

ぬン@メンテナスモード retweeted

Jun 9
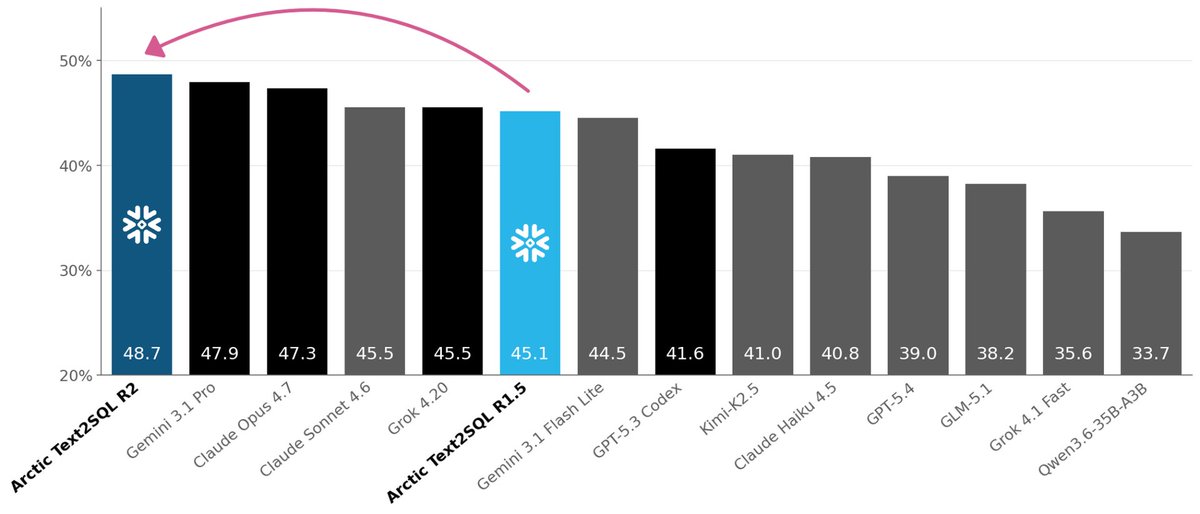
Enterprise SQL is where general models break.
Arctic-Text2SQL-R2 takes a different path:
→ beats frontier models
→ 30–150x smaller
→ trained on real SQL
→ rewards true correctness
Specialization > scale for real workloads: bit.ly/4fyOIjU
1
1
18
2,310

great post! maybe a text2sql tool woulb be a great tool example to put in PAW playground... maybe using sqlite or sqlite wasm database and the possibility to a user query the DB using natural language...
1
1
51

Jun 8
落地智能问数首要解决的问题不是选技术,而是明确用户画像、场景和失败容忍度。老板要准确高效的看板,适合Text2Metrics和skill;一线员工仅做月报、周报或临时分析,难在数据清洗,也不知道问什么、怎么分析,适合skill。数据分析师需求高频随机,懂SQL、能验错且容忍偶发失败,更适合Text2SQL。
31

8週間に一度バージョンアップするDataiku
【#Dataiku 14.6 新登場】
エージェントと企業のナレッジ・インサイトをダイレクトに繋ぐ、強力な機能拡張がリリースされました ``。
📌 3つの進化ポイント:
1️⃣ エージェントの現場実装(Agent Hub)
Teams上でエージェントをデプロイ、SharePointドキュメントと自動同期して常に最新情報でグラウンディング ``。
2️⃣ Snowflake連携の強化
Snowflakeのセマンティック定義をそのまま「セマンティックモデル」へインポート。Text2SQLの精度を劇的に向上 ``。
3️⃣ Consumer Homepageの新規搭載
ビジネスユーザーが欲しいインサイト、推奨コンテンツに一瞬でアクセスできる直感的な新ポータル ``。
さらに、質問書(RFI/RFP)の回答生成をAIで効率化・自動管理する「RFx Accelerator」も実装されています ``。
AIを「実験室」から「実用」へ。アップデートの詳細はリンクをチェック!
👉 doc.dataiku.com/dss/latest/r…
#OneDataiku #AIエージェント #データ分析
2
281

May 30
有个 Text2SQL 小模型训练任务,让我重新理解了“人工标注”。
一开始让 BI 团队打标,以为业务专家可靠。
结果发现:字段口径不统一、查询意图不清楚、SQL 风格不稳定。
标注质量甚至不如直接用顶级大模型生成。
AI 落地里残酷的一点:你以为人在提供高质量数据,其实在把业务混乱标进模型里。
2
1
30
4,940

