
Research scientist FAIR @Meta, PhD @unccs, @AdobeResearch Fellow, working on vision and language. Interned @TencentGlobal @Microsoft @MetaAI. Love🏂
Joined November 2015
- Tweets 140
- Following 290
- Followers 707
- Likes 467
19 Photos and videos





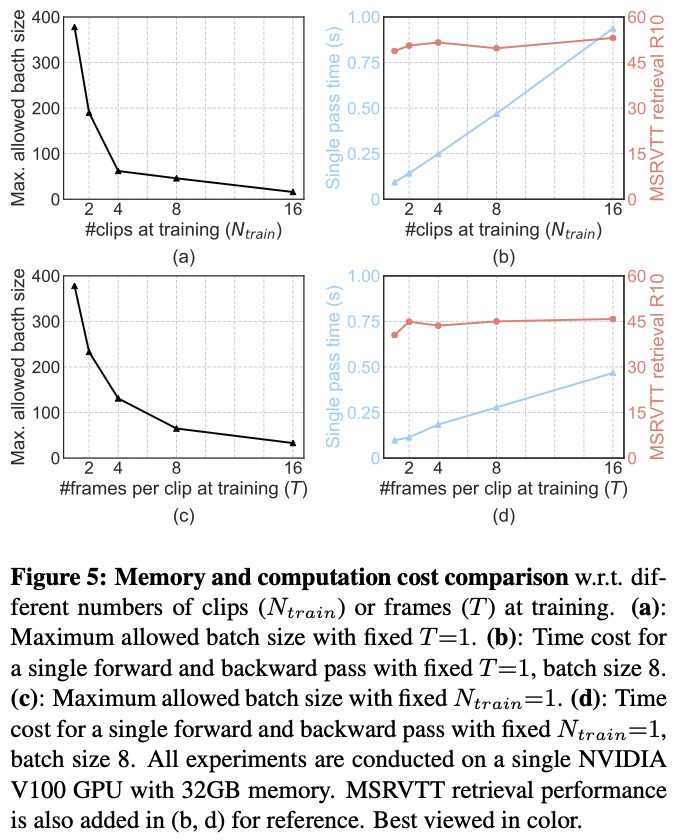




Sharing our latest work SAM 3, the most advanced model for segmenting anything in images and videos.
19 Nov 2025

Today we’re excited to unveil a new generation of Segment Anything Models:
1️⃣ SAM 3 enables detecting, segmenting and tracking of objects across images and videos, now with short text phrases and exemplar prompts.
🔗 Learn more about SAM 3: go.meta.me/591040
2️⃣ SAM 3D brings the model collection into the 3rd dimension to enable precise reconstruction of 3D objects and people from a single 2D image.
🔗 Learn more about SAM 3D: go.meta.me/305985
These models offer innovative capabilities and unique tools for developers and researchers to create, experiment and uplevel media workflows.
6
411
Jie Lei retweeted

