
Multimodal pre-training and post-training. final-year PhD student at Meta FAIR @AIatMeta and Oxford @OxfordTVG
Joined July 2020
- Tweets 224
- Following 757
- Followers 786
- Likes 1,775
21 Photos and videos



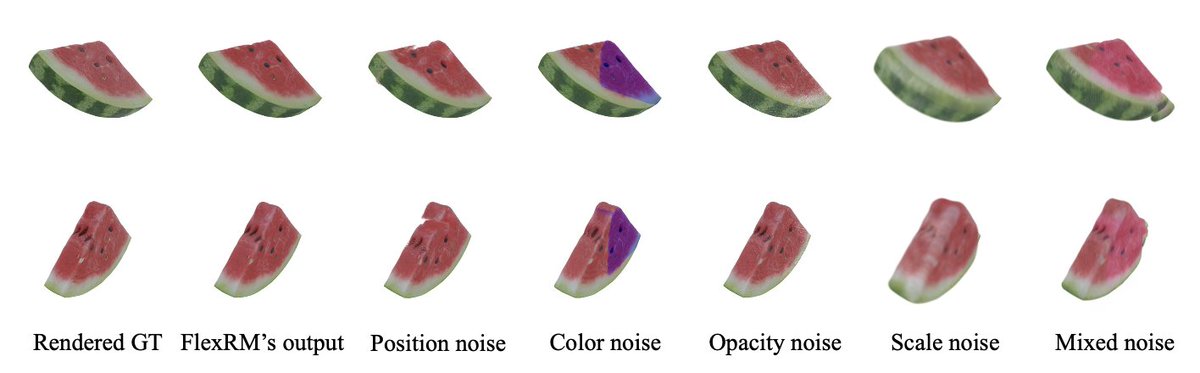






May 19
Do the right things that can scale.
May 19

Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
1
13
2,215
Mar 10
AMI was founded by amazing researchers I have deeply respected since the very beginning of my research career. They have built fundemental things:
before LLM era (SSL, JEPA, moco, mae, barlow twins, arch from LeNet to more recently resnext, convnext...),
during LLM era (gpt, dalle, gemini, Cambrian, rae, beyond language modeling...),
and AMI will undoubtedly open the path of building advanced, world-centric intelligence that shape the future!
Mar 10

i’m joining forces with @ylecun and an incredible group of people to start AMI Labs @amilabs.
AMI isn’t a conventional lab. we don’t intend to become one.
a lot to say about why this moment matters, but for now we’re heads down building.
join us: amilabs.xyz
2
1
59
7,256
Junlin Han retweeted

Mar 4
[1/9] What happens when you treat vision as a first-class citizen during multimodal pretraining? To find out, we studied the design space of training Transfusion-style models that input and output all modalities, from scratch. Here is what we learned about visual representations, data, world modeling, architecture, and scaling behavior!
Paper: arxiv.org/abs/2603.03276
Website: beyond-llms.github.io/
@TongPetersb, @DavidJFan, @__JohnNguyen__, @ellisbrown, @GaoyueZhou, @JasonQSY, @boyangzheng, @webalorn, @han_junlin, @rob_fergus, @NailaMurray, @gh_marjan, @ml_perception, Nicolas Ballas, @_amirbar, Michael Rabbat, Jakob Verbeek, @LukeZettlemoyer, @koustuvsinha, @ylecun, @sainingxie
12
60
305
51,095
Junlin Han retweeted

Mar 4
Humans communicate through language and interact with the world through vision, yet most multimodal models are language-first. What happens when we go beyond language? 🤔
Beyond Language Modeling: a deep dive into the design space of truly native multimodal models
Paper: arxiv.org/abs/2603.03276
Project: beyond-llms.github.io/

10
38
202
40,372
Mar 4
We believe the next leap in General Intelligence lies beyond language. Vision holds an untapped ocean of potential for true world modeling. By training all from scratch, we show that vision can play a more foundational role in intelligence, rather than just being an add-on!!
Mar 4

Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]

2
2
48
4,914
Mar 4
It covers many design spaces in unified pre-training, from visual rep and arch to world modeling and scaling. Each part has very useful findings backed up with tons of explorations. Crucially, we show that vision and language are highly complementary, a synergy for intelligence.
1
5
285
Mar 4
It was really a high-stakes bet and a challenging journey. Huge congrats to the amazing team, especially Peter @TongPetersb , David @DavidJFan , and John @__JohnNguyen__ for their incredible work in leading the project! You are da best!!!
5
235
Mar 4
now accepted to iclr 2026 with oral presentation! See you in Rio.
1 Oct 2025

