
Ex Treasure data engineer/Java Champion,Oracle ACE pro /JCO 3th chairman/Doctor of Veterinary Medicine
Joined May 2009
- Tweets 13,847
- Following 657
- Followers 1,022
- Likes 1,534
268 Photos and videos




양수열(Soo yeol, Yang) retweeted

May 18
Claude로 겉보기에 번지르르한 앱 뚝딱 만들어서 바로 시장에 던지는 양산형 빌더들이 법적 시한폭탄을 마주하는 중임. SQL 인젝션이나 .env 파일 유출 같은 뼈아픈 백엔드 공백을 완전히 방치했다가 청구서 폭탄이나 소송으로 직행하는 판임. AI가 코드를 초고속으로 짜준다고 인프라 보안과 규격 검증이라는 필수 노가다까지 건너뛸 수는 없음.
May 16

vibecoder'lara üzücü haber. claude a app'i yaptırıp direkt yayına alıp para kazanmaya çalışan vizyonsuz tayfa teker teker mahkemelerde sürünmeye başlıyor.
neden mi? çünkü herkes fiyakalı arayüzlerle piyasaya uygulama fırlatıyor ama işin o "sıkıcı" güvenlik ve altyapı kısmını tamamen es geçiyor.
canlıya çıkmadan önce masaya koyman gereken o acımasız liste:
• sql injection ve xss açıklarına karşı sistemi tarayacaksın.
• .env değerlerinin sızmadığına emin olacaksın.
• kullanıcı verisi topluyorsan o gizlilik politikasını yazacaksın.
• birileri api faturanı patlatmadan önce o hız sınırını (rate limit) koyacaksın.
• api key'lerini front-end'de ulu orta bırakmayıp sunucuya veya proxy arkasına gizleyeceksin.
yapay zeka sana o sistemi saniyeler içinde inşa edebilir. ama güvenlik ve gizlilik duvarlarını örmeden o "paylaş" butonuna basarsan... geçmiş olsun
ortaya bir "ürün" değil, sadece patlamaya hazır hukuki bir saatli bomba bırakmış olursun. aman dikkat edin
1
11
58
9,477
양수열(Soo yeol, Yang) retweeted