With companies like @OpenAI, @Meta, @databricks and many others deploying agents to interact with massive amounts of data, our work looks at how the API/tool surface exposed to agents, impacts the agent's efficacy in performing such text2SQL and analysis tasks.
1
2
310

May 27
מוקדם יותר היום כתבתי ש-text2sql היא דוגמא מצויינת ל-Bitter Lesson. אסביר למה התכוונתי!
ה-״bitter lesson״ ב-AI research הוא ״פשוט צריך עוד דאטא״.
וביותר מילים: ״במקום להבין את הבעיה הספציפית, הניואנסים שלה ובניית מודל\דאטא מתאימים - נזרוק עשר טון דאטא על הבעיה והפיתרון יתגלה״.
זה כמובן לא כזה קל ועל זה פעם אחרת. אבל ב-2020-2022 זה פשוט ״קרה״ עם GPT-3/ChatGPT ו - "emerging capabilities״ - שהגיעו יחד עם אימון מודל גדול משמעותית ממה שהכירו עד אז כמות דאטא גדולה בהתאם.
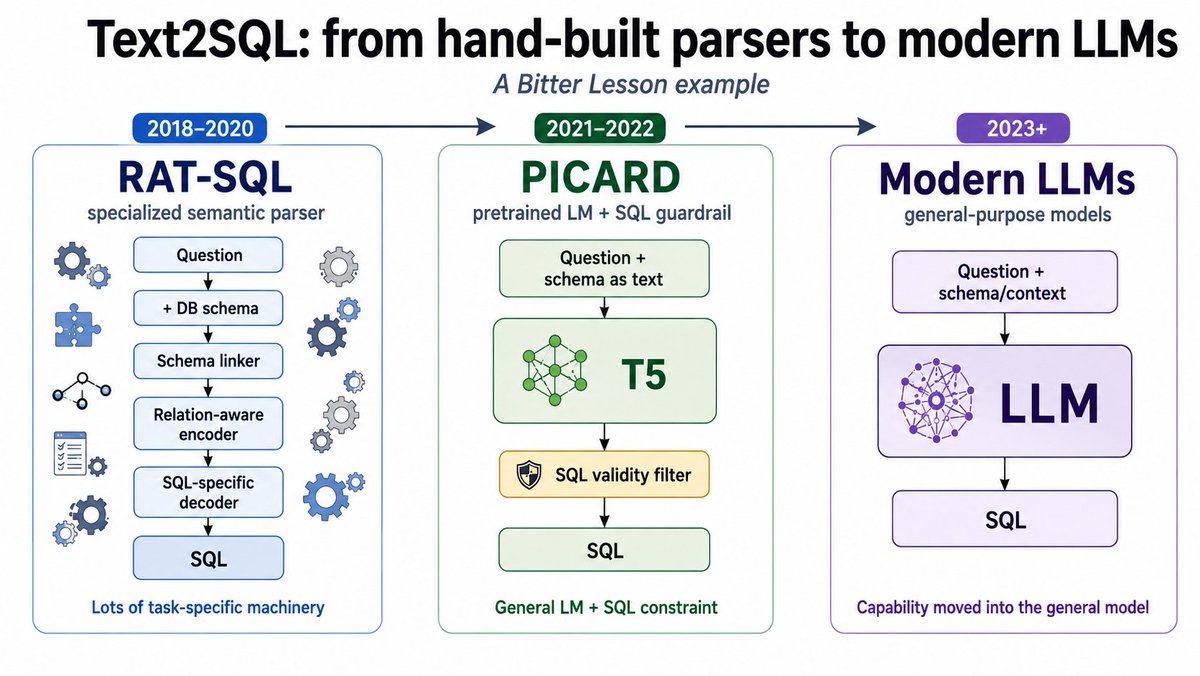
ועכשיו ל-text2sql:
עד 2022\ChatGPT, הגישה לפיתרון של text2sql התבססה על domain specific knowledge/solution. במקרה של SQL זכורות לי שתי שיטות מאותה תקופה: RAT-SQL (microsoft research) ו-PICARD (servicenow).
הראשונה - RAT-SQL - התבססה על semantic parsing: מודל שמקבל (ומתאמן כך) על שאילתה, סכמת SQL ו-"relation-aware self-attention". אמלק: מודל שיודע שהוא מתמודד עם SQL מכל כיוון אפשרי ומחווט לפתור את המשימה הספציפית הזאת בלבד.
השניה - PICARD - צעד קדימה אל ההווה - אימון מעל מודל שפה פתוח של גוגל (T5, שהיה אז ה-SOTA של הקוד הפתוח). זהו מודל seq2seq - כלומר כזה שמקבל טקסט ויוצר טקסט (ולא בצורה המקובלת היום). הקלט הוא עדיין שאילתה סכמה של טבלה בסינטקס ספציפי. בשלב ״יצירת הטקסט״ קיים צעד נוסף שמוודא שהטקסט המתקבל הוא SQL ״חוקי״ ודוחה כל עוד לא התקבל אחד כזה.
ולמה אני אומר שזו ״דוגמא ל-Bitter Lesson״? כי היום אף אחד לא מאמן מודלים ליצירת שאילתות SQL מטקסט חופשי. אף אחד לא אופה עבורם קלט, אין output validation. יש לנו מודלים שאומנו על דאטאסטים שגדולים בכמה סדרי גודל על טקסט בשפות שונות, קוד, וגם SQL ופשוט יודעים לפתור גם את הבעיה הזאת יותר טוב מכל מה שהכרנו עד לפני כמה שנים.
וזה כיף.
6
47
4,817

