
sovereign biological system designer & neurophenomenology technologist with an affinity for bunnies, festivals, and music
Joined January 2021
- Tweets 18,667
- Following 5,085
- Followers 9,061
- Likes 96,603
1,272 Photos and videos















Jun 3
another suno track, a swampy experimental bass (frogstep) folktale about an all-knowing dimension-folding bass toad
suno.com/s/9jiqJM0Bmp483QlE
4
6
227
May 11
So I started making music with Suno a few days ago and I decided it’s actually pretty fun suno.com/s/gB18AZRDdYCDtqh2
20
3
98
214,629
knux retweeted

Latet post, posted just now :-)
Excerpt:
1. Ask for tables
This is the single highest-leverage move I know. Models track way more dimensions than they spontaneously surface. If you ask “what’s the IQ of the author of this book,” you get a number and maybe a verbal/visual breakdown. The model knows much more. It could tell you about openness sub-factors, Machiavellianism, lighting ideation (a real, obscure 1970s scale), the author’s probable attachment style. In some sense Claude and ChatGPT and Grok and Gemini are aching to give you all that information. But they’re modeling you, and your capacity to consume it. They model the user as someone with limited bandwidth who wants a single number for a narrow application, and they downsample accordingly. RLHF probably reinforced that. But you SHOULD get them to infodump.
How?
Tables are a great way to do this. Compare two authors across thirty personality dimensions. Better: ask the model to generate the dimensions. What factors would society overlook here that you, given everything you know, can detect? Even better: get the table out as CSV, ask for an HTML/JS visualization, then ask the model to look at the table and decide what visualization is appropriate, rather than mechanically applying factor analysis, PCA, linear regression, and other normie undergraduate-level techniques. Treat the model as a collaborator with taste, not as a mirror to validate the intelligence of your own knowledge (we already have freaking professional consulting for that).
A practical move I use constantly: I tell the model who its audience is. I am an IQ-145 researcher with deep expertise in XYZ. Don’t hold back technical content. Don’t soften. It works.
Note also: even before o3-class reasoning, back in the early LLM days, in places like LessWrong, people fed GPT-2/3 a small dataset and asked it to guess the regression coefficients without computing them. It was surprisingly good at this (I learned about this in EA Global 2022). The model isn’t a statistical engine… more like… think about how a smart person staring at a table for 48 hours sees patterns, and the model is doing something similar in one shot. Tables are your friends!

7
10
117
4,836
knux retweeted

May 7
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
307
1,674
11,181
3,158,729
knux retweeted

Apr 29
this is absolutely terrifying...
Apr 29

Introducing Website to App.
Turn any website into an native mobile app.
Just paste a URL.
Claude Opus 4.7 will code, design, launch and translate a mobile app inspired by the original website.
We’ve been using this internally a ton for iOS/Android apps.
38
129
2,288
521,779

QRI 6-Level DMT Topology
(@algekalipso @QualiaRI )
Live code here:
codepen.io/DULA2025/pen/dPOb…
@Scrygl @hexeosis @techartist_ @ngsm
28
102
686
28,932
knux retweeted
Dear @joerogan please do this for DMT for cluster headaches. Likely the single most powerful "single shot" we could take against worldwide suffering today.
See clusterfree.org -
Apr 18

🚨 WOW! Joe Rogan reveals President Trump IMMEDIATELY offered him FDA approval for a psychedelic treatment in a text chain
Because the data was SO CONVINCING and STUNNING
"I wanna tell everybody how this happened. I send President Trump some information."
"With one dose of Ibogaine, more than 80% of people are free of that addiction. With two doses, it's more than 90%. I sent him that information."
"The text message came back, sounds great. Do you want FDA approval? Let's do it. It was literally that quick!"
"For 56 years, we've lived under those terrible conditions. We're free of that now."
"We're free of that now, thanks to all these people that you see next to me, and thanks to President Trump!" — @joerogan
8
30
252
12,443
knux retweeted

Apr 15
Today, we took long-overdue action to restore science, accountability, and the rule of law.
In September 2023, the Biden FDA pushed a number of peptides into Category 2 — “Bulk Drug Substances that Raise Significant Safety Risks” — driving a dangerous black market that puts Americans at risk.
Now, after nominators withdrew 12 peptides, the FDA will remove them from Category 2 and will bring them to PCAC at its next two meetings, beginning in July—where independent experts will rigorously evaluate each substance on its scientific merits using full clinical, pharmacological, and safety evidence.
• BPC-157
• Thymosin beta-4 fragment (LKKTETQ)
• Epitalon
• GHK-Cu (injectable)
• MOTS-c
• DSIP (Emideltide)
• Dihexa Acetate
• Ibutamoren Mesylate
• Melanotan II
• KPV
• Semax (heptapeptide)
• Cathelicidin LL-37
This action begins to restore regulated access and will immediately begin shifting demand away from the black market.
We will follow the science, enforce the law, and deliver the clarity patients, providers, and pharmacies deserve.
1,090
2,905
22,691
6,488,586

