Ligma Testacleesius retweeted

Remember - you should respect police and government officials because they're highly trained, objective people who are simply looking out for your best interests.

A Cherokee County deputy was fired and arrested Friday evening after an internal audit exposed unauthorized use of the agency's license plate reader system. fox5atlanta.com/news/cheroke…
15
47
575
8,936

12s
Same here.
@pumpfun_pepe is inclusive, all different, walking odds to the same objective. Make NFTs great again. Healthy competition between many quality projects/collections.
That brings confidence to new people for the rising we all want.
It’s happening !


shea (she/it/they) 🏳️⚧️🇵🇸 retweeted

Guys, you don't understand, I know all the previous Republican governors have been objective failures, but if we just elect ONE more Republican, THIS time they'll solve all of our problems.

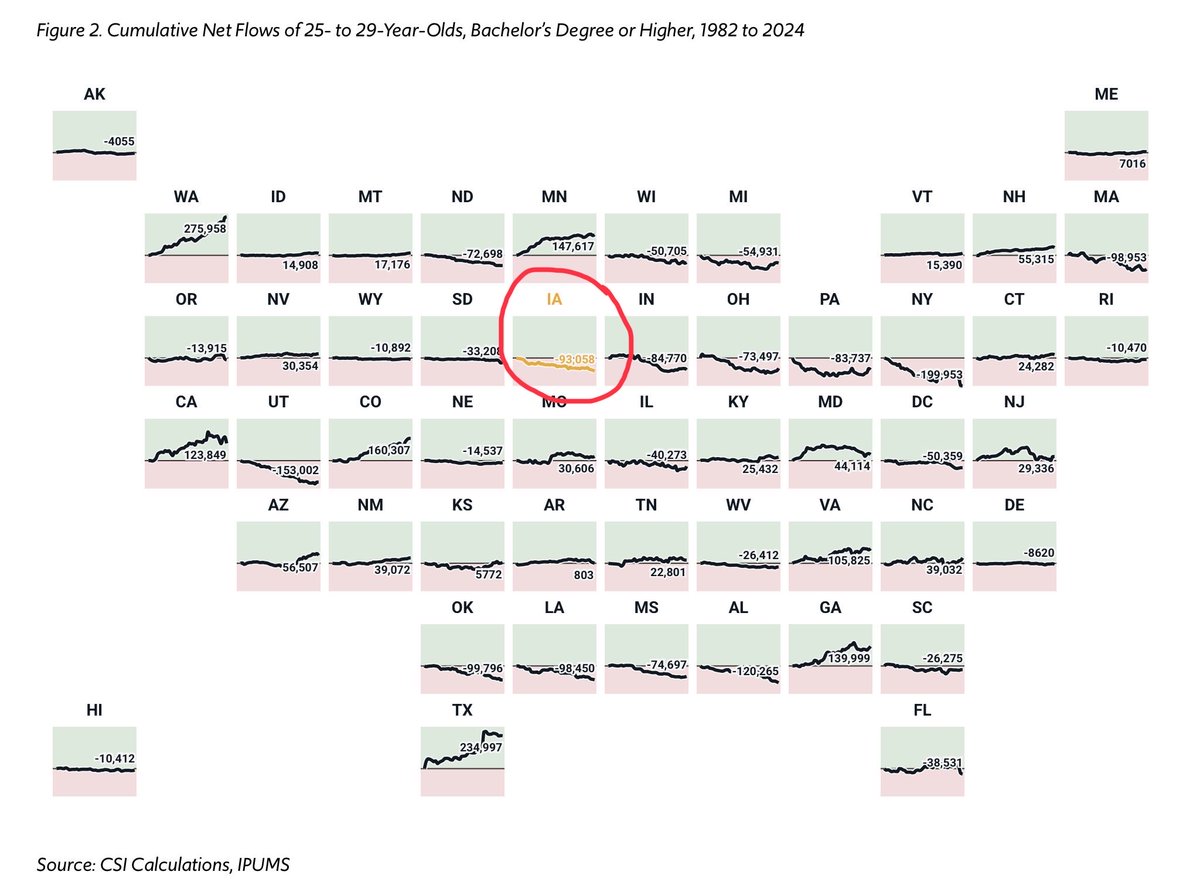
Iowa is losing our young people at one of the highest rates in America --- 4th worst in the nation for kids leaving the state.
Zach Lahn gets it: “You cannot build a state or a culture if your kids are leaving faster than 46 other states.”
Without young families staying, our rural communities, churches, schools, and family farms weaken.
10
76
1,160
34,036

