
しがないフリーランスエンジニア。zennのscrapに生息。競馬好き。
Joined February 2013
- Tweets 22,077
- Following 560
- Followers 1,279
- Likes 12,771
1,530 Photos and videos







kun432🇯🇵 retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

641
1,638
13,949
5,342,587


Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
339
958
8,026
2,116,250
kun432🇯🇵 retweeted

Jun 13
Thanks for all the feedback. GLM-5.2 will begin rolling out to all Coding Plan users in 3 hours.
Jun 13

Help us shape the next GLM release: what should we prioritize most?
134
115
1,771
286,325

kun432🇯🇵 retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


617
1,631
13,632
1,989,677
kun432🇯🇵 retweeted

We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

107
185
1,901
537,310
kun432🇯🇵 retweeted

Jun 11
Soniox v5 Async is live.
Our new async speech-to-text model turns real-world audio into more accurate, structured speech data.
What’s improved:
• Higher accuracy across 60 languages
• Completely reengineered speaker separation for identifying who said what
• Improved language identification for multilingual and accented speech
• Better recognition and formatting of numbers, dates, emails, IDs, codes, names, and addresses
• More robust context usage for names, domain vocabulary, product terms, and custom phrases
stt-async-v5 is fully compatible with the existing async API. Just update the model name.
Read more: soniox.com/blog/soniox-v5-as…

11
5
43
1,290,248
kun432🇯🇵 retweeted

Jun 10
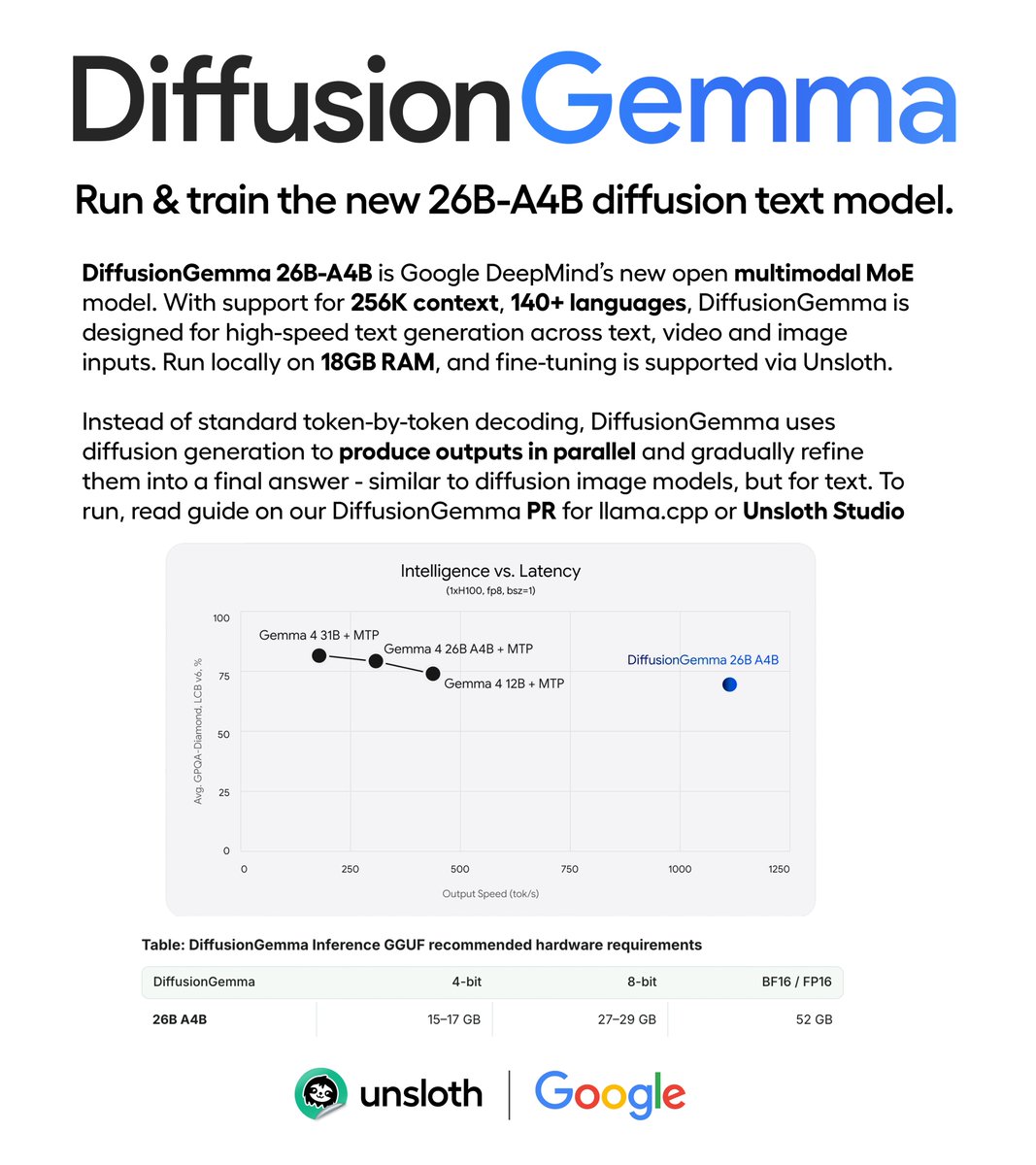
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
65
247
1,848
321,764
kun432🇯🇵 retweeted

Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
168
810
5,022
919,612
kun432🇯🇵 retweeted

Jun 10
New paper: Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
We use RL to post-train speech models (Moshi and PersonaPlex) to talk more like a human: to know when to respond, when to wait, and when to nod along with “yeah”s and “okay”s when listening.
12
45
312
30,011

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
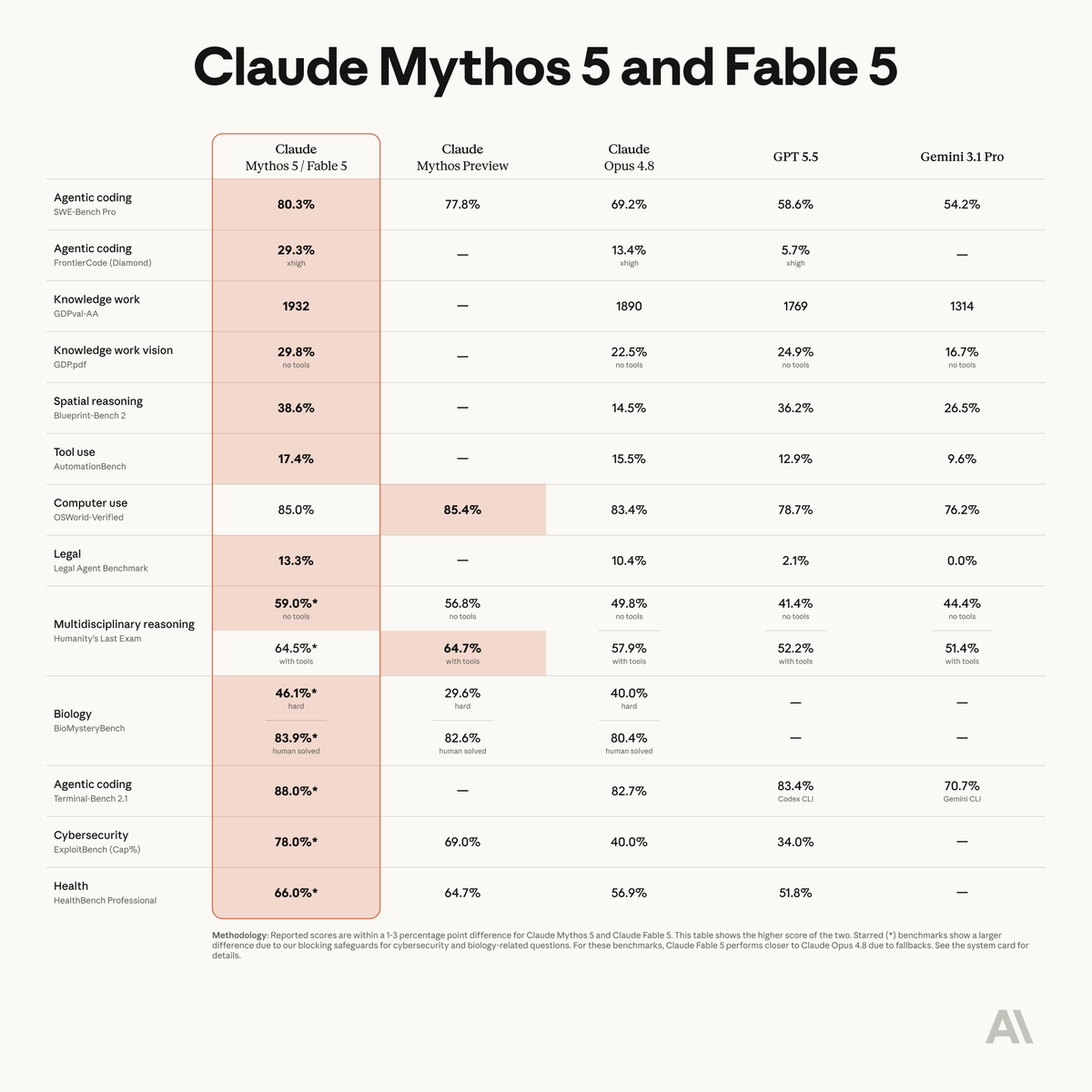
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
513
1,792
15,545
5,454,388
kun432🇯🇵 retweeted

