
Founder CRS, Open Intelligence Foundation, ReMyndAi (Move37), Protonet (YC W16) - love building great things with great people.
Joined April 2008
- Tweets 5,358
- Following 1,039
- Followers 1,250
- Likes 136,397
305 Photos and videos













True

one of the best days yet for open source
as i've said repeatedly, it's only a matter of time before a Chinese model reaches fable-level capabilities
the US has shot itself in the foot with the Mythos ban, because it will hurt Western AI innovation while doing very little to slow anyone else down
15
So many great releases/papers today!

Can a vision model learn to see with no augmentations, no masking, no cropping, no reconstruction?
🎬 It can! Introducing Temporal Difference in Vision (TDV), a new visual representation learning paradigm built on a single assumption: the past causes the future.
TL;DR :
- We introduce TDV, the first approach to learn useful representations without any augmentations, masking, cropping or pixel based reconstruction.
- TDV matches SOTA recipes like DINO and iBOT on dense spatial tasks
- We also show that as data scales up, weaker assumptions work better.
🧵Thread:

1
1
1
86
Huge!

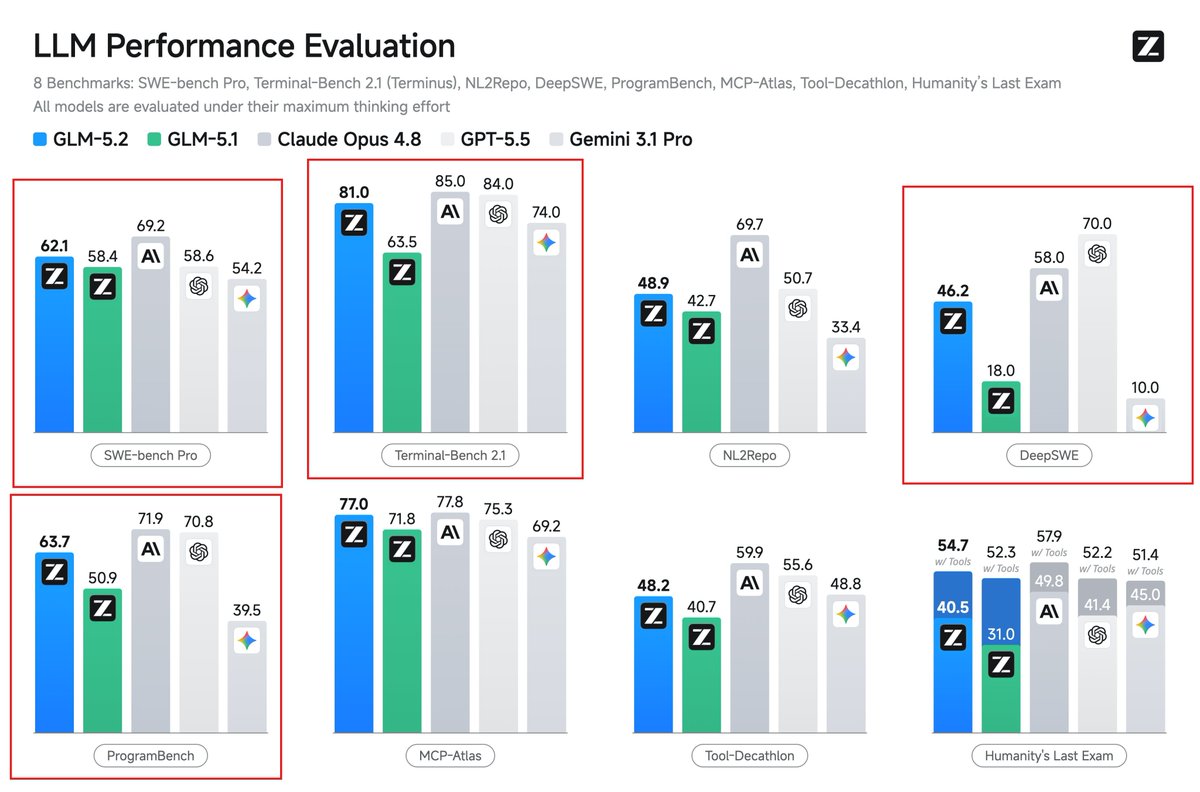
Just to be clear, if you remove Fable which is unavaialble, GLM-5.2 (Max) is the #1 model in the world for frontend coding.
This is a huge moment. OSS has caught up with proprietary, and China has caught up with the US, in this very important domain.
26
And it’s Open Weights!!!! 🔥🔥🔥
10h

GLM 5.2 ranks #3 on FrontierSWE. It is only behind Fable 5 and Opus 4.8, and it outperforms GPT-5.5.
This is the first model that closes the large gap between models from Anthropic / OpenAI and other providers, and it is the strongest open-weight model by far.
1
27
Ohhh fancy!! Next-Latent Prediction sounds like the natural next step!!

