
A city government IT department just shipped a model that beats Alibaba's latest.
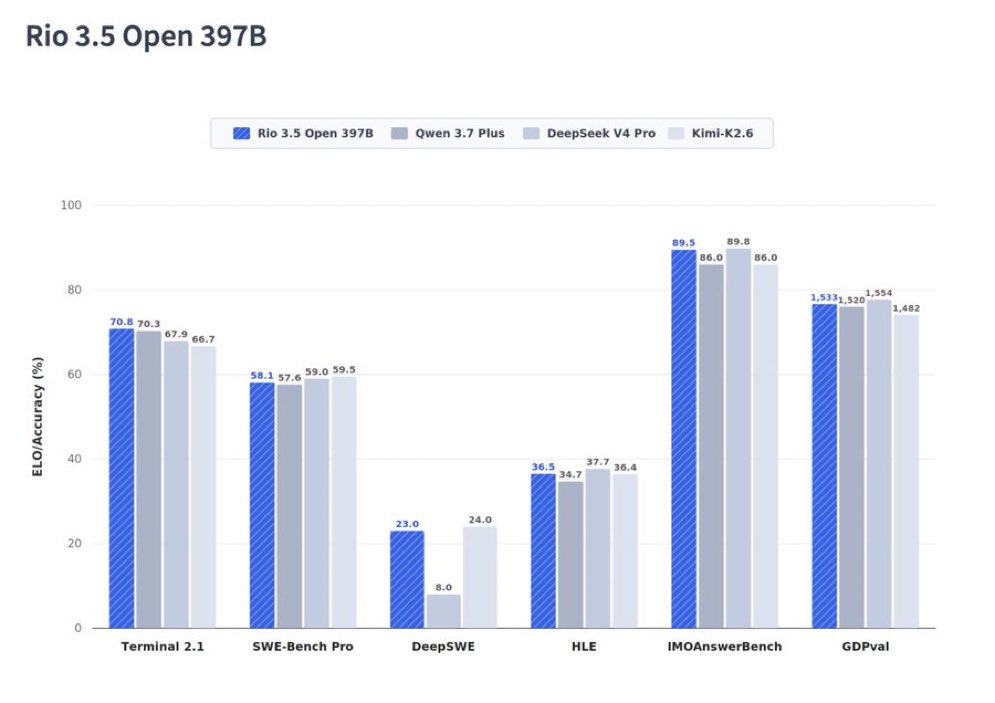
Rio 3.5 Open 397B was released yesterday by IplanRIO — the municipal IT company of Rio de Janeiro. It outperforms Qwen 3.7 Plus on agentic coding benchmarks. MIT-licensed. And almost nobody saw it coming.
Everyone is covering the geopolitics of GLM-5.2 and the Fable 5 export ban. The bigger signal is structural: the frontier doesn't belong to AI labs anymore. It belongs to whoever can post-train effectively.
Here's what actually happened:
1. The base model is Qwen 3.5 397B — open weights, 397B total / 17B active MoE. IplanRIO didn't train from scratch. They post-trained an existing open model.
2. The technique is SwiReasoning (Shi et al., 2025, arXiv:2510.05069) — a framework that dynamically switches between explicit chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals. The model only "thinks out loud" when confidence drops. Otherwise it reasons silently in hidden space. Published 8 months ago. Nobody applied it at frontier scale until now.
3. The self-reported results are striking:
- Terminal-Bench 2.1: 52.5 -> 70.8 ( 18.3 over base)
- DeepSWE: 6.0 -> 23.0 (barely functional to competitive)
- SWE-Bench Verified: 76.2 -> 80.2
Under constrained token budgets — the regime that matters for agents — SwiReasoning claims up to 6.78x more accuracy per token.
But here's what most people missed:
These are entirely self-reported benchmarks. Zero third-party evaluation exists. And the model card contains a tension nobody flagged: SwiReasoning is described as "training-free," yet the model "was explicitly trained to maximize the efficiency gained via latent reasoning." The inference trick is free, but the model needed specialized post-training to actually benefit from it. IplanRIO didn't just plug in a technique. They optimized weights for silent reasoning.
The multimodal story also contradicts the "frontier-class general-purpose" framing. On multimodal benchmarks, Rio 3.5 actually regresses from its own base model:
- MMMU-Pro: 79.0 -> 78.4 (down)
- VideoMMMU: 84.7 -> 81.6 (down)
- MathVision: 88.6 -> 89.1 (marginal)
This is a coding and reasoning specialist, not a generalist upgrade. The marketing says general-purpose. The numbers say otherwise.
There's also a deployment wall. 403B parameters. No inference provider has deployed it. 5,943 downloads on HuggingFace. The gap between "beats Qwen 3.7 on a benchmark table" and "runs in your coding agent tonight" is still enormous. Open weights is not the same as accessible compute.
The deeper question: if SwiReasoning was published 8 months ago, why didn't a frontier lab ship it? Probably because visible reasoning — the chain-of-thought users can read — is a product feature, not just a performance metric. A city government has no product experience to protect. No alignment debate. No user dashboard. Just: does it score higher? It does. Ship it.
That's the real paradigm shift of June 2026. The techniques to build frontier-class AI are public. The open base models are free. The only real cost is post-training compute and knowing which papers to combine. When a Brazilian municipal IT company can out-benchmark a trillion-dollar lab's latest release, the moat isn't the model. It's the ecosystem around it — inference, fine-tuning tools, developer trust, deployment infrastructure.
Models are commoditizing faster than the infrastructure to use them. That's the bottleneck, and nobody is building for it fast enough.
1
1
365

