
May 24
ConTact: Contact-First Antibody CDR Design via Explicit Interface Reasoning
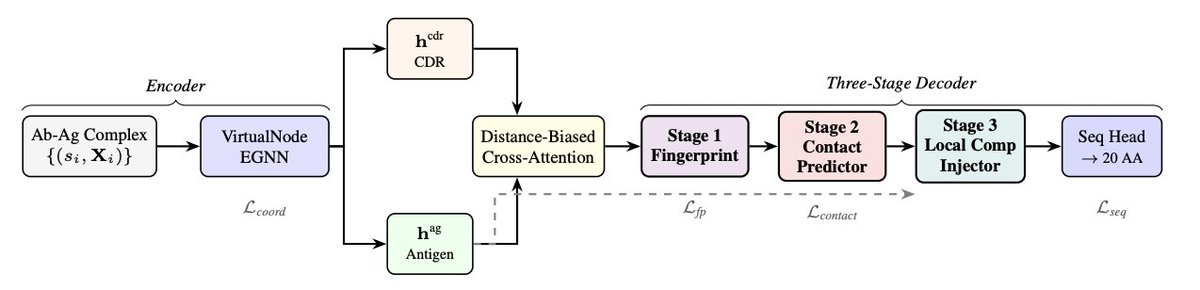
1. CONTACT reframes antigen-conditioned antibody CDR design as two distinct problems that should not be conflated: (a) deciding which CDR positions will actually contact the antigen (the “where”), and (b) choosing amino acids at those positions (the “what”). The paper argues current models often underuse antigen information because they try to solve both implicitly with uniform message passing and uniform sequence loss.
2. The core architectural idea is a contact-then-act, three-stage cascade for CDR-H3: Stage 1 learns per-position “surface complementarity fingerprints”; Stage 2 explicitly predicts which CDR residues contact the antigen (supervised); Stage 3 injects antigen features into the sequence head only where contacts are predicted, so antigen signal is routed preferentially to binding-critical positions.
3. Stage 1 (Complementarity fingerprinting) produces a compact vector per CDR position summarizing the local binding environment, inspired by molecular surface fingerprints. It is trained with an InfoNCE-style contrastive objective so positions facing similar antigen environments have similar fingerprints, improving downstream contact prediction.
4. Stage 2 (Contact prediction) uses a supervised contact label defined by a Cα–Cα threshold of 8 Å. The predictor combines CDR embeddings, KNN-aggregated antigen features, minimum-distance encodings, and the Stage 1 fingerprint. A focal binary cross-entropy loss addresses contact/non-contact imbalance and focuses learning on ambiguous boundary cases.
5. Stage 3 (Contact-guided injection) performs “double gating” to control antigen-conditioning strength at each CDR position: a learned gate multiplied by the predicted contact probability. This aims to prevent distant/noisy antigen residues from influencing non-contact positions, while still allowing fine-grained modulation at predicted contact sites.
6. The model also adds a distance-biased cross-attention module: standard cross-attention scores are augmented with a Gaussian bias based on predicted Cα distances, encoding a geometric prior that spatial neighbors should matter more for binding than far-away residues.
7. On the encoder side, CONTACT uses a heterogeneous VirtualNode-EGNN with virtual nodes connecting to all epitope residues and all CDR residues, creating a two-hop shortcut for epitope-to-CDR information flow and mitigating over-squashing that can occur when signals must traverse long chains of message passing steps.
8. Training uses a multi-term objective centered on sequence loss plus explicit contact loss and fingerprint loss, along with coordinate, pairing (CDR–antigen matching), docking (encouraging proximity to the epitope), and auxiliary regularization terms. A key detail is contact-weighted cross-entropy for sequence prediction: positions with higher predicted contact probability receive larger weights, concentrating gradient on binding-relevant residues.
9. Results on CHIMERA-BENCH (2,922 complexes; epitope-group split) show CONTACT leading on structural and interface awareness metrics among 11 retrained baselines: RMSD 1.63 Å (7% better than next-best), epitope F1 0.79 (10% over GNN baselines), fnat 0.67, DockQ 0.73, and competitive sequence recovery AAR 0.38. The paper highlights that CAAR remains low (0.20) across methods, suggesting a remaining bottleneck: Cα-level antigen representations may not capture enough chemistry (side chains/electrostatics) to nail residue identity at contacts.
📜Paper: arxiv.org/abs/2605.21600
