
Senior Research Scientist @GoogleDeepMind, core contributor of Gemini Pretraining and Omni Post-training; Prev: PhD @CornellCIS, BS @Tsinghua_Uni
Joined June 2015
- Tweets 207
- Following 2,758
- Followers 1,681
- Likes 10,597
11 Photos and videos








Luming Tang retweeted

15 Aug 2025
📢Thrilled to share that I'll be joining Harvard and the Kempner Institute as an Assistant Professor starting Fall 2026!
I'll be recruiting students this year for the Fall 2026 admissions cycle. Hope you apply!

We are thrilled to share the appointment of @QianqianWang5 as an #KempnerInstitute Investigator! She will bring her expertise in computer vision to @Harvard.
Read the announcement: bit.ly/4mIghHy
@hseas #AI #ComputerVision
101
43
748
113,294
Luming Tang retweeted

11 Aug 2025
📢Excited to share that I’ve joined @MBZUAI as an Assistant Professor of Computer Vision this fall!
If you’re interested in CV4Science: building the next generation of foundation models & discovery tools for science, consider applying to MBZUAI. I’ll be recruiting PhD students!

16
14
171
15,573

7 Aug 2025
After a year of severe injury and complex surgery, I wrote about my journey—physical, emotional, and everything in between—hoping it might help others feel less alone in their own recovery.
tender-aster-768.notion.site…
16
2
101
7,263
3 Jun 2025
These demos look so amazing!
3 Jun 2025

Bored of linear recurrent memories (e.g., linear attention) and want a scalable, nonlinear alternative?
Our new paper “Test-Time Training Done Right” propose LaCT (Large Chunk Test-Time Training) — a highly efficient, massively scalable nonlinear memory with:
💡 Pure PyTorch (no custom kernels)
🚀 10× GPU FLOPs utilization compared to previous nonlinear test-time training(ttt) methods.
🧠 Huge memory size (up to 40% of model params)
Project page with code: tianyuanzhang.com/projects/t…
(videos generated with our AR video diffusion)
1/9
1
1,393
12 May 2025
Congrats to my great roommate during PhD, who got best paper award when I was still trying to figure out how to write an organized vision paper 😆 Yucheng is so nice, kind, and have so much passion and insights on research. I cannot imagine how lucky his first batch students are
8 May 2025

🔥Thrilled to share that I’ll be joining the Computer Science Department at NYU Shanghai as an Assistant Professor starting Fall 2025! @nyushanghai
🎯 I’ll be recruiting PhD students across the entire NYU network—including @nyushanghai, @nyutandon, and @NYU_Courant—to build efficient ML systems (algorithms, models, kernels, and more). I’ll also be hosting multiple RAs and interns (remote friendly). If you're interested, DMs are open! ✉️
13
1,558
14 Apr 2025
Really cool work on using MLLM to analyze city-scale image collection and automatically find the changes over time. Really curious to see all the interesting findings discovered by it!
14 Apr 2025

Curious about how cities have changed in the past decade? We use MLLMs to analyse 40 million Street View images to answer this. Do you know that "juice shops became a thing in NYC" and "miles of overpasses were painted BLUE in SF"? More at→boyangdeng.com/visual-chroni… (vid ↓ w/ 🔊)
1
12
2,079
22 Jan 2025
really cool work and demo!
22 Jan 2025

Thrilled to introduce Video Depth Anything to support Depth Estimation for super-long videos (over 5 minutes).
👉It enjoys all the benefits of #DepthAnything: high-quality, fast, robust, etc.
Proj Page: videodepthanything.github.io…
2
833
Luming Tang retweeted

7 Jan 2025
github.com/NVIDIA/Cosmos
Cosmos is a developer-first platform designed to help physical AI builders accelerate their development. It has pre-trained world foundation models (diffusion & autoregressive) in different sizes and video tokenizers. They are open models with permissive licenses. Try it out, and let us know how we can better help.
11
152
671
105,268
Luming Tang retweeted

16 Dec 2024
and also check out paper, which might be the first wave to explore this idea, "Diffusion Models Without Attention" (arxiv.org/abs/2311.18257) with @thoma_gu and @srush_nlp.
6
15
2,337
Luming Tang retweeted

14 Dec 2024
Why can’t more non-Chinese researchers show even a bit care about the racism against Chinese students in the NeurIPS keynote?
Why can’t more US researchers pay any attention to the suffering of international students?
I remain very disappointed, esp. at many established people.
47
36
691
107,224
14 Dec 2024
Interesting recording. And thanks to the audience for confronting straightforward!
14 Dec 2024

Someone confronted on the spot, and they said “ Maybe there is one, maybe they are common, who knows what. I hope it was an outlier.” Even this explanation is full of implicit racial bias. See the full conv: dropbox.com/scl/fi/2dtji0z84…
11
1,797
14 Dec 2024
Apparently, this is called “cultural generalization” according to #NeurIPS2024 . Never too old to learn something new.
14 Dec 2024

1/3 Today, an anecdote shared by an invited speaker at #NeurIPS2024 left many Chinese scholars, myself included, feeling uncomfortable. As a community, I believe we should take a moment to reflect on why such remarks in public discourse can be offensive and harmful.

