
Joined June 2013
- Tweets 170
- Following 483
- Followers 1,722
- Likes 814
31 Photos and videos








Pinned Tweet

Mar 4
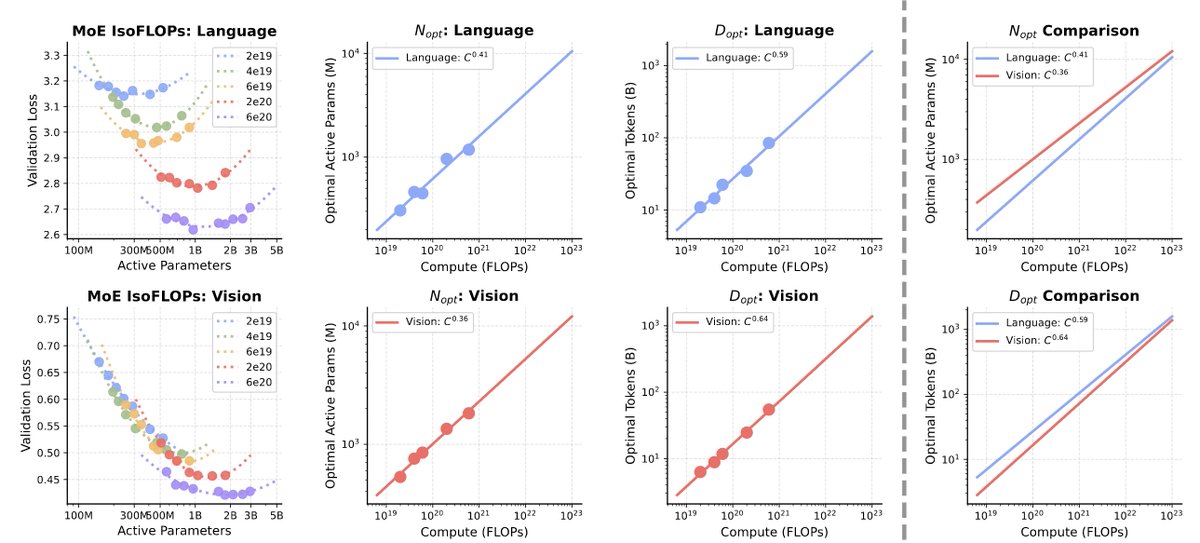
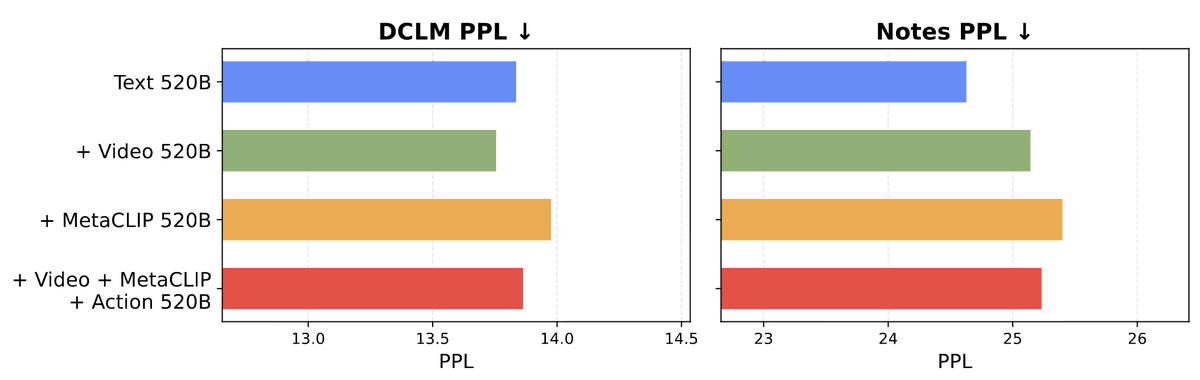
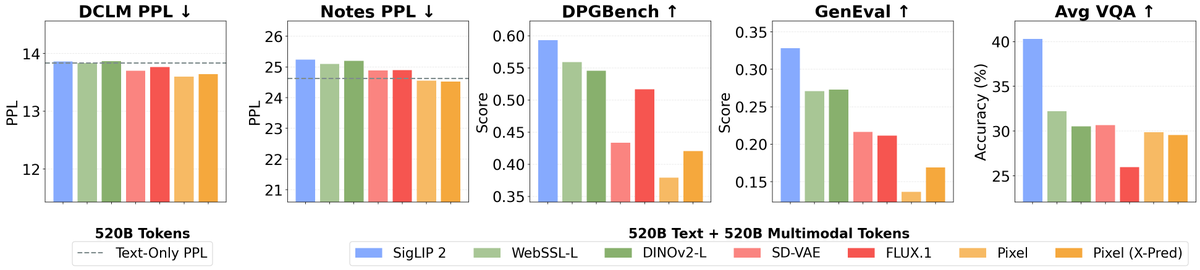
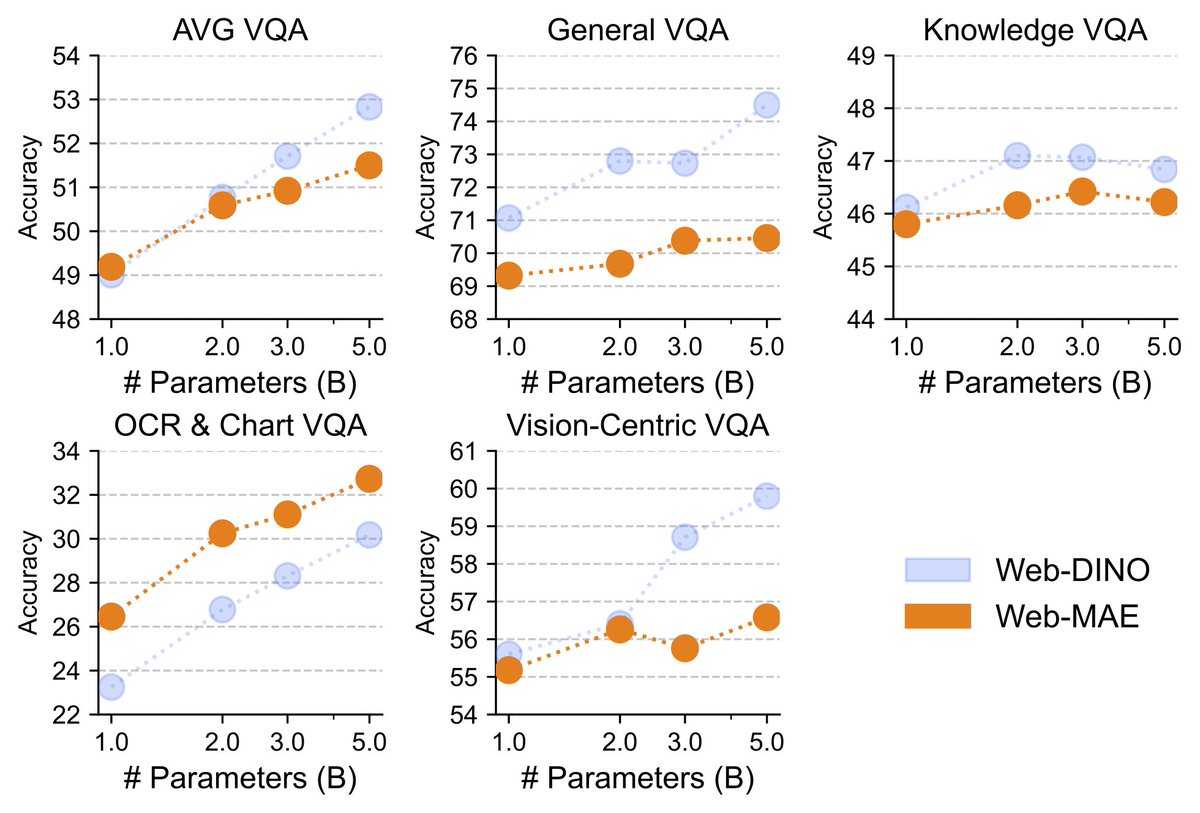
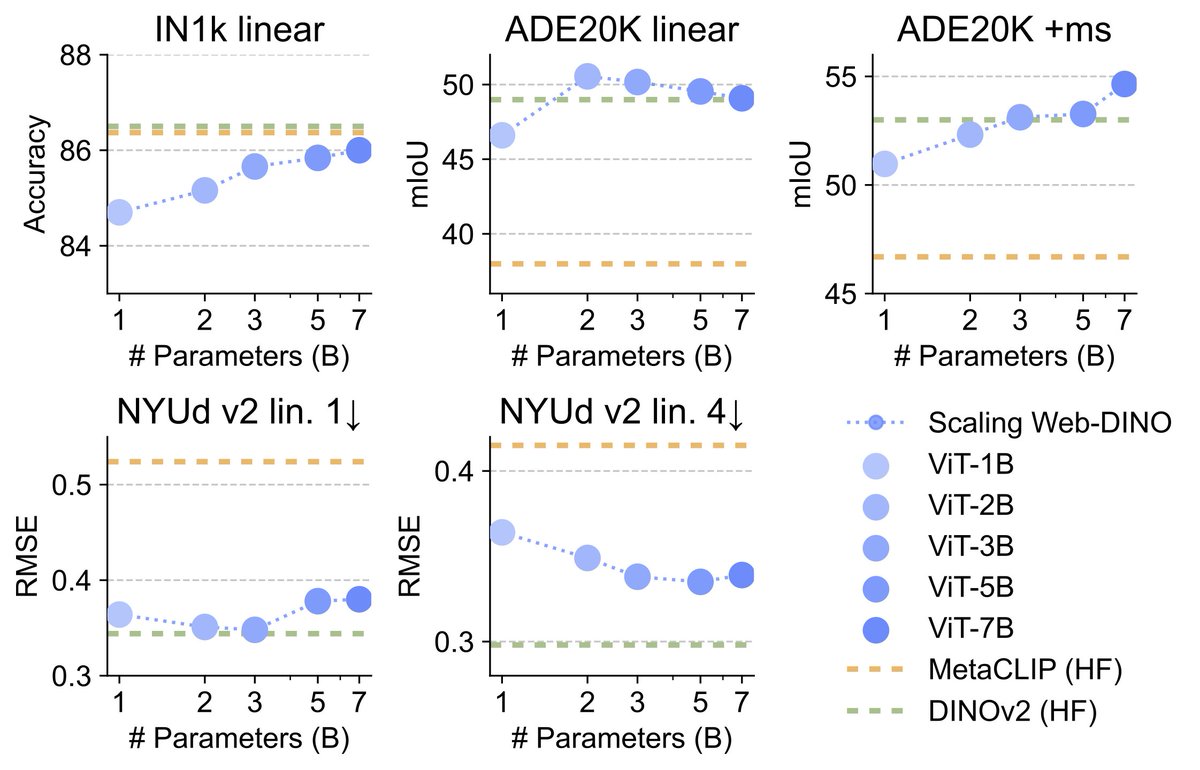
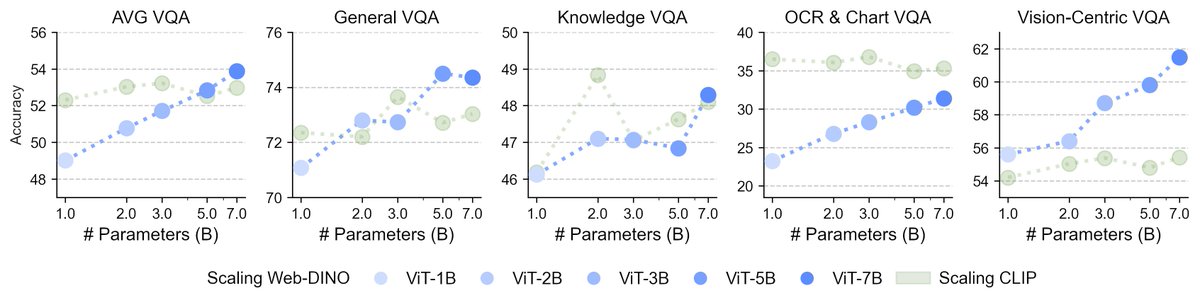
[1/9] What happens when you treat vision as a first-class citizen during multimodal pretraining? To find out, we studied the design space of training Transfusion-style models that input and output all modalities, from scratch. Here is what we learned about visual representations, data, world modeling, architecture, and scaling behavior!
Paper: arxiv.org/abs/2603.03276
Website: beyond-llms.github.io/
@TongPetersb, @DavidJFan, @__JohnNguyen__, @ellisbrown, @GaoyueZhou, @JasonQSY, @boyangzheng, @webalorn, @han_junlin, @rob_fergus, @NailaMurray, @gh_marjan, @ml_perception, Nicolas Ballas, @_amirbar, Michael Rabbat, Jakob Verbeek, @LukeZettlemoyer, @koustuvsinha, @ylecun, @sainingxie
12
60
305
51,093
David Fan retweeted