#ComputationalBiology #AntibodyDesign #ProteinDesign #GeometricDeepLearning #GNN #EquivariantNetworks #StructuralBiology #MachineLearning
3
12
1,800
May 24
AgForce Enables Antigen-conditioned Generative Antibody Design
1 Existing antigen-conditioned antibody design models often fail to actually use the antigen: across 11 CDR-H3 design methods on CHIMERA-BENCH, predictions at antigen-contacting positions recover worse than non-contacting positions, and an antigen-free baseline can achieve the strongest binding metrics—evidence of “antigen blindness.”
2 The paper identifies three causally linked failure modes behind this: antigen blindness (CDRs barely change across targets), vocabulary collapse (GNN greedy decoding predicts only ~3–5 amino acids per position vs native EV ~15.5), and a “cross-entropy ceiling” showing per-position cross-entropy optimizes to the positional marginal distribution, making antigen-specific predictions provably unattainable under the standard objective.
3 AGFORCE is proposed as an encoder-decoder co-design model that directly targets these failure modes rather than only changing the encoder: a VirtualNode-EGNN encoder (E(3)-equivariant) plus specialized conditioning and decoding mechanisms intended to block shortcut learning from the antibody framework.
4 To prevent the framework shortcut path (a key driver of antigen blindness), AGFORCE introduces framework dropout (randomly zeroing heavy-chain framework embeddings during training), plus gated bottlenecks and hyperbolic cross-attention between CDR and epitope embeddings to better transmit antigen information.
5 To break the cross-entropy ceiling and reduce vocabulary collapse, AGFORCE replaces the standard linear amino-acid head with an MDN-Potts sequence decoder: a mixture density network with K=4 components, augmented by Potts-like pairwise couplings between adjacent positions and decoded with belief propagation, enabling multi-modal sequence distributions beyond a single positional marginal.
6 Training uses annealed Multiple Choice Learning (aMCL): mixture components receive Boltzmann-weighted responsibility that anneals toward sharper assignments, encouraging component specialization; the paper argues this changes the optimal solution so components can deviate from the global positional marginal (i.e., can become antigen-conditional).
7 Diversity is explicitly regularized with a GDPP spectral loss to better match native distributional diversity (effective vocabulary and motif variety), addressing the observed collapse where rare but important residues (e.g., W/C/M) are nearly never predicted by greedy GNN baselines.
8 Antigen conditioning is further enforced with an antigen cycle-consistency style objective: an InfoNCE antigen classification loss computed from the predicted CDR probability distributions (a differentiable “soft sequence” embedding) against antigen embeddings, ensuring gradients flow through the sequence decoder and forcing predicted distributions to encode antigen identity.
9 On CHIMERA-BENCH (epitope-group split; 292 test complexes), AGFORCE reports improved sequence recovery and binding quality simultaneously: AAR 0.40 (vs 0.37 for strongest GNN baselines), lowest perplexity (2.95), and best interface metrics (fnat 0.67, iRMSD 1.30 Å, DockQ 0.74, epitope F1 0.77). It also increases antigen-specific diversity (95.5% unique sequences) and raises effective vocabulary to 9.4 (vs 3.0–5.5 for greedy GNN methods), though still below native diversity.
💻Code: github.com/mansoor181/ag-for…
📜Paper: arxiv.org/abs/2605.21610
#ComputationalBiology #ProteinDesign #AntibodyDesign #GenerativeModels #GraphNeuralNetworks #MachineLearning #Bioinformatics #StructuralBiology

