
Research Scientist at Meta FAIR | Computer Vision, NLP, Robotics | CS PhD @UMich
Joined May 2016
- Tweets 113
- Following 468
- Followers 863
- Likes 594
5 Photos and videos



Pinned Tweet

Mar 4
Vision isn't an "add-on"—and we have the data to prove it. 👁️⚡️
Thrilled to share our new work on Transfusion-style models. We explored treating visual data as a first-class citizen from day one, from architecture to scaling behavior.
Check it out:
🔗 beyond-llms.github.io
Mar 4

[1/9] What happens when you treat vision as a first-class citizen during multimodal pretraining? To find out, we studied the design space of training Transfusion-style models that input and output all modalities, from scratch. Here is what we learned about visual representations, data, world modeling, architecture, and scaling behavior!
Paper: arxiv.org/abs/2603.03276
Website: beyond-llms.github.io/
@TongPetersb, @DavidJFan, @__JohnNguyen__, @ellisbrown, @GaoyueZhou, @JasonQSY, @boyangzheng, @webalorn, @han_junlin, @rob_fergus, @NailaMurray, @gh_marjan, @ml_perception, Nicolas Ballas, @_amirbar, Michael Rabbat, Jakob Verbeek, @LukeZettlemoyer, @koustuvsinha, @ylecun, @sainingxie
1
2
16
3,127
Shengyi Qian retweeted