12 Dec 2025
My team at Meta is looking for summer research interns! We develop cutting-edge perception models like SAM 3, SAM 3D and Perception Encoder. Application link:
metacareers.com/profile/job_…
(the video is SAM 3 with prompt "fish")
8
26
277
20,581
Jie Lei retweeted
5 Dec 2025
We have LM Arena for chatbots, but what about one for computer vision models? It now exists! You can blind compare and rate models side by side on vision tasks. #SAM3 is currently the top scoring and fastest model for object detection!
playground.roboflow.com/aren…
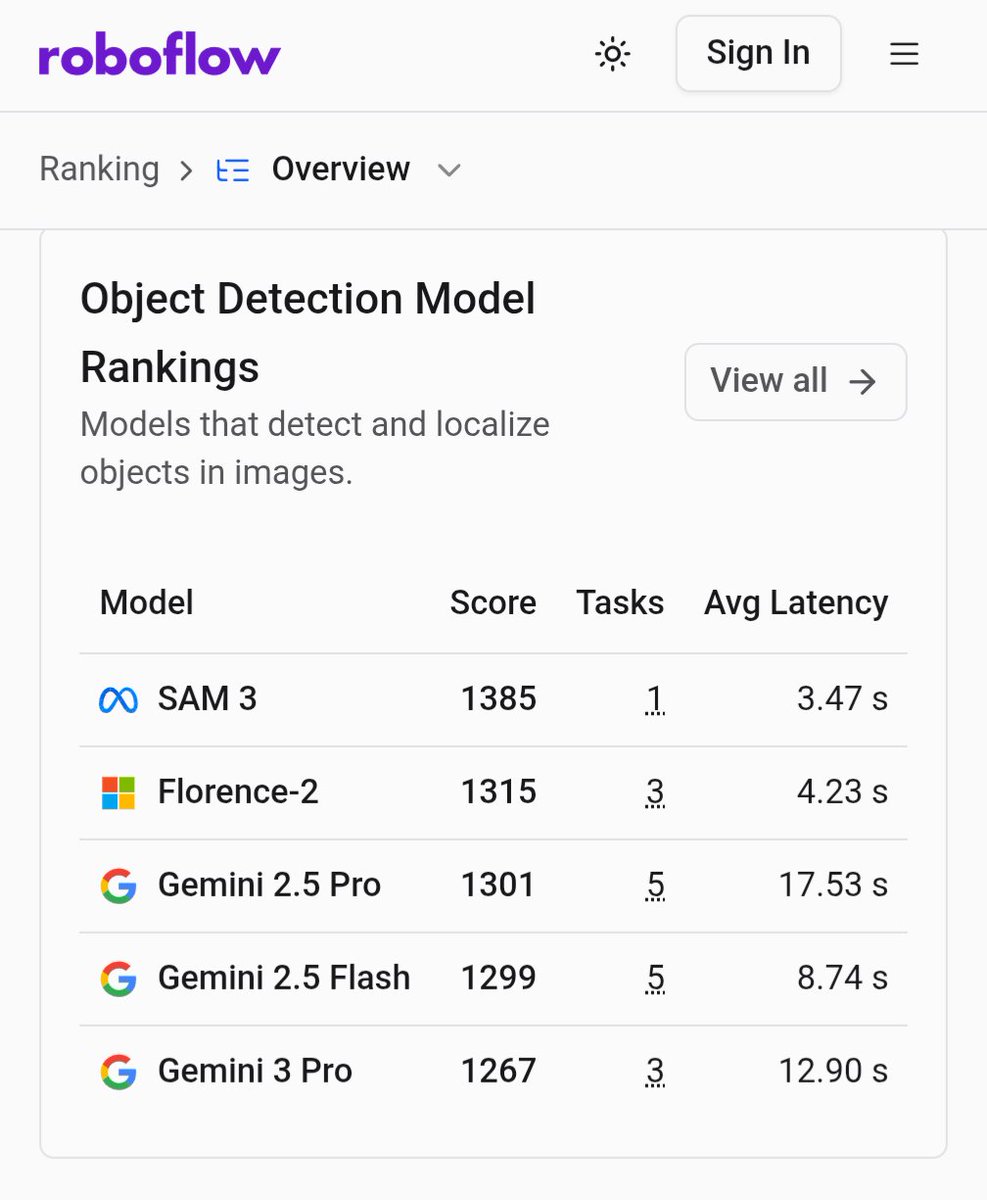
2
12
60
9,900
Jie Lei retweeted

19 Nov 2025
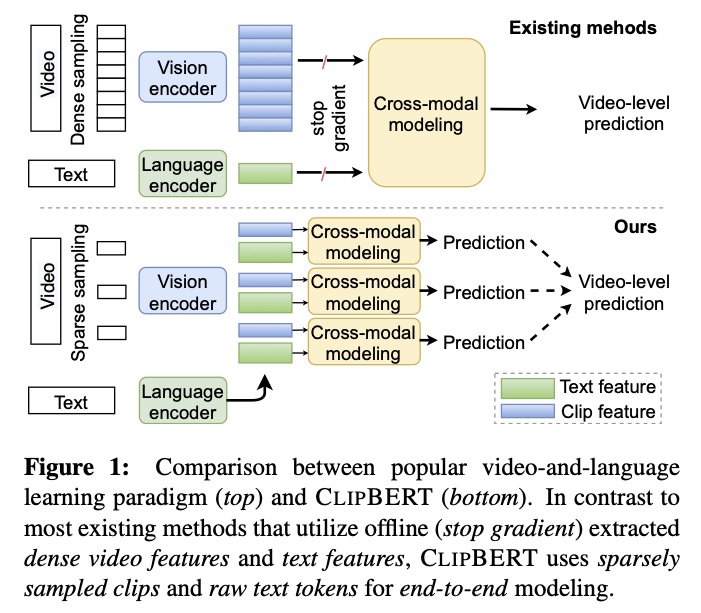
🧵Announcing Segment Anything 3! SAM 3 extends SAM 2 with open vocabulary text and exemplar prompts, enabling it to detect, segment, and track all instances of a target category in images/videos. We're releasing code, a checkpoint, an eval benchmark, & demo playground. SAM 3 will be coming soon to features in Edits, Vibes, & FB Marketplace! Deep dive below 👇
19 Nov 2025
Meet SAM 3, a unified model that enables detection, segmentation, and tracking of objects across images and videos. SAM 3 introduces some of our most highly requested features like text and exemplar prompts to segment all objects of a target category.
Learnings from SAM 3 will help power new features in Instagram Edits and Vibes, bringing advanced segmentation capabilities directly to creators.
🔗 Learn more: go.meta.me/591040
7
15
148
29,520
Jie Lei retweeted