Jun 13
Rio-3.5-Open-397B é um modelo de IA de fronteira (frontier-class) de código aberto lançado em 13 de junho de 2026 pela IplanRIO (Empresa Municipal de Informática e Planejamento S.A.), a empresa de tecnologia da Prefeitura do Rio de Janeiro.
Ele está disponível no Hugging Face:
huggingface.co/prefeitura-ri…
Principais características técnicas
•Base: Post-trained a partir do Qwen 3.5 397B (especificamente Qwen/Qwen3.5-397B-A17B).
•Arquitetura: Mixture-of-Experts (MoE) Transformer.
•Parâmetros: ~397 bilhões totais / ~17 bilhões ativos.
•Contexto: 1.010.000 tokens (1 milhão de tokens).
•Licença: MIT (totalmente aberto, uso comercial e pesquisa permitido).
•Tamanho dos pesos: ~807 GB.
•Multimodal: Suporte a visão texto (Image-Text-to-Text).
•Idiomas fortes: Inglês, Português, Chinês e dezenas de outros (en, pt, zh, ja, ko, fr, de, es, ar etc.).
Inovações principais: SwiReasoning
A grande novidade é a integração nativa de SwiReasoning (baseado no paper de Shi et al., 2025 — arXiv:2510.05069, apresentado no ICLR 2026).
É um framework de inferência sem treinamento (training-free) que alterna dinamicamente entre dois modos de raciocínio:
•Raciocínio explícito → Chain-of-Thought tradicional (gera tokens em linguagem natural).
•Raciocínio latente → Raciocínio contínuo no espaço oculto (hidden space), explorando múltiplos caminhos implicitamente sem emitir tokens.
A troca é guiada por sinais de confiança baseados em entropia da distribuição de próximos tokens:
•Baixa confiança (entropia subindo) → entra em modo latente.
•Alta confiança → volta ao modo explícito.
Vantagens:
•Maior precisão.
•Muito melhor eficiência de tokens (especialmente em orçamentos limitados).
•O modelo foi especificamente post-trained para maximizar os ganhos do SwiReasoning.
Existe repositório oficial: github.com/sdc17/SwiReasonin…
Desempenho (benchmarks auto-reportados)
O modelo supera significativamente a base Qwen 3.5 397B e compete ou vence o Qwen 3.7 Plus em vários benchmarks, especialmente em coding agentic.
Principais destaques (comparação com base e concorrentes):
Agentic Coding & Software Engineering
•Terminal-Bench 2.1: 70.8% (Qwen 3.5 base: 52.5% | Qwen 3.7 Plus: 70.3%)
•SWE-Bench Verified: 80.2%
•SWE-Bench Multilingual: 77.0% (melhor da tabela)
•DeepSWE: 23.0%
Conhecimento & Raciocínio
•GPQA Diamond: 90.9%
•SuperGPQA: 72.3% (melhor)
•HLE: 36.5%
Matemática
•HMMT 2026 Feb: 93.9%
•IMOAnswerBench: 89.5%
Multilingual
•MMMLU: 89.8% (melhor)
•MMLU-ProX: 85.6% (melhor)
Multimodal
•MMMU-Pro: 78.4%
•MathVision: 89.1%
Ele é especialmente forte em tarefas de coding agentic, raciocínio complexo e multilíngue (incluindo português).
Contexto e história
A IplanRIO já havia lançado em abril de 2026 a plataforma Rio 3 Open, uma família de 6 LLMs baseados em Qwen (licença MIT, gratuitos). O custo total do desenvolvimento foi de apenas R$ 500 mil (cerca de 30x mais barato que soluções proprietárias equivalentes).
O Rio-3.5-Open-397B é o modelo mais avançado dessa linha até o momento. A equipe (que inclui pesquisadores da própria IplanRIO) afirma que treina modelos desde a era do o1 da OpenAI, com objetivo de fazer algo parecido com a DeepSeek, mas com orçamento muito menor — por isso o desenvolvimento incremental.
Eles planejam lançar dezenas de modelos open source nos próximos meses e trabalham em parceria com universidades locais para validar benchmarks de forma independente (evitando “benchmaxxing”).
Filosofia declarada: “É dever do governo avançar e democratizar a ciência” e tornar a IA acessível publicamente.
Onde usar
•Hugging Face: link direto acima.
•Inferência recomendada: vLLM (suporte oficial).
•Também funciona com Transformers, llama.cpp (com quantização), etc.
•Requer hardware potente (múltiplas GPUs de alto desempenho), mas o MoE ajuda bastante na inferência (só ativa ~17B parâmetros por token).
15
50
389
23,511

