
Spent weeks struggling to train an image classification model due to computational constraints. Opened the notebook today and realized the culprit was a dataaugmentation Sequential layer. Moved augmentation into the dataset mapping function,and training went from hours to minutes
2
2
11

19/25 𝗕𝗼𝗼𝘀𝘁𝗶𝗻𝗴 𝗕𝗿𝗮𝗶𝗻-𝘁𝗼-𝗜𝗺𝗮𝗴𝗲 𝗗𝗲𝗰𝗼𝗱𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗧𝗥𝗜𝗕𝗘 𝘃𝟐 𝗗𝗮𝘁𝗮 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻
This paper addresses the challenge of low-data regimes in brain decoding by augmenting small fMRI datasets with synthetic data generated by TRIBE v2, a large encoding model pretrained on over 1000 hours of fMRI responses. Evaluated on the 7T fMRI Natural Scenes Dataset and 3T fMRI BOLD5000, this approach achieves up to 68% improvement in Top-10 image-retrieval accuracy. Notably, image decoders trained exclusively on synthetic fMRI can perform above chance, suggesting the potential for zero-shot brain-to-image decoding and significantly improving data efficiency.
#BrainDecoding #fMRI #SyntheticData #DataAugmentation #NeuroscienceAI #ZeroShotDecoding #TRIBEv2
Paper Link: arxiv.org/abs/2606.06345


1
1
16

May 14
#highlycited paper
📚CycleGAN with Atrous Spatial Pyramid Pooling and Attention-Enhanced MobileNetV4 for Tomato #DiseaseRecognition Under Limited Training Data
🔗mdpi.com/2076-3417/15/19/107…
👨🔬by Yueming Jiang et al.
🏫Northeast Forestry University
#tomatoleaf #dataaugmentation

2
4
56

Apr 15
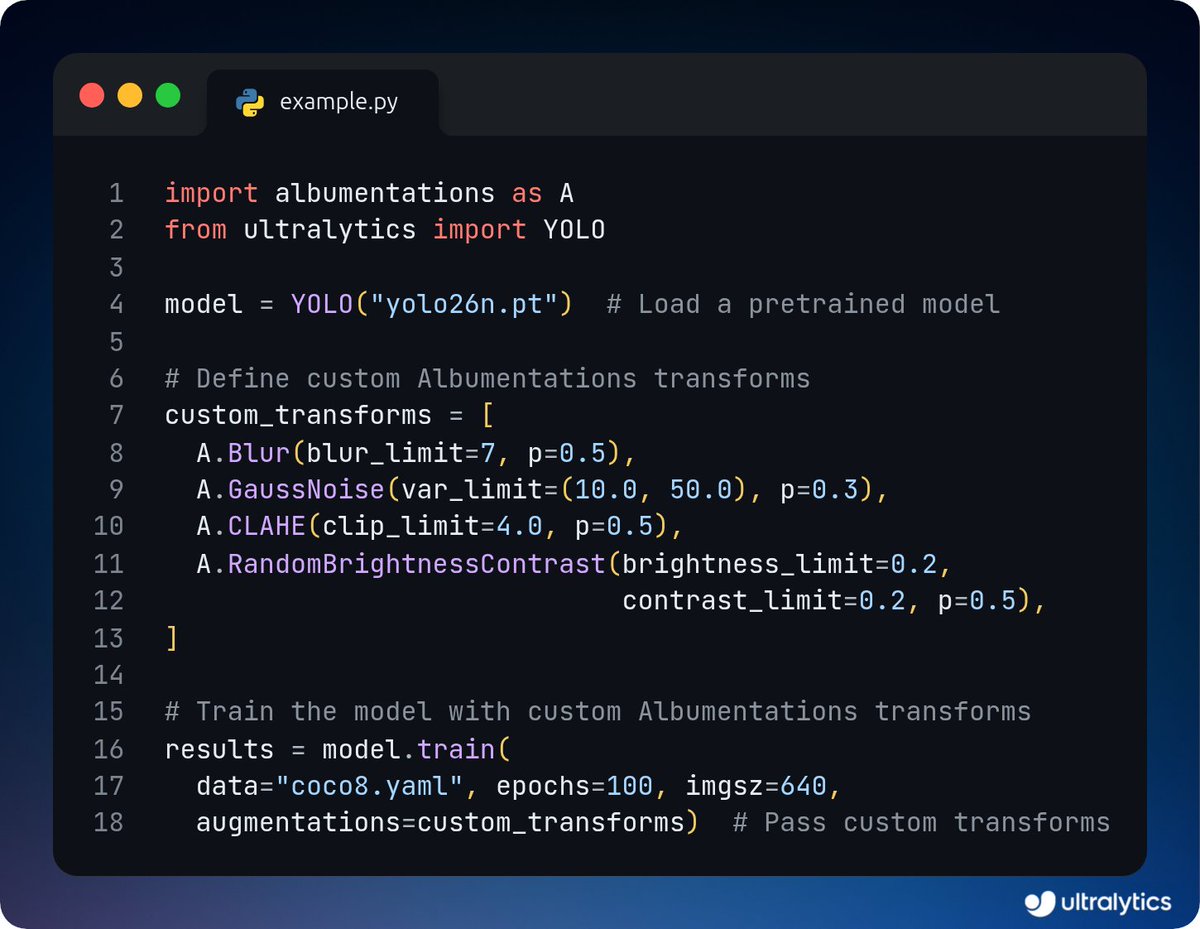