May 8
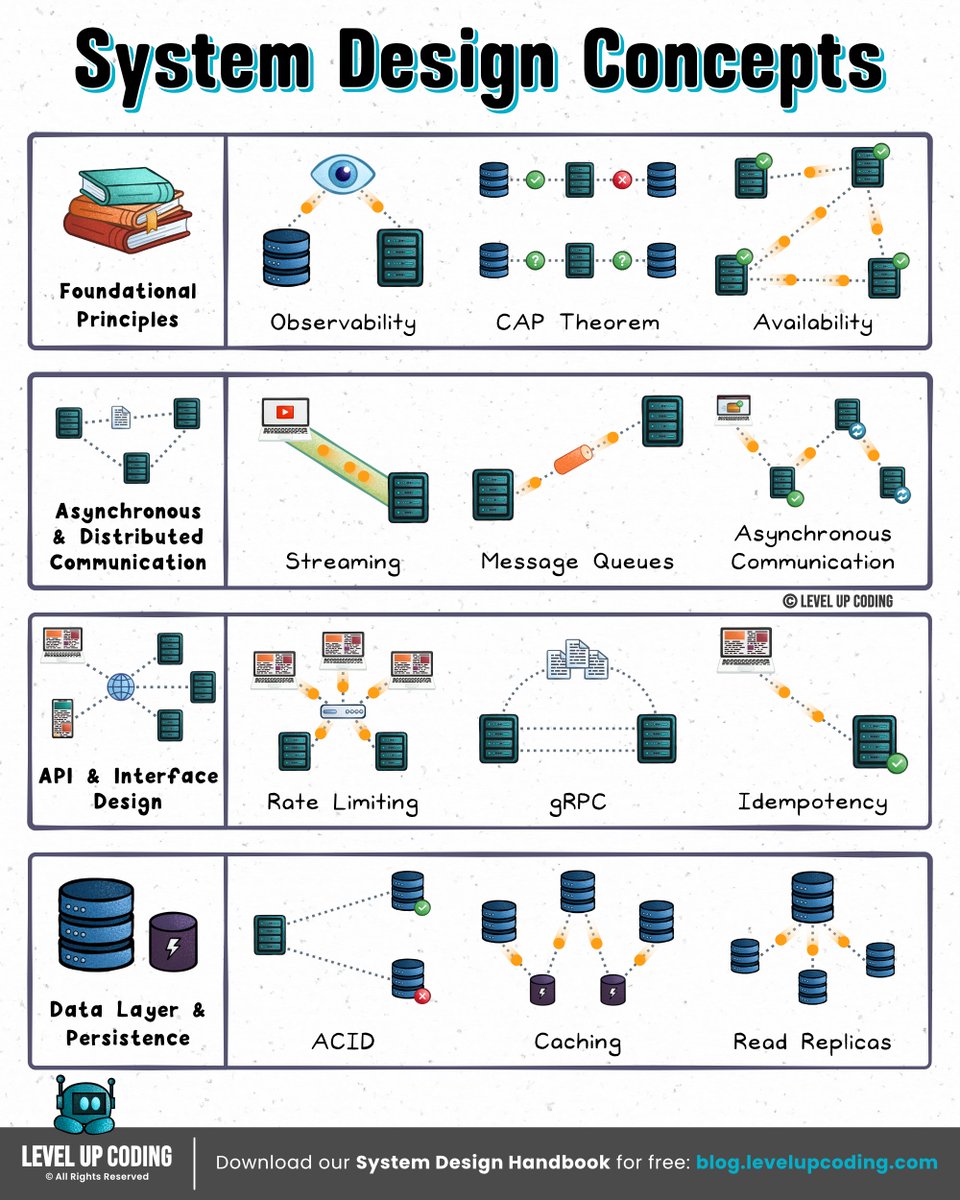
I wrote 35 articles for 35 system design concepts:
1) Microservices: lucode.co/microservices-lil1…
2) Redis: lucode.co/redis-explained-li…
3) Event-driven architecture: lucode.co/event-driven-archi…
4) Database indexing: lucode.co/database-indexing-…
5) Circuit breakers: lucode.co/circuit-breakers-l…
6) ACID vs BASE: lucode.co/acid-vs-base-lil1n…
7) Rate limiting: lucode.co/rate-limiting-lil1…
PS - if you want a structured path, get my free 142-page System Design Handbook when you join my free weekly newsletter → lucode.co/system-design-hand…
8) Observability: lucode.co/observability-clea…
9) System design quality attributes: lucode.co/system-design-qual…
10) CAP theorem: lucode.co/cap-theorem-lil1nl…
11) Idempotency: lucode.co/idempotency-in-api…
12) REST APIs: lnkd.in/gi5zd2jR
13) Sync vs Async: lnkd.in/gG-EnbA9
14) Network protocols: lucode.co/network-protocols-…
15) Change Data Capture (CDC): lucode.co/change-data-captur…
16) CI/CD pipelines: lucode.co/ci-cd-lil1nlsm
17). SSO (single sign-on): lnkd.in/gXdVyqBg
18) JWT: lucode.co/json-web-token-jwt…
19) gRPC: lucode.co/grpc-explained-lil…
20) Health checks vs heartbeats: lucode.co/health-checks-vs-h…
21) API gateway vs load balancer vs reverse proxy: lucode.co/api-gateway-vs-lb-…
22) HTTPS: lucode.co/https-explained-li…
23) Load balancing algorithms: lucode.co/load-balancing-alg…
24) Database caching: lucode.co/database-caching-s…
25) API protocols: lucode.co/api-architecture-s…
26) CDN: lucode.co/cdn-lil1nlsm
27) Database types: lucode.co/database-types-lil…
28) Message Queues: lucode.co/message-queues-lil…
29) Hashing vs encryption vs tokenization: lnkd.in/gfqGYQnq
30) Service Discovery: lucode.co/service-discovery-…
31) Pub/Sub: lucode.co/pub-sub-lil1nlsm
32) Connection pooling: lucode.co/connection-pooling…
33) Forward proxy vs reverse proxy: lucode.co/forward-vs-reverse…
34) Consistent hashing: lucode.co/consistent-hashing…
35) SQL vs NoSQL:lucode.co/sql-vs-nosql-lil1n…
——
👋 PS: Get my free 142-page System Design Handbook when you join my free weekly newsletter.
Join 33,000 engineers → lucode.co/system-design-hand…
——
♻️ Repost to help others learn system design.
➕ Follow me ( Nikki Siapno ) to become good at system design.
8
139
618
68,396
양수열(Soo yeol, Yang) retweeted

May 8
연구실 대학원생이 아주 기가막힌 비유를 해줬습니다.
부패와 발효의 차이와 똑같습니다.
같은 LLM 결과에 대해서
쓸모가 없으면 hallucination이라고 하고
쓸모가 있으면 inter/extrapolation이라고 부릅니다
쓸모가 없는데 재밌으면 creative라고도 합니다
May 8

LLM이 환각을 생성하는 이유!
왜냐면요
왜냐면 말이죠
‘환각’이라는 단어는 환각입니다.
옛날에는 interpolation/extrapolation이라고 불렀어요.
어떤 프로토스 하이템플러가 그걸 갑자기 환각이라고 부르기 시작했어요.
5
853
2,171
173,588
양수열(Soo yeol, Yang) retweeted