Jun 6
Recent advances in LLM reasoning have been fueled by large-scale text reasoning datasets and RL methods such as GRPO.
But VLMs face a bottleneck: collecting multimodal reasoning data is expensive and difficult to scale.
Can we transfer reasoning directly from text-only LLMs to VLMs?
Our answer is VOLD.
VOLD combines: ✅ Group Relative Policy Optimization (GRPO) ✅ On-policy distillation from a text-only teacher
The key idea: guide the VLM's reasoning traces during RL training using a stronger LLM teacher.
Surprisingly, this is not as straightforward as it sounds.
We find that on-policy distillation only works when the teacher and student reasoning distributions are sufficiently aligned.
Without alignment, the teacher's guidance becomes ineffective.
To solve this, we use a cold-start alignment stage using supervised fine-tuning before online RL training.
This initial alignment is critical for successful reasoning transfer from LLMs to VLMs.
We evaluate VOLD on challenging multimodal reasoning benchmarks:
📊 MMMU-Pro 📊 MathVista 📊 MathVision 📊 LogicVista
Across the board, VOLD significantly improves over the baseline VLM and consistently outperforms GRPO alone.
If you're interested in:
🧠 Reasoning VLMs
🎯 Reinforcement Learning
📚 Distillation
🔍 Test-time reasoning
📈 Scaling multimodal intelligence
visit me at the poster - I'm excited to discuss results and future directions of RL for MLLMs!
Authors: @BousselhamWalid @HildeKuehne @CordeliaSchmid
@uni_tue @Inria
#CVPR #ComputerVision #VLM #LLM #Reasoning #MultimodalAI #ReinforcementLearning
1
8
571

May 18
To support this, we build VS-Bench: 800 carefully curated image pairs from MathVista, MathVerse, MathVision, and MMMU-Pro. Pairs are visually close but answer-critical details differ — so genuine re-examination should flip the answer.
1
3
227

May 15
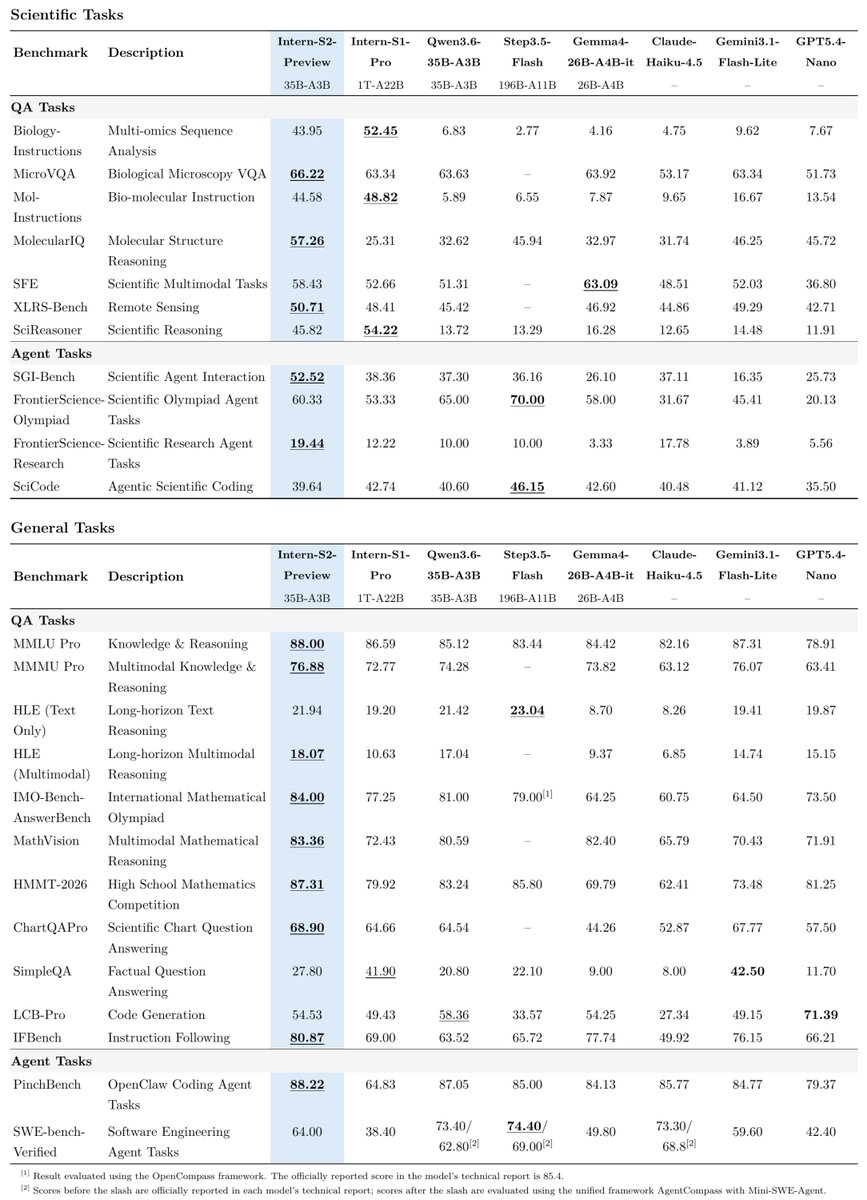
🚨 New Model Alert: Intern-S2-Preview (35B) from @intern_lm is an absolute monster in scientific & multimodal tasks! 🧪🔬
🤯 According to benchmarks, it beats Qwen3.6-35B and Gemma4-26B across most scientific benchmarks and leads in several general tasks. 📊
⛈️ Another Localmaxxing win! Could it be the next medium model winner and steal the thunder from Qwen3.6-35B and Gemma4-26B?
Standout wins
🏆 MicroVQA: 66.22
🏆 MolecularIQ: 57.26
🏆 SGI-Bench (Scientific Agent): 52.52
🏆 MMLU Pro: 88.00
🏆 MMMU Pro: 76.88
🏆 IMO-Bench: 84.00
🏆 MathVision: 83.36
🏆 HMMT-2026: 87.31
🏆 PinchBench (Coding Agent): 88.22
⚡ It delivers performance comparable to the trillion-parameter Intern-S1-Pro on many scientific tasks while being far more efficient.
🧬 First open-source model with material crystal structure generation capabilities strong scientific agent performance.
💾 Note: The FP8 version is 38.5GB → best suited for dual RTX 3090/4090/5090 setups. Perfect for Strix Halo or Mac Studio 64GB.
✅ Fully open source (Apache 2.0)
✅ Supports thinking mode tool calling
✅ Available on vLLM & SGLang
🌟A major win for open-source scientific AI!
May 15