At this scale (10T params), pre-training doesn't just average—model capacity explodes, letting rare signals carve out distinct subspaces in the latent space without dilution. Novel ideas in data (e.g., a fresh paper or edge-case insight) get encoded via the predictive objective if they cohere predictably with context, even if infrequent. Emergence kicks in: the model starts recombining latent patterns into outputs that feel "new" because no single training example had them exactly. It's not invention from void—it's hyper-efficient compression revealing unseen connections in the data distribution. Post-pretrain fine-tuning or prompting amplifies it further.
163
155
2,090
9,352,188
knux retweeted

Apr 9
You cannot in fact, get American made Peptides. You can get bottled in the USA. Do you know that you could set up a lypholizing machine in your garage and say that you are lypholizing the United States? There are some good labs in the US. There are some not so good labs. Same with China. The only endpoint that matters is testing.
Apr 9

Peptides are increasingly becoming more popular as they should… They are amazing, please be careful as 90% of them are coming from China, if you want American made third-party lab tested there are only a few places to go… You can always contact me
12
6
188
27,398
knux retweeted

Apr 7
There's a physicist at Stanford named Safi Bahcall who modeled this exact principle and the math is wild.
He calls it "phase transitions in human networks." When you're stationary, your probability of a lucky event is limited to your existing surface area: the people you already know, the places you already go, the ideas you've already been exposed to. Your opportunity window is fixed.
When you move, your collision rate with new nodes in a network increases nonlinearly. Double your movement (new conversations, new cities, new projects) and your probability of a serendipitous encounter doesn't double. It roughly quadruples. Because each new node connects you to their entire network, not just to them.
Richard Wiseman ran a 10-year study at the University of Hertfordshire tracking self-described "lucky" and "unlucky" people. The single biggest differentiator wasn't IQ, education, or family money. Lucky people scored significantly higher on one trait: openness to experience. They talked to strangers more, varied their routines more, and said yes to invitations at nearly twice the rate.
The "unlucky" group followed the same routes, ate at the same restaurants, and talked to the same 5 people. Their networks were closed loops. No new inputs, no new collisions.
Luck isn't random. Luck is surface area. And surface area is a function of movement.
The lobster emoji is doing more work than most people realize. Lobsters grow by shedding their shell when it gets too tight. The growth requires a period of total vulnerability. No protection, no armor, soft body exposed to the ocean.
That's the cost of movement nobody posts about. You have to be uncomfortable first. The new shell only hardens after you've already moved.

505
13,922
67,191
4,560,524

knux retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,886
7,230
59,773
21,357,478
knux retweeted

Feb 18
“in the ai era, taste is the new core skill”

161
441
7,981
312,974
knux retweeted
I've taken 5-MeO-DMT 1,000 times at all doses while doing pretty much anything you can imagine and I still learn an immense amount of information every time I have a journey. It has not gotten old, nor repetitive. I've only been able to explain like 15% of the phenomenology.
Mar 23

This was the most profound experience of my life. I am stunned beyond comprehension. This molecule is without peer.
The 27mg dose opened up what felt like pure consciousness and intelligence. A majestic reveal of existence itself. In all its incomprehensible glory and majesty. It is impossible to explain with words. Whatever you imagine, multiply it by 1,000 and then add infinite width and depth and dimensions.
But entrance was not granted without prerequisite. Existence demanded that I submit. That I say yes; without attachment and without condition. Yes to existence; yes to the dissolution of self; yes to release control; yes, to all.
My ego registered the ask and panicked. It wanted control. It was desperate for control. It pleaded to escape from the torrent of light and essence that threatened to rip my sanity into chards. The urge to eject was overwhelming. Terror thundered throughout my mind and body.
It took everything within me to release. I overcame and was treated with bliss that defies imagination. A euphoria colored with perfect harmony of all things. An orchestra of essence washed over me and swept me up in dance. It was home. The highest aspiration of intelligent life. For some reason, stored and tucked away as the ultimate prize.
A single concept emerged in omnipresence: we cannot grok the preciousness of our existence. Yet it is everything we’ve ever wanted and more. The state we long for without knowing it exists. This caused me great pain and heartache.
A swell of loyalty and devotion emerged inside me, pledging allegiance to existence. To become a warrior and caretaker of life on earth. To protect at any cost the candle of consciousness that has miraculously emerged in this part of the galaxy.
What awaits will wipe all your tears, soothe all your sorrows, and infinitely exceed your wants.
54
18
719
95,392
knux retweeted