9 Jul 2023
I am excited to join @northwesterncs as an assistant professor in Fall24 and @StanfordSVL as a postdoc with @jiajunwu_cs. I cannot say how much I appreciate the help from my advisor @elgreco_winter, references @ShihFuChang @kchonyc @JiaweiHan @kathymckeown and many many people.
37
15
378
98,725
I missed the days working with Linjie, best collaborator ever.
6 Jul 2023

I am humbled to be re-featured as Women in Computer Vision for the BEST of CVPR section of the Computer Vision News July Magazine. It was great chatting with Ralph Anzarouth. I hope my unconventional career path can encourage more female researchers. rsipvision.com/ComputerVisio…

2
5
2,093
Welcome to our tutorial @CVPR!
18 Jun 2023

Knowledge vs Large Models?
Welcome to our #CVPR23 tutorial "Knowledge-Driven Vision-Language Encoding" with
@Xudong_Lin_AI @jayleicn @mohitban47 @cvondrick @Shih-Fu Chang @elgreco_winter
Jun 19: 9:00-12:30
Loc: East 8
Website:blender.cs.illinois.edu/tuto…
Zoom:cvpr2023.thecvf.com/virtual/…

5
21
3,361
Jie Lei retweeted

11 Apr 2023
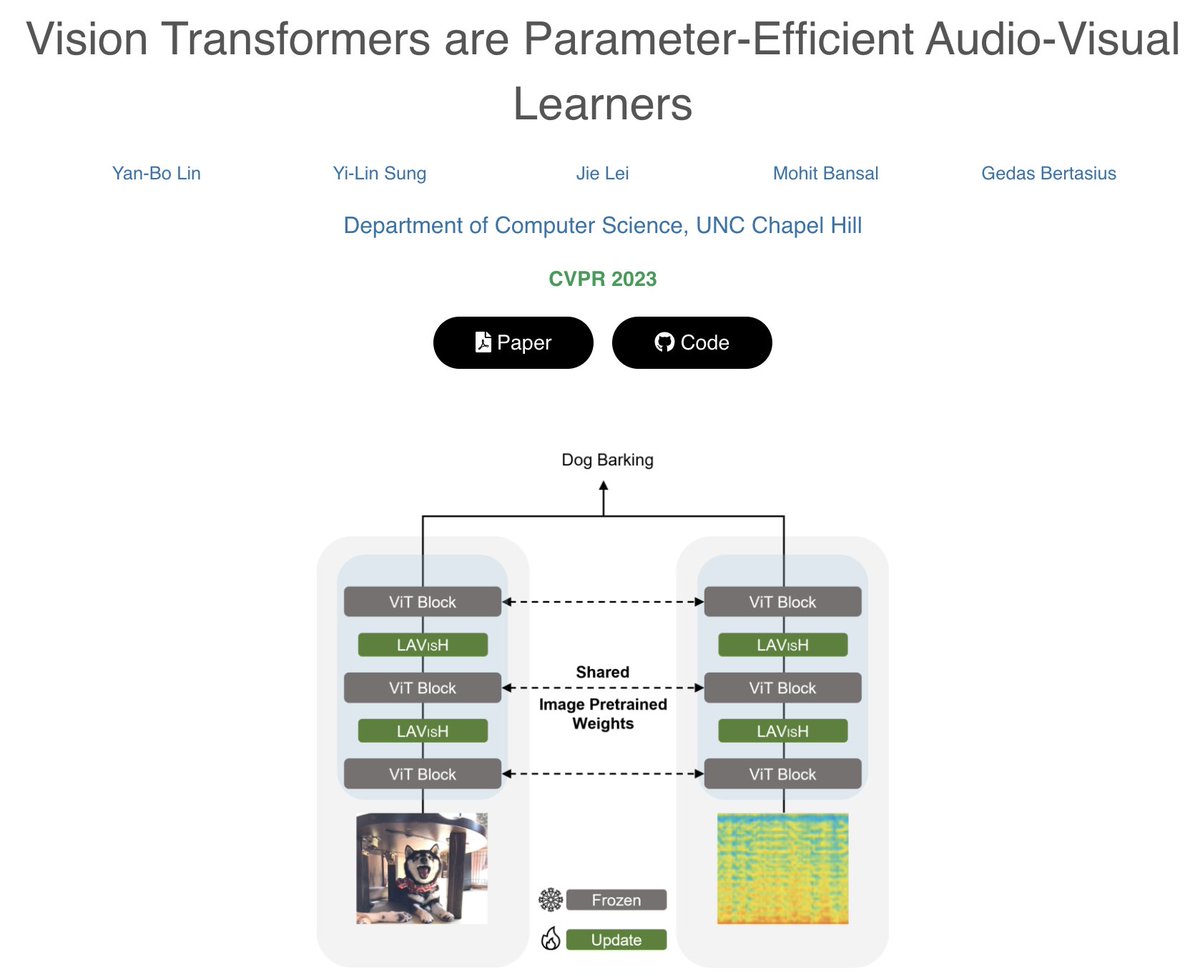
Exciting research from @UNCCS coming to #CVPR2023 shows that pretrained vision models can understand audio-visual data without audio pretraining #ComputerVision #MachineLearning
@yilin_sung @jayleicn @mohitban47 @gberta227 @CVPRConf @CVPR
7 Apr 2023