5
22
1,914

29 Jun 2024
調べてみたら、だいぶ前にVNode(VirtualNode)は勉強していました。
これがあるからこそのリアクティブという感じだったはず。
3
46


7 Aug 2020
Count me in for Azure related talk. AKS Event driven Autoscaling using KEDA is one of my fav topic. I can add a flavour of #serverless to that with #VirtualNode & #ACI
1
1
2
20 Jul 2020
Integrate Private Container Registry with Kubernetes with 𝑽𝒊𝒓𝒕𝒖𝒂𝒍 𝑵𝒐𝒅𝒆 to run workloads on #Serverless ACI containers.
Use 𝐈𝐦𝐚𝐠𝐞 𝐏𝐮𝐥𝐥 𝐒𝐞𝐜𝐫𝐞𝐭 to securely pull private images
📺📺👇👇youtu.be/bwFifZlQKLs
#AKS #ACR #VirtualNode #dotnetcore

6
3
15 Jul 2020
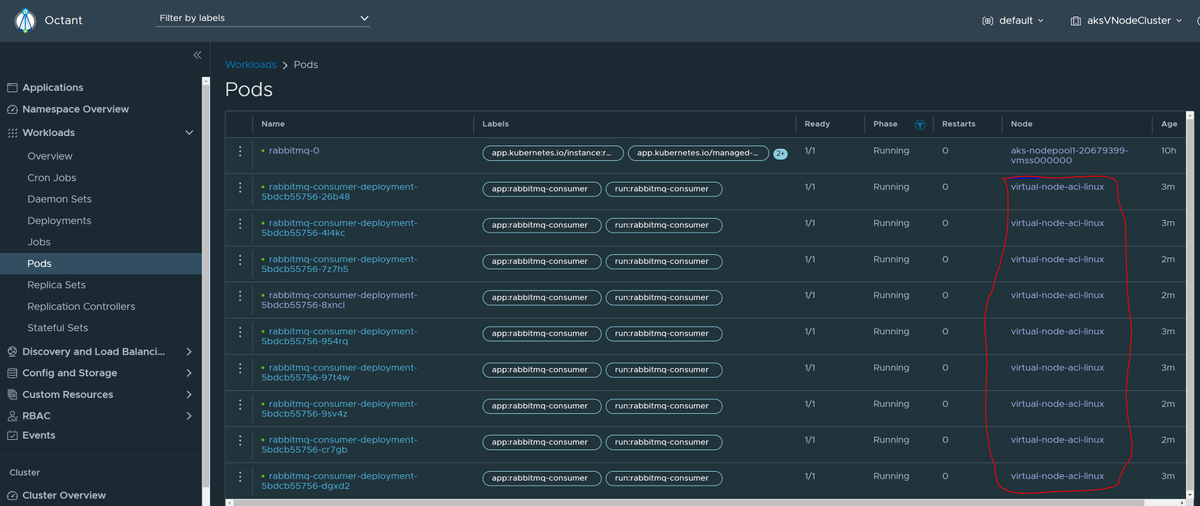
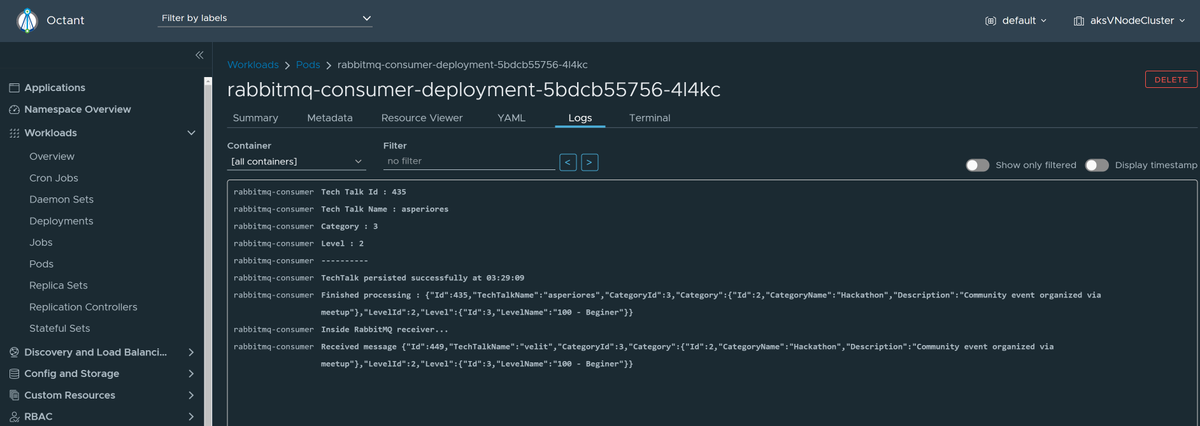
Recent version of @projectoctant has added an enhancement to show the logs from pods running on Azure Container Instances using Virtual Node. 👏👏
youtu.be/pIjIL6Vx4LE
#octant #aci #virtualnode #kuberentes #aks
2
7

