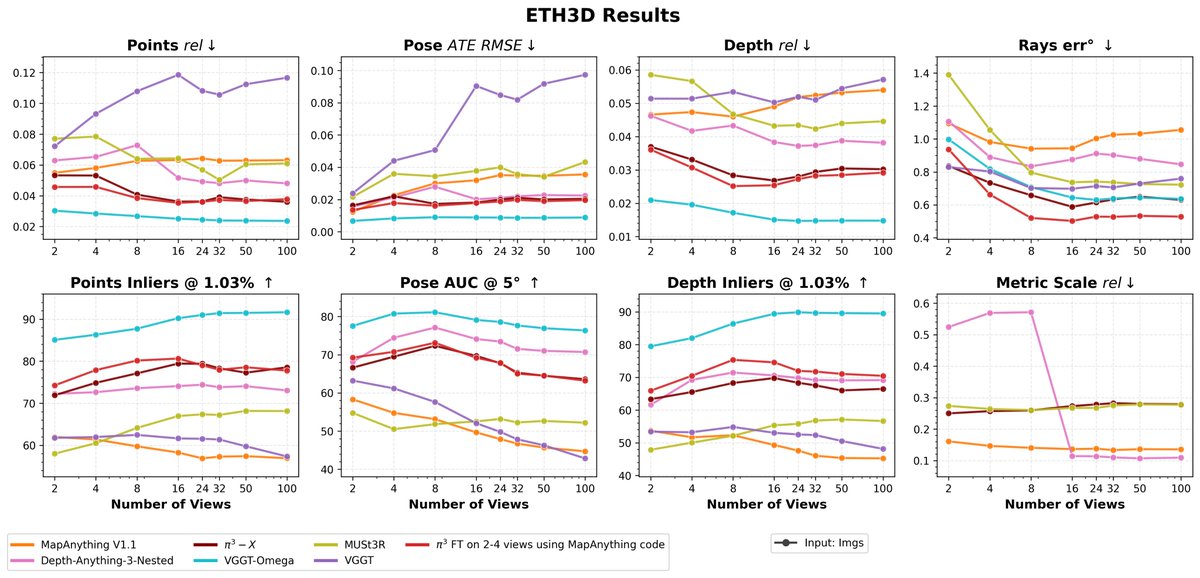
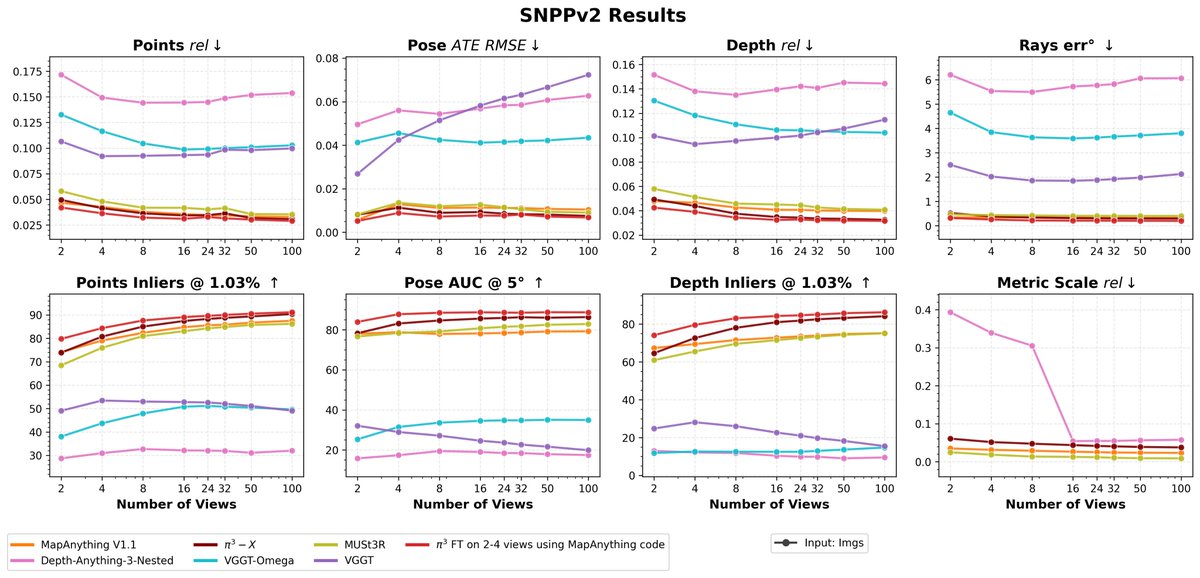
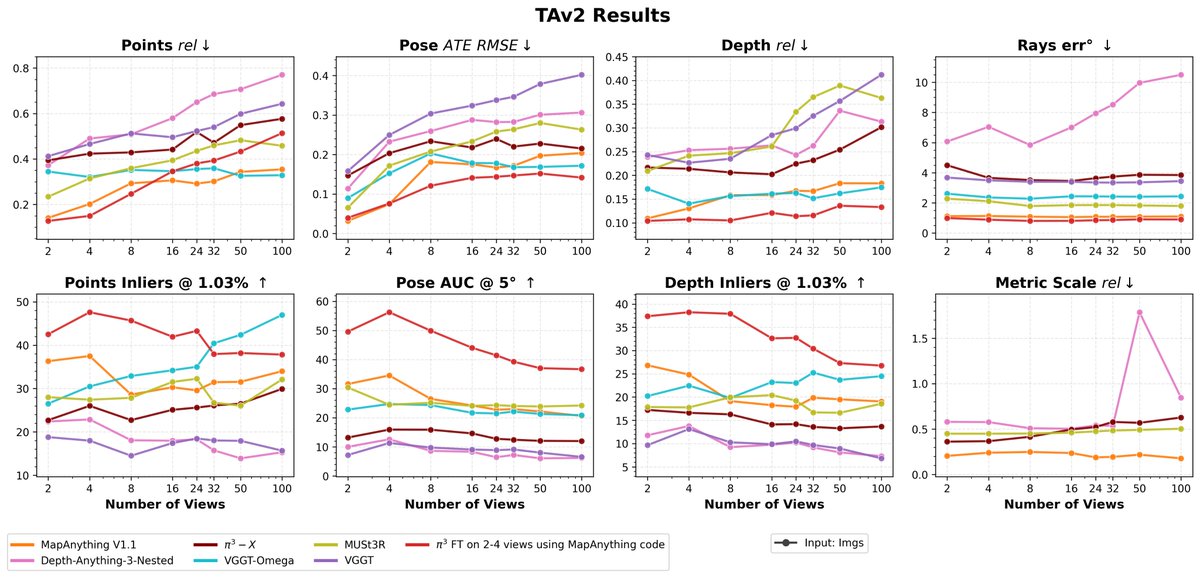
May 19

Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
3
17
133
14,676

May 18
Proud to see Co-Me accepted to CVPR 2026 🎉
Now supporting MapAnything 1.1, Depth Anything 3, and Pi3 - and 2× faster than the original, up to 21.5× speedup on long VGGT sequences. Congrats to the team!
May 18

All your favorite 3D models — now faster with Co-Me.
🎉 Accepted to CVPR 2026, Co-Me now supports more 3D foundation models: MapAnything 1.1, Depth Anything 3, and Pi3.
Same simple confidence-guided token merging idea — now accelerating even more 3D reasoning models. 👇
4
12
3,147

May 18
All your favorite 3D models — now faster with Co-Me.
🎉 Accepted to CVPR 2026, Co-Me now supports more 3D foundation models: MapAnything 1.1, Depth Anything 3, and Pi3.
Same simple confidence-guided token merging idea — now accelerating even more 3D reasoning models. 👇
1
16
92
10,457

段階的に世界を創る。
Stepperはパノラマを一歩ずつ拡張し、MapAnythingと3D Gaussian Splattingで探索可能な空間に変える。
3D生成は「歩きながら世界を増やす」段階に入った。
この分野の技術も急激に成熟してきている。
詳細は🧵
 AI Bites | YouTube Channel
AI Bites | YouTube Channel
2
2
38
3,693