Train Ultralytics YOLO26 model with Albumentations! 🧠
Apply advanced augmentations like blur, rotations, and color shifts during training to improve model robustness and boost performance across diverse real-world scenarios.
Learn more ➡️ bit.ly/3M4xZYO
#Ultralytics #YOLO26 #AI #MachineLearning #DataAugmentation
1
3
38
1,852
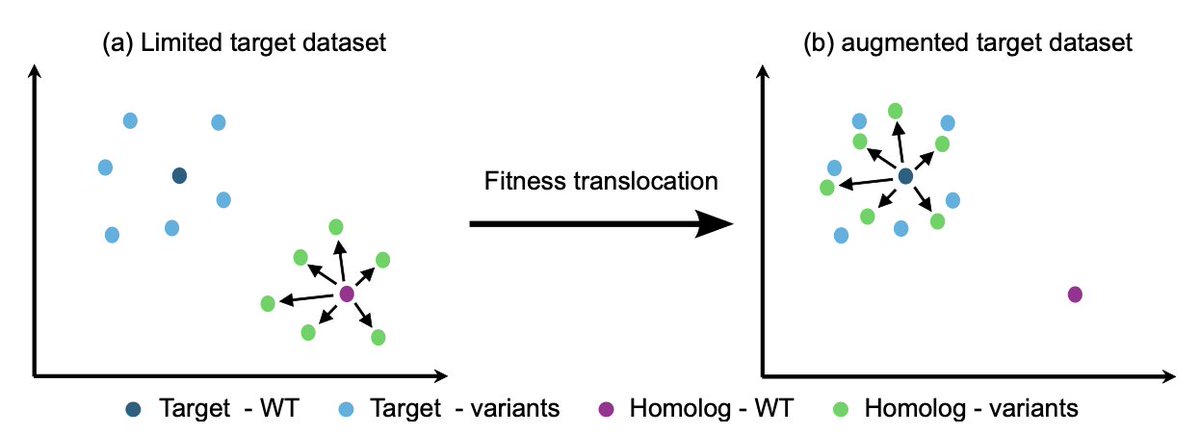
Fitness Translocation: Improving Variant Effect Prediction with Biologically-Grounded Data Augmentation
1. The study tackles the long‑standing bottleneck of sparse protein fitness data, which hampers accurate mapping from sequence to function in engineering and evolution.
2. It introduces *fitness translocation*, a data‑augmentation strategy that transfers the mutational effect observed in a homologous protein to a target protein, thereby enriching the target’s training set without new experiments.
3. Using pretrained protein language models, the method computes an embedding offset for each homolog variant (variant embedding minus wild‑type embedding) that captures the mutation’s directional change in latent space.
4. The offset is applied to the target wild‑type embedding, creating a synthetic variant that inherits the homolog’s measured fitness (normalized by wild‑type fitness), thus preserving biological relevance in the augmented data.
5. Because the technique operates solely in embedding space, it requires no sequence alignment and can be applied to homologs with as little as 35 % sequence identity, making it well suited for low‑data regimes.