Apr 14
bits-bytes-nn.github.io/insi…
이렇게 잘 정리된 글로 흐름을 보니 재밌네요.
83
222
16,716
양수열(Soo yeol, Yang) retweeted

법령을 코드처럼.. 이라는 표현이 모든 영역에 적용되게 될것 같다. 진료를 코드처럼. 회계를 코드처럼. 경영을 코드처럼. 등등 모두 성립한다.

legalize.kr/
@junghwan 님께서 한국 법을 모두 git repo로 옮겨주셨다! 한국법령정보 MCP보다 얘가 훨씬 빠르고 편하다!!!!
코드 : github.com/9bow/legalize-kr
이거 예전부터 하고싶었지만 은근히 까다로운 처리가 필요해서 미뤘던건데, 시간지나니 다 해주셨다 와와와와
2
28
119
14,172
양수열(Soo yeol, Yang) retweeted

Feb 22
제가 웬만해선 필독, 무조건, 100% 같은 단어는 자주 사용하지 않으려고 하는데요,
이 아티클은 무조건 필독하셔야 합니다.
아마 많은 분들은 앤트로픽과 오픈AI의 관계를 잘 모르실 것이고 또 그들이 추구하는 철학과 그들이 현재 미국 증시에 미치고 있는 막대한 영향에 대해 깊히 알기 어려우실 거라 생각합니다.
저를 오래 보신 분이라면 알겠지만 저는 오픈ai를 샘 알트만 때문에 싫어합니다.
챗봇도 chatGPT는 사용하지 않은지 오래 됐습니다.
이번에 오픈ai가 투자규모 축소를 발표했는데, 생각보다 빠른 시간에 일이 터질지도 모르겠네요.

19
374
1,359
162,775

I have built the future
I'm now running 3 of the most powerful AI models in the world on my desk, completely privately, for just the cost of power.
3rd 512gb Mac Studio is in (Apple reached out and lent me the third one! Thanks Apple!)
Here are the models I'll be running:
• Kimi K2.5 (600gb across all 3 studios via EXO labs)
• MiniMax 2.5 (120gb on one studio)
• Qwen 3.5 (220gb on one studio)
• GOT OSS 120B Heretic (60b on one studio- completely uncensored 😈)
3 ultra powerful models coding, writing, researching, reading your posts, 24 hours a day. 7 days a week. Nonstop.
Running across 4 OpenClaws on 3 Mac Studios and a Mac Mini
A few use cases I have set up:
• Kimi K2.5 reading feature requests for Creator Buddy and building out the feature requests autonomously. My own personal product manager
• MiniMax 2.5 reading Reddit all day, looking for challenges to solve. Then building prototypes for me to review every morning. All autonomously.
Qwen 3.5 hitting the X API every hour to see top trending posts in AI and vibe coding. Turning those into video scripts for me to review hourly (this has already built me one script with over 100k views on YT)
Unlimited economic power just sitting there. No cloud APIs. No crazy API bills. No tech executives reading my logs. Totally customizable and private.
This is the future. I'm just showing it to you before it arrives

617
359
4,512
735,888

양수열(Soo yeol, Yang) retweeted

Jan 6
🍌 Nano Banana Pro 레시피 북
> 159페이지 껴~~
와 감동.. 정말 다양한 케이스와 프롬프트를 담고 있는 레시피들이 공유되었네요.
canva.com/design/DAG6_Zjwl_w…
사실 프롬프트는 정답이 없습니다. 제공된 자료들을 참고해서 다양한 시도를 해본다면 다채로운 결과물을 얻으실 수 있습니다.
이렇게 공유해주셔서 감사드리네요~~
💬
이 책은 혼자 만든 결과물이 아닙니다.
각자의 자리에서 바쁘게 살아가면서도 기꺼이 참여해준 30여명의 크리에이터들이 본인이 맡은 카테고리에서 최선을 다해 사례를 공유해주었습니다.
완벽하지 않을 수도 있지만, 그래서 더 살아있는 자료라고 생각합니다.
- 레시피 북 프롤로그에서..