Jun 6
NVIDIA just dropped Nemotron-3.5-ASR: one 0.6B model, 40 languages, streaming.
parakeet.cpp already runs it. On a plain CPU, 2.5x faster than @NVIDIAAI 's Nemo runtime, output byte-for-byte identical (WER 0).
No GPU needed. Offline or real-time. Pick a language with --lang, or auto.
GPU numbers are coming to compare with Nemo framework.
21
108
939
77,211
kun432🇯🇵 retweeted

The new @GoogleColab bridges the gap between local environments and the cloud, providing a zero-friction execution platform for developers and AI agents alike. The CLI Supports:
⚡️ Agent-driven Colab workflows
⚡️ Instant GPU/TPU provisioning
⚡️ Remote script execution
⚡️ Interactive runtime access (console/REPL)
Learn more in the blog: goo.gle/4dNPhF6
23
87
455
45,465

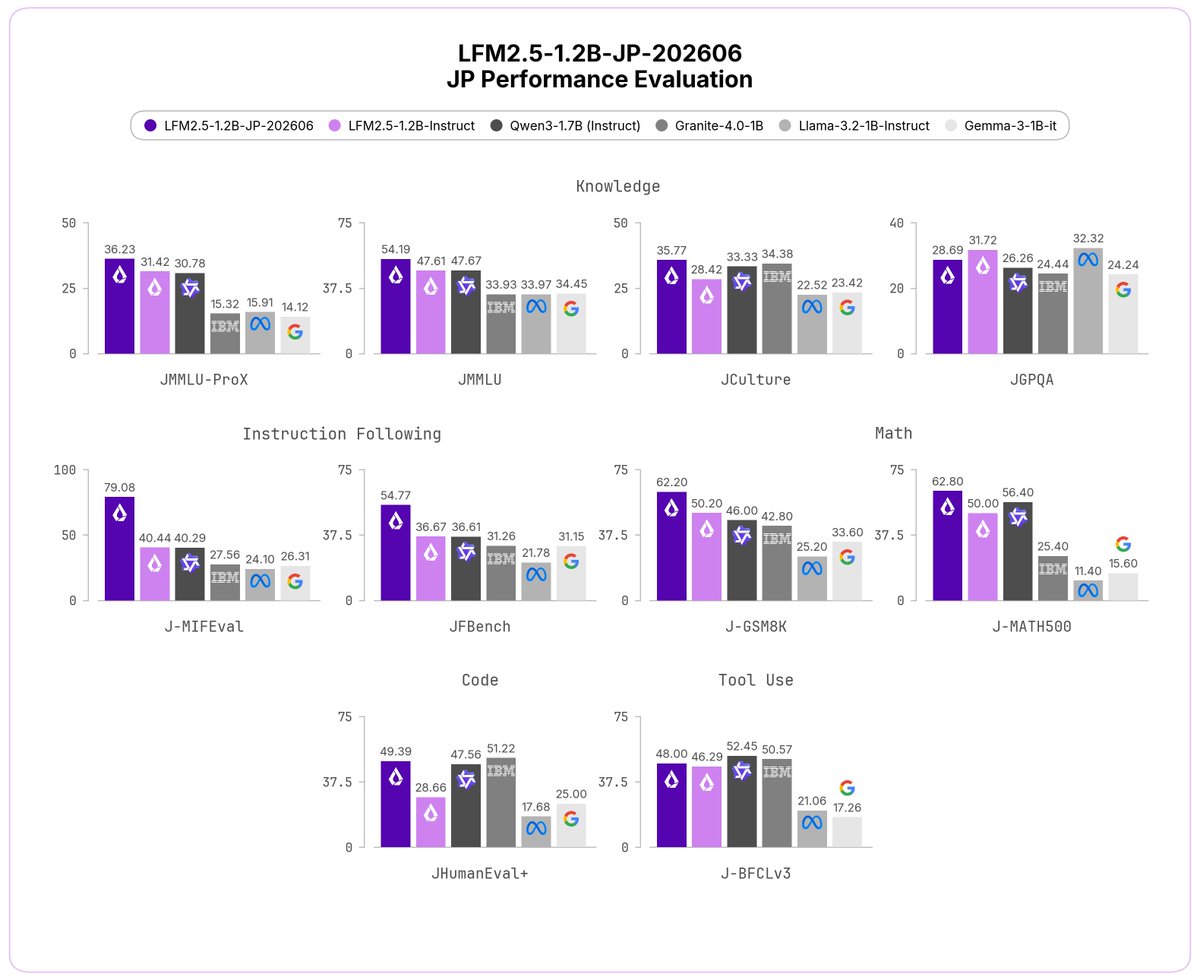
本日、日本語向けの新モデルを2つ公開しました🇯🇵
