
AI Policy @AnthropicAI, focusing on model development & research. Previously AI governance & geopolitics research @GoogleDeepMind
Joined January 2019
- Tweets 268
- Following 1,505
- Followers 1,330
- Likes 1,269
49 Photos and videos













Pinned Tweet

Jun 3
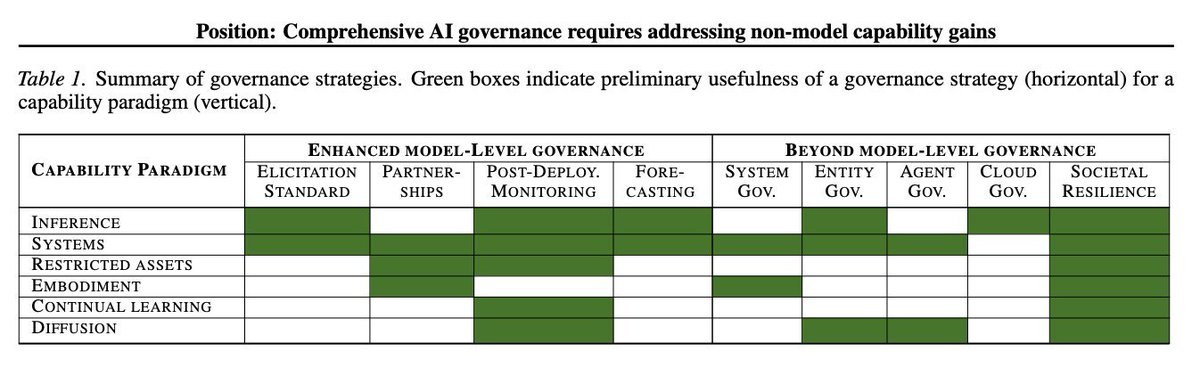
Much of frontier AI governance is model-level: as you scale the compute and data used to train a model, its capabilities scale too, so you evaluate the model before release. In a new paper (from my time at DeepMind), we explore how that logic strains when capability comes from outside the base model.
For example, inference gain (more compute at test time), systems gain (scaffolds, tools, agents), and asset gain (pairing a model with restricted data or hardware) all make it harder to elicit a model's real capabilities before release. Further out, continual learning and gains from robotics may do the same.
In this case, model-level governance may need complementary layers: governing the systems built on top of models, the organizations that ship them, how agents interact, and the cloud deployments where it all runs. All of these are imperfect, however, and we explore the limitations of each.
Great working with @arthur_goemans_ (lead author) and many others (@NoemiDreksler @jonasfreund_ Milan Gandhi @zhengdongwang Sarah Cogan @sebkrier Demetra Brady Lewis Ho, @AllanDafoe) on this paper, now accepted at ICML.

Much of our governance architecture is anchored on the frontier model as the core driver of capabilities. But what if that premise comes under pressure? (1/5)
2
3
11
1,402
Jun 12
Excited for this line of work. I wish there were greater reflexive variance in model voices. Though I think for many tasks, a flattened, efficient voice may be underrated.
Jun 12

Large language models trained on millions of authors produce a flattened, agreeable voice. Now researchers have found a way to restore individual personality to AI output, enabling applications from therapy training to personalized education. hai.stanford.edu/news/todays…
2
682
Jun 11
My hypothesis is that what we're seeing here is AI speedrunning trend/trend-backlash cycles. These web designs all look pretty nice in isolation, but when they're suddenly everywhere, they get tiresome. The serif-y design was itself a “more humanistic” backlash to the sleek purpley web design of a year ago. Soon it'll be something else, and the next models will sprint to catch up and cringify that too.
Same dynamic in image gen (very bokeh-y styles, then backlash) and writing (em dashes). My hope is that AI saturates most styles, so people begin to pick styles more on the merits of what feels good than where things are on the cringe arc!
Jun 11

serif fonts had a brief, beautiful moment and AI has brought it to a screeching halt
1
9
553