Apr 30
I (my agents) made a table comparing different 3D reconstruction methods, including COLMAP, DUSt3R, MASt3R, CUT3R, Fast3R, VGGT, π³, MapAnything, DA3
Sharing it here in case it's helpful for anyone else
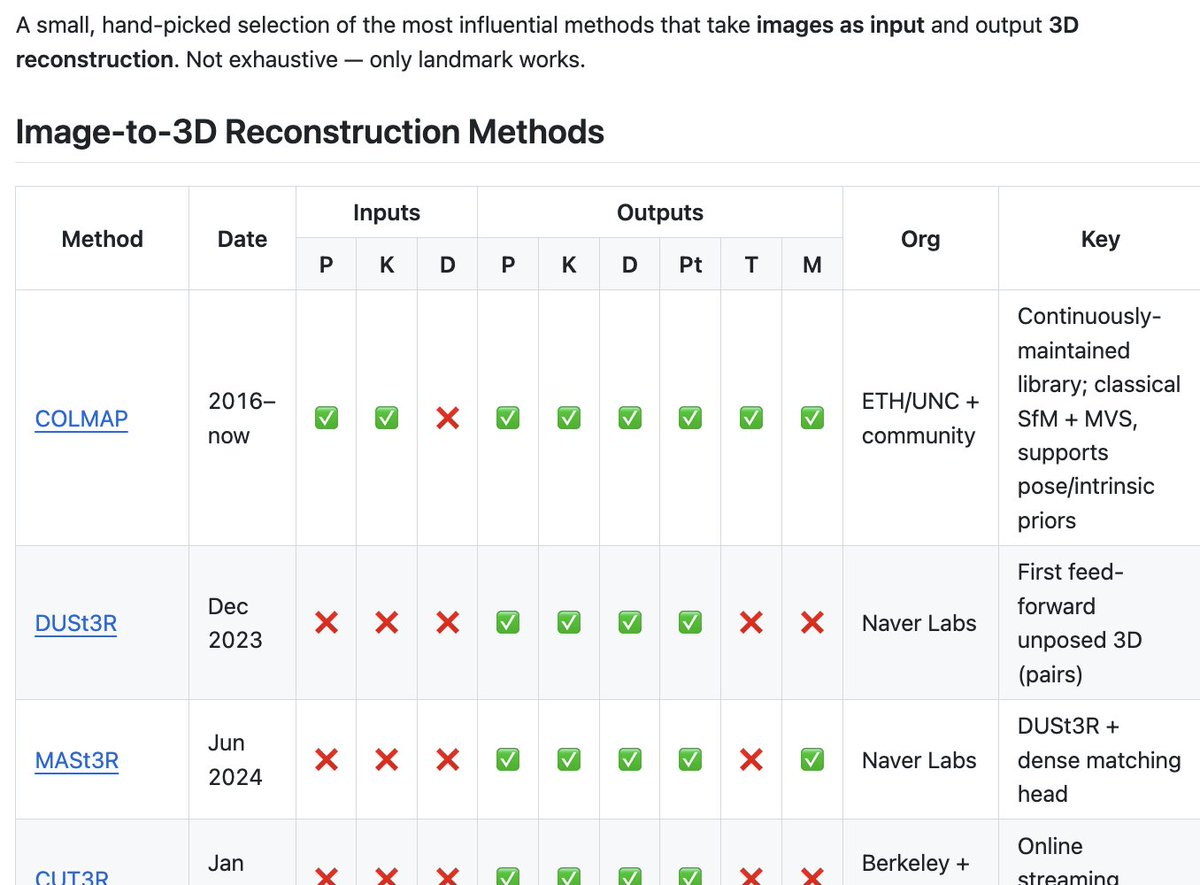
10
39
336
36,094

Apr 15
Congrats to @Normanisation for his successful PhD defense 🥳🎓
Norman's thesis about 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐌𝐨𝐝𝐞𝐥𝐬 𝐨𝐧 𝟑𝐃 𝐑𝐞𝐩𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧𝐬 makes important contributions to the 3D vision community. For instance, DiffRF, a generative approach directly operating in 3D space, was among the first diffusion techniques for neural radiance fields.
This led to many follow up works in this area and sparked interest across the computer vision community, establishing generative approaches as a corner stone in the 3D domain.
Also after his PhD, Norman continues to work on the forefront in computer vision, such as his contributions to MapAnything, a universal feedforward approach for 3D reconstruction.
Check out Norman's amazing work: normanm.de/
Congratulations Dr. Mueller - super proud!