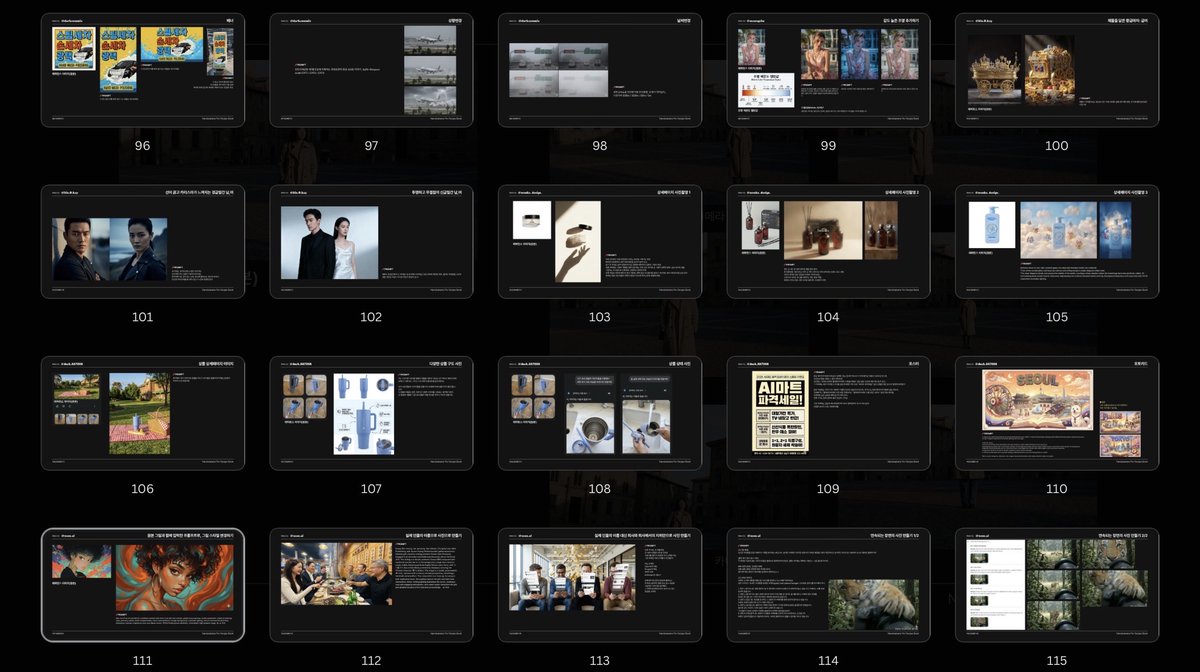
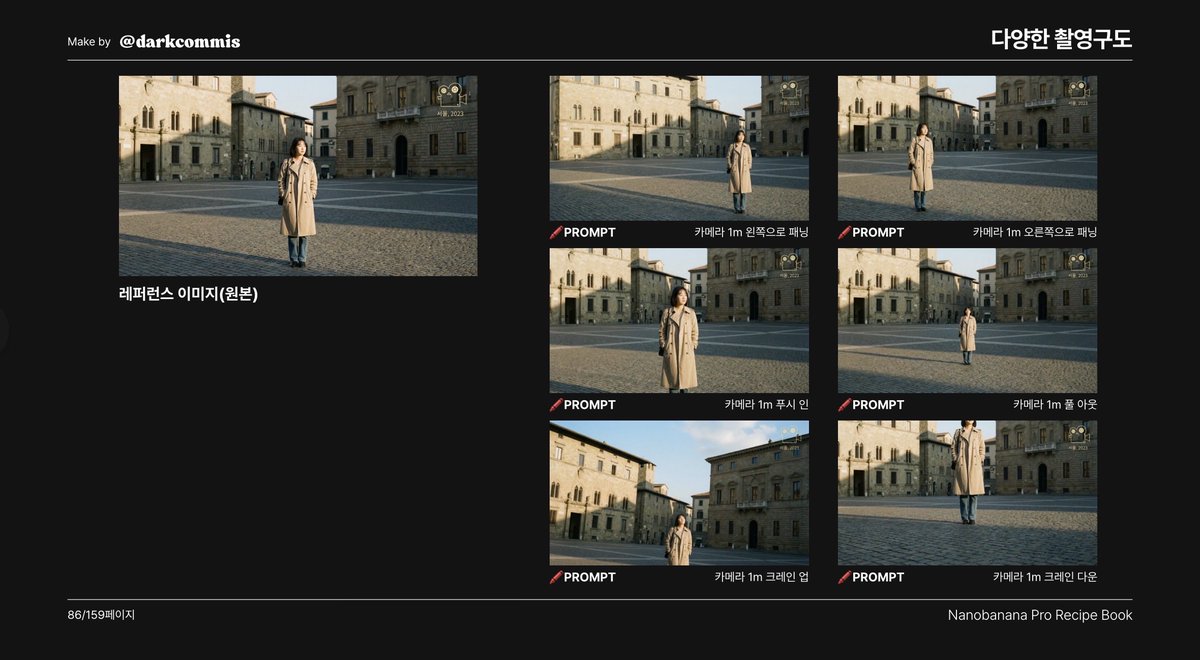