6. The authors benchmarked fitness translocation on three diverse protein families—IGPS enzymes, green fluorescent proteins, and SARS‑CoV‑2 spike proteins—using multiple predictors (SVR, RF, Lasso) and language models (ESM‑2, ESM‑1v).
7. Across all configurations, augmentation consistently improved Spearman correlation, with the largest gains observed for SARS‑CoV‑2 spike cell‑entry predictions, followed by IGPS enzymatic activity and GFP fluorescence.
8. A homolog‑selection algorithm, grounded in one‑sided paired t‑tests, identifies which homologs yield statistically significant performance boosts, preventing the inclusion of noisy or irrelevant data.
9. Ablation studies show that removing either the statistical test or the sequential selection stage degrades results, underscoring the algorithm’s role in achieving robust improvements.
10. Principal‑component analysis demonstrates that translocation aggregates homolog variant embeddings around the target, indicating that mutational impacts are effectively transferred across sequence space.
11. The method’s success aligns with evidence that fitness landscapes are conserved across phylogenetically distant proteins, validating the biological assumption that evolutionary pressures preserve functional constraints.
12. By expanding usable training data, fitness translocation can accelerate directed evolution and generative protein design, potentially reducing the number of costly experimental cycles needed to reach high‑performance variants.
💻Code: github.com/adrienmialland/Pr…
📜Paper: biorxiv.org/content/10.1101/…
#ProteinEngineering #MachineLearning #ProteinLanguageModels #VariantEffectPrediction #DataAugmentation #DirectedEvolution #ComputationalBiology #SARSCoV2 #IGPS #GFP #Bioinformatics
3
13
1,574
Mar 18
📢 #highlycited paper
📚 Effect of #DataAugmentation Using #DeepLearning on #PredictiveModels for #GeopolymerCompressiveStrength
🔗 mdpi.com/2076-3417/14/9/3601
👨🔬 by Ho Anh Thu Nguyen et al.
🏫 Hanyang University
#geopolymerconcrete #machinelearning

1
2
38

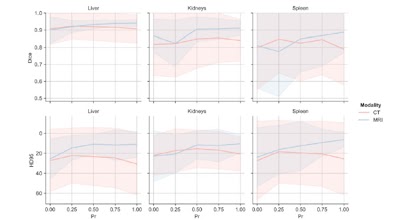