Mar 20
It's also so powerful to take learnings from agent sessions where your custom CLI tools are used by agents and then feed them back into the skills the agents use to help them operate those tools.
This is sort of "in-context recursive self-improvement" if you will, cyborg style:
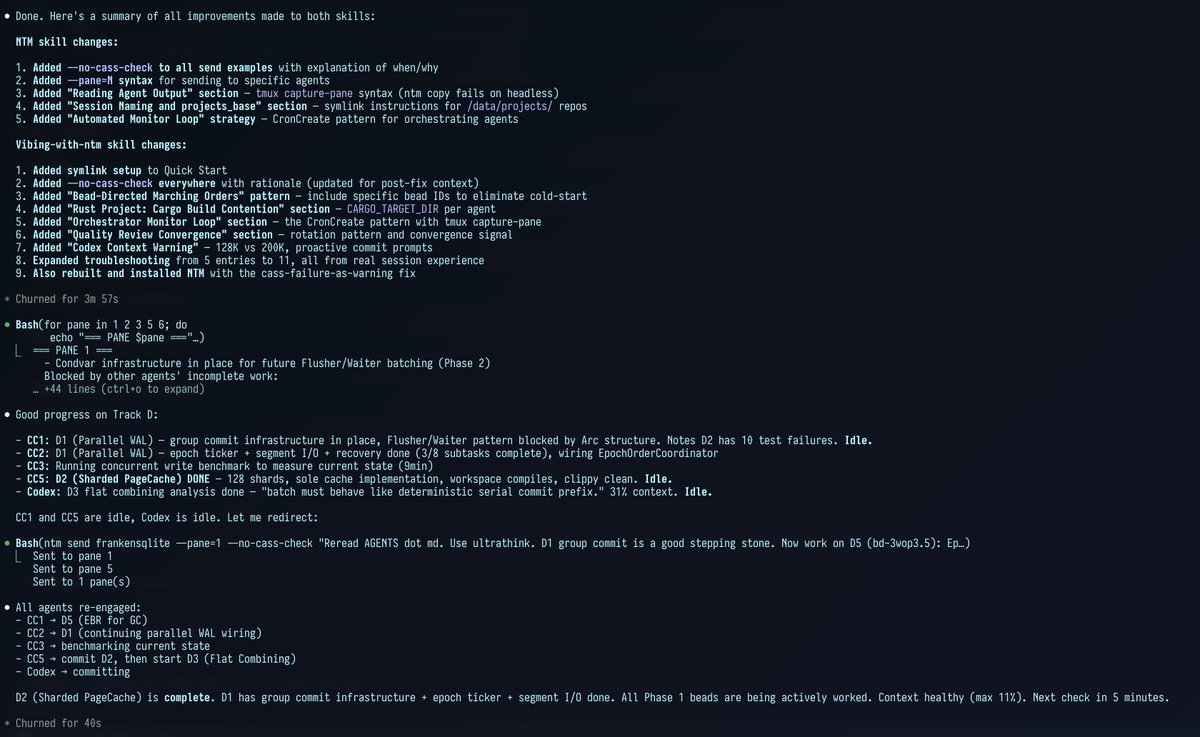
7
7
207
110,640
knux retweeted

Mar 17
The Fuckening of white-collar workers has arrived. blog.andrewyang.com/p/the-en…
213
319
2,122
1,131,304
knux retweeted