26 Jun 2020
I've updated my CloudFormation snippets extension for vscode to version: 2.14.0: The following resources were updated: AWS::AppMesh::VirtualNode and A… - ift.tt/2Vofth0 #AWS #VScode #CloudFormation #Releasenotes
1
2
12 May 2020
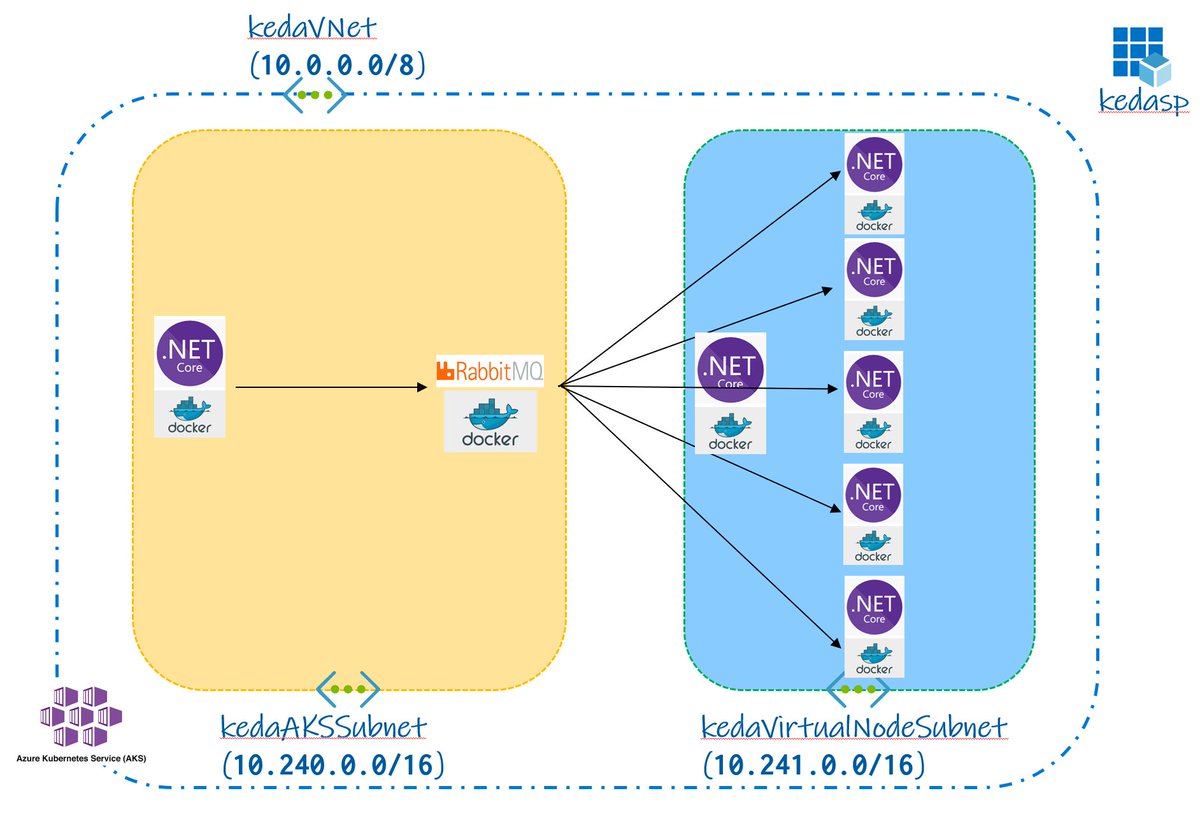
What do you need to scale containers in #Serverless environment on Kubernetes?
Virtual nodes, Node selector, Taints & Tolerations
youtu.be/yLzNcuD3boM
#Azure #AKS #k8s #VirtualNode

3
5

11 Sep 2019
Slowly filling up for #prognet keynote with @TessFerrandez
I'm on after the keynote in Room ALT/TAB with #Kubernetes #virtualnode stuff

1
9
14 Aug 2019
ACI all the way, if I chose K8s I'd want to use #virtualnode so I don't have to have provisioned capacity in my cluster for something that is unpredictable (therefore almost the same thing as ACI anyway)
5

14 Jun 2019
Also a nice update for Cloud Map service discovery plus metadata for App Mesh in AWS::AppMesh::VirtualNode, along with other useful neat stuff here for our customers!
14 Jun 2019

#AWS #CloudFormation for Secrets, GPU, and Tagging in Amazon #ECS is now live! This will help lots of customers who use CloudFormation for automation. docs.aws.amazon.com/AWSCloud…
2

3 Jun 2019
2
15 May 2019
Break time before I'm on at #microcph
Will be covering #Kubernetes, #AzureDevSpaces, #virtualnode and more

1
7
8 May 2019
Room 1 for the #Kubernetes double bill starting right after lunch at 13.40 #ndcminnesota
First talk will focus on basics with some #aks examples. Second talk immediately after (20mins break) will dive into scheduling, #virtualnode and a bit on #servicemesh
2

31 Mar 2019
my talk on #virtualnode #kubernetes #k8sday youtube.com/watch?v=yR68PX23… Thanks to @LachlanEvenson @rbitia for helping with the demo.
1
9

20 Mar 2019
@scottcoulton explaining #virtualnode and #virtualkubelet @melbkubernetes @NAB with @MicrosoftAUDev sponsoring.




2
5
19 Mar 2019
Come along tonight the Kubernetes Melbourne meetup talking about #virtualnode #virtualkubelet hosted by @NAB and sponsored by @MicrosoftAUDev @scottcoulton #Kubernetes
18 Mar 2019

Come join us for the march edition of #Melbourne #Kubernetes meetup on the 20th of March where @scottcoulton, Cloud Dev Advocate @Microsoft @Azure will talk about @virtualkubelet and #virtual nodes with some live demos.
RSVP: meetup.com/en-AU/Melbourne-K…
5
14
13 Mar 2019
Check out this Meetup: Melbourne Kubernetes User Group March 20th @scottcoulton talking about Virtual Kubelet & Virtual Node meetup.com/Melbourne-Kuberne… … #kubernetes #virtualnode #virtualkubelet
5
11
1 Mar 2019
Thank you to everyone who came to my #ndcporto talk on #Kubernetes, #virtualkublet / #virtualnode
I'll post the slides later
1
1
6