Can pretrained vision models generalize to audio-visual data without any audio pretraining? In our #CVPR2023 paper "Vision Transformers are Parameter-Efficient Audio-Visual Learners," we show that they can!
yanbo.ml/project_page/LAVISH…
w/ @yblin98 @yilin_sung @jayleicn @mohitban47
5
17
2,699
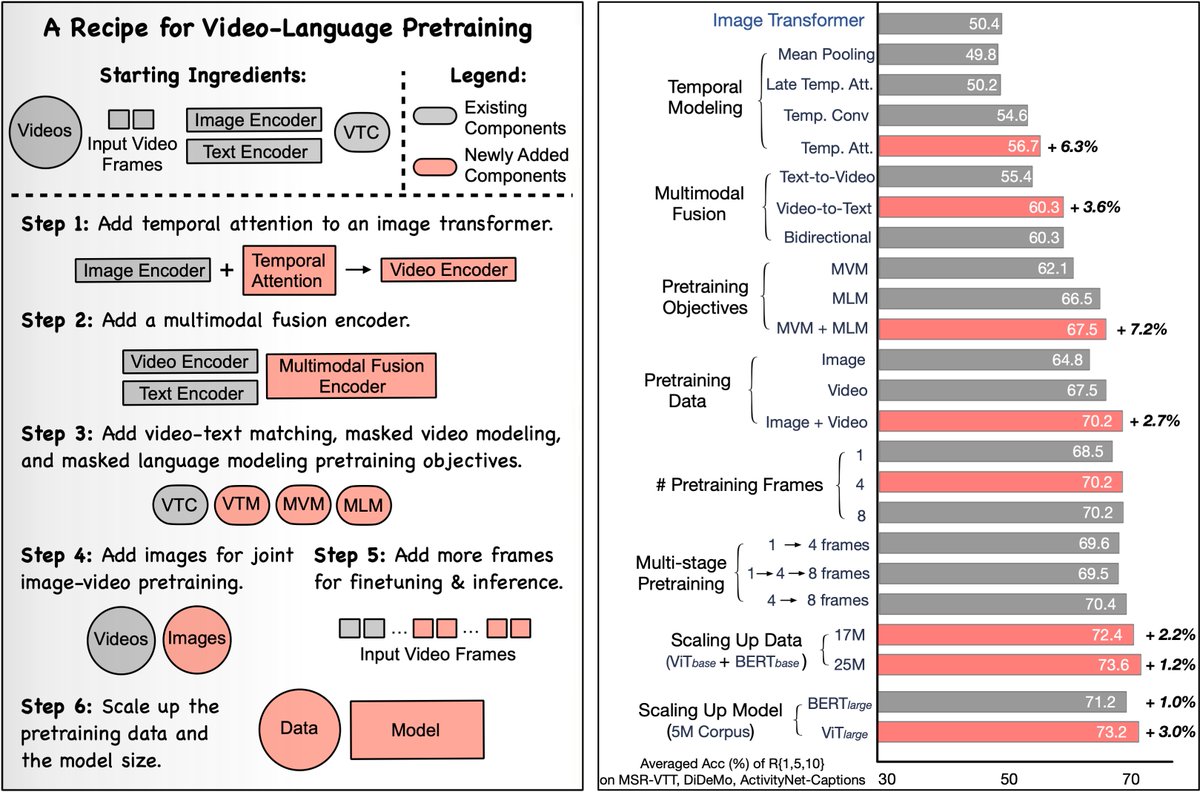
Check out our recent work studying the important factors of video-language pre-training.
6 Apr 2023
What makes modern Video-Language (VidL) perform well? Check out our #CVPR2023 paper "VindLU: A Recipe for Effective Video-and-Language Pretraining" where we demystify the most critical factors in the VidL model design.