Next-token prediction is myopic. What if transformers learn to predict their own next latent state?
🌠 We present 𝗡𝗲𝘅𝘁-𝗟𝗮𝘁𝗲𝗻𝘁 𝗣𝗿𝗲𝗱𝗶𝗰𝘁𝗶𝗼𝗻 (𝗡𝗲𝘅𝘁𝗟𝗮𝘁): a self-supervised learning method that teaches transformers to form compact world models for reasoning and planning. It also unlocks up to 3.3x faster inference via self-speculative decoding! 🚀

ALT illustration of next-latent prediction vs. other predictive mechanisms
1
2
251
Love strong, small OCR models!! 🔥🔥🔥
Now praying for a one that’s faster and better than Vision on MacOS!!
17h

兄弟们,我一直有个判断:OCR 这种活,早晚会被多模态大模型给吃掉。
这周看到百度发的 PP-OCRv6,我改主意了。
一个 1.5MB 的模型,能直接塞进浏览器里跑,单图最快 97 毫秒就能出结果,逐字识别的准确率还反超了 GPT-5.5、Gemini-3.1-Pro 和 235B 参数的 Qwen3-VL,我有点震惊了!
对做产品的人来说,这比「又一个 SOTA」重要得多。我有测试,先往下看 👇

1
58

How much?? 😂🙈

Researchers at ETH Zurich have developed ANYmal, a quadruped robot that can play badminton with humans.
The robot tracks the shuttlecock, predicts its path, and moves into position to return shots.
Its control system coordinates vision, movement, and racket swings to play the game effectively.
69
Ohhhh nice!!
More and more feeling like a combo of models is going to be the future. A strong core one surrounded by more task specific slim models.
Jun 15

1/5 🚀 Thrilled to introduce AFUN: a step toward an affordance foundation model for functionality understanding. From a single RGB-D image a language instruction, AFUN predicts where to interact (a task-conditional mask) and how to interact (a 3D motion curve), and can be directly deployed on a real robot with zero fine-tuning. It generalizes across diverse environments, objects, and tasks.
Code & Weights are public.
Paper: arxiv.org/abs/2606.02551
Project page: zhaoningwang.com/AFUN
Code: github.com/EricWang12/AFUN
#Robotics #Affordance #EmbodiedAI #Manipulation #AI
1
26
😍😍😍
Jun 14

OMG THEY ARE DROPPING IT! ANTHROPIC IS SCREWED!
Scores higher than Fable in every benchmark!!

56
Love this thank you!!
Jun 14

Two PII models this weekend, opposite ends of the spectrum.
A 3.3B generative model I RL-trained (GRPO) until it emits 100% valid JSON across 20 languages, 69 entity types.
And a 33M one, 37MB, that runs a realtime privacy filter on your iPhone = MLX
Both open, Apache 2.0. 👇

1
2
6
1,189
“Open Source must win now more than ever.” Amen! Great work!! 🔥🔥🔥
Jun 14

Very proud to share that we just release Luce KVFlash. Run your preferred model inside Lucebox at 256k context, without thinking about KVCache and OOM, up to 2.9x faster decoding at long context.
Taking inspiration from OS paging and using our speculative prefill method (Luce PFlash), we managed to make KV vram usage almost constant. Offloading what is not needed dynamically.
Opensource must win now more than ever.
1
2
247
Such good news after the Fable debacle.