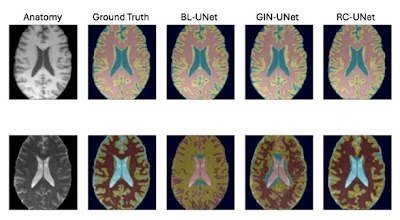
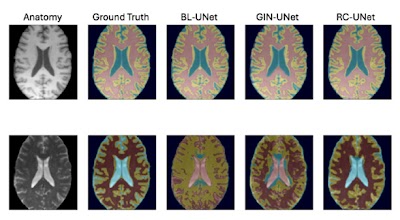
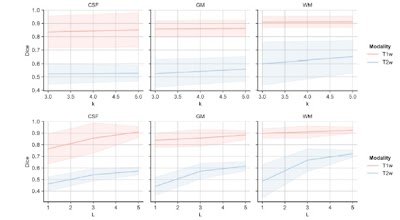
Random convolutions serve as a data augmentation strategy for deep learning-based medical image segmentation models doi.org/10.1148/ryai.240502 @TU_Muenchen #DeepLearning #DataAugmentation #ML
1
4
219
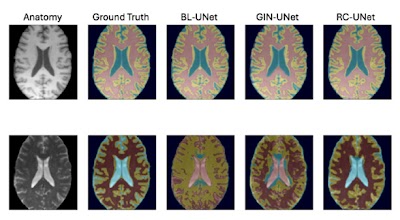
Domain generalization of medical image segmentation models with random convolutions doi.org/10.1148/ryai.240502 @TU_Muenchen #DeepLearning #DataAugmentation #ML
1
146
Domain generalization of medical image segmentation models with random convolutions doi.org/10.1148/ryai.240502 @TU_Muenchen #DataAugmentation #AI #ML
1
3
233
Domain generalization of medical image segmentation models with random convolutions doi.org/10.1148/ryai.240502 @TU_Muenchen #DataAugmentation #AI #MachineLearning
1
2
220
Random Convolutions for Domain Generalization of Deep Learning-based Medical Image Segmentation Models doi.org/10.1148/ryai.240502 @TU_Muenchen #segmentation #DataAugmentation #AI
2
202

💥Excited for the publication: "Deep Temporal Clustering of Pathological Gait Recovery Patterns in Post-Stroke Patients Using Joint-Angle Trajectories: A Longitudinal Study"
🔗 shorturl.at/TYBiY
📌#stroke #rehabilitation #gaitanalysis #jointangletrajectory #dataaugmentation
7
111

30 Dec 2025
Learn more about Synthetica: from messy clinical images to ML-pipeline-ready data — in one click. #Synthetica #MedicalAI #MedicalImaging #ComputerVision #MachineLearning #SyntheticData #DataCleaning #DataAugmentation
youtu.be/EOZ3UJCBC60

1
1
2
213

11 Dec 2025
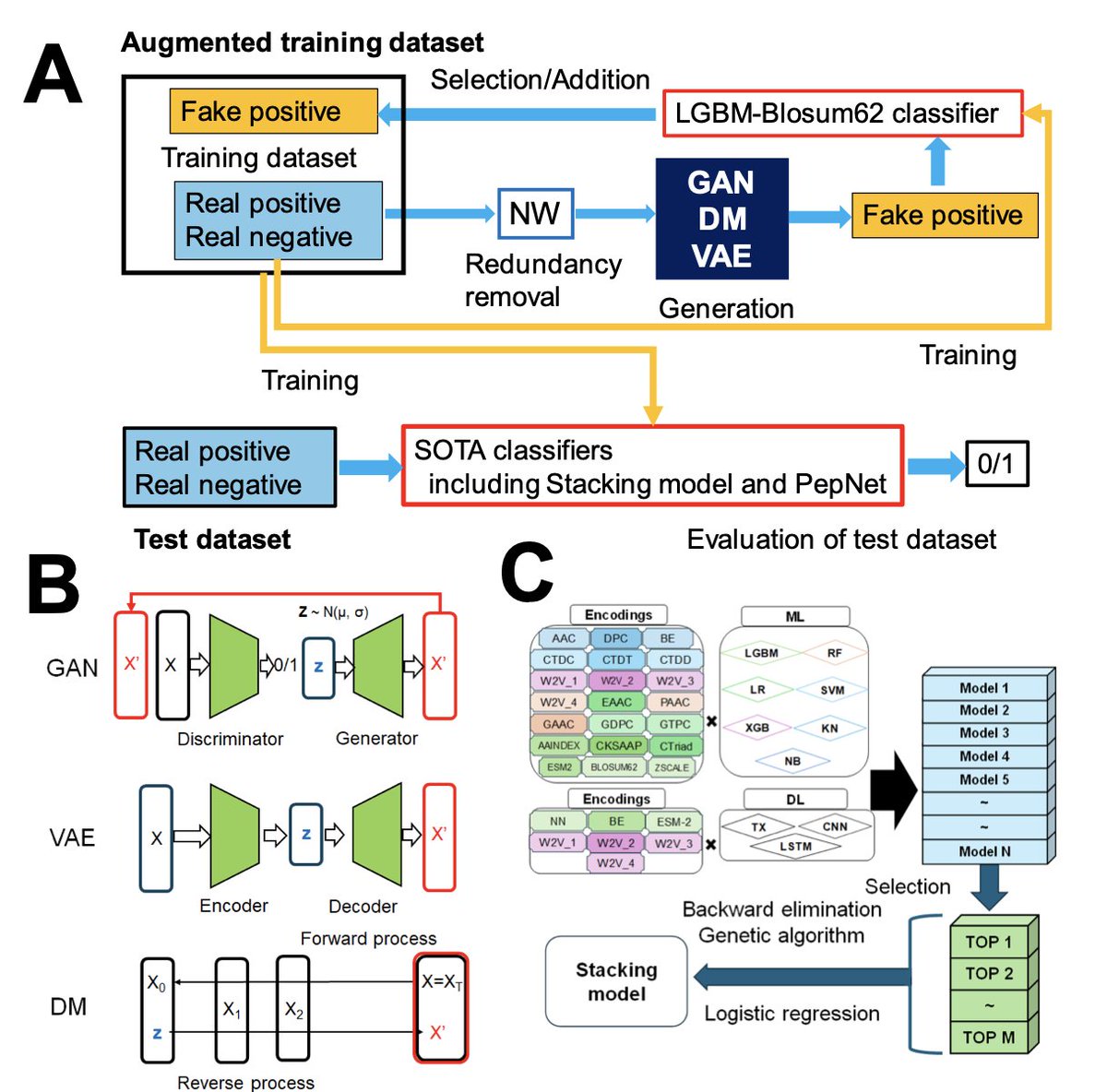
GDA-Pred: Generative AI-Driven Data Augmentation for Improved Prediction of IL-6 and IL-13 Inducing Peptides
1. This study introduces GDA-Pred, a novel framework leveraging Generative AI to enhance the prediction of peptides that induce IL-6 and IL-13, crucial for drug discovery in cancer, immune disorders, and infectious diseases. The approach addresses the challenge of limited experimental data by augmenting training datasets with AI-generated peptide sequences.
