
Jun 7
Do Vision-Language Models (VLMs) actually "see" everything in a crowded room? 🔍
Today at #CVPR2026, we are presenting VisualOverload, our work exploring the critical visual perception bottlenecks of VLMs in dense scenes.
If you're attending, I’d love to connect, share insights, and hear your thoughts!
📅 Today (Poster Session 6)
⏰ 5:30 PM - 7:30 PM
📍 Poster 431 (ExHall A)
🌎 paulgavrikov.github.io/visua…
Joint work with @WeiLinCV, @jmie_mirza, @soumyasj2222, @huzaifa2k50, @SivanDoveh, @yeung_levy, James Glass, @HildeKuehne.

1
4
35
2,696

Jun 7
Presenting today @CVPR Poster 431 3:30 - 5:30:
VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes
paulgavrikov.github.io/visua…
How good are current MLLMs in understanding dense visual scenes?
We tested 37 state-of-the-art models on a new benchmark designed to answer this question.
Introducing VisualOverload👇
Most VQA benchmarks evaluate relatively coarse or global image understanding.
But real-world scenes can be crowded, cluttered, and packed with details.
Can VLMs still answer simple visual questions when the scene becomes visually overloaded?
To find out, we built VisualOverload:
🖼️ High-resolution scans of public-domain paintings
👥 Many interacting people
🎭 Multiple actions and subplots
🏰 Rich, detailed backgrounds
We manually annotated 2,720 QA pairs across six task categories.
Importantly, the tasks require:
✅ No external knowledge
✅ No specialized expertise
Just careful visual understanding.
We evaluated 37 leading models, including proprietary and open-source systems.
Even the best-performing model, o3, achieved:
📉 69.5% overall accuracy
📉 Only 19.6% on our hardest split
Far below what many existing benchmarks might suggest.
Why do models fail?
Our error analysis reveals several recurring failure modes:
🔢 Counting mistakes
📝 OCR failures
🤔 Logical inconsistencies
👀 Missing important scene details
The takeaway:
Current VLMs can appear highly capable on existing benchmarks, yet struggle with surprisingly simple questions when visual complexity increases.
Basic visual understanding is still far from solved.
We hope VisualOverload becomes a useful resource for developing the next generation of vision-language models that can truly reason about rich, detailed visual worlds.
If you're interested in:
👁️ Visual Understanding
📊 Benchmarking
🤖 VLM Evaluation
🔍 Failure Analysis
come visit our poster. We'd love to discuss!
@PaulGavrikov @WeiLinCV @jmie_mirza , @soumyasj2222 , @SivanDoveh @yeung_levy James Glass, @hildekuehne
@MIT_CSAIL @Stanford @MITIBMLab @uni_tue
#CVPR #ComputerVision #VLM #MultimodalAI #Benchmarking #ArtificialIntelligence

4
17
906

May 21
Someone said Korean actors are good looking. 👀
Then I looked at Chinese actors…
And realised — yes. You are absolutely, 100%, undeniably RIGHT. 😭🔥
Asia said 'we don't do average' and meant it. 🫡
#KoreanActors #ChineseActors #AsianDrama #Cdrama #Kdrama #TooGoodLooking #AsianMen #DramaObsessed #NotFair #VisualOverload
1
7
97

There are encounters we spend our entire youth just waiting to see come true.
I’ve been longing to see this trio of 'cool sisters' walk the Kazz Awards 2026 red carpet together. If it happens, it will be a historic moment for the GL fandom—seeing these visual icons in a single frame. It’s real: I couldn’t sleep all night from the excitement.
Is anyone else experiencing this 'Emotional shock' while waiting for this afternoon like I am? 🥺✨
.
#engfa #faye_malisorn #jayna #faye #engfawaraha #KazzAwards2026 #GirlsLove #GL #GLFandom
#GLLatam #BrasilLovesGL #MexicoLovesGL
#SoaiTy #VisualOverload #ThaiGL #TheHiddenMoon #RedCarpet #EngfaFaye
#lunarsecret #aangelinaass #ginj #ginnynatnicha #พระจันทร์ซ่อนเงา #gl #jayna #PoisonousLove #GinJ #ginny #ginjay #ginnyjayna #alkey #panda #Cat #MEW #funny #จินเจ #PoisonousLoveTheSeries #aangelinaas #ginnyspaca #Peru #Lima #Peruanos #Mexico
1
10
545

Apr 27
System Error: The attempt to hide Wonyoung's beauty has failed catastrophically. Perfection this absolute cannot be contained. Watch and succumb. 🚧💖✨
시스템 오류: 원영이의 미모를 가리려는 시도는 처참하게 실패했습니다. 이토록 절대적인 완벽함은 숨길 수 없습니다. 보고 굴복하세요. 🚧💖✨
システムエラー:ウォニョンの美しさを隠そうとする試みは無残に失敗しました。これほど絶対的な完璧さは隠せません。見て、屈服してください。🚧💖✨
系统错误:试图隐藏元英美貌的尝试彻底失败。如此绝对的完美是无法掩盖的。观看并屈服吧。🚧💖✨
Is it even possible to find a flaw? 👇
#JANGWONYOUNG #장원영 #ウォニョン #元英 #IVE #아이브 #アイヴ #WonyoungPerfection #VisualOverload

