
Joined July 2009
- Tweets 585
- Following 568
- Followers 724
- Likes 3,315
23 Photos and videos




Pinned Tweet

18 Dec 2024
I recently spoke at IPAM's Naturalistic Approaches to Artificial Intelligence Workshop, and shared some of the programmatic perspectives we're exploring in reinforcement learning research.
youtu.be/UNpg05yxc3o?si=FxuE…
2
19
1,504
Levi Lelis retweeted

I can nominate one Canada Impact postdoc candidate at UAlberta. Please reach out only if you have a strong theory track record (learning theory/bandits-RL theory/LLM reasoning). Deadline: May 10 (23:59 MT. Email: CV best papers brief pitch. Pls RT tinyurl.com/38vt2vyj
10
39
4,973
Levi Lelis retweeted

Apr 22
I'm in Brazil for ICLR! 🇧🇷
Presenting our paper "Gradient-Based Program Synthesis with Neurally Interpreted Languages" (arxiv.org/abs/2604.18907) on Thursday, April 23rd, 10:30 AM – 1:00 PM at Pavilion 3, P3-#215.
If you want to chat about world models, test-time adaptation or continual learning lets set up a chat or come say hi!
3
41
3,248
Apr 22
I’m headed to Brazil for #ICLR2026 and looking forward to seeing old friends and making new ones. Please drop me a line if you’d like to chat about program synthesis, programmatic reinforcement learning, or programmatic representations more broadly.
4
143
Levi Lelis retweeted
A couple of months ago, we released a preprint of one of my favourite papers I’ve ever written. It lies at the intersection of representation learning and neuroscience. I have now written a blog post about it.
Preprint: biorxiv.org/content/10.1101/…
Blog post: medium.com/@marlos.cholodovs…
3
35
183
13,656
Levi Lelis retweeted

Feb 21
Amii is hiring a Machine Learning Resident (1-year term) to work with ConeTec! Help solve critical safety challenges in geocharacterization using LLMs, OCR, and Deep Learning.
📍 Edmonton (Hybrid)
📅 Apply by March 4, 2026
🔗 amii.bamboohr.com/careers/23…

1
3
585
Levi Lelis retweeted
Feb 21
Amii is hiring a Machine Learning Scientist to lead our ML Educators and scale AI literacy across Canada.
If you have a background in ML research, people leadership, and a passion for AI for good, apply now: amii.bamboohr.com/careers/22…

2
2
597
Levi Lelis retweeted

Feb 11
Insightful thread about world models with ideas that very few people in the industry understand!
Building static, giant world models is a dead end for achieving human-level adaptation to new tasks. Instead, it's all about efficiently adapting local models of the world. The community should develop systems that produce world models (a la program synthesis) rather than static models.
Feb 10

Nobody asked, but here's 4 world model papers that I read early on in my PhD which I still ponder over now.
- Value Equivalence Principle
- Learning Awareness Models
- Embedded Agency (figure pic below), Big World Hypothesis
See the thread for details:

3
10
1,464
Levi Lelis retweeted

Jan 14
To make a bit of an excuse for Microsoft: the world is just waking up to the fact that coding agents are general agents.
It’s bitter lesson adjacent: Writing and executing code will likely outperform years of handcrafting vertical-specific agents with expert knowledge.
Actually it might exactly map in bitter lesson: Program synthesis is a form of scalable search.
49
129
1,703
456,064
Levi Lelis retweeted

20 Nov 2025
The Department of Computing Science at the University of Alberta at the University of Alberta has an opening for another tenure-track faculty in robotics. Please, spread the word.
I can attest to how awesome @UAlbertaCS and @AmiiThinks are!
(Official job posting coming soon.)
3
23
2,528
Levi Lelis retweeted

22 Sep 2025
Join our Reinforcement Learning Group next week on Monday, September 29th for a session with Esraa Elelimy on "Deep Reinforcement Learning with Gradient Eligibility Traces."
Thanks to @rahul_narava for organizing this event ✨
Learn more: cohere.com/events/cohere-lab…