2. The GDA framework utilizes three types of generative models—GANs, diffusion models, and VAEs—to expand the sequence space of functional peptides. The study demonstrates that GANs outperform the other models in generating realistic and diverse peptide sequences, significantly improving prediction accuracy.
3. A key innovation lies in the optimization of GDA parameters using a moderately sized dataset of anti-inflammatory peptides (AIPs). This case study approach allowed researchers to derive interpretable settings for parameters such as sequence identity cutoff, probability threshold, and augmentation ratio, which are critical for effective data augmentation.
4. The effectiveness of GDA-Pred was validated through stratified 5-fold cross-validation with cluster-based partitioning, ensuring robust generalizability. The results showed substantial improvements in prediction performance for both IL-6 and IL-13 inducing peptides, outperforming conventional data augmentation methods like SMOTE and KDE.
5. The study highlights the potential of GDA to fill gaps in peptide sequence distribution, smoothing decision boundaries and enhancing model generalization. This approach is particularly beneficial for small or moderate-sized datasets, where traditional methods often fail to capture diverse sequence patterns.
6. The integration of GDA into state-of-the-art classifiers, such as PredIL6 and PredIL13, further enhanced their predictive capabilities. The findings suggest that GDA-Pred could be a valuable tool for accelerating the discovery of functional peptides in various biomedical applications.
📜Paper: biorxiv.org/content/10.64898…
#GenerativeAI #DataAugmentation #PeptidePrediction #Bioinformatics #DrugDiscovery #MachineLearning
1
1
8
984

8 Dec 2025
TaxaPLN: a taxonomy-aware augmentation strategy for microbiome-trait classification including metadata. #Microbiome #DataAugmentation #GenerativeModel #BMCbioinformatics
link.springer.com/article/10…
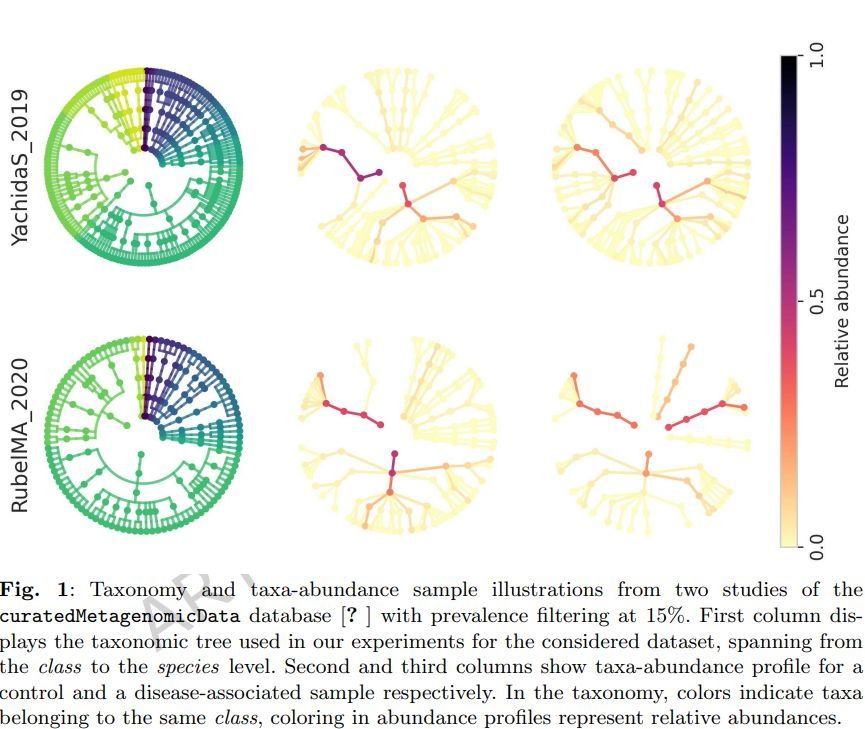
2
5
19
902
1 Dec 2025
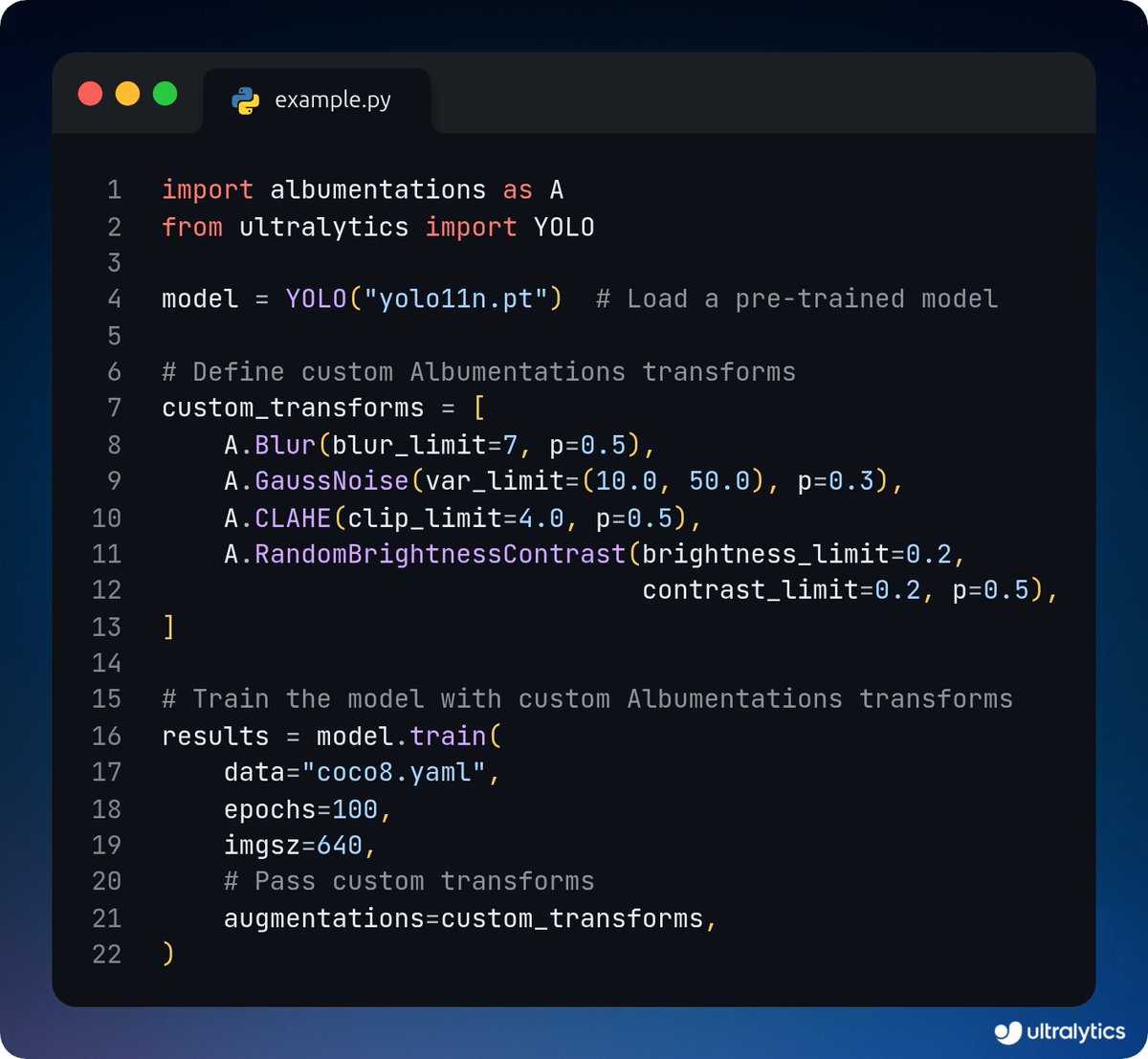
Train Ultralytics YOLO11 with Albumentations transforms!