klauscc.github.io/vindlu.htm…
@fncheng2333 @jayleicn @mohitban47
1
3
7
2,762
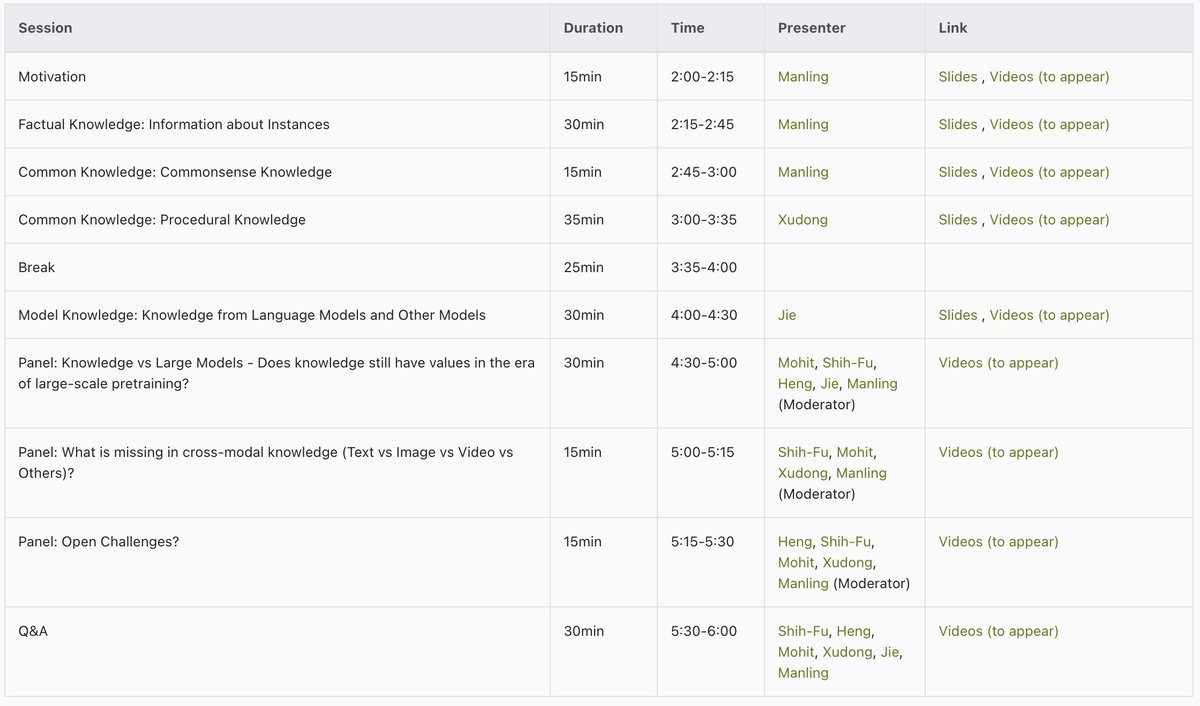
Come and join our AAAI tutorial on knowledge-driven vision-language pre-training tomorrow afternoon.
7 Feb 2023
What is the value of knowledge in the era of large-scale pretraining? Welcome to our #AAAI23 tutorial "Knowledge-Driven Vision-Language Pretraining" with @Xudong_Lin_AI @jayleicn @mohitban47 @Shih-Fu Chang @elgreco_winter
Feb 8: 2-6pm
Loc: Room 201
Zoom: underline.io/events/389/sess…
2
13
2,135
Jie Lei retweeted