Excited to share our new work: “Learning to See Before Seeing”! 🧠➡️👀 We investigate an interesting phenomeno: how do LLMs, trained only on text, learn about the visual world?
Project page: junlinhan.github.io/projects…
1
3
55
7,338
6 Oct 2025
Congrats to the team!
Such a simple yet graceful way to unlock the latent multimodal capacities of text-trained LLMs. The idea of using sensory prompts to actively steer representation alignment is very cool—both practically useful and conceptually deep.
6 Oct 2025

LLMs, trained only on text, might already know more about other modalities than we realized; we just need to find ways elicit it.
project page: sophielwang.com/sensory
w/ @phillip_isola and @thisismyhat
1
10
1,690
6 Oct 2025
I have been trying to advance 3D gen from video gen back in 2024.
This project is the ultimate version along this path. My great honor to participate.
3D perception is a form of visual common sense. We do not need any explicit 3D reps for generation. (As bitter lesson says)
6 Oct 2025

Introducing Kaleido💮 from @AIatMeta — a universal generative neural rendering engine for photorealistic, unified object and scene view synthesis.
Kaleido is built on a simple but powerful design philosophy:
3D perception is a form of visual common sense.
Following this idea, we formulate rendering purely as a sequence-to-sequence generation problem, successfully unifying neural rendering with the architecture principles behind modern language and video models.
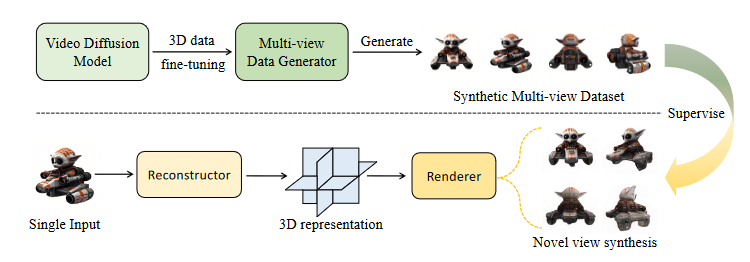
Unlike traditional neural rendering methods, Kaleido learns 3D purely in a data-driven way, without explicit 3D representations or structures.
It acquires spatial understanding directly through large-scale video pretraining, then multi-view 3D data finetuning, inspired by how LLMs acquire textual common sense from large corpora before specialising in domains like coding.
Through extensive ablations, we progressively modernised the architecture design and training strategies and tackled key scaling challenges in sequence-to-sequence generative rendering, arriving at a design that’s simple, versatile, and scalable.
Kaleido significantly outperforms prior generative models in few-view settings, and remarkably is the first zero-shot generative method matches InstantNGP-level rendering quality in multi-view settings.
We view Kaleido also as an alternative step towards world modeling that flexibly spans a spectrum of “realities": with many views, it faithfully reconstructs grounded reality; with fewer views, it imagines plausible unseen details.
🔗 Explore more results and paper: shikun.io/projects/kaleido
3
1
46
5,510
1 Oct 2025
Many thanks for sharing our work!

Learning to See Before Seeing
Demystifying LLM Visual Priors from Language Pre-training

5
1,077
1 Oct 2025
Excited to share our new work: “Learning to See Before Seeing”! 🧠➡️👀 We investigate an interesting phenomeno: how do LLMs, trained only on text, learn about the visual world?
Project page: junlinhan.github.io/projects…
7
26
158
25,850
1 Oct 2025
Implications: Beyond a better understanding of visual priors, we show that rather than treating vision as an "add-on," stronger models can be built by instilling such priors during language pre-training from scratch, making later multimodal adaptation easier and more efficient.
1
5
596
1 Oct 2025
Want to go deeper? Our full paper details 6 findings and 3 hypotheses. Beyond what's in this thread, we study relations to Platonic Representation Hypothesis, the contributions of language vs. vision, how language can 'hack' vision, and much more! See junlinhan.github.io/projects…