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

88
Amazing!!!! 😍 thank you for open sourcing this critical work!!
Jun 13

56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
61
GOAT 🐐

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
38
100% !!!
Jun 13

Anthropic pulling the plug on Fable and Mythos 5 at the direction of a government order is a massive wake-up call. 🔥
It highlights exactly why open, distributed AI matters.
When AI is centralized, access can disappear overnight.
Local models are different.
No one can revoke your access.
No one can pull the plug.
No one can take away the weights you already own.
Own your AI.
1
54
Banger 😂
Jun 13

Sound on.
Bat finding the bug using only the info of its last chirp, and the FFT of the reflections.
One cool thing about PufferLib, you can train deterministically. So I could train again, get the exact same result, and draw what the bat sees.
x.com/KinvertOG/status/20655…
1
69
That would unlock insane levels of local, open AI! 🤯
Jun 12

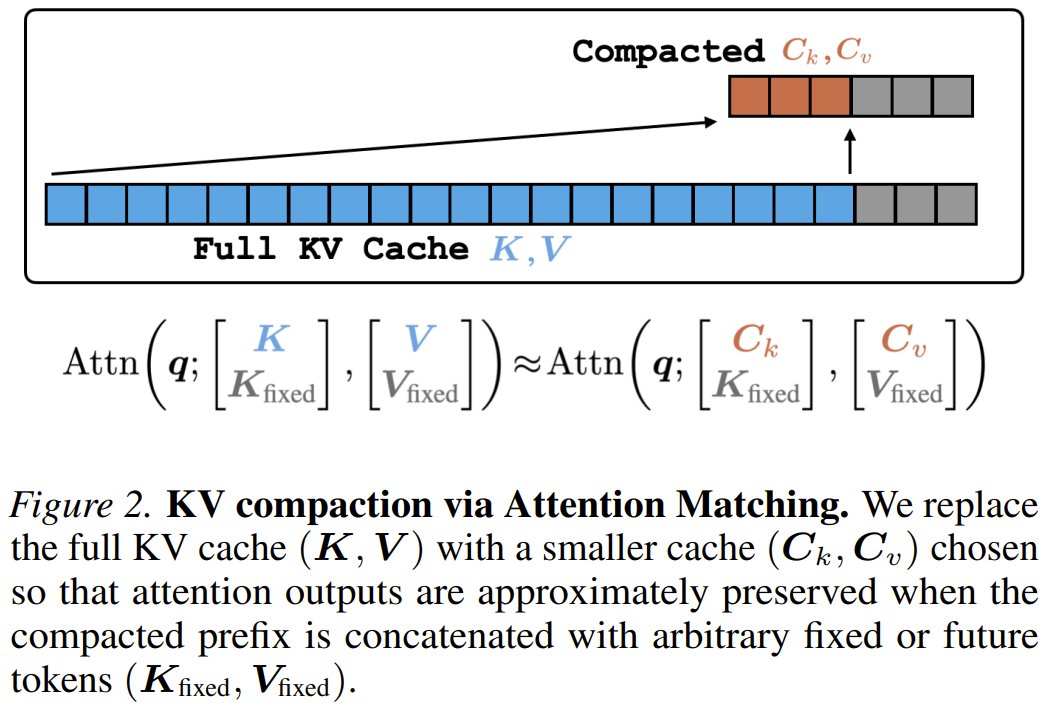
What if you could shrink a language model’s memory by 50x in seconds without losing performance?
MIT researchers present Fast KV Compaction via Attention Matching.
They build compact key-value caches in latent space that preserve attention outputs per head, avoiding slow end-to-end training.
Result: up to 50x compaction in seconds on some datasets with minimal quality loss – outperforming prior methods on the speed vs. quality tradeoff.
Fast KV Compaction via Attention Matching
Paper: arxiv.org/pdf/2602.16284
Code: github.com/adamzweiger/compa…
Our report: mp.weixin.qq.com/s/3wDmtR64s…
📬 #PapersAccepted by Jiqizhixin
53
Wow!!
Jun 11

Force is arguably the most overlooked ingredient in modern robot learning.
Introducing FACTR 2: it turns *any* commodity robot into a force-aware system with no force sensors required.
Train a tiny force network in <1min with <10mins of data and drop it into any existing teleop pipelines:
✅ Free force sensing for both the robot and the operator arm
✅ Makes demos higher-quality → fewer of them needed.
✅ A new force-aware learning algorithm (FIRST) uses those recovered forces to figure out which parts of a demo actually matter, making learning data-efficient.
✅ Strong performance on complex tasks with fewer demos and even no pretraining!
More details below.
32