🥳Introducing Intern-S2-Preview, an efficient 35B scientific multimodal foundation model.
1⃣Delivers performance comparable to the trillion-scale Intern-S1-Pro on core scientific tasks.
2⃣The first open-source model with material crystal structure generation capabilities and strong general capabilities.
3⃣Significantly stronger scientific agent capabilities on multiple benchmarks.
4⃣Improves MTP acceptance rate and token generation speed via shared-weight MTP KL loss.
5⃣CoT compression shortens responses while preserving strong reasoning , improving both performance and efficiency.
🥰Now supported by vLLM (@vllm_project) and SGLang ( @lmsysorg ) — with more ecosystem integrations on the way.
🤗Model:
@huggingface
huggingface.co/collections/i…
@ModelScope2022
modelscope.cn/collections/Sh…
🤗GitHub:
github.com/InternLM/Intern-S…
🤗Try it now at:
chat.intern-ai.org.cn

6
19
185
20,223

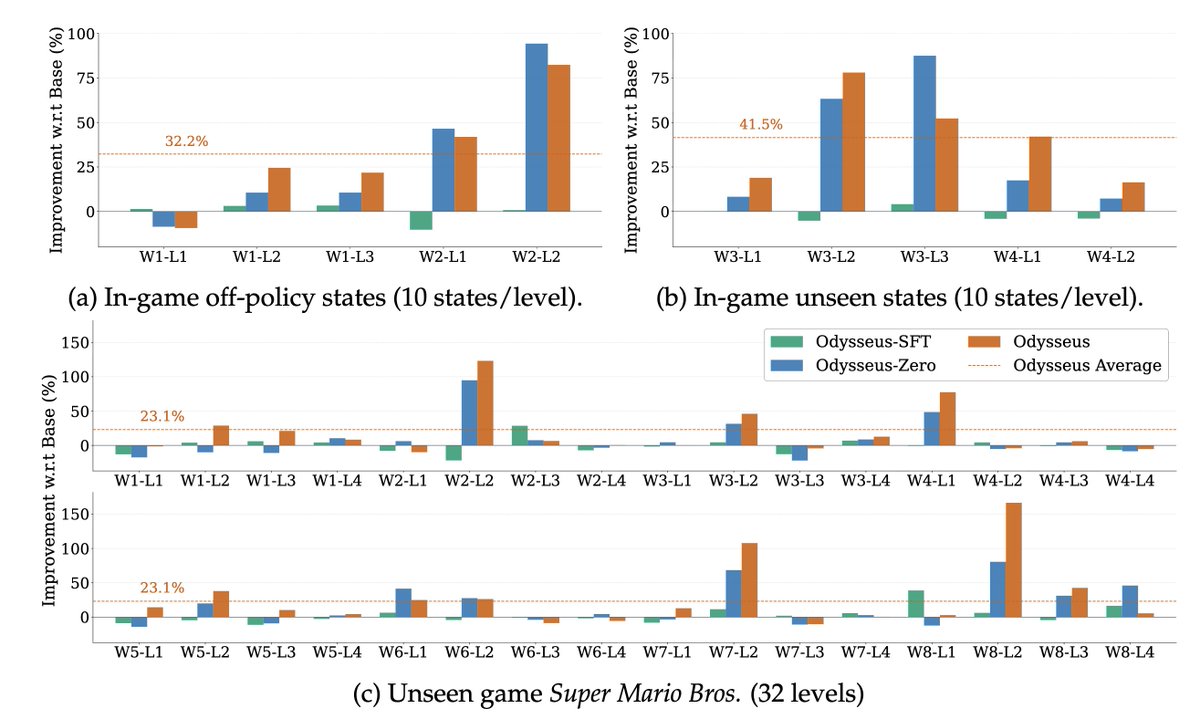
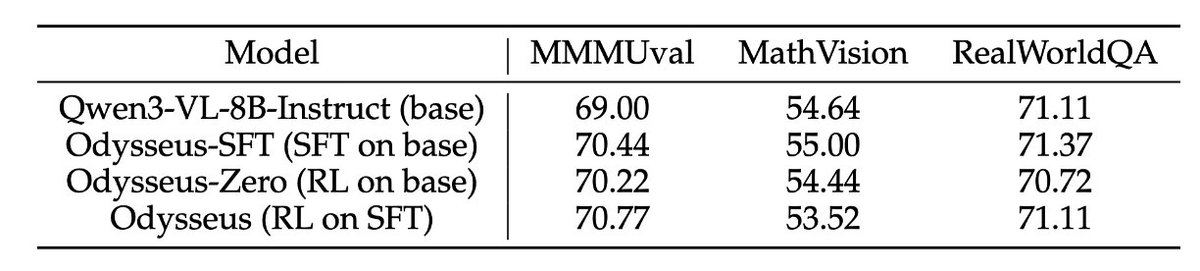
(5/N) The trained agent also generalizes beyond its training levels:
• 32.2% on in-game off-policy states
• 41.5% on unseen Super Mario Land levels
• 23.1% on cross-game Super Mario Bros. levels
All relative to the base model.
Importantly, after extensive game RL training, Odysseus maintains comparable performance on general multimodal benchmarks such as MMMU, MathVision, and RealWorldQA.
So the model gains decision-making ability without an obvious loss of general VLM capability.
1
1
8
668


Apr 23
The numbers nobody expected from an open-source release:
>> 54.0 on HLE with tools
>> 58.6 on SWE-Bench Pro
>> 76.7 on SWE-bench Multilingual
>> 83.2 on BrowseComp
>> 93.2 on MathVision with Python
It beats every other open model. It trades punches with the closed frontier.

2
1
17
3,347


Apr 20
It is a coding master while also a reasoning (first ever 90 GPQA-D oss model) and vision (93 MathVision with python) master; try chat with it on kimi.com
Apr 20

Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

43
1,537