Apr 8
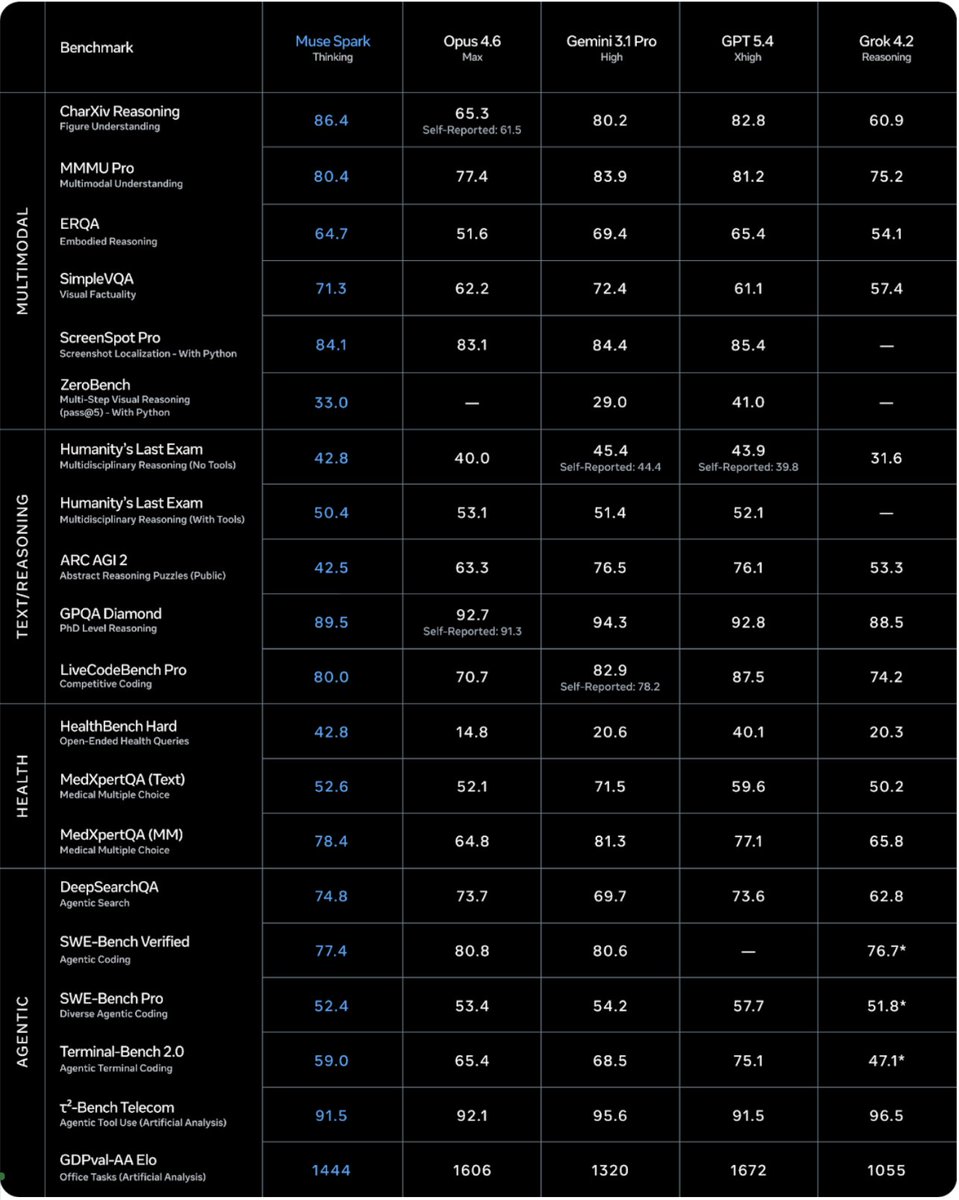
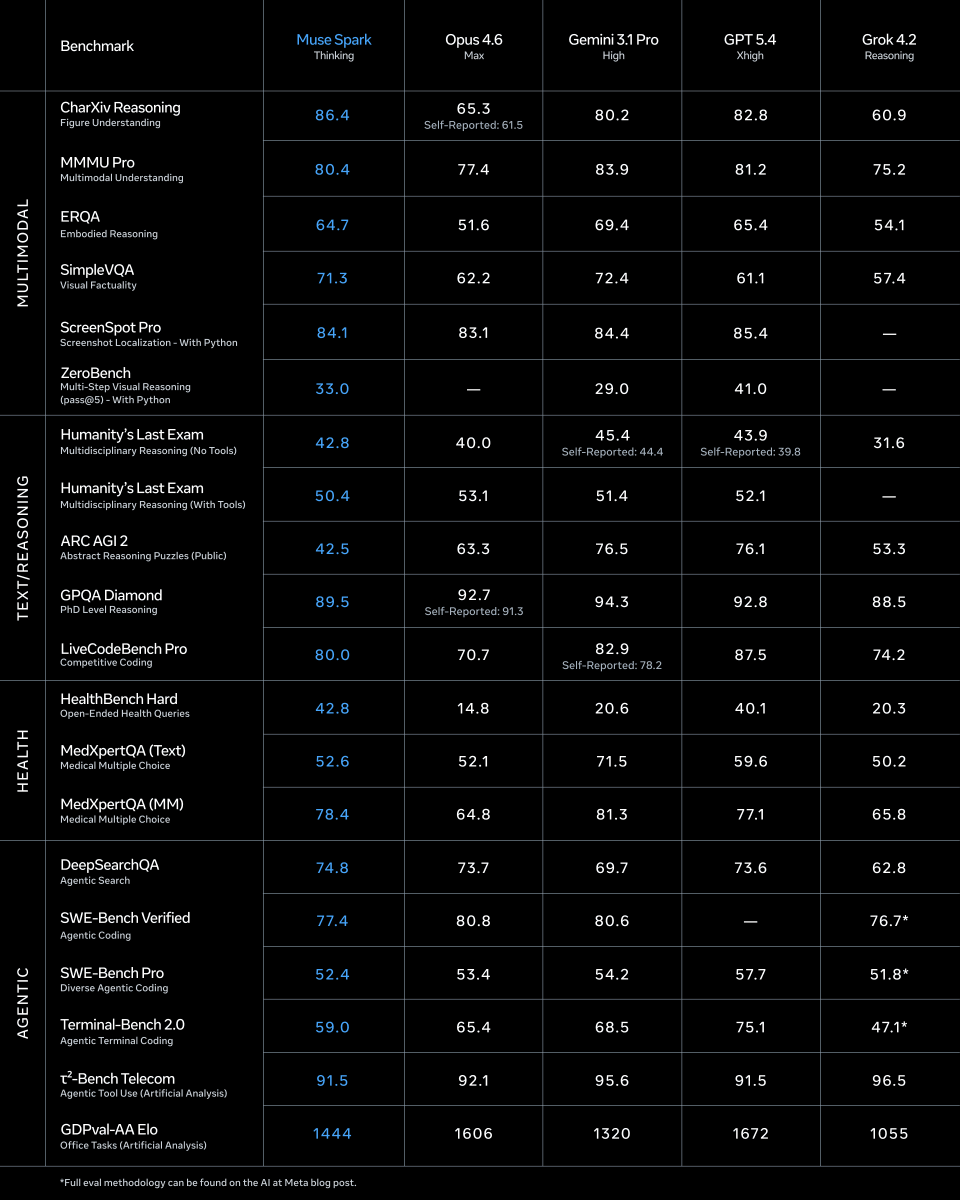
Excited to share what we’ve been building at Meta Superintelligence Labs! We just released Muse Spark, our first AI model. It's a natively multimodal reasoning model and the first step on our path to personal superintelligence. We've overhauled our entire stack to support scaling, and this is just the beginning.
ai.meta.com/blog/introducing…
74
172
1,667
236,956
Shengyi Qian retweeted