4
6
140
15,125
14 Dec 2024
Cultural generalization? Come on bro
14 Dec 2024

NeurIPS acknowledges that the cultural generalization made by the keynote speaker today reinforces implicit biases by making generalisations about Chinese scholars. This is not what NeurIPS stands for. NeurIPS is dedicated to being a safe space for all of us. We want to address the comment made during the invited talk this afternoon, as it is something that NeurIPS does not condone and it doesn't align with our code of conduct. We are addressing this issue with the speaker directly.
NeurIPS is dedicated to being a diverse and inclusive place where everyone is treated equally.
6
1,118
5 Dec 2024
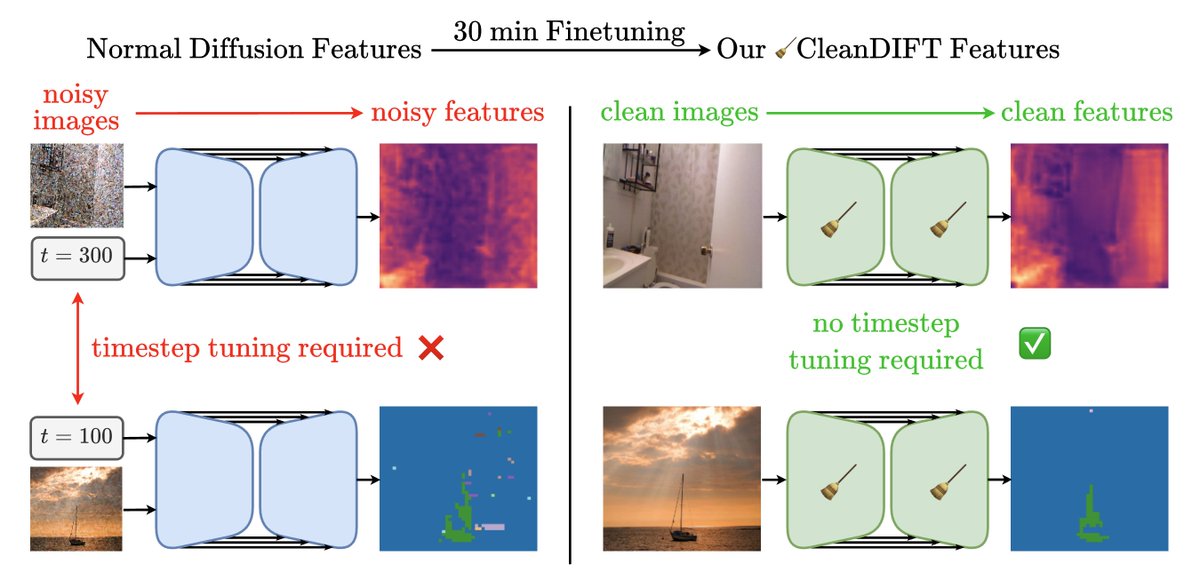
Really cool work on getting diffusion features directly from clean images!
4 Dec 2024

🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle
🧵👇
1
7
1,095
4 Dec 2024
This looks so cool!
4 Dec 2024

What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities. Here’s a few examples – check out this thread 🧵 for more results!
4
829
28 Nov 2024
Amazing results 🤩
28 Nov 2024

🚀 Introducing CAT4D! 🚀
CAT4D transforms any real or generated video into dynamic 3D scenes with a multi-view video diffusion model.
The outputs are dynamic 3D models that we can freeze and look at from novel viewpoints, in real-time!
Be sure to try our interactive viewer!
2
781
Luming Tang retweeted

21 Nov 2024
I am on the job market for industry and academic roles. My research focuses identifying, designing, and building efficient, scalable, sustainable, and affordable abstractions and infrastructure for generative modeling research. I also minor law, and do AI policy work.
3
12
65
9,270
21 Nov 2024
Really cool work on 3D consistent video generation!
21 Nov 2024

We've released our paper "Generating 3D-Consistent Videos from Unposed Internet Photos"! Video models like Luma generate pretty videos, but sometimes struggle with 3D consistency. We can do better by scaling them with 3D-aware objectives. 1/N
page: genechou.com/kfcw
5
945
Luming Tang retweeted

5 Nov 2024
Curious whether video generation models (like #SORA) qualify as world models?
We conduct a systematic study to answer this question by investigating whether a video gen model is able to learn physical laws.
Three are three key messages to take home:
1⃣The model generalises perfectly for in-distribution data, but fails to do out-of-distribution generalization. For combinatorial scenarios, scaling law is observed.
2⃣The models fail to abstract general rules and instead tries to mimic the closest training example.
3⃣The model prioritizes different attributes when referencing training data: color > size > velocity > shape.
This work is a joint effort with our outstanding intern @YangYue_THU.
Paper: arxiv.org/abs/2411.02385
Webpage: phyworld.github.io/
40
206
1,055
606,557
Luming Tang retweeted

2 Nov 2024
🎉 New work on ARC-AGI: We achieved open model SOTA by finetuning Llama3-8B on synthetically generated ARC-like problems! Our method: Prompting LLMs to create both (1) input grid generators and (2) input-output transformations in Python to create problems grounded in code!
2 Nov 2024

New ARC-AGI paper
@arcprize w/ fantastic collaborators @xu3kev @HuLillian39250 @ZennaTavares @evanthebouncy @BasisOrg
For few-shot learning: better to construct a symbolic hypothesis/program, or have a neural net do it all, ala in-context learning?
cs.cornell.edu/~ellisk/docum…

21
107
14,833