The default frame for the last two years has been more gigawatts: bigger clusters, more power, more concrete poured. Stanford's @HazyResearch spent that same window measuring the opposite direction, and came up with an intelligence-per-watt metric: task accuracy divided by mean power draw, measured per query on real workloads.
Across their 2023 to 2025 measurement window, intelligence-per-watt improved 5.3x. Roughly 3.1x of that came from better models and 1.7x from better hardware. On single-turn chat and reasoning, 88.7% of queries could be answered correctly by a local model under 20B active parameters. Local accelerators still trailed cloud silicon by 1.4 to 7.4x on the same workload, but a hybrid router that sends easy queries local and hard ones to the cloud cut energy, compute, and cost by 60 to 80% against a batched cloud baseline. The win is in the routing.
NVIDIA's DGX Spark put 128GB of unified memory and a petaFLOP at FP4 on a desktop, and open-weight families like Qwen3, gpt-oss, Gemma, and Granite now trail frontier cloud models by 6 to 12 months on most personal-AI tasks rather than years.
MoE decouples capacity from per-token compute, which works for cloud serving at batch, but on a single-user device most experts sit cold across queries, so you pay in memory for capacity you rarely touch. They argue local-first models should look different: dense, small active footprint, quantization-aware, trained with local serving as a real objective rather than an afterthought.
Power, not chips, is the binding constraint on most AI buildout right now, and almost every public argument about it is denominated in gigawatts and $$$ instead of useful work per watt. A metric that ties accuracy to energy changes which number you push on. My read: one of the frontiers in compute is a smarter router that decides, query by query, which one earns the watt. How many gigawatts we need isn't the only discussion point on the power debate.
2

Not exceptional? The free market says otherwise. Your subjective opinion means nothing to the objective data suggesting the value he has created. The Chinese’s have cars in the US that are hands free? Thats news to me.
1

I like how an objective fact becomes bullshit when it works against you but we have to just accept those other things as unchangeable, undeniable proof.
You're exhibiting a blatant and obvious double standard in real time and I am supposed to believe you're intelligent?
I mean we all make mistakes, but come on.
2

They need to reconstitute. Safety isn’t an objective. I still prefer Claude.
1

49s
today yes, but I mean a new powerful model, one of those that scares the politicians, would be one that is not simply agreeable but truly/maximally objective to the point in which people start to consider it as some sort of infallible oracle
1

Hahahahaha… Israel is going to stop short of their objective? Yeah right!
2
Mide 18'OFIVE 💫🎭 retweeted

All objective football watchers acknowledged Nigeria as the team that played best football in last AFCON.
Ask Yaya Toure. Ask Rio Ferdinand

Take Nigeria out please
5
28
312
13,504

Most of us are contented with daily monitor reporting about Muganga..it's so objective and not only appealing to Muganga's social media influencers
1

turns out the hottest organ is still the pattern-recognition engine pretending it's objective
2

Humans are group animals due to their physical characteristics. Partnering and/or bonding in small groups is necessary to protect babies. A positive emotion helps that. That's also where objective morality comes from.
1

Love it when some random twitter yahoo (who let's be real here doesn't seem the sharpest tack in the drawer) gives the most idiotically subjective take ever and then claim he's speaking truth. You want objective truth? Knicks 4, Spurs 1.
2

This whole twt thread is ruining everything for me we. Got ppl hating on BB too now I hope OP met their objective
11h

Some Male concerts: humping, misogyny, objectifying women, thirst-trap performance, and sometimes the performance itself isn't even giving 🤮
Female concerts: FUN. BEAUTIFUL. TALENT. Vocals, visuals, dance, song choice, stage presence, crowd interaction, women supporting women, and everyone having the time of their lives 😭🤍✨
2
K retweeted

Jun 13
If you are not absolutely certain of objective and completely legitimate evidence that proves her to be the demon so many have publicly made her out to be, then to participate in even the most minute public tarring and feathering of her makes you the actual demon.

231
28
372
10,009
Your Least Favorite Uncle retweeted

These same people literally do not believe in objective morality btw.
Jun 13

The first trillionaire being announced before the end of child poverty is not a success story.
It’s a moral failure.
19
10
279
8,085
V Dale Pelz Jr retweeted

Dear @POTUS @realDonaldTrump
Hezbollah is an arm of Iran’s IRGC with only one objective: to wage war against America, Israel — and the Lebanese people. Hezbollah has been attacking America and Israel for over four decades. It has violated every ceasefire. It has killed America and Israeli diplomats, civilians and soldiers, violated U.N. Security Council Resolution 1701 requiring it to disarm, built the world’s largest terrorist missile arsenal, and prepared for an Oct 7 cross-border invasion. Under the command of its IRGC masters, it has destroyed Lebanon and blocked peace with Israel. The IRGC and Hezbollah are trying to destroy your Iran policy and ruin your legacy.
85
319
1,157
59,556

The PNPRisers-led party is a part of government. They influence policies of the govt. Their elected members are paid.
When they (your Risers) act foolishly, you pretend as if you only have one 👁️.
Don’t have a problem with people who are objective in their opinions.
You’re not.