2
4
23
4,184
Levi Lelis retweeted
19 Sep 2025
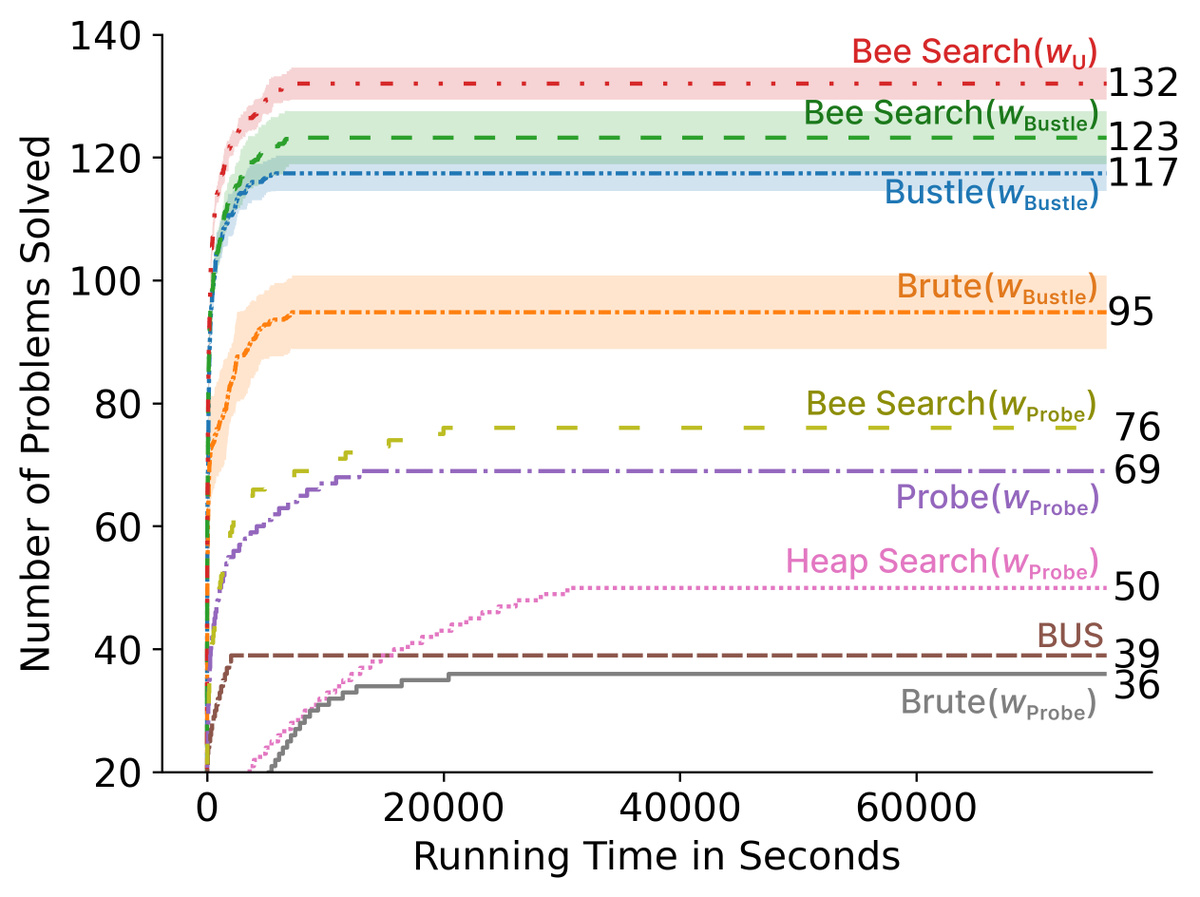
Happy to share that Searching Latent Program Spaces has been accepted as a Spotlight at #NeurIPS2025 ✨
It's been a pleasure to work with @ClementBonnet16 on this!
See you all in San Diego 🌴 👋,
arxiv.org/pdf/2411.08706

8
27
186
14,325
Levi Lelis retweeted

15 Sep 2025
I am hiring a post doc at @UAlberta , affiliated with @AmiiThinks ! We study language processing in the brain using LLMs and neuroimaging. Looking for someone with experience with ideally both neuroimaging and LLMs, or a willingness to learn. Email me Qs
apps.ualberta.ca/careers/pos…
9
20
3,726
Levi Lelis retweeted

1 Sep 2025
My acceptance speech at the Turing award ceremony:
Good evening ladies and gentlemen.
The main idea of reinforcement learning is that a machine might discover what to do on its own, without being told, from its own experience, by trial and error. As far as I know, the first person to propose this was Alan Turing in 1947, which makes it particularly gratifying and humbling to receive this award in his name for reviving this essential but still nascent idea.
I have three people that I would like to particularly thank.
First, Andy Barto. As my PhD supervisor he taught me my whole approach to science, and in particular instilled in me an appreciation of scholarship and craft, and of the great breath of prior work.
Second, I would like to thank Oliver Selfridge, my other main mentor; sadly, now deceased. Oliver taught me how keeping ideas simple can be the boldest of all ambitions.
Third, I want to thank Martha Steenstrup, my life partner and intellectual sparring partner. She keeps me honest and grounded.
Finally, I also want to thank the University of Alberta, which has been an ideal environment for me and for reinforcement learning research these past 22 years.
These three people and my university have reinforced in me the ambition to have ideas that matter, without getting too full of myself about it. They taught me that the quest for better ideas is serious, but is best approached playfully, with humility, kindness, and optimism. For this I am eternally grateful.
I would also like to thank all of you for being here and for celebrating the pursuit of intellectual excellence.
Thank you very much.
62
225
2,275
183,471
22 Aug 2025
Rina’s work has inspired me since my early days as a PhD student. I’m so happy to see her receive this very well-deserved award. Congratulations, Rina!
22 Aug 2025