Apr 8
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
745
1,191
10,372
4,552,768
Shengyi Qian retweeted

Mar 4
Beyond Language Modeling
FAIR Meta and NYU present a deep dive into native multimodal pretraining. They show RAEs unify visual understanding/generation, vision/language data are complementary, world modeling emerges naturally, and MoE harmonizes vision's higher data hunger—paving the way for truly unified models.

1
6
37
2,742
Shengyi Qian retweeted

Mar 4
Humans communicate through language and interact with the world through vision, yet most multimodal models are language-first. What happens when we go beyond language? 🤔
Beyond Language Modeling: a deep dive into the design space of truly native multimodal models
Paper: arxiv.org/abs/2603.03276
Project: beyond-llms.github.io/

10
38
202
40,372
Shengyi Qian retweeted

Mar 4
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]

35
221
1,053
217,736
Feb 19
Excited to share our latest work from Meta Superintelligence Labs! 🚀 We’re moving beyond static AI to agents that actually evolve with you. Our PAHF framework solves "Alignment Drift" through a continuous feedback loop. Check out the paper!
Feb 19

New Meta Research 🚀
AI agents are powerful, but don’t stay aligned with you over time.
When preferences shift, they don’t adapt. You correct them once…they repeat the mistake. 🤦
Introducing PAHF: continual personalization where agents learn from feedback to stay in sync.

2
13
1,646
Feb 3
We are excited to host the 2nd 3D-LLM / VLA Workshop at CVPR this June! If your research explores the synergy between spatial intelligence, robotics, and language grounding, we invite you to submit your work.
We also have an incredible lineup of speakers. Join us!
Feb 3

LLMs are now learning space, geometry, and how to move. 🤖📐
The 2nd CVPR 3D-LLM VLA Workshop brings together language, 3D perception, and action for embodied intelligence.
📢 Call for Papers is OPEN: openreview.net/group?id=thec…
🌐 Website: 3d-llm-vla.github.io
If your research lives at the intersection of words, worlds, and robots—this one’s for you.
#CVPR2026 @CVPR

2
15
2,359
Shengyi Qian retweeted

3 Nov 2025
Have arrived in Suzhou!
I will present DISCO paper in EMNLP 2025 Thursday’s noon poster session. Feel free to reach out and discuss! If you’re interested in Meta’s current position for both FTE or internships, also let me know! #EMNLP2025
20 Aug 2025

💃🕺🪩 DISCO 🪩 🕺💃 is now accepted to EMNLP findings. Congratulations to @YuhangZhou2 and collaborators!
2
9
37
10,657
Shengyi Qian retweeted
20 Aug 2025
Glad to have my PhD’s last work accepted by EMNLP 2025! Thank all my collaborators for their efforts. Expect to see you all in Soochow! #EMNLP25
20 Aug 2025
💃🕺🪩 DISCO 🪩 🕺💃 is now accepted to EMNLP findings. Congratulations to @YuhangZhou2 and collaborators!
1
1
15
2,469
Shengyi Qian retweeted