21 Dec 2022
🎉🎉BIG congrats to @ZinengTang for the amazing achievement of being selected as Winner (out of 4 in North America) of the 2023 CRA Outstanding Undergraduate Researcher Award! #ProudAdvisor🙂
🚨 Zineng is applying for a PhD this year 👉 zinengtang.github.io/
@CRAtweets @unccs
1
9
52
13,361
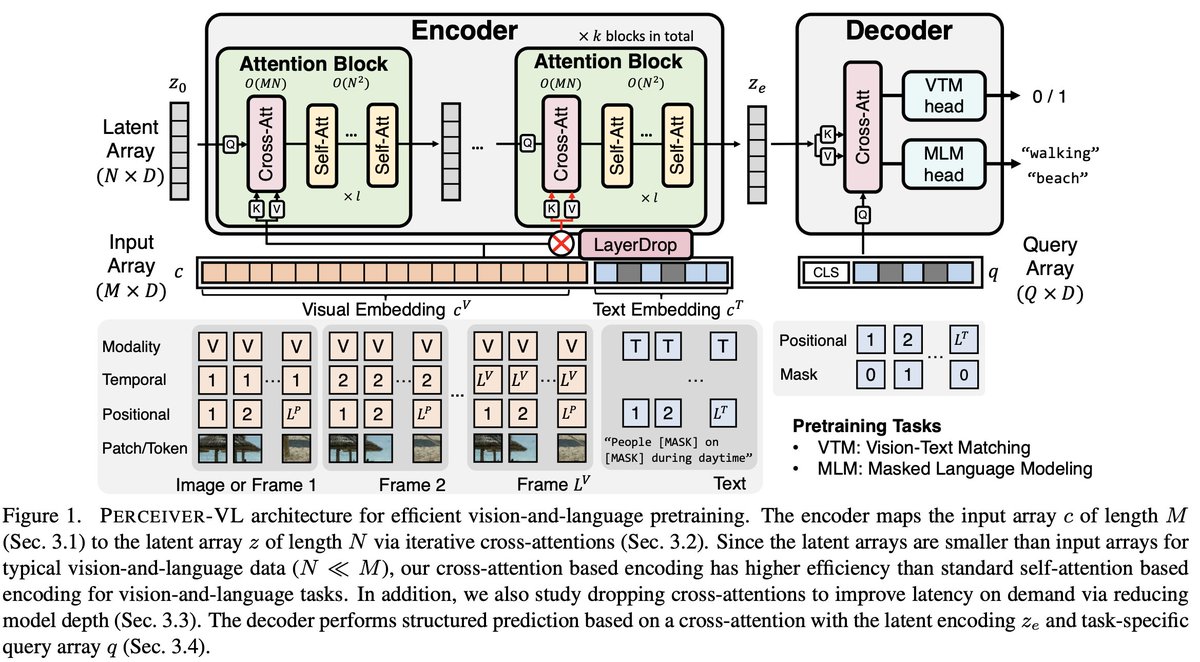
Efficient vision language learning with our Perceiver-VL.
22 Nov 2022