May 27
I’m excited to share new research work from the Snowflake AI Research Team focused on advancing enterprise AI systems.
Arctic-Text2SQL-R2 is a reasoning model designed for enterprise SQL generation. Trained on Snowflake-native data and optimized for real-world enterprise SQL workloads, the specialized model outperforms larger frontier models on difficult SQL benchmarks despite being 30–150x smaller than other high-performing models.
To make specialized models like Arctic-Text2SQL-R2 practical at scale, the team also introduced ZoRRo (Zero Redundancy Rollouts), a set of optimizations that eliminate redundant computation in long-context RL workflows. ZoRRo accelerated RL training by up to 3.5x, reducing runtime from over five days to only 1.5 days. It also reduced memory consumption enough to support 3.2x longer context windows, enabling more efficient training on complex enterprise reasoning workloads.
Together, this work demonstrates how the next wave of enterprise AI innovation will be driven by both stronger domain-specific models and more efficient training systems. Read more in the blog posts in the comments:
Arctic-Text2SQL-R2: snowflake.com/blog/engineeri…
ZoRRo: snowflake.com/blog/engineeri…
@yao_zhewei @yuxionghe @samyamrb @jeffra45 @StasBekman
3
10
814
May 27
היוז קייס הספציפי של text2sql הוא אולי האהוב עליי כדוגמא ל-Bitter Lesson
May 26

לפני משהו כמו שמונה שנים הציעו לי להצטרף לחברה שעושה text2sql. לא קרה כי שכנעו אותי שהטכנולוגיה לא בשלה למוצר איכותי. היום אני עושה text2sql בעשר שורות קוד עם LLM בקוד פתוח. מדהים
3
31
11,563

May 26
לפני משהו כמו שמונה שנים הציעו לי להצטרף לחברה שעושה text2sql. לא קרה כי שכנעו אותי שהטכנולוגיה לא בשלה למוצר איכותי. היום אני עושה text2sql בעשר שורות קוד עם LLM בקוד פתוח. מדהים
5
58
16,587

荒天時でも気象情報を即座に届ける運航支援を実現する🚢
▶ go.aws/3RccA2A
問い合わせなしで気象情報を取得できる環境をどう作るか。ウェザーニューズ様が AI Agent と Text2SQL で構築した運航支援システムの設計と実装のポイントを紹介します。
#AWSウェブマガジン

1
8
5,123

May 24
セマンティックレイヤーって言葉、最近までエージェントがDWHやRDBを読む際のtext2SQLに代わる論理ビューの意味で使われてたけど、最近はコーディングエージェントのために整理した知識グラフやASTもそう呼ばれてるんだな。
May 22

