
Mapping job-postings to a taxonomy of industrial sectors without finetuning: “No Train, No Pain? Assessing the Ability of #LLMs for #TextClassification with no Finetuning” by R. Fechner, J. Dörpinghaus. ACSIS Vol. 40 p. 9–16; tinyurl.com/2s9tm9y3

1
3
3
57

9 Oct 2025
📘 Day 46 – 100 Days of ML
🧠 Topic: Text Classification using Naive Bayes
📖 Learn with @geeksforgeeks Nation SkillUp
👉Course: geeksforgeeks.org/batch/ds-1…
#100DaysOfML #MachineLearning #NaiveBayes #TextClassification #nationskillup #skillupwithgfg
3
62

25 Aug 2025
This paper studies active learning with parameter‑efficient fine‑tuning (adapters), showing AL PEFT improves PLMs in low‑resource text classification. - hackernoon.com/teaching-big-… #textclassification #activelearning(al)
2
2
520

2 Aug 2025
이것도 시작하는데 키워드 놓치긴 아쉽지.
@JoinSapien @cookiedotfun
Sapien은 혁신적인 분산형 AI 데이터 파운드리로, 인간의 전문지식과 AI 학습을 연결하는 프로토콜임.
쉽게 말해서 어떤 기업이나, AI 모델, 또는 에이전트가 인간의 전문지식을 소싱할 수 있고, 누구나 AI 발전을 위해 자신의 지식을 기여할 수 있는 무허가 프로토콜
주요 키워드 30개
-DecentralizedDataFoundry
-HumanInTheLoop
-RLHF
-DataLabeling
-LLMFineTuning
-TheForge
-PlayToEarn
-Gamification
-BaseNetwork
-PermissionlessProtocol
-QualityAssurance
-SlashingMechanism
-OnchainReputation
-TokenEconomics
-Crowdsourcing
-AITrainingData
-Annotation
-TextClassification
-SentimentAnalysis
-ImageClassification
-SubjectMatterExpert
-Marketplace
-ModelEvaluation
-SemanticSegmentation
-QuestionAnswering
-PointsProgram
-Stake
-Web3Infrastructure
-VariantFund
-LLM

3
6
129

23 Jul 2025
🚀 Introducing GLiClass‑V3 – a leap forward in zero-shot classification!
Matches or beats cross-encoder accuracy, while being up to 50× faster. Real-time inference is now possible on edge hardware.
huggingface.co/collections/k…
#TextClassification #NLP #ZeroShot #GLiClass
1
20
72
4,027

26 Jan 2025
Do check out a basic AI agent I built for classifying text sentiment in real-time. github.com/akshat-shah-2003/…… #ArtificialIntelligence #AI #Agent #AgenticAI #HuggingFace #TextClassification #SentimentAnalysis
2
33

11 Jan 2025
Congratulations to Prof. Muhammad Abulaish and his PhD student, Mr. Amit Kumar Sah, on the publication of their work, "Handling imbalanced textual data: an attention-based data augmentation approach." This research introduces an innovative data augmentation technique utilizes an attention-based deep learning approach to effectively balance imbalanced textual datasets by oversampling instances from the minority class. This approach is essential for addressing the significant natural language processing challenge of classifying imbalanced text data, which is prevalent in applications like sentiment analysis, hate speech, and fake news detection. The paper has been published in the International Journal of Data Science and Analytics (WoS/Scopus Indexed). It has achieved a noteworthy Impact Factor of 3.4 and a CiteScore of 6.4, indicating its substantial impact in the field. For more details, you can access the paper at its DOI: doi.org/10.1007/s41060-024-0….
Mr. Amit Kumar Sah
webofscience.com/wos/author/…
#SAU
#ProfMuhammadAbulaish
#AmitKumarSah
#InternationalJournalofDataScienceandAnalytics
#DataAugmentation
#ClassImbalance
#TextClassification
#AttentionMechanism
#Transformers

4
324

15 Nov 2024
RAG based Text Classification with LLMs
This paper introduces a semi-supervised learning approach involving RAG for text classification.
The proposed approach integrates few-shot learning with retrieval-augmented generation (RAG) and conventional statistical clustering.
The proposed approach demonstrates SOTA results, with few-shot augmented data alone producing results nearly equivalent to those achieved with fully labeled datasets.
Paper - arxiv.org/abs/2411.06175
#rag #llms #textclassification #nlproc #deeplearning #clustering

1
19
1,658
11 Nov 2024
LLM Knowledge Distillation for Text Classification
This paper introduces Performance-Guided Knowledge Distillation (PGKD), a cost-effective and high throughput solution for production text classification applications.
PGKD utilizes teacher-student Knowledge Distillation to distill the knowledge of LLMs into smaller, task-specific models.
Results reveal that models finetuned with PGKD are up to 130X faster and 25X less expensive than LLMs for inference on the same classification task.
PGKD is a versatile framework can be extended to any LLM distillation task, including language generation.
Paper - arxiv.org/abs/2411.05281
#llms #distillation #nlproc #textclassification #deeplearning

