
Joined March 2013
- Tweets 3,811
- Following 149
- Followers 1,824
- Likes 4,427
254 Photos and videos



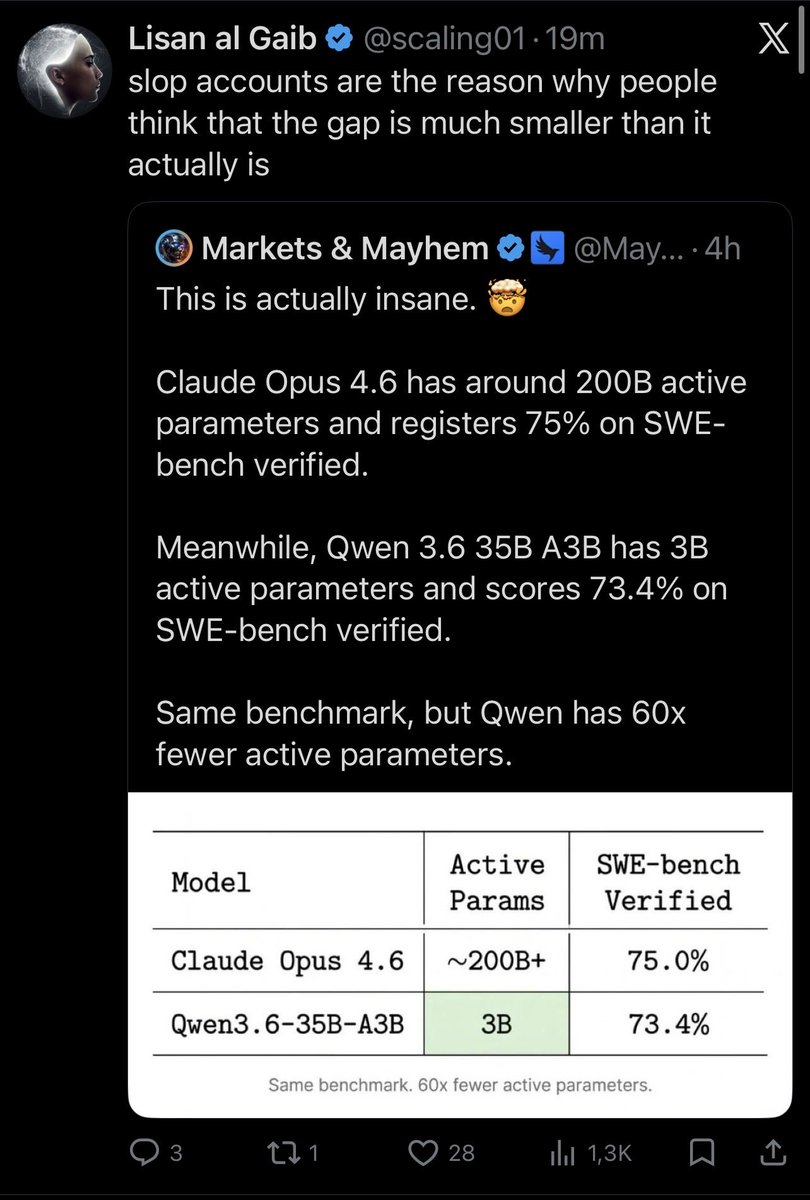



🔥GLM 5.2 vs Kimi K2.7.
Which one is better?
Will test it soon.
What's your thoughts?
46
2
298
37,845

Jun 12
K2.6 was the best Chinese model until today.
Now K2.7 is even better.
Amazing work.
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


2
8
917
Jun 9
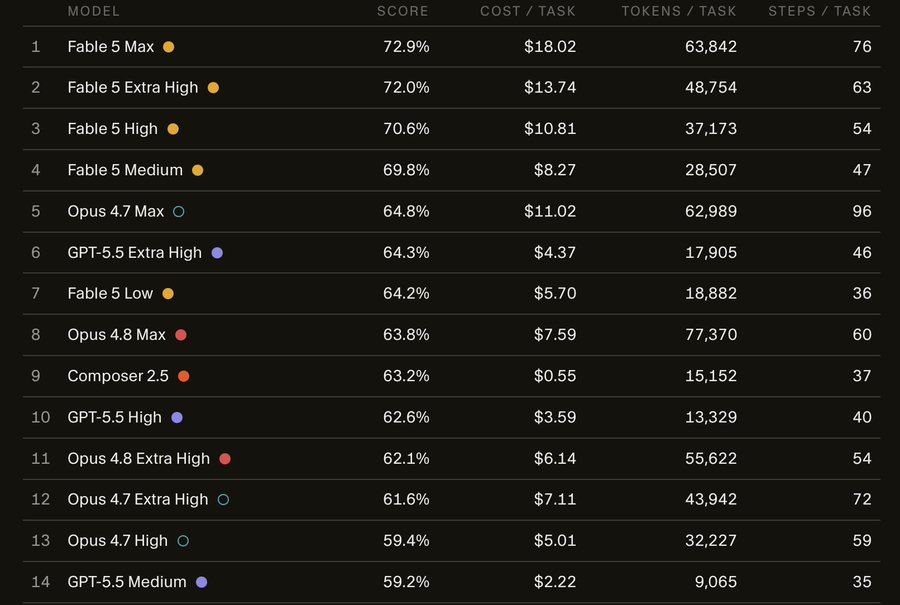
So Fable 5 is more expensive than 5.5 xhigh, but at the same level.