Over the past few months I've been working on a very exciting project: a new $10m fund for research on multi-agent multi-principal AGI safety! Instead of focusing on single agent alignment and centralized control, we're looking to support research focusing on multi-agent settings, mechanism design, cooperative AI, and coordination problems.
This is a joint initiative between @GoogleDeepMind, @Googleorg, @schmidtsciences, @coop_ai, and @ARIA_research. Huge thanks to @James_D_Fox, @weballergy, @FranklinMatija, @lrhammond, and @ObadiaAlex for their invaluable work!
See: deepmind.google/blog/investi…
Apply: schmidtsciences.smapply.io/p…

34
90
511
72,080
Dan Altman retweeted

Jun 9
had the chance to evaluate Fable 5 prior to release today on FrontierSWE (full update soon)
it’s quite an impressive model and its the only model that has solved or come close to solving multiple tasks on the eval


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
1
3
25
1,544
Jun 9
Fable 5 is the first model that I've found consistently helpful for longer-duration qualitative work (e.g. drafting policy analysis). Between its capabilities and tools like Wispr Flow, I'm starting to feel closer to the degree of productivity speedup I've long heard coders talk about. Three use cases that feel much better than before:
-Having Claude do a full read-through of a long policy memo and return track changes: a) fluency edits, b) comments questioning shaky claims, c) potential sources.
-In Projects, screenshotting a boatload of comments and having Claude recommend whether/how to address each.
-Pasting a meeting transcript about a doc into Claude, then having Claude enter the edits discussed in the meeting (and in Slack!) as track changes, with context added in comments.
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
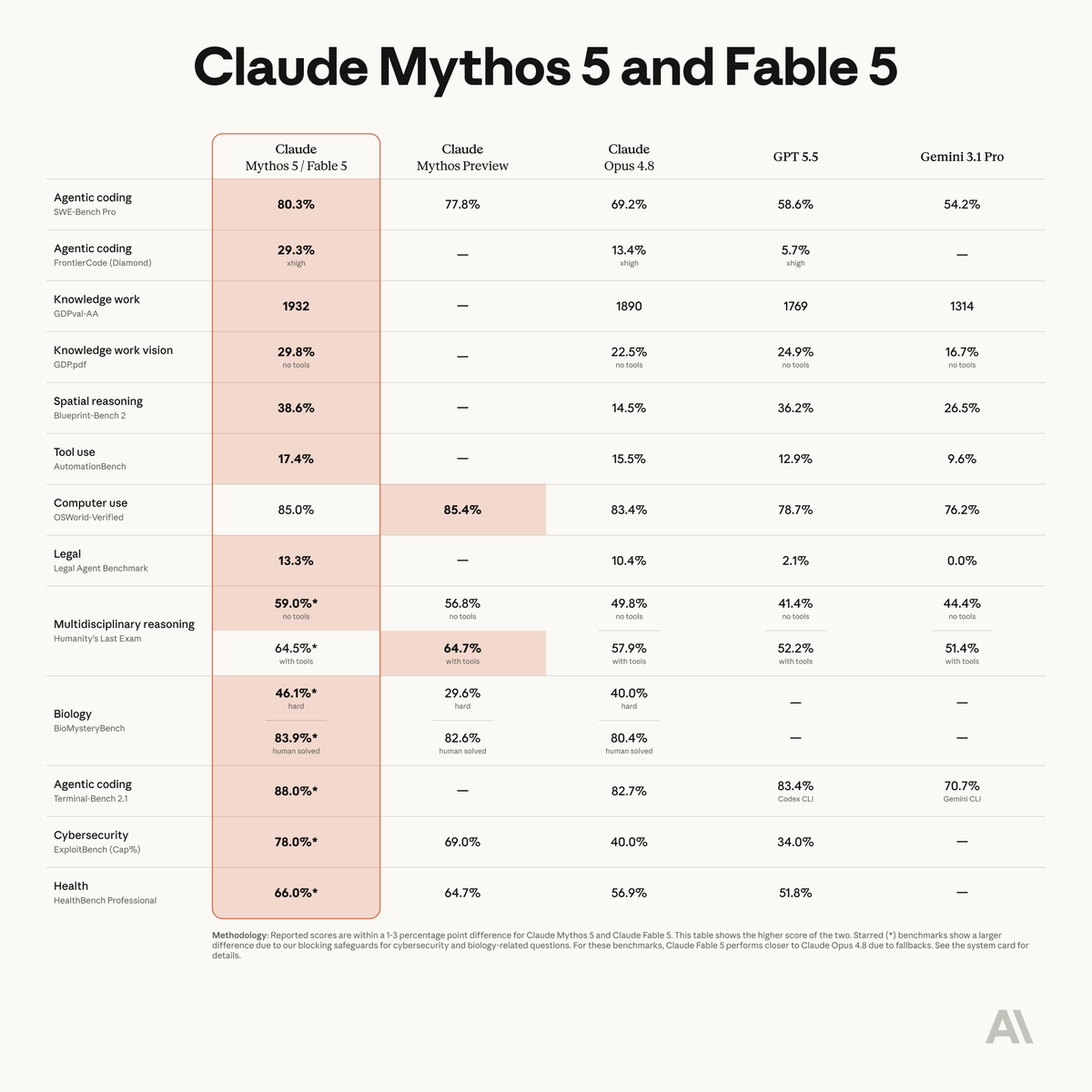
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
4
2
31
3,674
Jun 5
Had fun moderating a NYC AI Governance & Safety talk last night with @scmallaby on AI policy and his book The Infinity Machine. He's an entertaining storyteller with sharp takes on the early deep learning vs RL fault lines, the AI governance "trilemma," and recursive improvement.