2
17
1,016

9 Oct 2024
Big Distilabel release! Distilabel is an open source framework for creating synthetic datasets and generating AI feedback, designed to provide fast, reliable, and scalable pipelines based on verified research papers for engineers! 👀
And just got its 1.4 release with:
🧩 New Steps for better dataset sampling, deduplication (embeddings and minhash), truncation of inputs and better combining outputs
💰 50% Cost Savings by pausing pipelines and using OpenAI Batch API
⚡️ Caching for step outputs for maximum reusability—even if the pipeline changes.
📝 Steps can now generate and save artifacts, automatically uploaded to the Hugging Face Hub.
🆕 New Tasks with CLAIR, APIGen, URIAL, TextClassification, TextClustering, and an updated TextGeneration task.
1
14
69
4,325

17 Sep 2024
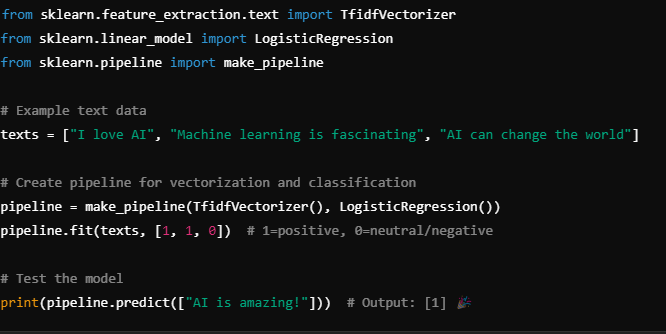
💡 Working on a Text Classification app using machine learning! Here’s a simple pipeline using scikit-learn to classify text data:
Anyone working on NLP or text classification projects? Let’s exchange ideas! 🚀
#MachineLearning #AI #NLP #TextClassification #AICommunity
3
112
17 Sep 2024
"When you finally fix the bug and the model accuracy goes from 65% to 99%:"
#MachineLearning #AI #NLP #TextClassification #AICommunity
1
75

29 Aug 2024
Check out the latest blog post on an optimized text classification algorithm based on graph neural networks. Learn how this approach enhances accuracy and efficiency in natural language processing. Read the full paper at: bit.ly/471w8KV #textclassification #GNN #NLP
3
88
23 Aug 2024
Combining PLMs and LLMs for Text Classification
The study compares three first-generation transformers (BERT, RoBERTa, BART) with two open Large Language Models (Llama 2, Bloom) across 11 sentiment analysis datasets.
Issue with Open LLMs
Open LLMs moderately outperform or match first-generation transformers in 8 out of 11 datasets, but only when fine-tuned, raising questions about their cost-effectiveness in practical applications.
Proposed Strategy
A confidence-based approach is introduced, integrating first-generation transformers with open LLMs based on prediction certainty, balancing performance and cost-effectiveness.
Experimental Findings
The proposed solution outperforms first-generation transformers, zero-shot, and few-shot LLMs, while competing closely with fine-tuned LLMs at a significantly lower cost.
#llms #generativeai #textclassification

1
3
457

18 Jul 2024
Can TensorFlow classify my texts into categories like "texts that make me smile" and "texts that make me roll my eyes"?
Source: devhubby.com/thread/how-to-d…
#TextClassification #TechTuesday #Influencer #Tech
1
6
21

30 May 2024
5/: This dataset is ready for use in various Natural Language Processing tasks, including text classification and regression, offering a valuable resource for future studies. 🛠️🔍 #NLP #TextClassification
1
1
20

3 Apr 2024
I'll explain myself :)
In older versions of Argilla we make the distinction between TextClassification, TokenClassification, etc
but now we have the Feedback dataset which integrate all the functionality of the old datasets. You can create a Feedback dataset with as many questions as you like: text question, label selection question, ranking question, etc.
docs.argilla.io/en/latest/ge…
The label selection question of the new Feedback dataset doesn't have the feature of sorting labels based on a score yet, but it will have it.
2
42

29 Mar 2024
arxiv.org/ftp/arxiv/papers/2…
Evaluating Large Language Models for Health-Related Text Classification Tasks with Public Social Media Data
#NLProc #textclassification #socialmedia #gpt4 #LLM
2
12
881

11 Mar 2024
What’s the best way to use large language models (#LLMs) for #textclassification? Find out in the wrap-up of our blog series! Learn about supervised vs. unsupervised learning methods (and whether or not you can just use #ChatGPT). bit.ly/3IyFfaq
#AI #MachineLearning
4
101

6 Mar 2024
Learn how to automatically organize, structure, and categorize large amounts of data in minutes, TODAY, for free using Appsmith AI.
#ai #artificialintelligence #artificialintelligenceforbusiness #enterprise #classifytext #textclassification
youtu.be/5_ymWlE2LjY
3
171