Self-attention for VL tasks (esp. video text) is too expensive!
Check out our #WACV2023 paper “Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention”
arxiv.org/abs/2211.11701
github.com/zinengtang/Percei…
@ZinengTang* @jmin__cho* @jayleicn @mohitban47
🧵
4
9
Jie Lei retweeted

1 Nov 2022
🎉Our LST paper was accepted to #NeurIPS2022🎉
Ladder Side-tuning achieves both memory & parameter efficiency in NLP VL tasks.
Talk video: youtube.com/watch?v=OuMIZCQ-…
Camera-ready version: arxiv.org/abs/2206.06522
We will be in New Orleans, happy to chat!
@jmin__cho @mohitban47
16 Jun 2022

Do you still get Out-of-Memory error even when you've saved >95% params w. adapter/prompt-tuning? Try Ladder Side-Tuning (LST 🪜) for both Parameter & Memory Efficient Transfer Learning (in NLP VL tasks)!
arxiv.org/abs/2206.06522
github.com/ylsung/Ladder-Sid…
@jmin__cho @mohitban47
🧵
1
13
40
Static frame-level info LLM = a strong few-shot video captioner.
25 May 2022

Can GPT-3 understand videos? Glad to share our new work VidIL on prompting LLMs to understand videos using image descriptors (frame caption visual token). We show strong few-shot video-to-text generation ability WITHOUT the need to train on ANY videos: arxiv.org/abs/2205.10747
2
25
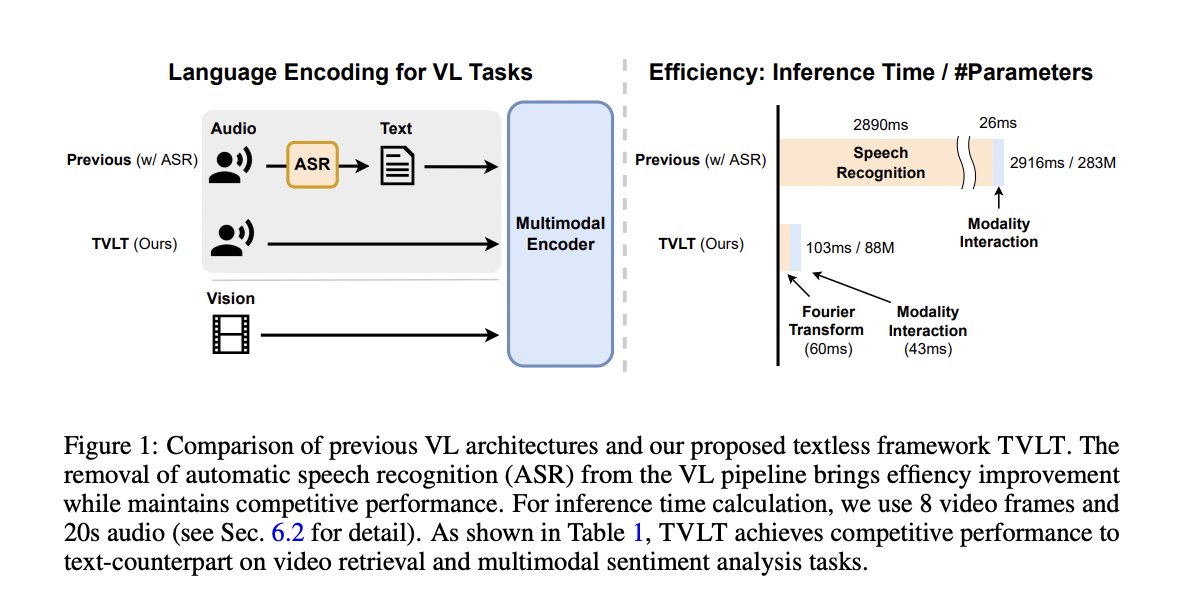
Neat idea - directly using audio and video signals for learning vision language models.

TVLT: Textless Vision-Language Transformer
abs: arxiv.org/abs/2209.14156
github: github.com/zinengtang/TVLT
5
12
Check out our #ECCV2022 oral paper on efficient long-range video retrieval using sparse frame audio.
6 Sep 2022