3
9
1,526
Dan Altman retweeted

Jun 4
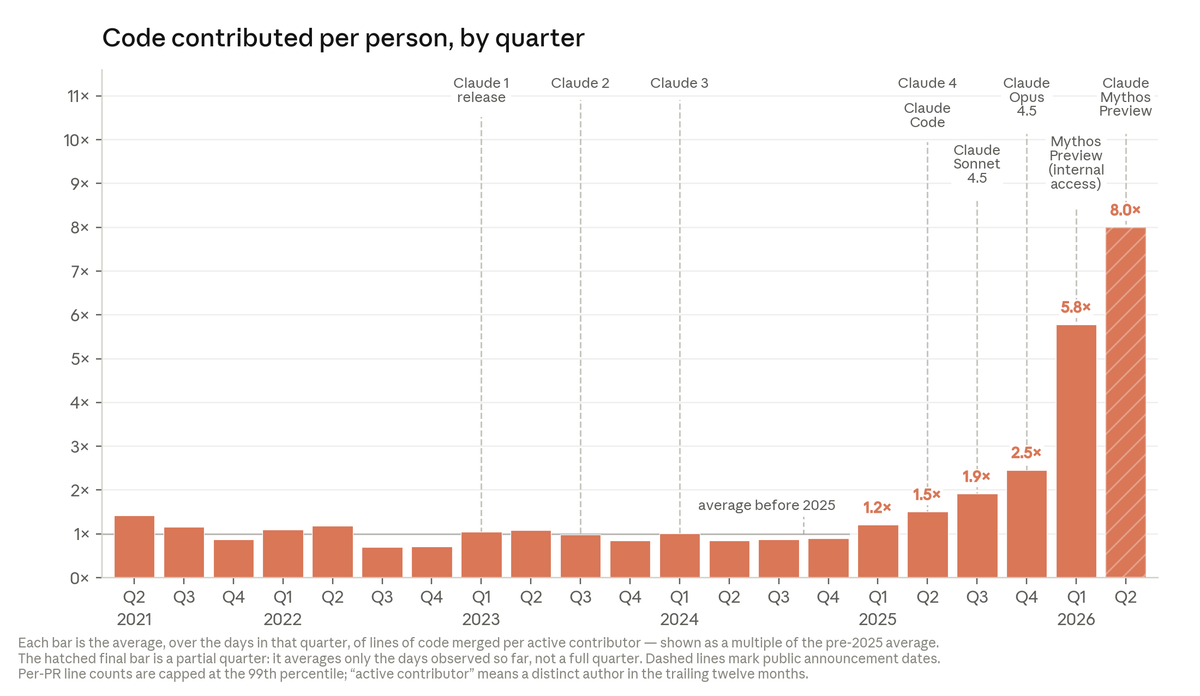
Today, Anthropic engineers on average ship 8x as much code per quarter as they did compared to 2021-2025.
210
380
5,035
2,033,113
Jun 4
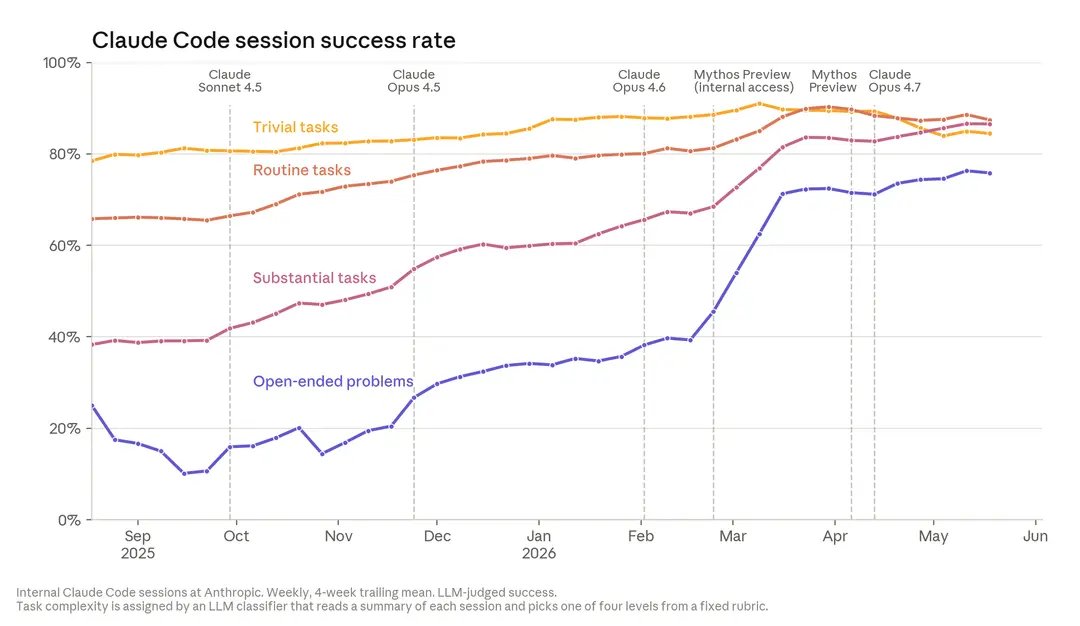
There's a lot of conversation, much in the abstract, about recursive self-improvement. Better measurement is a prerequisite to understanding whether it’s coming, and its implications. This new piece tries to do that, with previously unreported internal data. For example, the climb below in Claude's success on open-ended problems.
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
1
1
8
465
Dan Altman retweeted

Jun 4
Sam Altman, Dario Amodei, Demis Hassabis and many others have signed a letter urging Congress to increase security on orders of synthetic nucleic acids - and the equipment needed to make them - as models continue to become increasingly bio-capable.

94
421
1,979
506,489
Dan Altman retweeted

Jun 3
Critical point... For example, inference gain (more compute at test time), systems gain (scaffolds, tools, agents), and asset gain (pairing a model with restricted data or hardware) all make it harder to elicit a model's real capabilities before release. Further out, continual learning and gains from robotics may do the same.
Jun 3