Boost your model’s performance using advanced augmentations like blurs, rotations, and more, all seamlessly integrated into the Ultralytics training pipeline.
Learn more ➡️ bit.ly/3M4xZYO
#DataAugmentation #AI
2
1
12
700
11 Nov 2025
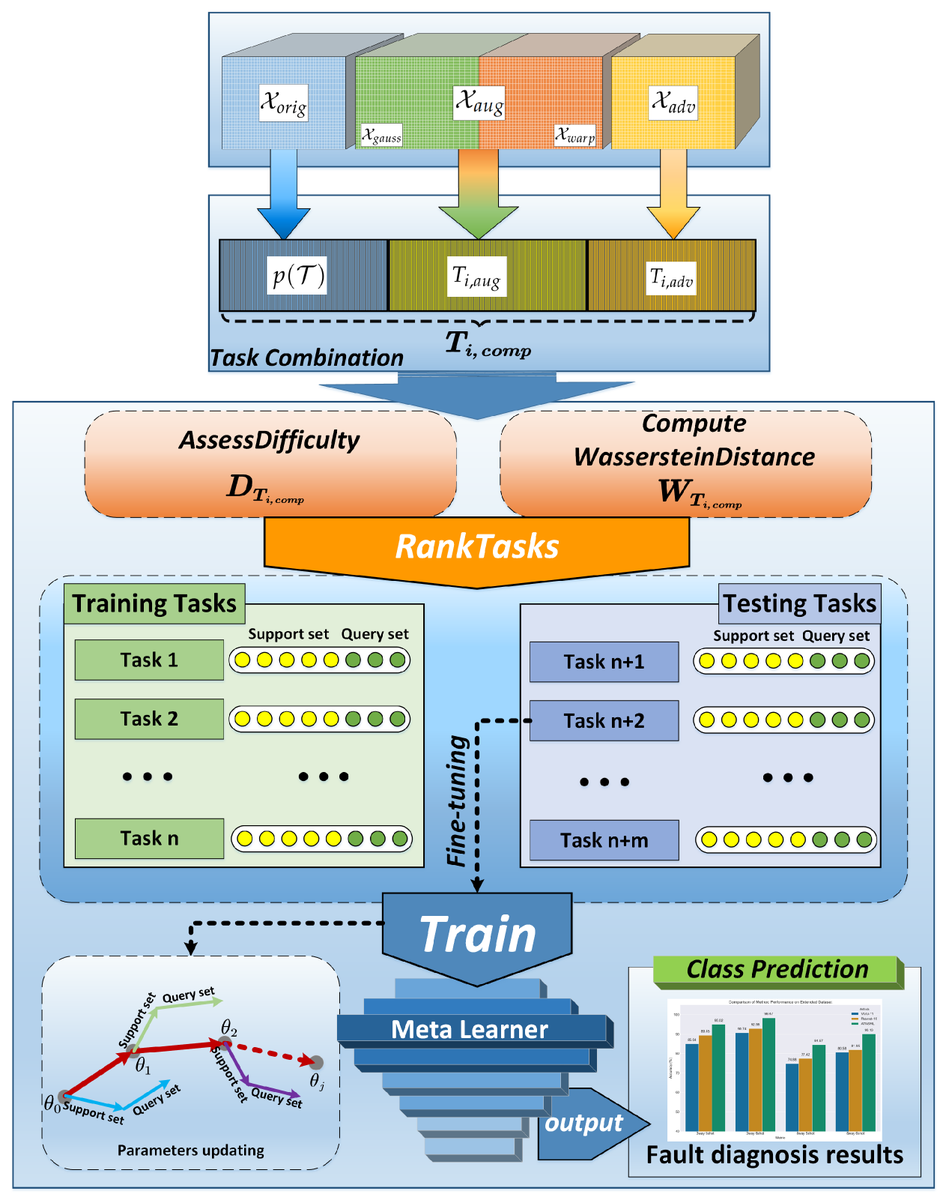
📚 Enhancing #FaultDiagnosis in #IndustrialProcesses through Adversarial Task Augmented Sequential #MetaLearning
🔗 mdpi.com/2076-3417/14/11/443…
👨🔬 by Dexin Sun et al.