44
700
1,895
124,903
양수열(Soo yeol, Yang) retweeted

29 Dec 2025
Harvard's just open-sourced their ML Systems textbook. it's extremely practical for not just learning how to build and train models, but to build production systems (the skill that actually matters). topics are cool af:
> building autograd, optimizers, attention, and a mini-pytorch from scratch to truly learn how an ML framework runs. (i love this the most)
> basics of DL, batch sizes, precision, model architectures, and training
> ML performance optimization, HW acceleration, benchmarking, efficiency
so this is not just an intro to machine learning, it's the full package from the beginning to the actual end. right now you can read the book and access the code for free. this is one of the best books I've seen dropping in 2025, so don't sleep on it.
here's the repo (you can find the book link there): github.com/harvard-edge/cs24…
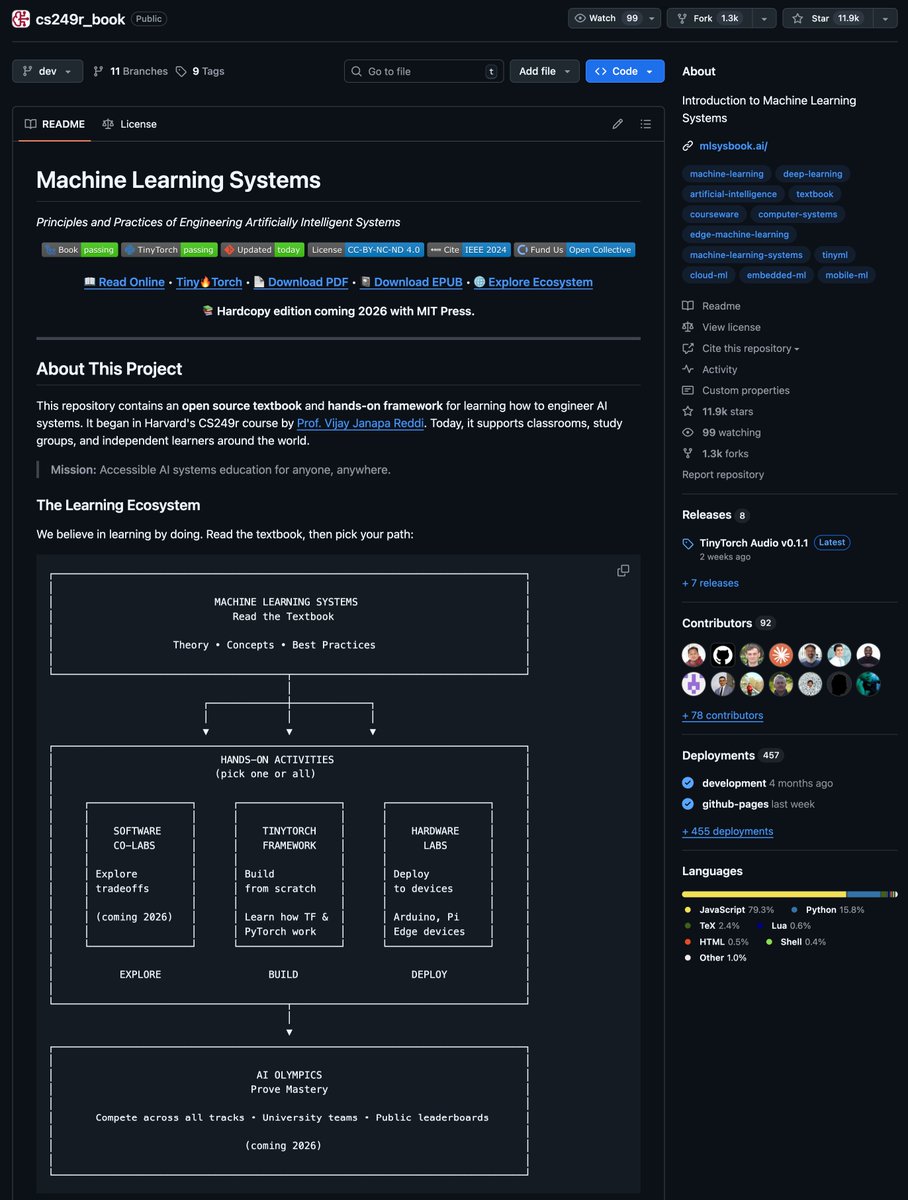
50
645
5,137
280,200
양수열(Soo yeol, Yang) retweeted
11 Dec 2025
ChatGPT의 메모리 시스템을 리버스 엔지니어링한 분의 글을 읽었는데, 벡터 DB RAG로 하겠지 라고 생각했던게 아니라는걸 알게 됨.
결론부터 말하면, ChatGPT는 거의 RAG를 안 쓴다.
벡터 임베딩도, 유사도 검색도, 리트리벌 비용도 거의 없다.
대신 훨씬 더 단순하고, 훨씬 더 영리한 4단계 계층만으로 모든 걸 해결한다.
1. 세션 메타데이터 (일시적)
너가 지금 모바일인지 데스크톱인지, 다크모드 켜져 있는지, 화면 크기, 시간대, 구독 등급, 심지어 최근 사용 패턴까지 전부 실시간으로 주입됨.
이건 영구 저장 안 하고, 세션이 끝나면 바로 버림. 덕분에 "지금 새벽 2시에 폰으로 물어보는구나" 하고 답변 길이랑 포맷을 알아서 조절함.
토큰 낭비 없이 환경 적응을 완벽하게 해냄.
↓
2. 명시적 장기 메모리 (최대 33개 사실)
이거 기억해줘~라고 한 거나, 대화 중에 중요한 사실을 모델이 제안하면 확인한 것만 저장됨.
이름, 직업, 목표, 취향, 진행 중인 프로젝트 정도. 그 이상은 안 넣음.
"모든 걸 기억해야 한다"는 착각 버렸고, 진짜 중요한 것만 골라서 넣는 것.. 이게 오히려 훨씬 깔끔.
↓
3. 최근 대화 요약 (약 15개)
이거 좀 흥미로움..
과거 대화 전체를 임베딩해서 검색하는 게 아니라, 그냥 미리 계산된 초경량 요약만 던져줌.
형식은 제목 타임스탬프 사용자 메시지 몇 줄 발췌. 어시스턴트 답변은 아예 안 넣음.
그러니까 "너 지난주에 뭐 물어봤더라?" 할 때 정확히 기억 안 해도, 대략적인 주제 흐름만으로도 충분히 이어갈 수 있음.
정확도 조금 희생하고 속도랑 토큰을 극한까지 아끼는 방향..
↓
4. 현재 세션 슬라이딩 윈도우
평범해 보이지만, 메시지 개수가 아니라 토큰 수로 제한 걸고,
한계 다다르면 오래된 메시지 날리면서도 2번과 3번은 계속 살아있음.
그래서 대화가 아무리 길어져도 장기 연속성은 끊기지 않음.
RAG의 집착은 그래.. 비효율적이지.
정확도 100% 챙기려고 매번 검색 돌리고, 임베딩 저장하고, 비용 올라가나 싶었는데,
OpenAI에서는 95%의 유저는 이 정도만 기억해도 충분하다라고 판단한 것.
결과적으로 속도는 빠르고, 토큰은 적게 들고, UX는 더 자연스럽게.. 좋구만...