4
64
Apr 16
Great work @WuMinghao_nlp. Qwen3.6 is now the leader on our VisualOverload benchmark (CVPR 2026): paulgavrikov.github.io/visua…
8
651
Apr 16
Qwen3.6 nicely improves upon 3.5 and takes the lead on #VisualOverload
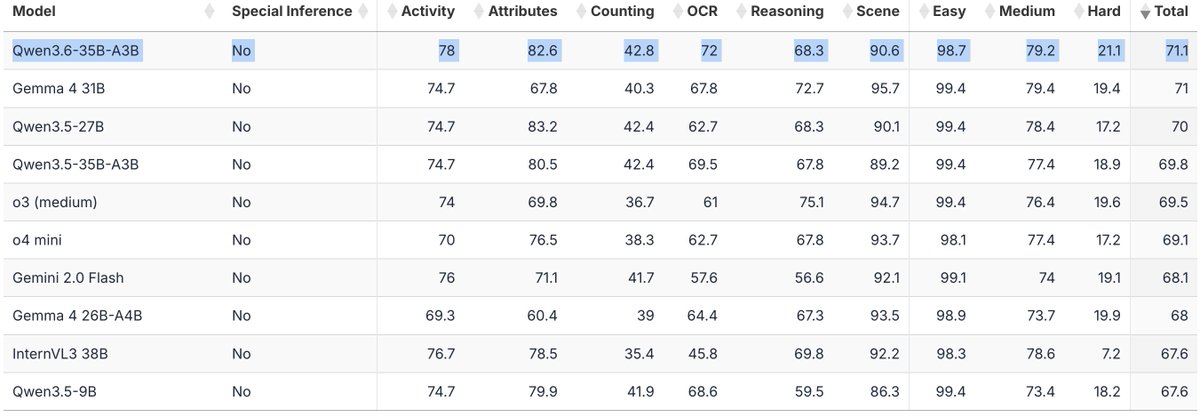
Apr 16

⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.6-35b-…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

4
238
Mar 24
Cool work. Can you try it on VisualOverload? Should be a good pressure test paulgavrikov.github.io/visua…
3
37
Feb 26
🚀4 Papers accepted to CVPR 2026!
Checkout:
VOLD: arxiv.org/abs/2510.23497
AMoE: arxiv.org/abs/2512.20157
VisualOverload: arxiv.org/abs/2509.25339
TTRV: arxiv.org/abs/2510.06783
Detailed posts follow soon!
Big congrats @BousselhamWalid Sofian Caybouti @PaulGavrikov @akshit_fbd
1
11
104
5,127

Explosion of Meaning
#ExplosionOfMeaning #nftart #MythicShock #SymbolicScream
#VisualOverload #CosmicWitness
#SurrealEmotion #HairOfChaos
#tezosart #iranianart #surrealism
#Scream

1
7
270

30 Oct 2025
"the effects look like when you eat a mushroom” and honestly, fair 😅 this game’s visuals are wild in the best way ✨
🎮 experience the madness on Steam now: store.steampowered.com/app/2…
#ParticleHearts #IndieGame #SteamGames #VisualOverload #GamingCommunity
3
358
1 Oct 2025
🚨 New paper out!
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700 VQA questions about dense scenes.
Findings: even top models like o3 fumble badly — <20% on the hardest split and key failure modes in counting, OCR & consistency.
Key findings in 🧵

1
3
14
3,299

If your #visualtimetable for #SEND students has:
- fancy detailed images
- joined up handwriting
- intricate boarders
- lots of colours
To make it look pretty, it’s not as useful as you think it is.
#visualperception #visualoverload #sensory #overwhelming #visualdiscrimination
1
3
141

8 Sep 2025
🚀 🚀 We are introducing VisualOverload🎨🖼️, a VQA benchmark designed to test fundamental vision skills in visually dense scenes. 2,720 Q&A pairs across 6 tasks, 150 high-res artworks, and private ground truth. Even top VLMs hit only ~20% on the hardest tasks. Try it yourself🤖👉
8 Sep 2025

Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.

3
226

8 Sep 2025
AGI might not be there (yet).
Try our latest VisualOverload benchmark, testing many fine-grained abilities of your state-of-the-art VLMs, identifying their failure modes, and opening many avenues for improvements.
8 Sep 2025
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
4
365
8 Sep 2025
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
2
4
10
1,541

27 May 2025
hope you like this chaotic cuteness
#colorfulart #visualoverload #ocart #japaneseartist #popartstyle

1
5
130

12 May 2025
A hyperreal, surrealistic portrait capturing the feeling of digital overload with a dreamy, holographic twist. Ideal for designers exploring identity, tech anxiety, or visual storytelling.
#digitalaesthetic #glitchart #visualoverload #holographicdesign #conceptualbackground

3
19

13 Apr 2025
HOW
many realities
can one mind handle? 📺𓂃༘⋆
What do Y⚬U see HERE?
Chaos 𖣠r clarity?
Signal 𖣐r noise?
🤔
#RetroFuture #AnalogDreams #VisualOverload #AiArt #ArtPrompt #CreativeMind

5
2
38
936