#IJCAI2025 What inspires her research? Rina Dechter, 2025 IJCAI Research Excellence Award recipient, takes us on a journey in her #Invited talk: Graphical Models Meet Heuristic Search: A Personal Journey into Automated Reasoning
📆 22 August, 2 PM
🌐 2025.ijcai.org/invited-talks…

6
372
Levi Lelis retweeted

10 Aug 2025
Test Time Compute was "invented" the same way America was "discovered"..
x.com/rao2z/status/186803815…
14 Dec 2024

Inference Time Computation is NOT new--we wanted to get rid of it, but are letting it back in out of necessity.. #SundayHarangue (#NeurIPS2024 workshop edition)
Noam Brown @polynoamial has been giving talks on o1 suggesting that including inference time computation was a relatively newer idea in games (which he and others have brought to LLMs).
While I have a lot of respect for Noam (he is probably one of the handful of frontier folks who actually has a good understanding of pre- 2013 AI) , I am afraid that in this particular case, his characterization gets the chronology mostly wrong for prominent games--most of which were "deliberative" rather than "reflex" agents in Russell/Norvig's terminology.
Many games--including Chess and Go--focused exclusively on inference time compute in the beginning! (See my Intro #AI slide below..)
The 1997 Deep Blue, for example, was all inference time compute (using alpha-beta pruning on shallow game trees where the leaves were evaluated by (mostly hand-coded) evaluation functions--plus a library of end games.
Pre-Alpha-Go approaches for GO went with just MCT at inference time.
For these games, it is the idea of learning an approximate policy off-line and using it to complement the already standard inference time computation (via generalized policy rollout) that is the latter development!
TD-Gammon is more of an exception which tried first spending time "off-line" to get a policy and make a largely reflex agent. (Partly because between Samuel's Chekers and TD-Gammon, there were few RL/Learning based approaches for Games..)
So when Noam says he and Tuomas started poker first with off-line approximate policy learning and just using that during inference time, and then recognized that online policy roll out is actually helping, they went in the reverse order of what happened in Chess and Go!
The appeal for the off-line policy computation was that you can spend unlimited amounts of time behind the scenes, so that online computation can be mostly taken out. Many of us still remember marveling at the fact that the learning time for AlphaGo would have been about 1700 years on the common desktops of that time!
This learn everything upfront with a close-to reflex agent became so strong in the aftermath of AlphaGO that they tried their best to reduce the MCT search that was left over in the original AlphaGo in a stream of latter developments.
Reducing user-facing inference time computation was a deliberate choice--and has even lead to a change in the way the field started viewing computational complexity considerations (see x.com/rao2z/status/150017834…).
This trend continued with LLMs too--with all focus on pre-training so inference time compute is kept negligible--so that it costs very little for end users, and can even be done locally on edge devices..
I suspect that the twin bitter truths (c.f. x.com/rao2z/status/183435453…) --that you can't quite get reasoning out of auto-regressive LLMs, and that learning an approximate pseudo-cot-action policy that is good enough would be way too costly even for OAI/Microsoft's resources--dragged them into inference time compute awkwardness (c.f. x.com/rao2z/status/186345813…) which certainly changes the business model by pushing the scaling costs to the edge users! (x.com/rao2z/status/186760478…).

1
3
22
4,317
Levi Lelis retweeted

5 Aug 2025
Kicking off #RLC2025 with our Workshop on Programmatic Reinforcement Learning! This workshop explores how programmatic representations can improve interpretability, generalization, efficiency, and safety in RL.

2
9
53
11,836
31 Jul 2025
Armando's lecture notes are my favorite resources for program synthesis. Definitely worth reading!

The 2023 "Introduction to Program Synthesis" lecture series from Armando Solar-Lezama at @MIT_CSAIL is an amazing resource.
Topics:
- Inductive Synthesis
- SMT & SyGuS
- PS RL
- Neurosymbolic Learning
"...at the intersection of programming languages, formal methods and AI."