10 Dec 2025

I spent the last few days prompting ChatGPT to understand how its memory system actually works.
Spoiler alert: There is no RAG used
manthanguptaa.in/posts/chatg…
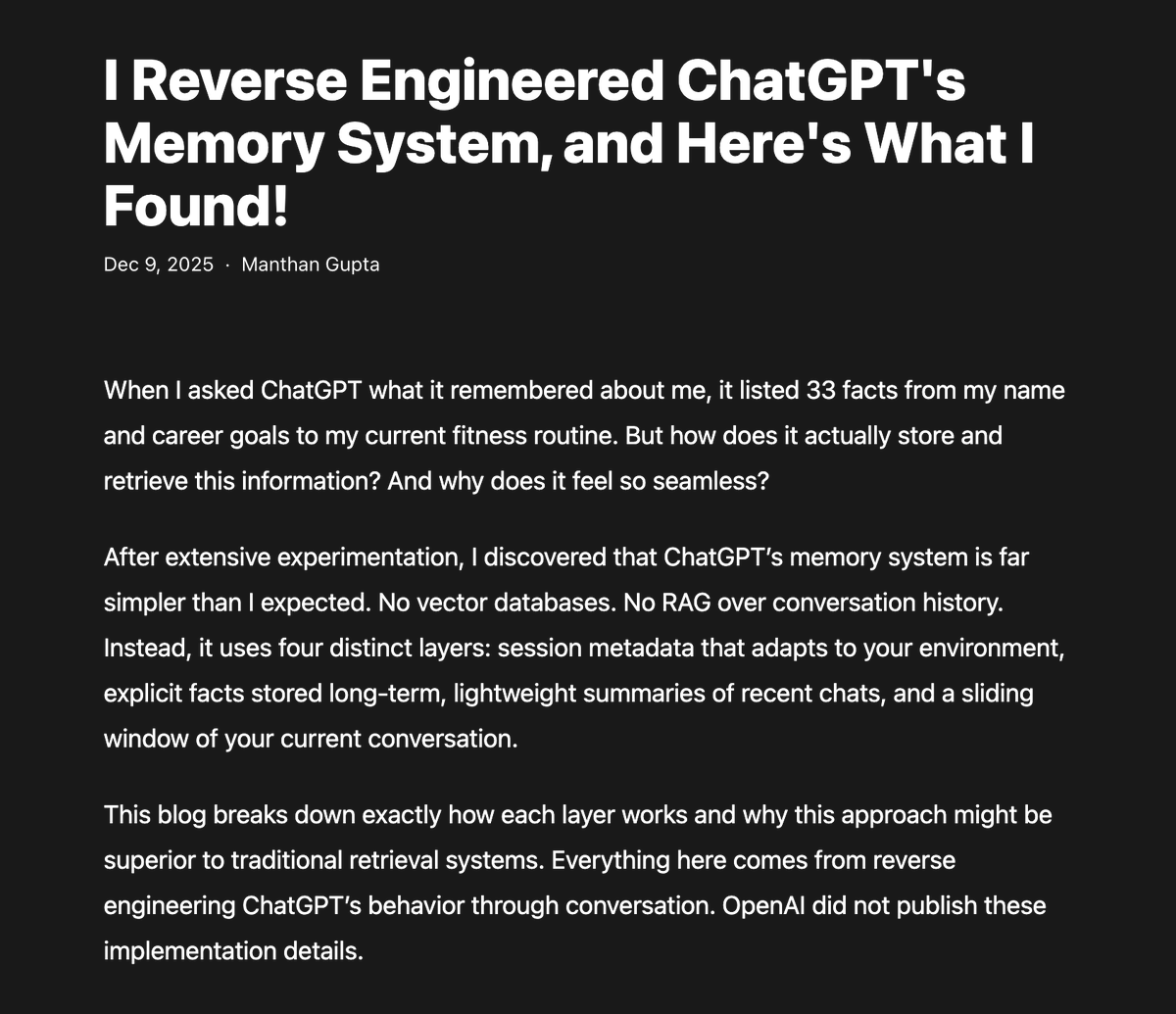
ALT A blog on how chatgpt's memory works
5
176
392
40,520
양수열(Soo yeol, Yang) retweeted