7
604
13 Jul 2025
We’ll be presenting this Flex3D work at ICML soon!
Unfortunately, I won’t be able to attend due to a pending visa, but Filippos @filippos_kok will present it in the 11am session on 17 July (W-216).
Drop by if you’re interested in 3D generation!
2 Oct 2024
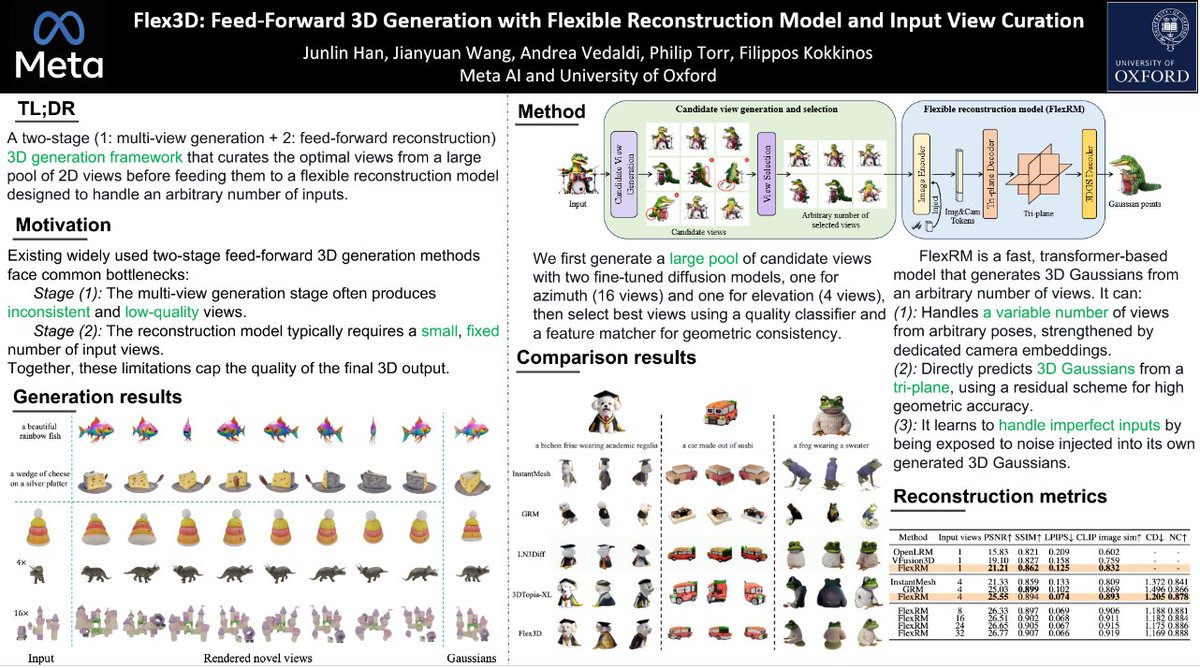
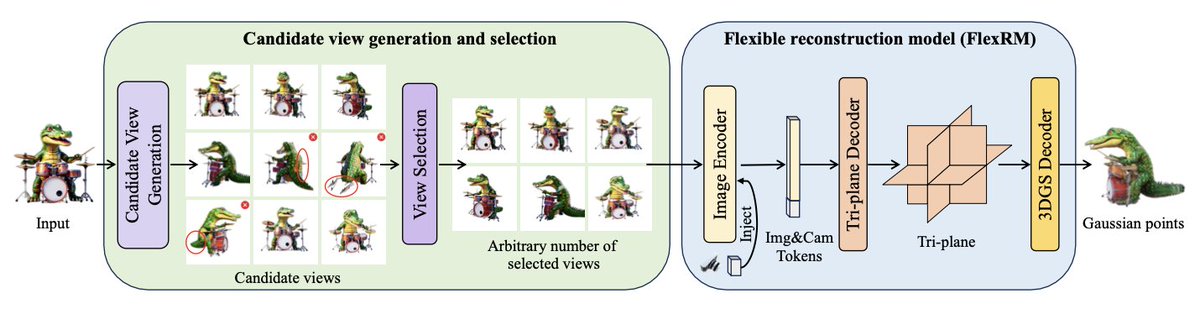
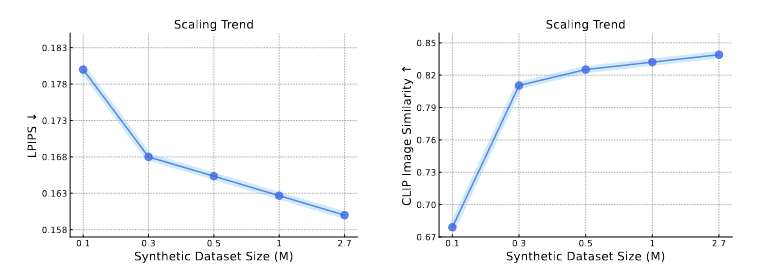
Releasing Flex3D, a two-stage pipeline for generating high-quality 3D assets in a feed-forward manner, as a further step toward high-quality 3D generation and reconstruction.
Project page: junlinhan.github.io/projects…
2
41
2,700