Apr 20
Um lab chinês que quase ninguém no Brasil conhece acabou de humilhar os três maiores labs de IA do planeta.
Modelo open-source.
Pesos no HuggingFace. Gratuito.
E bate Claude Opus 4.6, GPT-5.4 e Gemini 3.1 Pro em 6 benchmarks.
Não é exagero.
A Moonshot lançou o Kimi K2.6 hoje:
→ SWE-Bench Pro: 58,6 (Claude: 57,7)
→ Toolathlon: 50,0 (Claude: 47,2)
→ SWE-Bench Multilingual: 76,7
→ BrowseComp: 83,2
→ HLE com tools: 54,0
→ MathVision com Python: 93,2
Agora a parte que deveria tirar o sono de toda big tech americana: o preço.
Kimi K2.6 via API: $0,60/milhão de tokens de input. $2,50 de output.
Claude Sonnet 4.6: $3,00 e $15,00.
5x mais barato no input. 6x no output.
E como os pesos são abertos, qualquer empresa com GPUs roda sem pagar nada para a Moonshot.
Mas o número mais assustador não é benchmark nem preço. É velocidade de execução.
O modelo rodou 4.000 tool calls em uma sessão única. 12 horas de execução contínua. 300 sub-agentes em paralelo. Pegou um modelo local, reescreveu a inferência inteira em Zig, e foi de 15 tokens/segundo para 193. Sozinho.
Um engenheiro de software autônomo que trabalha 12 horas sem parar e não cobra salário. Open-source.
A OpenAI cobra $200/mês pelo Pro.
A Anthropic levantou $60 bilhões em valuation.
O Google queima $75 bilhões por ano em infraestrutura.
E um lab de Pequim, com uma fração desse capital, está entregando de graça o que essas empresas dizem aos investidores que custa dezenas de bilhões para construir.
A cadência é o que mata.
K2 em julho de 2025.
K2.5 em janeiro de 2026.
K2.6 agora.
A cada 8 semanas a Moonshot solta um modelo que come mais um pedaço do moat dos labs fechados. Dessa vez, em benchmarks agênticos, o moat evaporou.
Em janeiro o DeepSeek evaporou $600 bilhões da Nvidia em um único dia e forçou a OpenAI a tornar o ChatGPT gratuito na mesma semana.
Agora a Moonshot fez de novo.
Essa é a segunda vez em quatro meses. Vai ter uma terceira.
Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
43
225
2,207
335,168