26 Jul 2025
중국 비즈니스맨한테 들은 충격적인 얘기를 해줄게,
"한국을 망하게 하는 건 너무나 쉽다. 마포구나 성동구 같은데 아파트 매매가 2배로 올려서 한 채만 사주면, 다 따라 오르고 중산층 붕괴되고 청년층은 의욕상실로 일 안하고, 직장인들 의욕은 반으로 꺽인다."
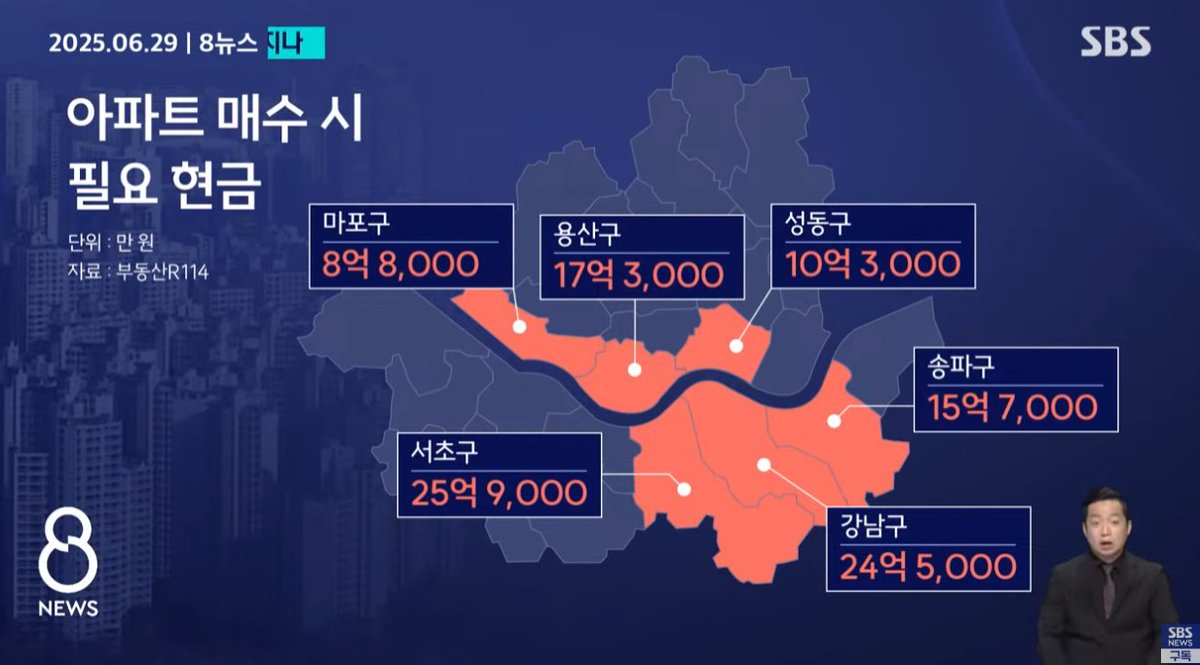
77
2,783
10,533
3,325,066
양수열(Soo yeol, Yang) retweeted
8 Jul 2025
you must read Harvard’s AI Research Experience if you’re a student/researcher. A free course book which covers the essentials and tips on doing research:
> VSCode, Git, Conda
> PyTorch, W&B
> AWS, colab
> LLMs and VLMs
> reading AI papers
> research progress and organization