7
276

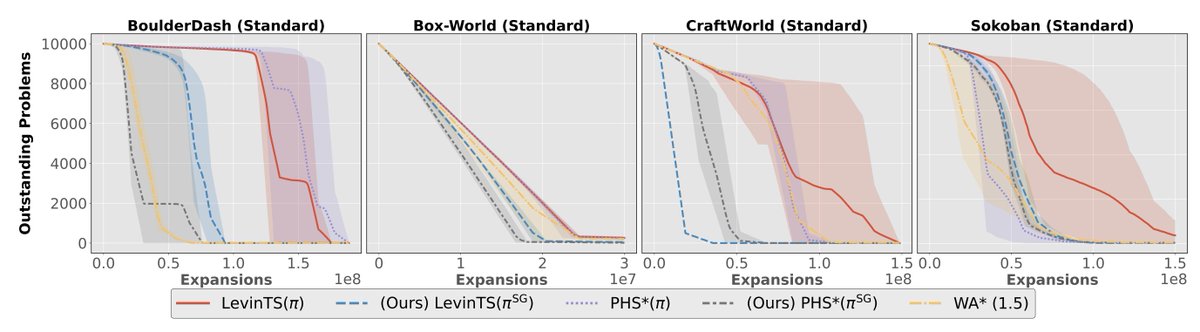
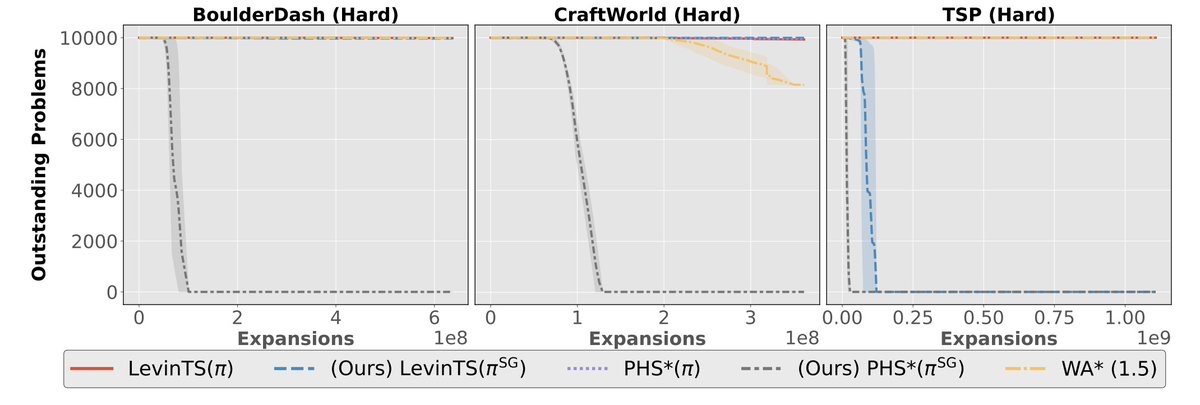
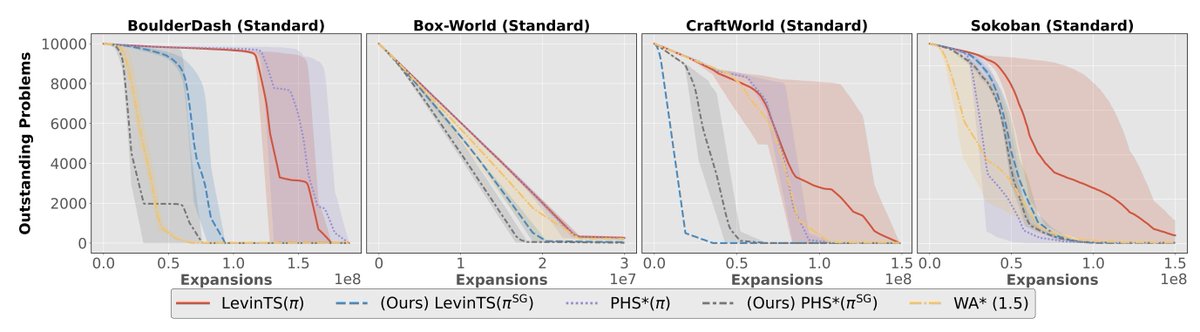
Are programmatic policies really better at generalizing OOD than neural policies, or are the benchmarks biased?
This position paper revisits 4 prior studies and finds neural policies can match programmatic ones - if you adjust training (sparse observation, reward shaping, etc.)

1
5
30
3,075
18 Jul 2025
Sparsity can also be used to partially explain some of the successes of programmatic representations, such as FlashFill. DSLs and the way we search over the space of programs naturally give us sparse representations, which favor sample efficiency and OOD generalization.
18 Jul 2025

After studying the mathematics and computation of Sparsity for nearly 20 years, I have just realized that it is much more important than I ever realized before. It truly serves as *the* model problem to understand deep networks and even intelligence to a large extent, from a computational point of view.
4
248
18 Jul 2025
Attending #ICML2025 and interested in programmatic representations in ML? This workshop is for you. :-)
17 Jul 2025

Our #ICML2025 Programmatic Representations for Agent Learning workshop will take place tomorrow, July 18th, at the West Meeting Room 301-305, exploring how programmatic representations can make agent learning more interpretable, generalizable, efficient, and safe! Come join us!

1
10
408