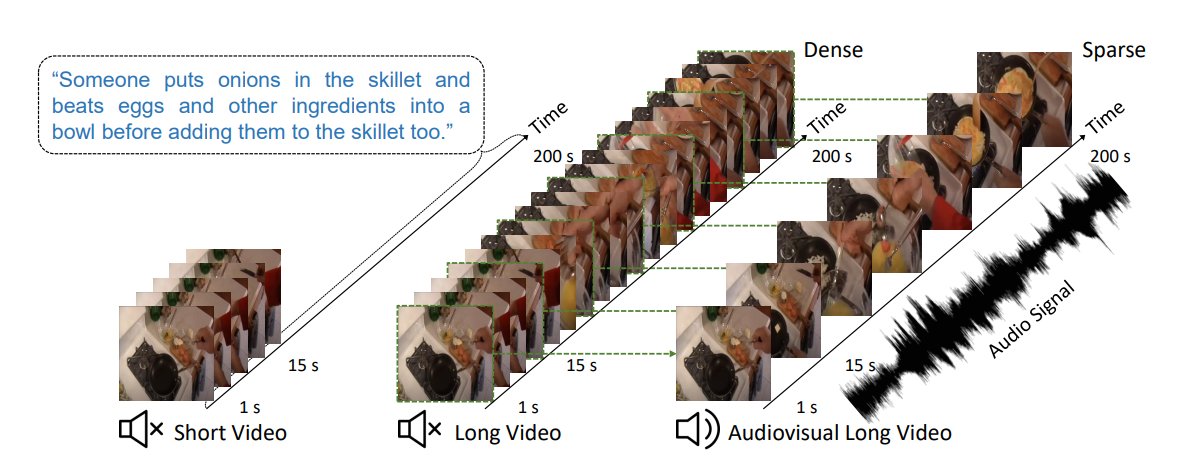
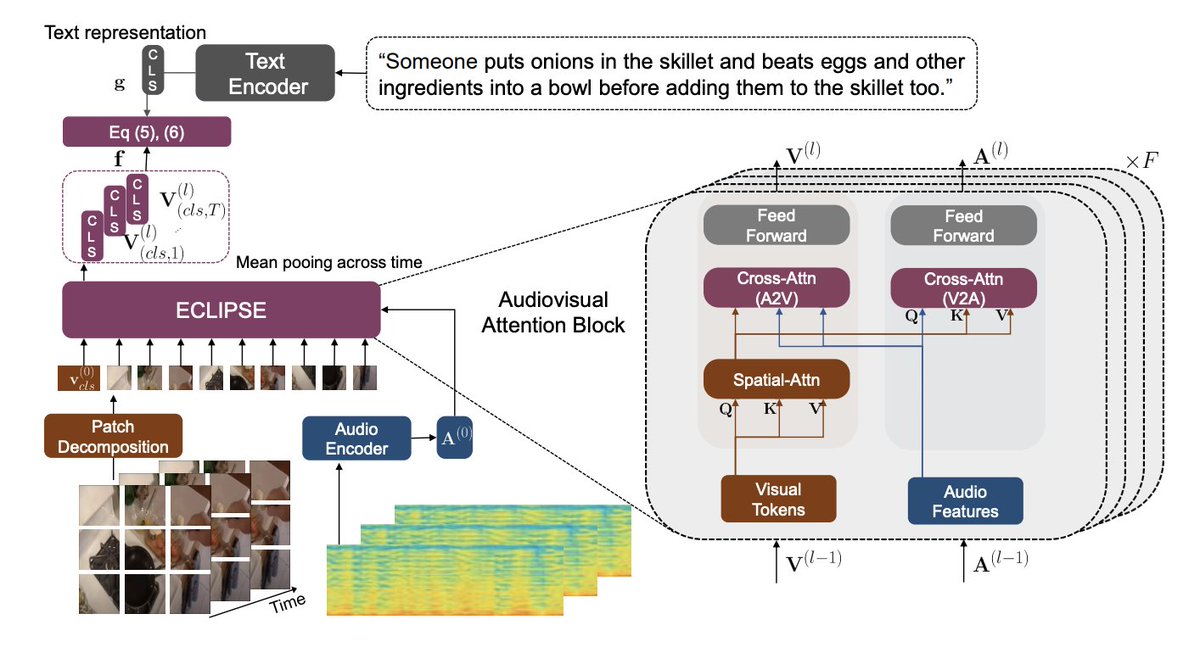
🥳🥳 Check out our #ECCV2022 oral paper. We propose ECLIPSE 🌒 that integrates audio🔊🎵 into popular CLIP to have 2.92x faster and 2.34x memory-efficient for long-range video retrieval.
arxiv.org/abs/2204.02874
yanbo.ml/project_page/eclips…
w. @jayleicn @mohitban47 @gberta227
🧵👇
4
19
Jie Lei retweeted
25 Jul 2022
🎉🎓Congrats to awesome new old graduates: PhDs @lbauer119 @khsquared @jayleicn @easonnie ( @haotan5 who graduated last yr w. @ramakanth1729, but was able to join us at @unccs this summer) & undergrad @EvaHuyn! Was fun to attend in-person hooding celebration photo sessions😀




3
13
106
Jie Lei retweeted

4 Jul 2022
Proud of my students who went 4/4 in their paper submissions during their first year of working with me (3 #ECCV2022 1 #ACMMM22). Our work this year focused on Transformer architectures for long-range multimodal video understanding. Check out an overview of each paper below.
7
13
180
Jie Lei retweeted
4 Jul 2022
1) In our first paper, we propose Efficient CLIP with Sound Encoding (ECLIPSE), for long-range video retrieval. We show that audio can replace the costly video modality, making our model fast and memory-efficient.
w/@yblin9527 @mohitban47 @jayleicn
Paper:arxiv.org/pdf/2204.02874.pdf
2
4
26
Jie Lei retweeted

29 Jun 2022
We have posted recordings of each talk on Bilibili, YouTube links will be added when available. Enjoy!
18 Jun 2022
Interested in Vision Language Pre-training (VLP) but do not know where to start? Hard to track the rapid progress in VLP? Come and join us at our CVPR2022 VLP tutorial on 19th Jun (9am-5pm CDT) in person in New Orleans or virtually. vlp-tutorial.github.io #CVPR2022



5
35