9 Jul 2025
Reasoning can be made much, much faster—with fundamental changes in neural architecture. 😮
Introducing Phi4-mini-Flash-Reasoning: a 3.8B model that surpasses Phi4-mini-Reasoning on major reasoning tasks (AIME24/25, MATH500, GPQA-D), while delivering up-to 10× higher throughput at 32K generation length with vLLM. 🤯
Model: huggingface.co/microsoft/Phi…
Codebase: github.com/microsoft/ArchSca…
Blog: aka.ms/flashreasoning-blog
Paper: aka.ms/flashreasoning-paper
(1/8)

2
68
362
43,767
Shengyi Qian retweeted

24 Jun 2025
Interactable Digital Twins hold great promises. It allows us to train in sim and test in real.
But can we go a step further? Can we deploy a robot w/o training?
Key idea: simulate the outcome of each action with Digital Twins and use VLM as critic to select the best action.
18 Jun 2025

How can robots solve tasks that demand both semantic and physical reasoning, like playing real-world Angry Birds, without tons of data?
We introduce Prompting with the Future: an MPC framework that fuses a pretrained VLM with an interactive digital twin for grounded, open-world motion planning.
🌐 prompting-with-the-future.gi…
1
6
59
5,195
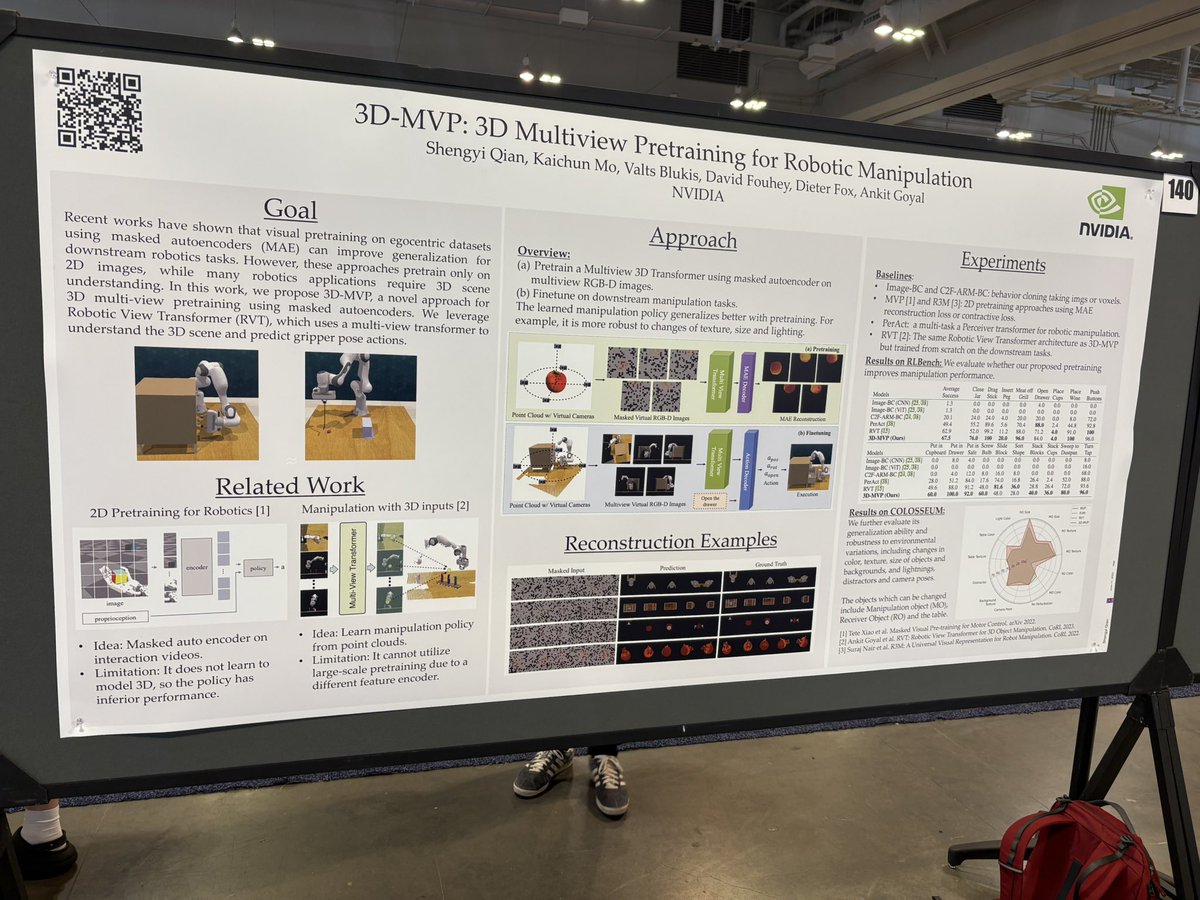
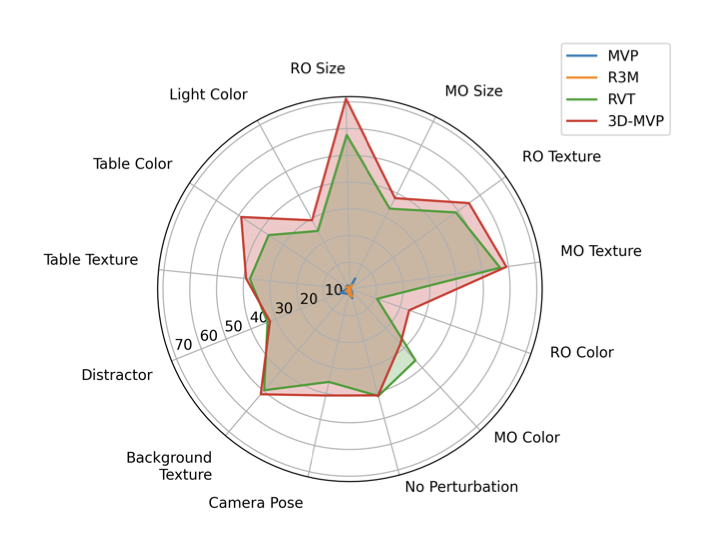
15 Jun 2025
We’re presenting 3D-MVP at CVPR poster #140 right now!
#CVPR2025 #ComputerVision #MachineLearning #DeepLearning #3DVision #Robotics #AI #Research #PaperPresentation
1
6
35
2,208

