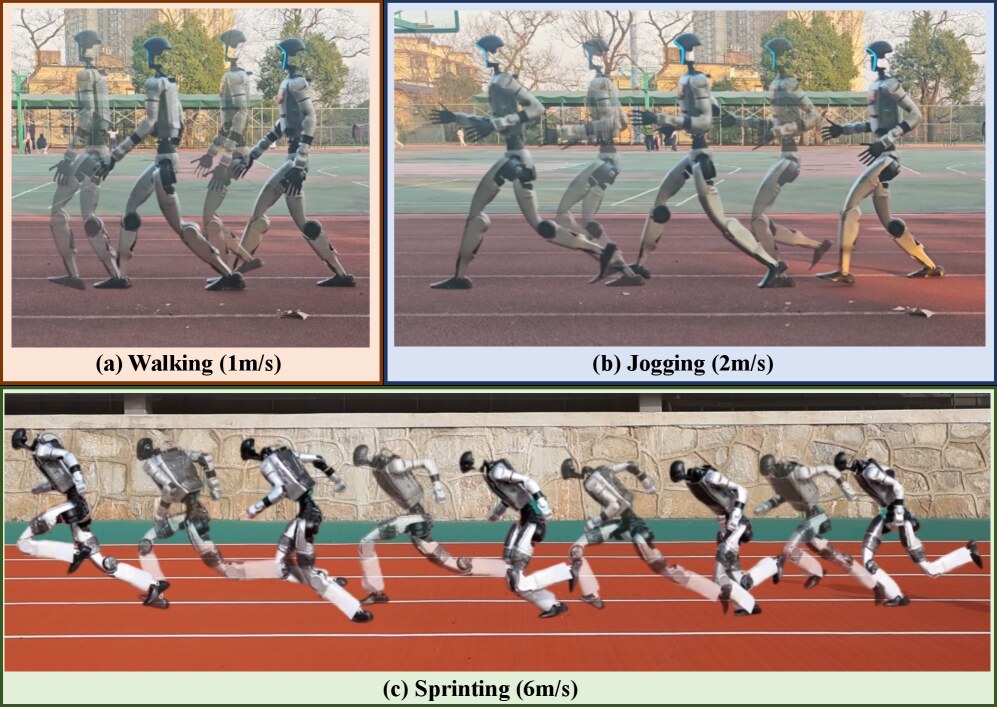
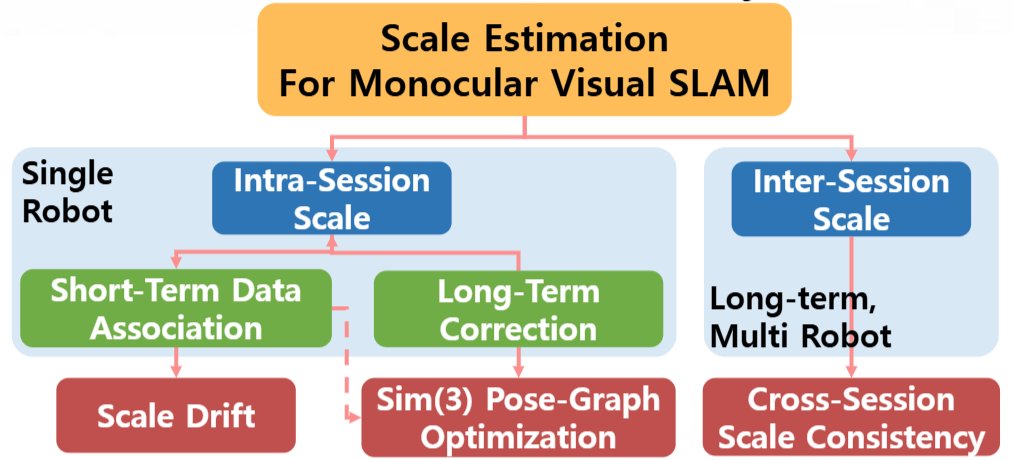
🔥#Legged_Robot_SLAM, State Estimation & Locomotion🔥Open Source Robotics / Now at URobotics, MS. EECS
- Tweets 13,671
- Following 956
- Followers 1,459
- Likes 25,590


























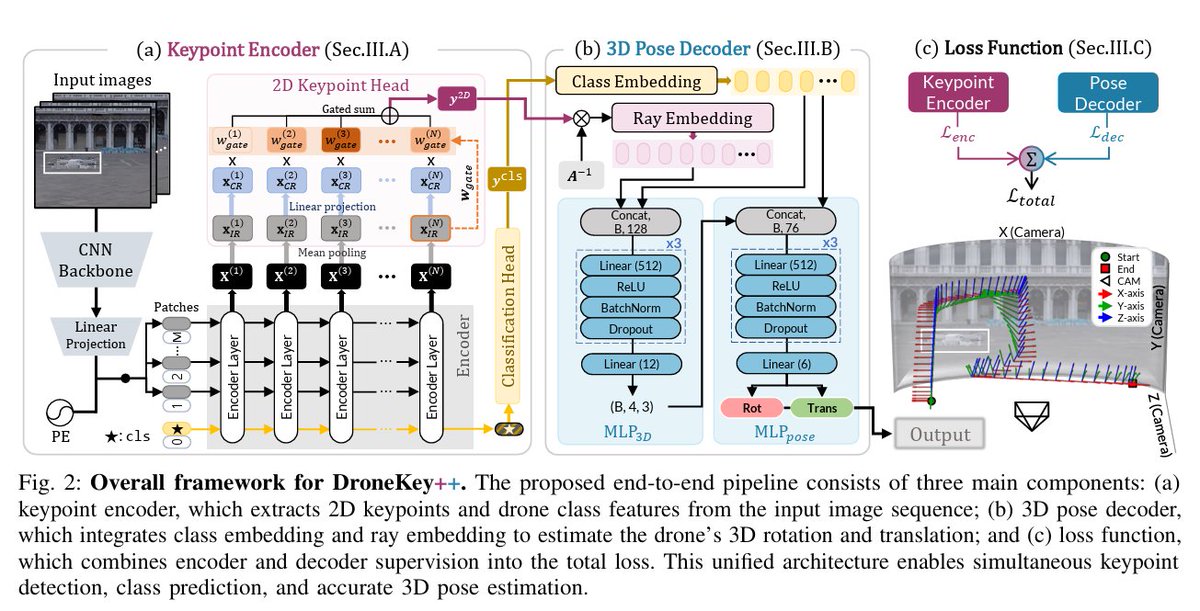
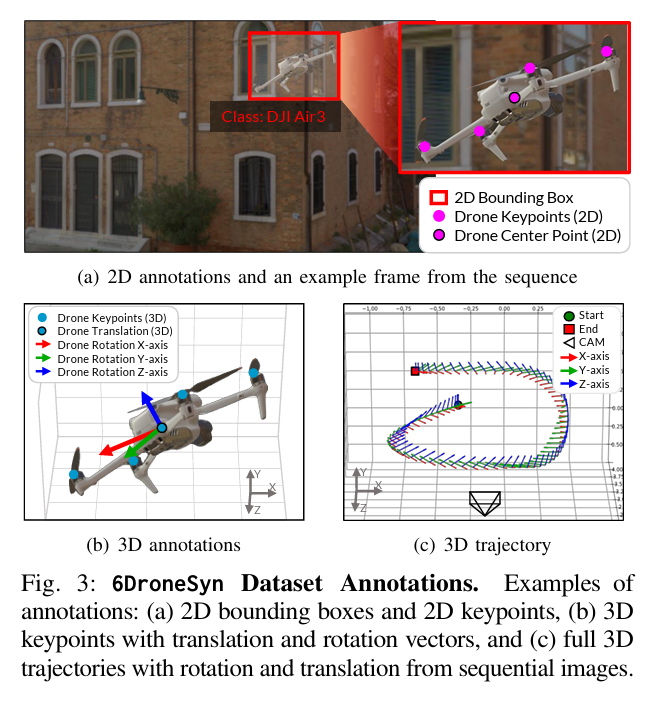
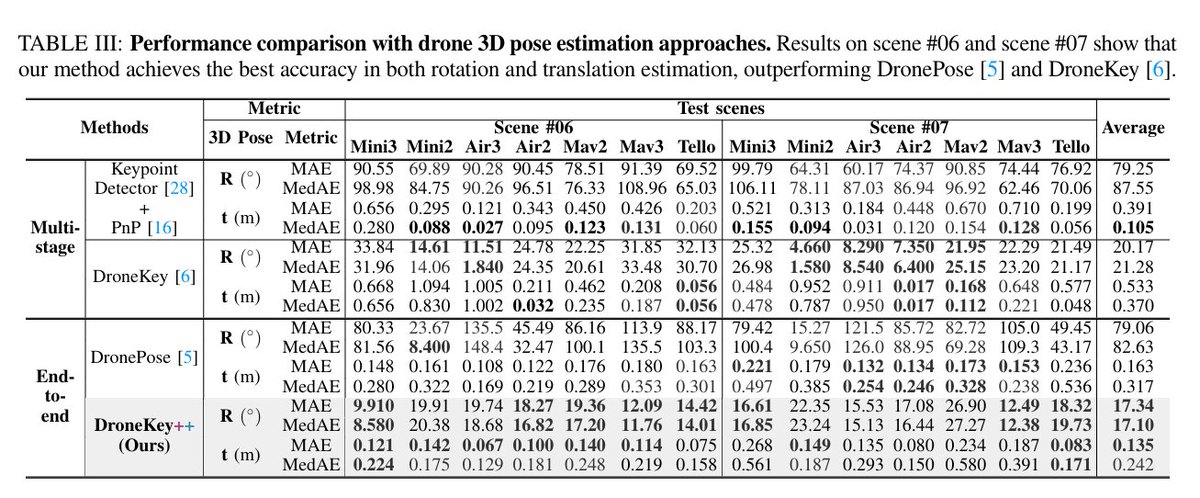
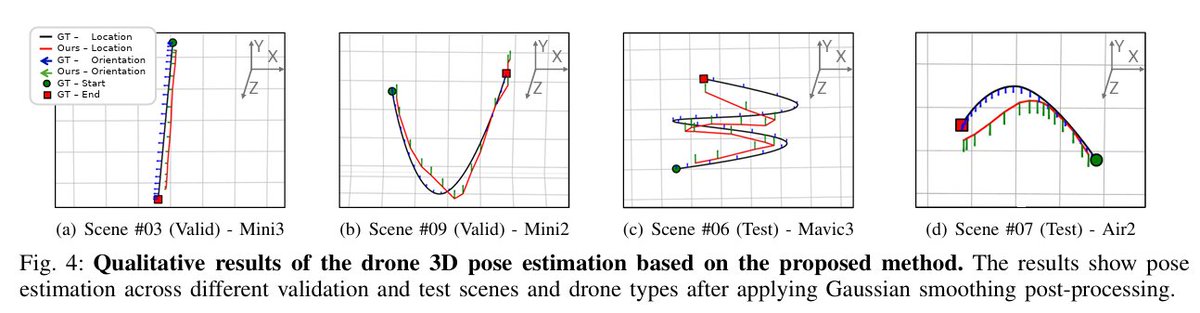






ALT Radar-Inertial Odometry (RIO) based on the Extended Kalman Filter (EKF) relies on accurate extrinsic calibration between the radar and the Inertial Measurement Unit (IMU) and is sensitive to disturbances, as large linearization errors can degrade performance or even cause divergence. To address these limitations, this letter proposes an Equivariant Filter (EqF) for RIO based on a Lie group symmetry that geometrically couples navigation states and IMU biases, extending it to incorporate radar-IMU extrinsic calibration and multi-state constraint updates. This equivariant formulation inherently preserves consistency and enhances robustness, enabling reliable state estimation even under poor or completely wrong initialization of calibration states. Real-world experiments on two different Uncrewed Aerial Vehicles (UAVs) show that the proposed EqF-RIO achieves state-of-the-art accuracy under correct extrinsic calibration and offers improved convergence under large calibration errors, where t