6
10
115
13,503

Apr 13
Repeat after me: supervision with Colmap, SIFT does NOT mean "no supervision".
No, supervising with MapAnything does NOT mean "relieving from GT annotation".
It is not "self-supervision" either.
Screenshots: Reliev3r (2026), SGP (2021).
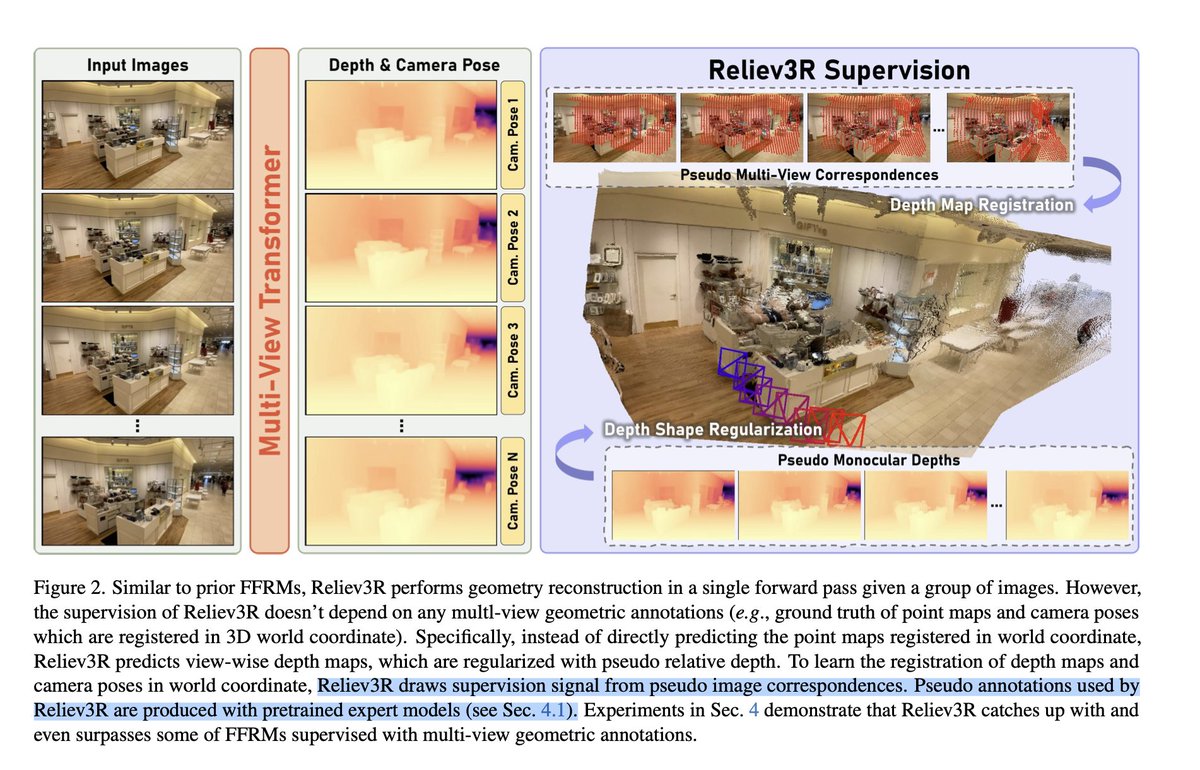
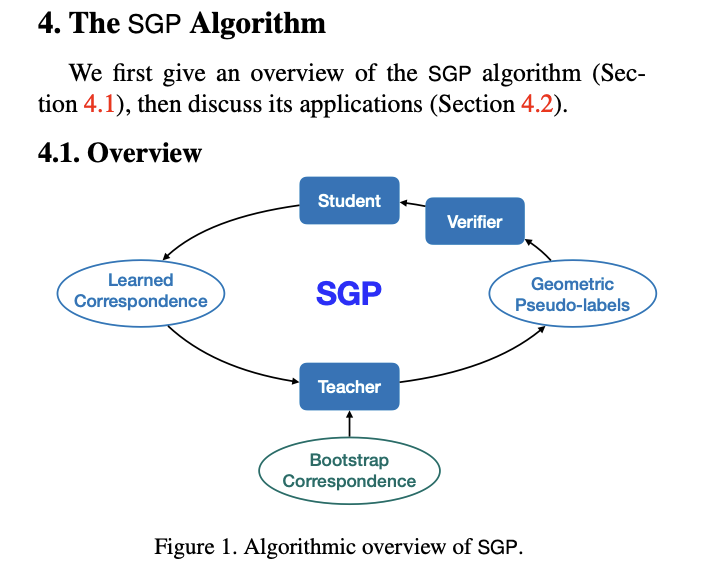

5
4
91
14,480

Here's how it works:
1. A contributor records a walkthrough video
2. Our pipeline (MapAnything) reconstructs the space in 3D, then Grounding DINO SAM2 to detect and segment every object
3. 2D detections are lifted into world coordinates, a fully labeled, explorable 3D scene
3
177