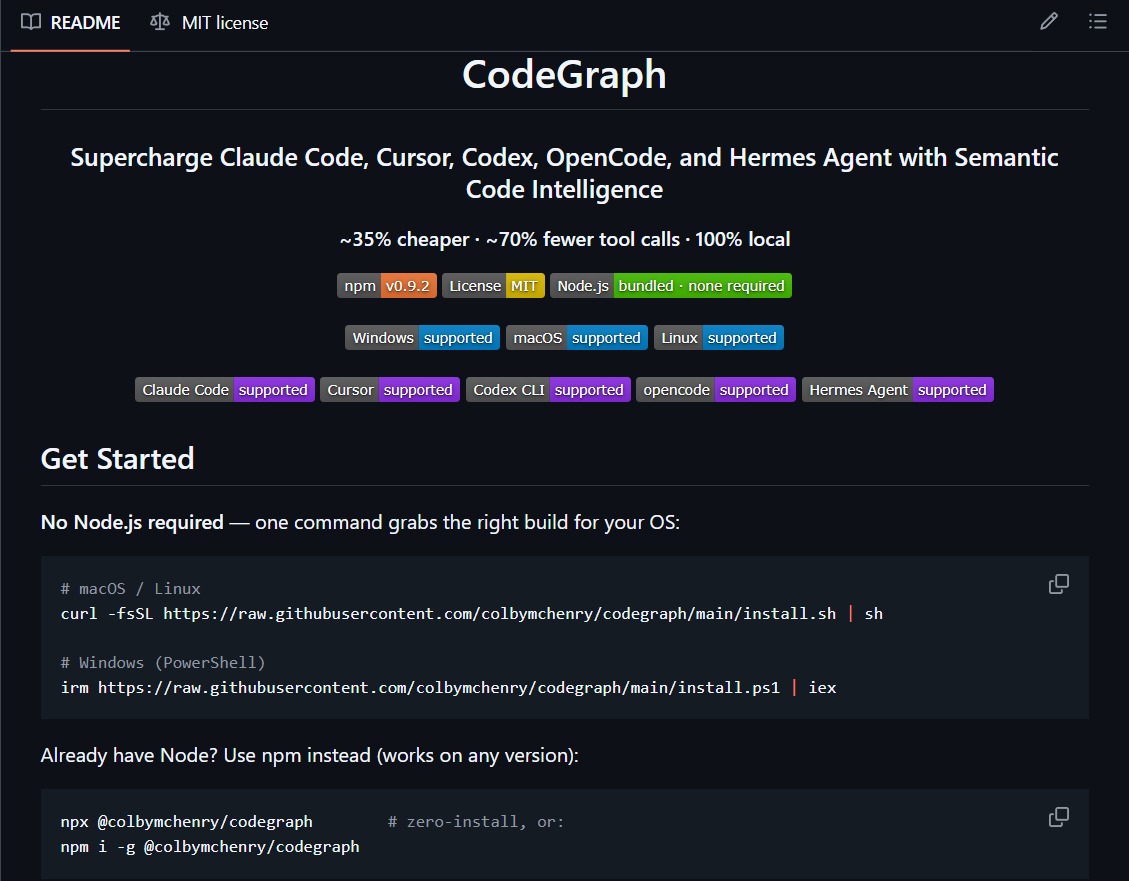
This is wild 🤯
Somebody finally realized AI coding agents spend half their time searching your codebase instead of actually understanding it.
So they built a local knowledge graph for Claude Code, Cursor, Codex CLI, OpenCode, and Hermes Agent.
Not another wrapper
Not another “AI devtool” landing page
An actual semantic layer that indexes your entire repo and lets agents query relationships, call graphs, routes, symbols, and dependencies instantly.
The wild part?
On real repos like VS Code, Django, Excalidraw, Tokio, and OkHttp, CodeGraph cut:
→ ~59% tokens
→ ~70% tool calls
→ ~49% execution time
→ ~35% cost
Instead of Claude Code or Codex endlessly grepping files and spawning exploration agents, they query a pre-built graph and move straight to the relevant context.
That changes the feel of AI coding completely.
Especially on larger codebases where Cursor, Claude Code, and Codex usually start drowning in file reads.
And the setup is absurdly simple:
npx @colbymchenry/codegraph
No external APIs
No cloud dependency
No weird config hell
Just local semantic intelligence for your codebase.
This is one of those repos where you instantly understand why it blew up to 14k stars so fast.
100% open source
Link in comments

1
13
76
13,090

May 21
LLM data prep is where a lot of model work quietly gets stuck.
DataFlow is an open-source data preparation and training system for generating, refining, evaluating, and filtering AI/LLM data from noisy sources like PDFs, plain text, and low-quality QA.
It helps you build reusable data workflows by turning cleaning and synthesis steps into operator-based pipelines you can reproduce, share, and extend.
Key features:
• Ready-to-use pipelines – covers text, reasoning, Text2SQL, knowledge-base cleaning, and Agentic RAG workflows
• Operator-based design – package generation, evaluation, filtering, and refinement steps into reusable pipeline components
• Custom operator support – create plug-and-play operators and distribute them through GitHub or PyPI
• WebUI option – run dataflow webui to build and execute pipelines through a visual interface
• Practical setup paths – install from PyPI with uv, use Colab, or run via Docker with GPU support
It’s open-source (Apache License 2.0).
Link in the reply 👇