May 21
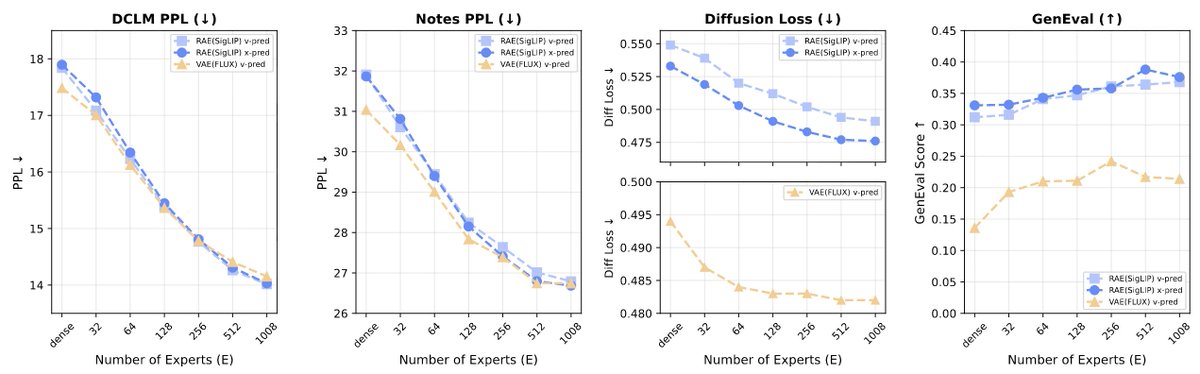
In Oct last year, Representation Autoencoders provided an elegant solution to unified tokenization for understanding and generation.
Today we make them a bit more simple. a bit more general.
Result: >10x faster convergence, better reconstruction, better generation.
And yes we test them on T2I and world models :)
Introducing RAEv2