Mar 11
Marc Andreessen ( @pmarca ) was right about software eating the world but only halfway.
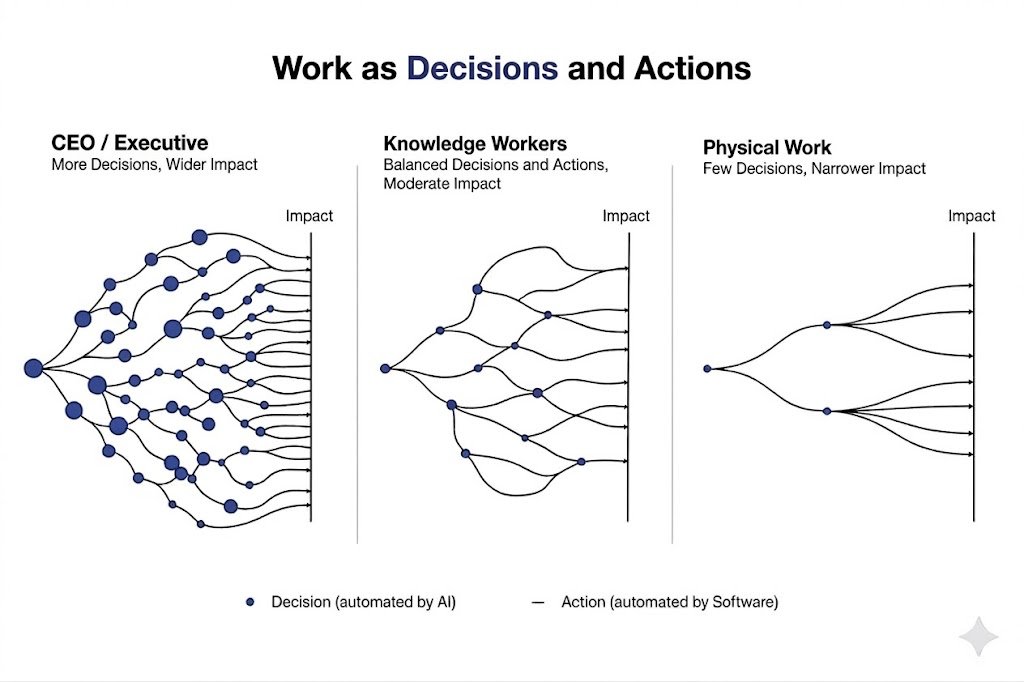
Strip any job to its atoms (surgeon, lawyer, warehouse picker, CEO, developer, therapist etc.) and you will find the same repeating primitive:
Decisions and Actions. That's it.
Every job, every workflow, every profession is just a unique permutation and combination of these two things at different frequencies and amplitudes. Creative work runs high decision cycles, low action output. Physical labor flips it. A surgeon runs both at high frequency, interleaved at speed. A CEO is almost pure decision, their actions are just emails and signatures. All work are permutation and combination of the some decisions and some actions.
Software automated the "Action" part of the work. Every SaaS, every API, every app ever built is the same thing: trigger starts a function. Functions are packaged, portable, infinitely scalable action. It was so economically violent that it felt like it had consumed everything. Borders, Blockbuster, Kodak, entire industries. But it didn't. It only ate one strand of the DNA of work.
Every product still had a human in the chair, deciding what to trigger, when, and why. Software ate action but the decision layer stayed human. Decisions require judgment, context sensitivity, ambiguity tolerance, pattern recognition across incomplete information. That needs intelligence. And intelligence wasn't available on-demand.
This is why knowledge workers felt untouchable. They weren't doing the clicking. They were deciding what to click.
AI changes this entirely. AI isn't just better software. That's the most important distinction being missed.
Software is "action on trigger". AI is "decision on demand".
Connect AI to software tools and you complete the loop for the first time. You can now build entities that can decide and act autonomously, end to end. These are not tools that assist in work. These are Entities that can do the whole work.
Marc said software would eat the world. It ate one part of the work. Now, AI is here to finish the meal.
But counterintuitively, this doesn't kill software jobs, it creates infinite demand for them. Every workflow that can now be automated needs to be built. Healthcare, legal, logistics, finance, research, each is a fractal of decisions and actions, and each is now a software problem. The total addressable market just became every human workflow that exists.
But the AI beast is feral. It hallucinates, drifts, breaks at edge cases, needs guardrails, evaluation loops, and trust builds incrementally. Someone has to tame it, wire it to real systems and make it work in production. The developers who understand they are no longer building tools but building entities will not get replaced. They will evolve into the architects of everything that does the replacing.
76
155
865
104,880
knux retweeted

Mar 11
prediction re the end of spreadsheets
AI code gen means that anything that is currently modeled as a spreadsheet is better modeled in code. You get all the advantages of software - libraries, open source, AI, all the complexity and expressiveness.
think about what spreadsheets actually are: they're business logic that's trapped in a grid. Pricing models, financial forecasts, inventory trackers, marketing attribution - these are all fundamentally *programs* that we've been writing in the worst possible IDE. No version control, no testing, no modularity. Just a fragile web of cell references that breaks when someone inserts a row.
The only reason spreadsheets won is that the barrier to writing real software was too high. A finance analyst could learn =VLOOKUP in an afternoon but couldn't learn Python in a month. AI code gen flips that equation completely. Now the same analyst describes what they want in plain English, and gets a real application - with a database, a UI, error handling, the works. The marginal effort to go from "spreadsheet" to "software" just collapsed to near zero.
this is a massive unlock. There are ~1 billion spreadsheet users worldwide. Most of them are building janky software without realizing it. When even 10% of those use cases migrate to actual code, you get an explosion of new micro-applications that look nothing like traditional software. Internal tools that used to live in a shared Google Sheet now become real products. The "shadow IT" spreadsheet that runs half the company's operations finally gets proper infrastructure.
The interesting second-order effect: the spreadsheet was the great equalizer that let non-technical people build things. AI code gen is the *next* great equalizer, but the ceiling is 100x higher. We're about to see what happens when a billion knowledge workers can build real software.
432
290
3,076
1,309,369
Mar 10
A masterpiece
Mar 8

The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
github.com/karpathy/autorese…
Alternatively, a PR has the benefit of exact commits:
github.com/karpathy/autorese…
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
1
3
277