🏫 Dalian Maritime University / @CAS__Science / Key Laboratory of Technology and System for Intelligent Ships of Liaoning Province
#adversarialtraining #dataaugmentation #anomalydetection
2
1,202
7 Nov 2025
📢 #highlycited paper
📚 #SAITI-#DCGAN: #Self_Attention Based #DeepConvolutionalGenerative Adversarial Networks for #DataAugmentation of #InfraredThermalImages
🔗 mdpi.com/2076-3417/14/23/113…
👨🔬 by Zhichao Wu et al.
🏫 @UniversityHohai/@cardiffuni
#aluminumfoilsealing #GAN

2
43
1 Oct 2025
SoDaDE: Solvent Data-Driven Embeddings with Small Transformer Models
1. A new solvent representation scheme, SoDaDE, has been proposed to address the limitations of existing solvent representations in chemistry. This scheme leverages a small transformer model and a solvent property dataset to create more accurate and specific solvent fingerprints, which is crucial for green solvent replacement research.
2. The SoDaDE model outperforms previous representations on the Catechol Benchmark, a recently published dataset for solvent selection. This benchmark highlights the need for better solvent representations due to the significant impact of solvents on reaction outcomes. SoDaDE’s success demonstrates its potential for improving solvent modeling.
3. The study uses a small but suitable solvent property dataset, the Spange dataset, which contains detailed molecular properties of 191 solvents. By pre-training the transformer model on this dataset through data augmentation, SoDaDE learns to predict solvent properties effectively, even with missing values in the dataset.
4. The method involves creating 'solvent sequences' by shuffling property-value pairs, generating a large number of unique data points from a small dataset. This innovative data augmentation technique helps the model learn robust representations. The model uses masking tokens to cover random solvent properties, ensuring it focuses on relevant preceding values.
5. The SoDaDE model architecture includes a dimension size of 64, 16 attention heads, 5 layers, and a hidden dimension of 4×64. It employs a learning rate scheduler and achieves a normalized MSE of 0.107 on the validation set. The model’s performance on solvent property prediction is significantly better than traditional methods like Gaussian processes and random forests.
6. In the Catechol Benchmark, SoDaDE shows stronger performance in predicting reaction outcomes with multiple solvent mixtures compared to single solvents. This suggests that the model captures the interactions between solvents effectively, which is a significant improvement over previous methods.
7. The study concludes that SoDaDE creates an effective solvent fingerprint that is not dependent on fine-tuning. This demonstrates that meaningful representations can be learned from small datasets, inviting further exploration of similar methods in other chemical domains.
📜Paper: arxiv.org/abs/2509.22302
#MachineLearning #Chemistry #SolventRepresentation #TransformerModels #GreenChemistry #DataAugmentation

3
13
1,473
28 Sep 2025
🔥 Read our Paper
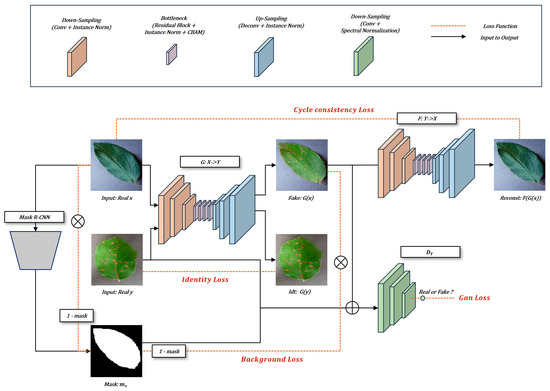
📚#DataAugmentation Method for Plant Leaf Disease #Recognition
🔗mdpi.com/2076-3417/13/3/1465
👨🔬by Byeongjun Min et al.
🏫Sejong University
#plantdiseaserecognition #dataaugmentation
1
5
78