Mar 24
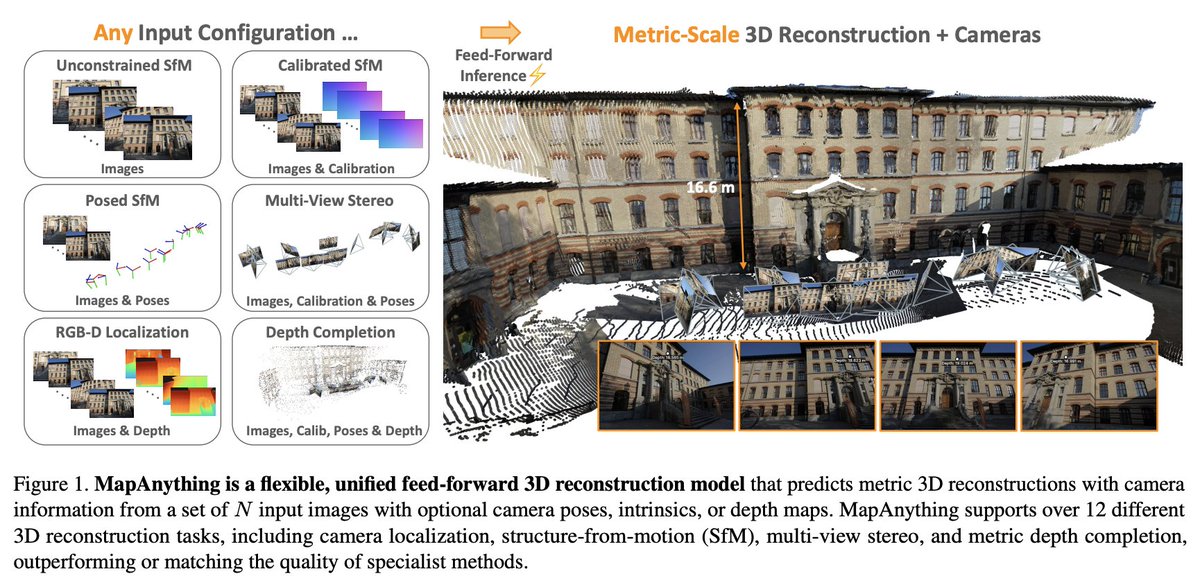
my fav papers from 3DV because why not 🤝
MapAnything by Meta
→ 1B foundation model for 3D
→ takes in images optional ray directions, poses & depth outputs 3D, normal, depth maps
→ consists of mm encoders on top of transformer with MLP, DPT and pose head
model & demo ➡️
1
8
139
8,053

Mar 22
Meta has a model that can turn images into full 3D worlds
It's called MapAnything (paper model) & is available on HuggingFace.
Paper: huggingface.co/papers/2509.1…
Github: github.com/facebookresearch/…
Try here:huggingface.co/spaces/prithi…
What you can do:
→ Reconstruct full 3D scenes from images
→ Estimate depth, camera poses, geometry
→ Run multi-view stereo SfM in one model
→ Handle 12 3D vision tasks at once
How it works:
A single transformer takes images optional inputs
(camera, depth, poses) and predicts full 3D geometry
Uses a unified representation of depth maps, rays, and cameras
to build consistent metric 3D scenes
Supports:
→ Monocular depth estimation
→ Multi-view reconstruction
→ Camera localization
→ Depth completion & more
Video Source: PRITHIV SAKTHI U R
2
3
334

Mar 21
Great day! I spy Toon3D w/ @cardiacmangoes and MapAnything! 👀 @Nik__V__ we missed you here for MapA but I did my best to cover. 🥳





2
10
1,050
Mar 18
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
🔗 map-anything.github.io/
This work is led by @Nik__V__, who unfortunately can't attend. I'll be there to represent our team from Meta!
12
439
Mar 18
Headed to Vancouver for #3DV to present 3 papers!
🖼️ Toon3D: Cartoon to 3D w/ @cardiacmangoes
⛽️ Fillerbuster: Generative scene completion
🗺️ MapAnything: Feed-forward reconstruction
Say hi if you're around or reach out to chat! 👋😃
Links to papers below 👇
2
14
222
11,700


Jan 29
MapAnything V1.1, comes with Apache 2 license and a Rerun viewer 🔥
Jan 28

Check out our code for more details and to try things out!
github.com/facebookresearch/…
huggingface.co/spaces/facebo…
This marks a freeze on the immediate improvements to the repo. Stay tuned for the next step delta 😉
2
9
104
8,081