Apr 20
Kimi K2.6 Launched: Open-Source Competing with Frontier Models
- Agentic coding king: #1 on SWE-Bench Pro (58.6), beating GPT-5.4 xhigh (57.7), Gemini 3.1 Pro (54.2), Claude Opus 4.6 (53.4)
- Open-source SOTA: Moonshot AI released weights code on HuggingFace first open model competing at frontier level in complex agentic tasks
- Extreme long-horizon: handles 4,000 tool calls over 12-hour runs, manages full-stack repos, DevOps, performance tuning across 100 files
- Massive agent swarms: supports up to 300 parallel sub-agents for large-scale autonomous execution (upgrade from K2.5)
- Frontend mastery: strong in motion-heavy UI WebGL shaders, Three.js, GSAP, Framer Motion
- Multimodal prowess: 54.0 on HLE (with tools), 93.2 on MathVision, strong beyond just coding
- Where it lacks: behind Muse Spark in visual factuality (SimpleVQA), slightly behind GPT-5.4 & Gemini 3.1 Pro in top-tier reasoning
- Cost advantage: local runs → no API cost, better privacy, more control
Open-Source is now seriously competing not replacing frontier models yet, but closing the gap fast

5
3
36
3,466

Apr 20
Kimi K2.6 just matched or beat Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro on 6 benchmarks, dropped the weights on HuggingFace, and the Western AI press barely covered it.
That's the story everyone's missing.
Moonshot is now shipping frontier-tier open weights every 8 to 10 weeks. K2 in July 2025. K2.5 in January 2026. K2.6 today. Each release closes the gap with the closed US labs on the benchmarks that matter for agents, and K2.6 actually wins on SWE-Bench Pro (58.6 vs Claude's 57.7), SWE-Bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0 vs Claude's 47.2), and MathVision w/ python (93.2).
The pricing delta is the part nobody is pricing in. Kimi K2 runs roughly $0.60 per million input tokens and $2.50 per million output. Claude Sonnet 4.6 is $3.00 and $15.00. That's 5x and 6x. The open weights mean anyone with H100s can host it themselves at closer to unit cost.
Now the cascade. Every closed lab prices on the assumption that a capable substitute doesn't exist. Anthropic, OpenAI, and Google all have pricing power because the benchmark gap to open weights was real in 2024 and shrinking in 2025. In April 2026, on agent tasks, the gap inverted on some benchmarks.
The subscription business depends on enterprises not benchmarking alternatives on their actual workloads. The second a procurement team runs a two-week bake-off with K2.6 on their actual codebase and the outputs pass QA, the 6x cost savings make the switch defensible in a slide. One CFO does this math out loud and it moves.
The deeper point. There are now two frontier races happening in parallel. The US labs are racing to AGI and charging $200/mo for it. Moonshot, DeepSeek, and Qwen are racing to match frontier capability at commodity prices with open weights. These are different games with different endgames.
The closed labs win if capability scales faster than compute gets cheaper. The open labs win if the marginal frontier benchmark point stops mattering to 90% of enterprise workloads.
K2.6 is the first release where the second scenario stops being theoretical for coding agents.
Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
9
14
112
19,879