20
58
719
2,293,773
David Fan retweeted

May 9
Today we released the code for our CVPR 2026 paper, Flowception.
Flowception bridges fully bidirectional sequence modeling and autoregressive generation by inserting frames via learned order, then denoising them with continuous flow.
Website: flowception-meta.github.io
Code: github.com/facebookresearch/…
16 Dec 2025

I thought the path to variable-length video was frame-wise autoregressive with complex forcing schedules, but I was wrong!
The solution is simple! Flowception, using frame insertions to model any-order video generation.✅
Arxiv: arxiv.org/abs/2512.11438
Project page: flowception-meta.github.io
Great collaboration with Jakob, @inthebrownbag, and @RickyTQChen on this work, and led by Tariq!
4
17
94
18,802

Heading to ICLR in Rio 🇧🇷?
We’re hosting our first networking mixer on April 24.
Meet AMI’s technical team and cofounders, and learn more about what we’re building.
Food, drinks, and great conversation included.
Register at luma.com/np3x51zh
16
262
83,166
Apr 16
Congrats Dr. @TongPetersb!! Your research journey has clearly culminated in a very cohesive and inspiring narrative that unifies several areas of work with much scope for future expansion :D It's a testament to your work ethic, good taste in problems, and attention to detail. I'm so proud of you! Very lucky to learn from you


35
11,887
Apr 1
Check out the code and data for DexWM!
Training Inference Code: github.com/facebookresearch/…
Robocasa Data: huggingface.co/datasets/face…

The code for DexWM is now publicly available: github.com/facebookresearch/….
The repository includes the full training and evaluation pipelines, along with custom dexterous manipulation datasets generated in RoboCasa, making it easy to reproduce our results and build on top of this work.
1
19
3,447
Mar 27
This week I joined AMI Labs as a founding member of the NYC lab! I'm super excited to build AI systems that truly understand the physical world. I'm also excited to help build the research agenda, culture, and team from the ground up, and learn what it takes to build a company. It's a real privilege to be here.
The last ~2 years at FAIR have been the most rewarding of my professional life so far. When I first started doing research almost 10 years ago, joining FAIR felt like a pipe dream. I became a better researcher, open-sourced for the first time (V-JEPA 2, WebSSL, MetaMorph, DexWM), grew as a person, made life-long friends, and even rekindled old hobbies — like playing clarinet with the Meta NYC orchestra.
I want to thank Mike Rabbat, Maryam Fazel-Zarandi, the JEPA team, and all my amazing colleagues collaborators who made this dream come true. The research world is small, so I know our paths will cross again. Please stay in touch!

Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe.
We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world.
We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one.
Read more: amilabs.xyz/
AMI - Real world. Real intelligence.