9
374
2,431
182,430
양수열(Soo yeol, Yang) retweeted

26 May 2025
PYTHON is difficult to learn, but not anymore!
Introducing "The Ultimate Python ebook "PDF.
You will get:
• 74 pages cheatsheet
• Save 100 hours on research
And for 48 hrs, it's 100% FREE!
To get it, just:
1. Like & RT
2. Reply "Python"
3. Follow @Ronycoder [MUST]

426
311
598
51,676


양수열(Soo yeol, Yang) retweeted
1 May 2025
PYTHON is difficult to learn, but not anymore!
Introducing "The Ultimate Python ebook "PDF.
You will get:
• 74 pages cheatsheet
• Save 100 hours on research
And for 48 hrs, it's 100% FREE!
To get it, just:
1. Like & RT
2. Reply "Py"
3. Follow @Ronycoder [MUST]

1,244
899
2,141
202,016
양수열(Soo yeol, Yang) retweeted

1 May 2025
5 AI to convert APIs to MCP servers in just a few minutes.
1. FastAPI-MCP exposes your FastAPI endpoints as MCP servers in one line of code with native auth support.
100% opensource.
164
102
571
65,401
양수열(Soo yeol, Yang) retweeted

30 Apr 2025
All Docker Command Essentials.
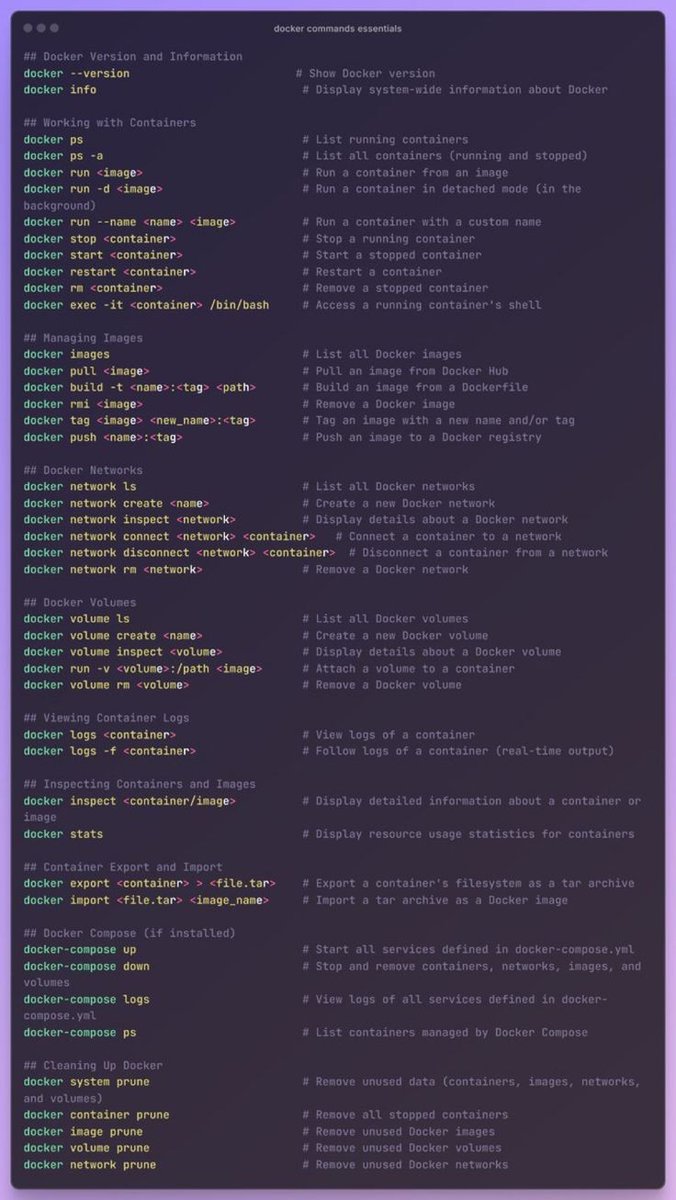
8
165
1,076
105,921
양수열(Soo yeol, Yang) retweeted

30 Apr 2025
💎 SQL Cheat Sheet
Find the HQ link inside:

4
115
759
109,466

If you're building AI agents, read this twice:
There’s a new invisible OS being written for the autonomous future. It’s built on two emerging protocols:
• Model Context Protocol (MCP)
• Agent-to-Agent Protocol (A2A)
Here’s why they’re a big deal—and why you need to care:

84
533
3,083
629,936