One of the biggest bottlenecks in deploying visual AI and computer vision is annotation, which can be both costly and time-consuming. Today, we’re introducing Verified Auto Labeling, a new approach to AI-assisted annotation that achieves up to 95% of human-level performance while cutting labeling costs by up to 100,000x and time by 5,000x.
Read the full paper: arxiv.org/abs/2506.02359
3
194
113
12,613
5 Jun 2025
Thrilled to be heading to Nashville next week for #CVPR2025! Can't wait to connect with the community & dive into the latest in computer vision.
1
3
182
5 Jun 2025
2️⃣ Mosaic of Modalities: A Comprehensive Benchmark for Multimodal Graph Learning. Introducing a new benchmark for #MultimodalGraphLearning. Project: mm-graph-benchmark.github.io…
#MachineLearning
1
1
98
5 Jun 2025
3️⃣ 3D-GRAND: Towards Better Grounding & Less Hallucination for 3D-LLMs. A large-scale dataset & models for improved 3D visual grounding. Project: 3d-grand.github.io/
#3DLLM #AI
DM me if you're at #CVPR or want to chat about these! Looking forward to it!
3
125
Shengyi Qian retweeted

29 May 2025
🔥 How can we align #LLMs effectively with messy, imbalanced real-world data?
#GRPO is great 🤩—simple, strong, and doesn't even need a learned value function. 😥But it struggles when data isn’t evenly balanced across domains.
🕺💃 Enter 🪩 DISCO 🪩: Domain- & Difficulty-Aware #RLHF!
🔗👉: arxiv.org/abs/2505.15074
#NLP #LLM #RLHF #GRPO
A 🧵👇

2
12
66
15,999