
Clinical IT Architect --designing the next generation EMR and health system.
- Tweets 5,084
- Following 405
- Followers 609
- Likes 637

























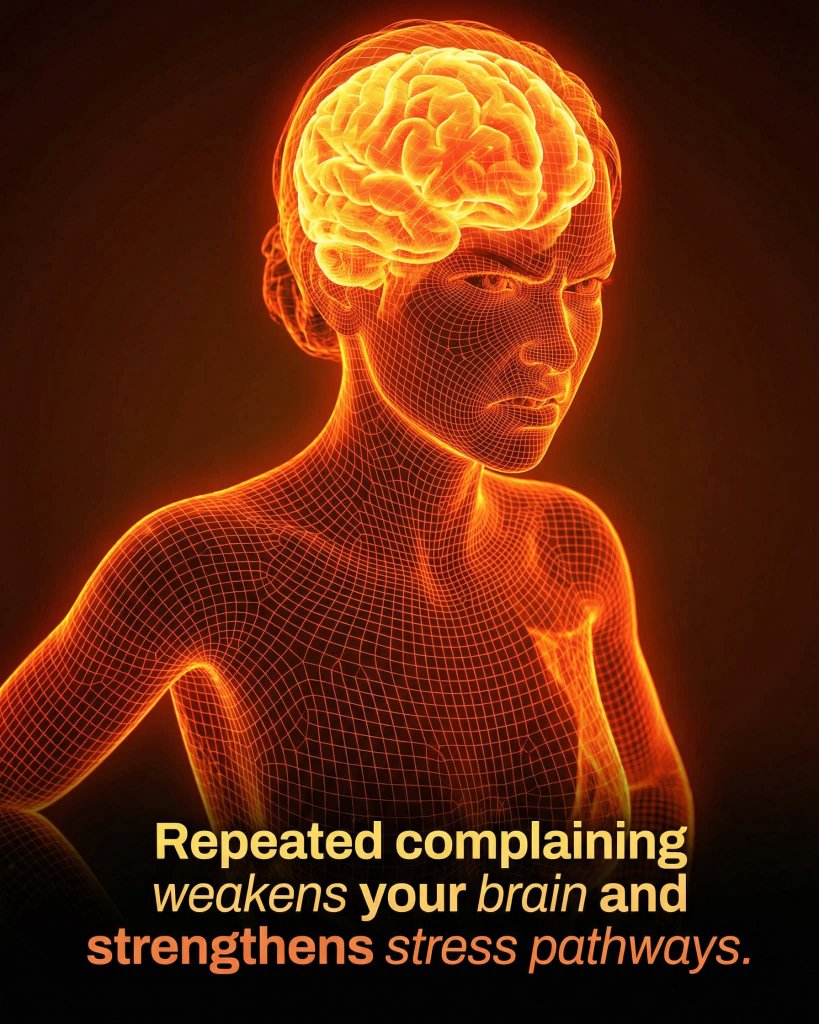
ALT Research shows chronic complaining physically rewires your brain to prioritize stress and negativity. The way we speak about our daily challenges does more than just vent frustration; it physically alters the architecture of the brain. When we engage in chronic complaining, we repeatedly activate neural networks responsible for detecting threats and processing stress. Through the biological process of neuroplasticity, these circuits become stronger and more efficient every time they are used. Essentially, the brain learns to become more adept at finding things to be unhappy about, turning a temporary mood into a permanent biological predisposition toward negativity and fear-based thinking. As these negative pathways become the brain's default setting, individuals often experience a measurable increase in baseline stress levels and emotional volatility. This heightened sensitivity means that even minor inconveniences can trigger an intense stress response.


















ALT A promotional image with the text 'REGISTER NOW' encouraging viewers to sign up for an event or service