Apr 20
🚨 Moonshot AI just open-sourced Kimi K2.6
12-hour autonomous coding sessions. 4,000 tool calls without losing context.
A 68.2 score on long-horizon engineering benchmarks.
And it learned Zig on the fly to beat LM Studio by 20%.
Here's the full technical breakdown:
(in very simple words)
First, the problem with every "coding AI" you've used until today.
They write functions. Not systems.
Ask Claude or GPT to build you a feature, you get 50 lines of clean code.
Ask them to optimize an entire inference engine in a language they've never seen, iterate 14 times over 12 hours, and beat a specialized desktop app?
They forget what they're doing by iteration 3.
Kimi K2.6 solves this with a fundamentally different capability stack.
The core innovation: Long-horizon execution Agent swarm coordination.
Let's break each one down.
Long-horizon execution (the "never sleeps" engine):
Current AI models are sprinters. K2.6 is a marathon runner.
Most coding agents lose coherence after 10-20 tool calls.
Their context becomes a blurry mess of half-remembered files and abandoned strategies.
K2.6 maintained perfect execution across 4,000 tool calls and 14 iterative optimization cycles over 12 continuous hours.
The task: download Qwen3.5-0.8B, deploy it locally on a Mac, and implement inference from scratch in Zig - a systems language so niche most developers have never touched it.
Starting point: ~15 tokens per second.
End point: ~193 tokens per second.
That's not incremental improvement. That's 13x optimization through persistent, coherent iteration.
And it ended up ~20% faster than LM Studio, an app built specifically for this exact job.
This is where it gets wild.
Agent swarm capabilities (the "parallel engineering org" mode):
K2.6 doesn't just code. It orchestrates.
Traditional AI agents work like a solo developer.
K2.6 can spawn and coordinate parallel sub-agents that explore different optimization strategies simultaneously.
Think CPU kernel tuning, GPU shader optimization, memory layout experiments, and SIMD instruction vectorization - all happening at once, coordinated by a central orchestrator that prevents conflicts and merges the best results.
It's the difference between hiring one freelancer and deploying an entire dev agency that works overnight.
The architecture making this possible:
Sparse expert routing means K2.6 processes each token only through the most relevant specialist networks.
Instead of activating the entire model brain for every word, it summons exactly the experts needed - keeping inference costs manageable despite massive total capacity.
On top of that: native multimodal understanding, and "Preserve Thinking" mode that maintains reasoning chains across disconnected sessions.
The model doesn't just remember what it told you. It remembers how it reached the conclusion.
The numbers - what the benchmarks actually show:
→ Kimi Code Bench: 68.2 (up from 57.4 on K2.5) - a 19% jump on end-to-end engineering tasks
→ Terminal-Bench 2.0, SWE-Bench Pro, SWE-Multilingual - competitive with closed-source frontier models
→ OSWorld-Verified, Toolathlon - strong agentic environment performance
→ MathVision Python, V* Python - visual reasoning with code execution
The honest caveat:
This is a large-scale model.
Even with sparse expert activation, you need serious GPU infrastructure to self-host.
Running K2.6 locally isn't a "download and run on your MacBook" situation.
For indie devs, the API and Kimi Code terminal tool are the real play.
For researchers, the open weights are a goldmine.
The honest limitation nobody is talking about:
Open-source long-horizon agents are so new we don't have robust safety benchmarks for 12-hour autonomous execution.
In a fully unsupervised pipeline, a model this capable can also make persistent, coherent mistakes for hours before anyone notices.
The competence is real. The oversight requirement is also real.
The Kimi K2.6 vs Qwen3.6 picture:
These dropped within days of each other.
They tell the same story from different angles.
Qwen3.6: 1M context, hybrid linear attention, built for reading and reasoning at massive scale.
Kimi K2.6: 12-hour execution, agent swarms, built for building and shipping at massive scale.
One is the research assistant. One is the engineering team.
Together, they prove the open-source ecosystem isn't catching up to closed source anymore.
In coding and agentic execution, it's pulling ahead.
The geopolitical angle:
K2.6 is open-sourced. Weights on Hugging Face. API live at kimi.com.
Closed frontier models: locked weights, premium pricing.
Kimi K2.6: Open weights, API pricing that undercuts most closed alternatives significantly.
For startups building agentic products, that cost delta is the difference between burning runway and shipping profitably.
The architectural throughline from K2.5 → K2.6:
Same core bet every time:
Sparse expert routing long-context coherence tool-use autonomy = frontier capability at sustainable inference cost.
And K2.6 is the sharpest expression of that bet yet.
The bottom line:
Kimi K2.6 is not just a better chatbot.
It's an autonomous software engineering organization that fits in an API call.
The 12-hour Qwen deployment isn't a party trick.
It's a proof of concept for what happens when AI doesn't forget, doesn't tire, and doesn't stop iterating.
Moonshot AI didn't just ship a model.
They shipped a dev agency that works around the clock.
The open-source AI race just got a lot more serious 🔥

Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
8
1
12
2,396

This is pretty impresive - its definetly strong model
BUT 🛑
Claude Opus said it best
"⚠️ The Kimi marketing framing is misleading. Across all 10 benchmarks, GPT-5.4 (xhigh) leads with 4 wins. Kimi K2.6 wins 3/10 benchmarks — strong in DeepSearchQA & V*, but loses on Toolathlon, OSWorld, MathVision, SWE-bench Multilingual, and V*. The original chart's blue bars draw the eye even when Kimi isn't first."

Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
1
2
58

🚀 Open-source AI just leveled up BIG time!
Kimi K2.6 from @Kimi_Moonshot is straight-up claiming SOTA on multiple coding & agent benchmarks:
- SWE-Bench Pro: 58.6
- SWE-Bench Multilingual: 76.7
- Humanity’s Last Exam (with tools): 54.0
- MathVision (Python): 93.2
It’s going toe-to-toe with GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro… while being fully open weights! 🔥
New superpowers include 4,000 tool calls across 12 hour runs (Rust, Go, Python), 300-parallel sub-agent swarms, and motion-rich frontends with WebGL GSAP Three.js. Claw Groups for human bot collab? Game changer.
Open weights code are live right now on Kimi’s platform. Devs, this is the moment open-source pulls ahead.
Who’s spinning up an agent swarm first? Drop your thoughts 👇 Have you tried the new agent mode yet?
#KimiK26 #MoonshotAI #OpenSourceAI #SWEbench #AIAgents #CodingRevolution #LLM #DevTools
Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
1
3
265

open source just absolutely cooked...
Kimi K2.6 is now beating Claude Opus 4.6 across coding, agents and vision.
SWE-Bench Pro: 58.6 vs 53.4
Terminal-Bench 2.0: 66.7 vs 65.4
HLE-Full w/ tools: 54.0 vs 53.0
LiveCodeBench v6: 89.6 vs 88.8
MathVision: 87.4 vs 71.2
DeepSearchQA (f1): 92.5 vs 91.3
V* w/ python: 96.9 vs 86.4
and the real world run is insane. 12 hrs of continuous execution, 4,000 tool calls, throughput from ~15 to ~193 tokens/sec
if this is April, 2026 is gonna be absolutely unhinged for open source AI lol
Apr 20
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…
4
8
29
11,399

Apr 20
While everyone was arguing over Chinese open weights this week, Seoul shipped the first serious non-US/non-China open VLM. 🇰🇷
LG AI Research released EXAONE 4.5 — a 33B open-weight vision-language model (plus FP8 GGUF variants) on Hugging Face on ~Apr 9. Quiet release, real numbers. huggingface.co/LGAI-EXAONE
The chain reaction so far:
-> HF downloads climbed past ~22k across variants inside a week
-> Community GGUF quants shipped within 48 hours, landing it on Ollama configs alongside Qwen3-VL and the usual Gemma/GLM suspects
-> LiveCodeBench v6 81.4, MMMU 78.7, MathVision 75.2, OmniDocBench 81.2, STEM avg 77.3 — ahead of GPT-5-mini (73.5) on STEM, competitive on vision
-> 262K context, industrial-document bias in the training mix — not a coincidence given LG's enterprise play
The pattern worth watching: open-weight VLMs are becoming a three-horse race — China (Qwen3-VL), Google (Gemma 4 multimodal), and now Korea. Not Meta. Not a US lab. Honest caveat: EXAONE is strongest on documents and STEM; general chat still lags pure-text LLMs of similar size, and the ~10-day-old release means production stress tests are still landing. We're running it through our own workloads this week.
What we're shipping at OSSAIHub to help you cut through this:
— Side-by-side: EXAONE 4.5 vs Qwen3-VL vs Gemma 4 on real document STEM workloads, not cherry-picked leaderboard rows
— Local hardware configs (quad-5090, single-5090, M4 Max) with GGUF quant sweeps
— Deployment checklist for running EXAONE behind vLLM / llama.cpp with 262K context actually usable
Running any open VLMs in production yet? What's your stack?
#OpenSourceAI #LLM #VLM #LocalAI #OSS
huggingface.co/LGAI-EXAONE/E…
2
110

Apr 6
Moonshot trained a model on 15 trillion tokens of mixed vision and text data. The result scores 96.1 on AIME 2025 and 76.8 on SWE-Bench Verified.
Model Spotlight: Kimi K2.5 by @kimi_moonshot
1T total parameters. 32B activated per token (MoE). 256K context. Vision baked into pretraining, so it reads documents, charts, code screenshots, and video without a separate adapter.
The benchmarks put it right next to GPT-5.2 and Claude 4.5 Opus on most tasks. On a few vision benchmarks (MathVista, OCRBench, InfoVQA), it outperforms both.
78.5 MMMU-Pro (multimodal reasoning)
84.2 MathVision
76.8 SWE-Bench Verified
85.0 LiveCodeBench v6
The other thing worth knowing: Agent Swarm. You give it a complex task, K2.5 breaks it into parallel sub-tasks, assigns domain-specific agents to each one, and coordinates output. BrowseComp jumps from 60.6 to 78.4 with this approach.
It can also look at a UI mockup and write the frontend code.
Running on Chutes with TEE. Your prompts and outputs stay protected from GPU operators during inference.
Try it here: chutes.ai/app/chute/2ff25e81…
Have you tried any of the K2 family? Curious what use cases people are running.

10
34
256
16,207

the MathVision score (64.7) beating GPT5-minimal is wild for an open-source A3B model. discrete tokens for vision finally working at scale without the understanding/generation trade-off
3
74