ALT Photographer: Yann LeCun IC1340 / NGC 6992 / Eastern Veil nebula 20210628-ic1340-rasa-2600mc-lext Scope: Celestron RASA 11" Camera: ZWO ASI2600MC Filter: Radian Triad quad narrow band. Subs: 65 @300 seconds.
35
16
489
59,378
Mar 4
[1/9] What happens when you treat vision as a first-class citizen during multimodal pretraining? To find out, we studied the design space of training Transfusion-style models that input and output all modalities, from scratch. Here is what we learned about visual representations, data, world modeling, architecture, and scaling behavior!
Paper: arxiv.org/abs/2603.03276
Website: beyond-llms.github.io/
@TongPetersb, @DavidJFan, @__JohnNguyen__, @ellisbrown, @GaoyueZhou, @JasonQSY, @boyangzheng, @webalorn, @han_junlin, @rob_fergus, @NailaMurray, @gh_marjan, @ml_perception, Nicolas Ballas, @_amirbar, Michael Rabbat, Jakob Verbeek, @LukeZettlemoyer, @koustuvsinha, @ylecun, @sainingxie
12
60
305
51,093
Mar 4
[9/9] On a personal note: I grew a lot from this project. More challenging than the technical hurdles was navigating organizational dynamics, advocating the research vision, and securing the compute resources. A huge thanks to the incredible team that made this a reality, to FAIR for the support, and especially to @TongPetersb @__JohnNguyen__.
We started this journey together and stuck by each other’s side through all the highs and lows. This work builds upon all of our collective experiences in and long-term beliefs about visual representations multimodal modeling. I see this as just the first step in a long-term research agenda. I couldn't ask for a better partnership!
2
1
15
1,263
Mar 4
Also many thanks to the numerous people who gave feebdack on the work and supported us through this journey! @JimmyTYYang1, @sharut_gupta, @JiachenAI, @jiawzhao, @Hu_Hsu, @em_dinan, @XiaochuangHan, @TusharNagarajan, @TianhongLi6, @jilin_14, @Aniket_d98, @shushengyang, @jihanyang13, @WeijiaShi2, @gene_ch0u, Daniel Bolya, just to name a few
15
1,167
David Fan retweeted
Mar 4
Humans communicate through language and interact with the world through vision, yet most multimodal models are language-first. What happens when we go beyond language? 🤔
Beyond Language Modeling: a deep dive into the design space of truly native multimodal models
Paper: arxiv.org/abs/2603.03276
Project: beyond-llms.github.io/

10
38
202
40,372
David Fan retweeted

Mar 4
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]

35
221
1,053
217,731
David Fan retweeted

Feb 26
world modeling is never about rendering pixels.
rendering is local. world state is global. as soon as more than one agent exists, the only thing that truly matters is the shared representation beneath individual views. that shared representation is what scales into collective capability.
this is why I'm super excited to share project Solaris -- our new work focused on building a multiplayer video world model in minecraft.
This release includes three main pieces.
1⃣Solaris Engine, a fully featured multiplayer data collection system with built in visuals. the team put a huge amount of work into this since nothing like it really exists yet.
github.com/solaris-wm/solari…
2⃣Solaris Model, a multiplayer DiT with a new memory efficient self forcing design, trained on 12.6M frames of coordinated Minecraft gameplay.
github.com/solaris-wm/solari…
3⃣Solaris Eval, which uses a VLM as a judge to evaluate different multiplayer capabilities.
read the full technical breakdown by @ojmichel4, and start building with Solaris.
solaris-wm.github.io/

Feb 26

📢Current world models aren't really modeling the world; they're modeling one agent's view of it. Partial observations ≠ world state.
Future world models will be independent of any one agent's perspective. You will be able to “drop in” any number of agents at any point in time, and a persistent world state will evolve with their interactions. Imagine a neural MMORPG server. 🧵[1/10]
15
62
481
76,543
Feb 9
Going beyond cross-entropy method will make planning on top of world models much more feasible in the real world, e.g. for real-time robotics! Amazing work @michaelpsenka @_amirbar 😁 Was amazing to see the progress unfold over the summer

Planning is one of the most exciting uses of world models, but existing planners struggle on long horizons.
Introducing GRASP: a fast gradient-based planner for world models that outperforms prior methods on long-horizon tasks.
Two key ideas:
1.jointly optimize actions and intermediate subgoals
2.inject stochasticity to explore subgoal space
Project page: michaelpsenka.io/grasp/
Paper: arxiv.org/abs/2602.00475
w/ @michaelpsenka @mikerabb @ask1729 and @ylecun
1
4
40
6,596