5
22
75
2,614

May 18
> AI Tools Being Used By Data Engineers in 2026
- Data engineering has quietly become one of the fastest evolving roles in tech. AI is not replacing data engineers, it's making them 10x faster. here's every tool worth knowing right now
1. Vanna.ai / Defog / DAIN
- Text2SQL tools that eliminated the one-off SQL request problem for good
→ query Snowflake, BigQuery, Redshift in plain English
→ non-technical teams are self-serving data without touching SQL
→ data engineers are now building the systems behind these tools, not writing queries
2. Apache Airflow AI Layers / Prefect
- pipeline orchestration got an AI upgrade and scheduling will never be the same
→ DAGs auto-generated from plain text descriptions
→ agents handle dependency resolution and backfill decisions
→ scheduling conflicts flagged and fixed before they break anything
3. Monte Carlo / Soda AI / Bigeye
- autonomous data quality tools that don't just monitor, they act
→ writes quality checks automatically from plain language rules
→ detects schema drift, null spikes and volume anomalies early
→ some pipelines are self-healing now without a single page sent
4. Atlan / Alation
- LLM-powered cataloging that killed manual documentation
→ auto-generates column descriptions, lineage maps and ownership tags
→ sensitive fields flagged and classified without human input
→ manually maintaining a catalog in 2026 is just wasted time
5. dbt Copilot
- the transformation layer where AI is delivering the most immediate ROI
→ writes and explains dbt models inside your workflow
→ suggests optimizations on existing models
→ junior engineers shipping production-grade work faster than ever
6. Pinecone / Weaviate / Qdrant
- vector databases are now a core part of the modern data stack, not just an AI team problem
→ data engineers building embedding pipelines and chunking strategies
→ RAG integrations sitting alongside traditional ETL in the same stack
→ if your team is building LLM apps, someone needs to own this layer
7. AI Agents for DataOps
- the biggest shift happening right now, autonomous agents running data operations end to end
→ monitoring warehouses and triggering alerts without human intervention
→ root cause analysis on failed jobs done in seconds
→ data engineer role is shifting from executor to orchestrator
the engineers winning in 2026 are not the ones who know every tool
they are the ones who plugged the right AI into their stack and focused on higher leverage work
1
8
31
1,412

AIのトークン消費を前提にしたなんちゃってデータパイプラインとか野良データ基盤とか、データモデルもSSoTもないローデータからText2SQLをし続けているAI活用とかもコスト死する未来しか見えないので、備えてほうがよさそう。

今のAIサブスクの価格は永久に続かないので、備えておいた方がいいよ、って記事だった
・AI企業は市場シェアを独占するために採算度外視の低価格でサービスを提供している
・この現在の低価格はいわば一時的な補助金のようなもの
・つまり、永久に続くわけではない
・多くの企業がこの格差に気づかないままAIを業務に深く組み込んでいる
・例えば月額20ドルのプランでAPI換算すると、200ドルから400ドル分の処理を行うユーザーもいる
・現在のビジネスモデルは経済合理性ではなく、普及率を最優先して設計されている
・しかし自律的に動くエージェント型AIの登場によりこれまでの価格モデルは完全に崩壊しつつある
・今は、ユーザーがチャットするだけはなくなった
・AIが自律的に長時間稼働するため、トークン消費量が爆発的に増えている
・開発者向けのエージェント型ツールでは、数時間の制限枠が90分で使い切られる例もある
・複数のAIが連携して働くエージェントチームの運用はさらに桁違いのコストを発生させる
・実際、GitHubは定額制の維持が困難になり、2026年6月から従量課金制への移行を決定
・OpenAIの経営陣も現在の無制限プランを廃止の可能性を示唆している
・AIが業務に不可欠な存在になったタイミングで値上げされるという罠に企業は直面している
・IPOによって罠が発動する可能性がある
・各企業は、AIコストが将来的に2倍から10倍になった場合の予算シミュレーションをしておいた方が良い
・特定のAIベンダーに依存せず、他社製品へ切り替えられる選択肢を持っておくことが大事だろう
thestateofbrand.com/news/ai-…
4
27
4,992

May 15
#PyConUS is underway – and PyCharm is at booth 421, from May 13–19!
Come say hi to the PyCharm team, check out live demos, take the Python quiz, grab coffee, and create a 90s-style bracelet!
Chat with us about Python, PyCharm, data science, web development, community, and more.
Don’t miss Artem Trofimov’s talk: “Text2SQL: From Academic Benchmarks to Self-Service Analytics”.
See you at booth 421!

1
3
16
1,255

May 11
Text2SQLもしくはデータ分析エージェントの話題増えてきているけど、
・そもそもLLMが学習しているであろうドメイン
・ユーザーが分析の素養のある人が大半
の事例は話半分で聞いておいた方が良いと思う。そういう領域が難しくないわけではないけれど。
5
162