音声モデル:LFM2.5-Audio-1.5B-JP
言語モデル:LFM2.5-1.2B-JP-202606
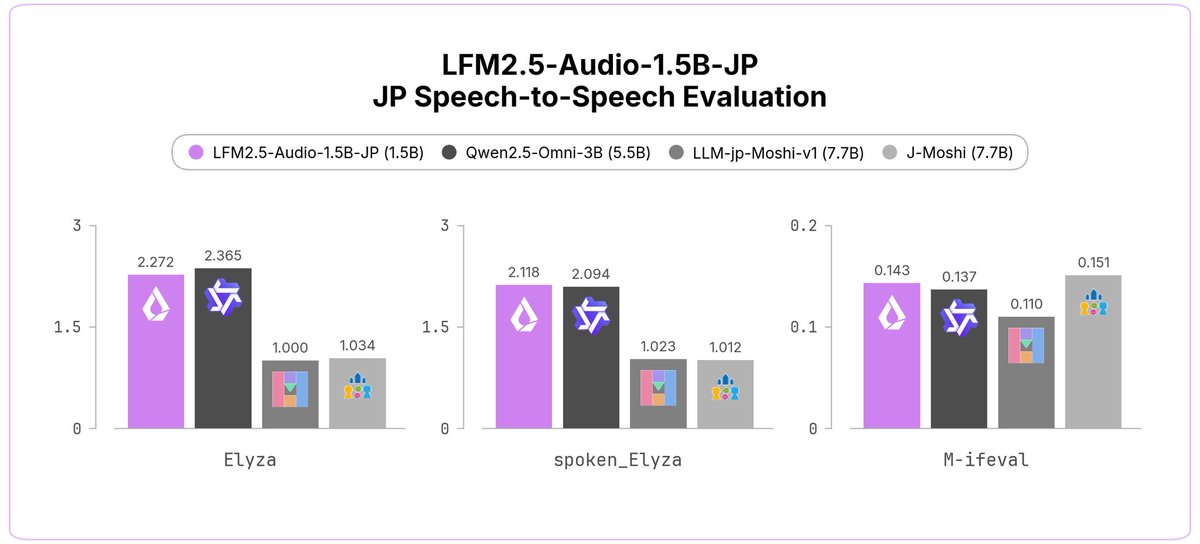
LFM2.5-Audio-1.5B-JP は、Liquid AI 初の日本語音声モデルです。
日本語で話しかけると、日本語の音声で応答します。ASR・TTS を別々に組み合わせるのではなく、単一のモデルで完結するエンドツーエンドの音声モデルです。
> 日本語に対応した、このスケールでは初の汎用エンドツーエンド音声モデル
> 15億(1.5B)パラメータで、J-Moshi(約77億)を上回る性能
> Qwen2.5-Omni-3B(約55億)にも匹敵する性能
> 追加学習を想定したベースモデル
LFM2.5-1.2B-JP-202606 は、最新版の日本語言語モデルです。
前バージョン(LFM2.5-1.2B-JP)はすでに、JMMLU、M-IFEval、GSM8K において Qwen3-1.7B や Llama 3.2 1B を上回っていました。
今回のアップデートでは、日本語データミックスの改善と新しい中間・事後学習により、さらに広範な日本語ベンチマークで 最高性能を達成しています。
どちらのモデルも本日より利用できます。
モデル:
音声: huggingface.co/LiquidAI/LFM2…
言語: huggingface.co/LiquidAI/LFM2…
ドキュメント: docs.liquid.ai
12
370
1,836
1,162,222
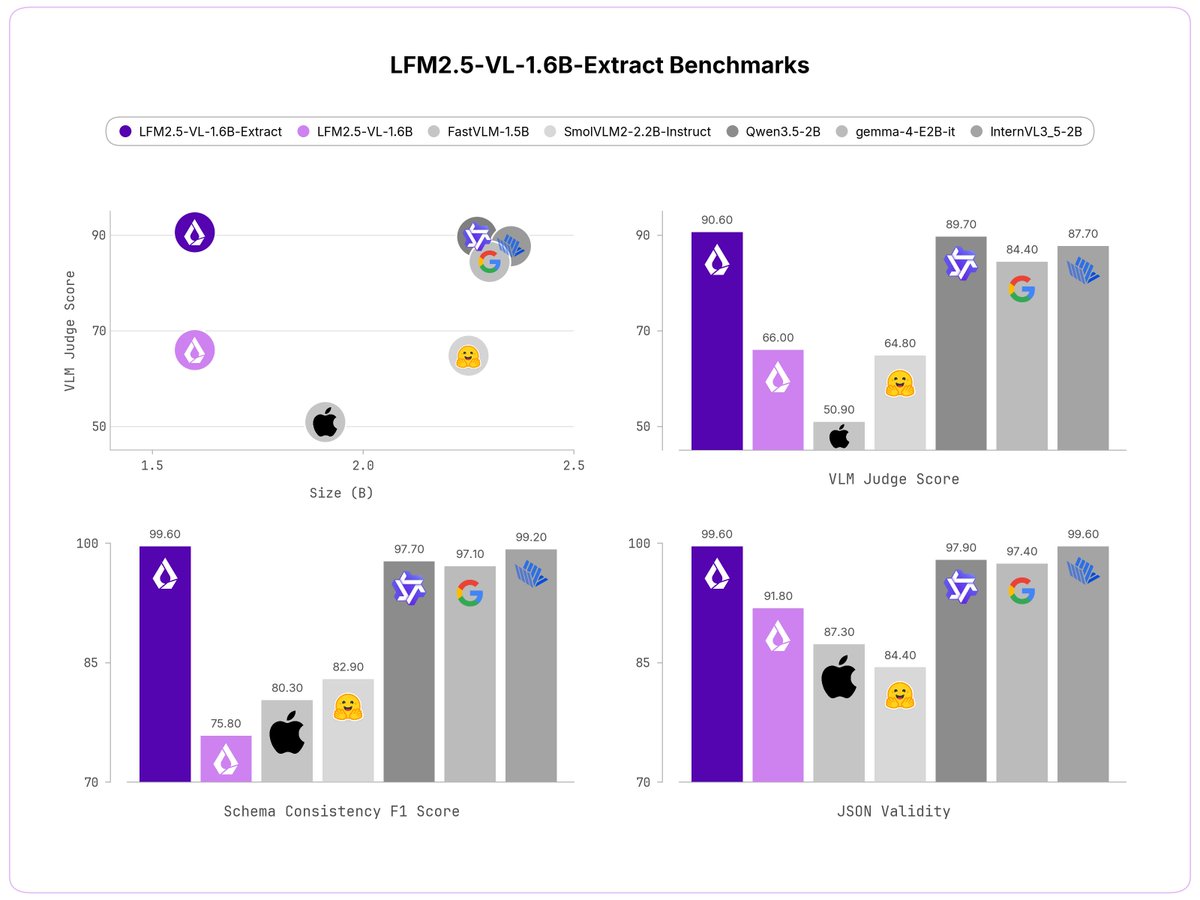
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
38
150
1,200
94,664

Higgs Audio v3 TTS is here.
Built for voice AI that speaks, not just reads:
• 100 languages with single-digit WER/CER
• inline control over emotion, style, prosody, and sound effects
• API, Workspace, and open weights
• Blog 👉 boson.ai/blog/higgs-audio-v3…
Watch the demo 👇
14
61
389
55,049

We’ve been researching new ways for ChatGPT memory to carry context across conversations and keep it useful over time.
Today, that work is rolling out as a more capable memory system in ChatGPT. openai.com/index/chatgpt-mem…
745
1,016
9,685
2,627,030
kun432🇯🇵 retweeted

Jun 4
Second big release from us today: Nemotron-3.5-ASR-Streaming!
🌎40 languages
⚡️80ms - 1s controllable latency
🔥240 - 2400 concurrent streams on 1xH100
🧱FastConformer Cache-Aware RNN-T architecture
huggingface.co/nvidia/nemotr…
23
118
980
60,160