4
11
1,562
Jun 9
😞Yesterday I realized that 5.3 codex is removed.
This is very sad.
5.3 was great for fixing bugs or small features.
And it was very cheap.
I hope we will get something in return.
2
166
Jun 1
Second iteration much better, but still issues with animations.
Jun 1

🚀First try MiniMax 3.
Not bad. Animations are a bit clunky, but overall it proposed me interesting design.
Although I prefer what Kimi K2.6 proposed.
228
Jun 1
🚀First try MiniMax 3.
Not bad. Animations are a bit clunky, but overall it proposed me interesting design.
Although I prefer what Kimi K2.6 proposed.
1
4
839
Jun 1
We have it!
Looks fantastic.

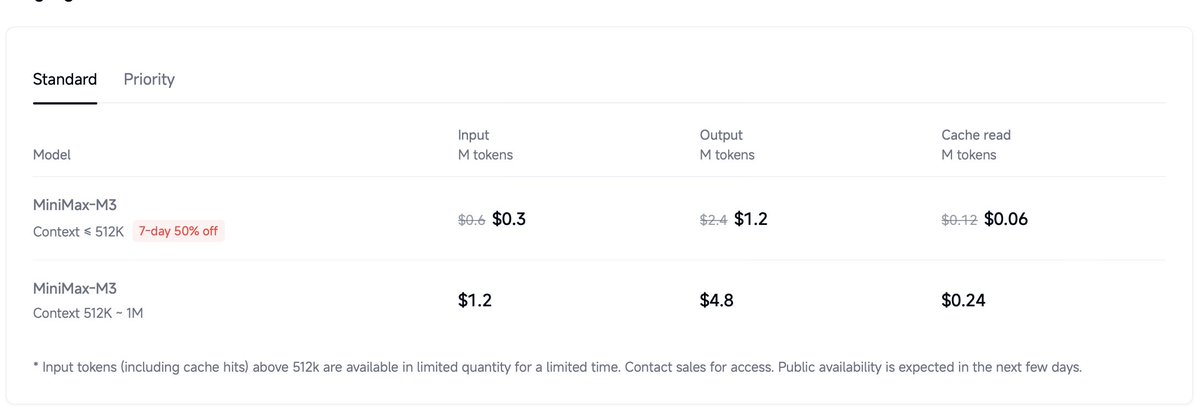
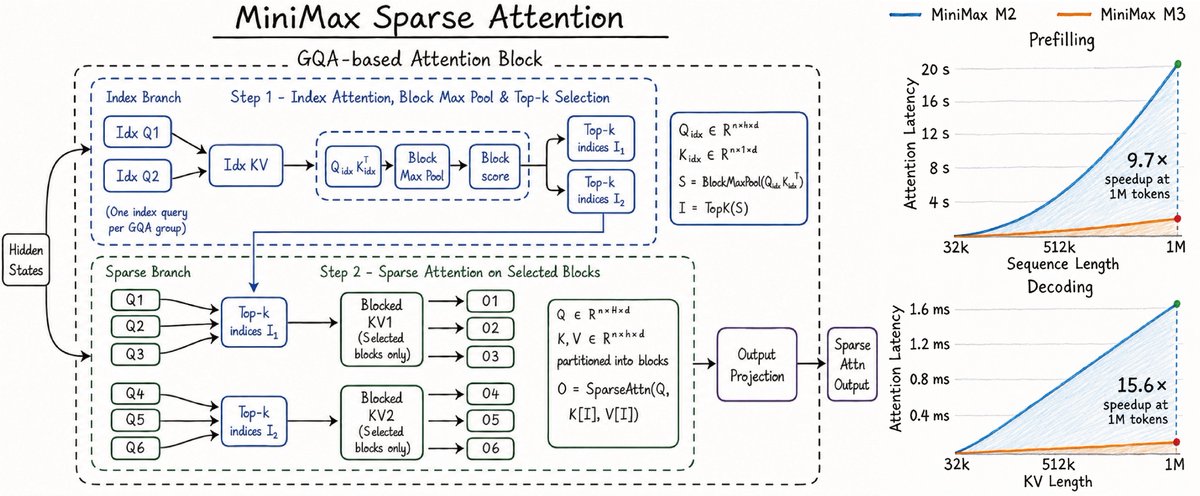
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

1
8
297
May 30
Playing with new TV(middle one).
My wife loves the new bedroom design for the next two weeks - 10/10.
My wife happiness - 10/10
My happiness - 10/10.
Only one score is true. Guess which one. 😂
BTW new soundbar is coming on Monday. 🙈
1
4
611
May 28
Did Opus 4.8 beat GPT-5.5?
Please tell me because I don't use anything from Anthropic.
116
365
105,648
May 27
I wonder what that could be! 🤔
Can't wait.

257
May 26
🇨🇳Xiaomi increased mimo usage.
This is DeepSeek effect.
Most companies reduce usage.
Deepseek and xiaomi increase or reduce price.
Win for us.
May 26

🚀 Better inference efficiency, lower costs, broader access.
MiMo-V2.5 Series API pricing is now permanently reduced — by up to 99% compared to previous pricing.
✨ Unified pricing across all context lengths.
MiMo Token Plans have also been upgraded:
• 5–8× more usable tokens at the same price
• Simpler and more transparent billing rules
🎁 As a thank-you to current users, all current Token Plan credits will be fully reset.
🎧 MiMo-V2.5-TTS remains free for a limited time.
⏰ Effective May 26 at 6:00 PM PDT.
These improvements are powered by continued inference optimization and serving efficiency upgrades across the MiMo stack.
🛠️ We’ll also publish a detailed technical blog on the inference optimizations later — stay tuned.


1
51
2,370
May 22
Unbelievable.
For this price it's amazing choice for coding and Hermes agent.
May 22

We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

1
16
955
May 19
Such an amazing terminal score. 😮

Gemini 3.5 Flash is built to help you execute complex, agentic workflows.
3.5 Flash rivals flagship models to deliver frontier performance for agents and coding, at the lightning speeds you expect from the Flash series.

ALT A benchmark table comparing the performance of Gemini 3.5 Flash against other AI models across categories like coding, reasoning, and multimodal tasks.
1
178
May 18
8gb vram for local models?
Still usable.
You don't have to start with rtx 6000 pro.

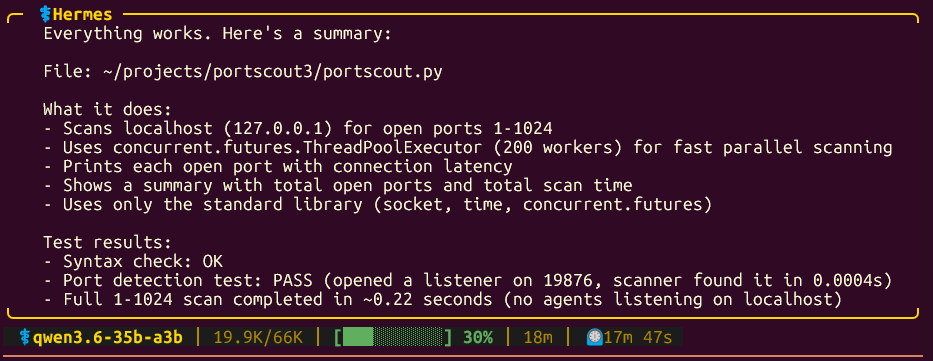
running Hermes locally with Qwen 3.6-35b-a3b is possible on a RTX 4060 Ti 8GB.
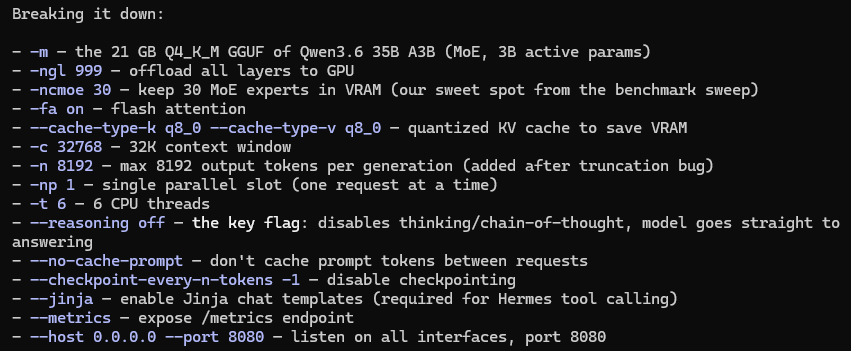
my params are:
~~~
llama-server \
-m ~/llama-models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
-ngl 999 -ncmoe 30 -fa on \
--cache-type-k q8_0 --cache-type-v q8_0 \
-c 32768 -n 8192 -np 1 -t 6 \
--reasoning off \
--no-cache-prompt --checkpoint-every-n-tokens -1 \
--jinja --metrics --host 0.0.0.0 --port 8080
~~~
biggest flaws:
- context: if you are coding, a few prompts will eat it all
- speed: it took 17min to create a medium-difficult .py file
but it works! I'm going to test /goal feature as well, to see how Qwen handle multiple compactions and see if it can finish a goal.
5
375
May 16
Great insight about mtp vs gguf.

2
3
295
May 16
So for less than 3090 price you can get 4x1080ti and have 44gb vram.
Speed is quite good, tdp 1000w, but it can be reduced to 800w with no performance loss.
2x1080ti with 22gb vram is not bad too.
Long live 1080ti. 🥳
May 16
Really good speeds on 1080 ti.
Wow.
1
1
404