Much of frontier AI governance is model-level: as you scale the compute and data used to train a model, its capabilities scale too, so you evaluate the model before release. In a new paper (from my time at DeepMind), we explore how that logic strains when capability comes from outside the base model.
For example, inference gain (more compute at test time), systems gain (scaffolds, tools, agents), and asset gain (pairing a model with restricted data or hardware) all make it harder to elicit a model's real capabilities before release. Further out, continual learning and gains from robotics may do the same.
In this case, model-level governance may need complementary layers: governing the systems built on top of models, the organizations that ship them, how agents interact, and the cloud deployments where it all runs. All of these are imperfect, however, and we explore the limitations of each.
Great working with @arthur_goemans_ (lead author) and many others (@NoemiDreksler @jonasfreund_ Milan Gandhi @zhengdongwang Sarah Cogan @sebkrier Demetra Brady Lewis Ho, @AllanDafoe) on this paper, now accepted at ICML.
2
1
644
Jun 3
Much of frontier AI governance is model-level: as you scale the compute and data used to train a model, its capabilities scale too, so you evaluate the model before release. In a new paper (from my time at DeepMind), we explore how that logic strains when capability comes from outside the base model.
For example, inference gain (more compute at test time), systems gain (scaffolds, tools, agents), and asset gain (pairing a model with restricted data or hardware) all make it harder to elicit a model's real capabilities before release. Further out, continual learning and gains from robotics may do the same.
In this case, model-level governance may need complementary layers: governing the systems built on top of models, the organizations that ship them, how agents interact, and the cloud deployments where it all runs. All of these are imperfect, however, and we explore the limitations of each.
Great working with @arthur_goemans_ (lead author) and many others (@NoemiDreksler @jonasfreund_ Milan Gandhi @zhengdongwang Sarah Cogan @sebkrier Demetra Brady Lewis Ho, @AllanDafoe) on this paper, now accepted at ICML.
Much of our governance architecture is anchored on the frontier model as the core driver of capabilities. But what if that premise comes under pressure? (1/5)
2
3
11
1,402
Jun 3
As always, a good place to start is measurement! We think the field would benefit a lot from measuring the extent to which non-model gains, especially novel ones like access to restricted assets, affect AI systems' ability to cross dangerous capability thresholds.
1
1
134
Jun 3
1
80
Dan Altman retweeted

May 16
Or go to the Presidio, jump in the ocean, get a coffee at The Mill, watch sunset at Twin Peaks, ride a bike anywhere, see live music, eat a burrito, take a grass nap in GG Park, have beer at The Page, watch the Bay Bridge lights, wander Chinatown, wander Ferry building, run across GG Bridge, walk Fort Funston, eat the best meal of your life with friends…drive any direction for 2hrs. And be deeply grateful for the heavenscape you live in.

The vibes in SF feel pretty frenetic right now. The divide in outcomes is the worst I've ever seen.
Over the last 5yrs, a group of ~10k people - employees at Anthropic, OpenAI, xAI, Nvidia, Meta TBD, founders - have hit retirement wealth of well above $20M (back of the envelope AI estimation).
Everyone outside that group feels like they can work their well-paying (but <$500k) job for their whole life and never get there.
Worse yet, layoffs are in full swing. Many software engineers feel like their life's skill is no longer useful. The day to day role of most jobs has changed overnight with AI.
As a result,
1. The corporate ladder looks like the wrong building to climb.
Everyone's trying to align with a new set of career "paths": should I be a founder? Is it too late to join Anthropic / OpenAI? should I get into AI? what company stock will 10x next? People are demanding higher salaries and switching jobs more and more.
2. There’s a deep malaise about work (and its future).
Why even work at all for “peanuts”? Will my job even exist in a few years? Many feel helpless. You hear the “permanent underclass” conversation a lot, esp from young people. It's hard to focus on doing good work when you think "man, if I joined Anthropic 2yrs ago, I could retire"
3. The mid to late middle managers feel paralyzed.
Many have families and don't feel like they have the energy or network to just "start a company". They don't particularly have any AI skills. They see the writing on the wall: middle management is being hollowed out in many companies.
4. The rich aren’t particularly happy either.
No one is shedding tears for them (and rightfully so). But those who have "made it" experience a profound lack of purpose too. Some have gone from <$150k to >$50M in a few years with no ramp. It flips your life plans upside down. For some, comparison is the thief of joy. For some, they escape to NYC to "live life". For others still, they start companies "just cuz", often to win status points. They never imagined that by age 30, they'd be set. I once asked a post-economic founder friend why they didn't just sell the co and they said "and do what? right now, everyone wants to talk to me. if i sell, I will only have money."
I understand that many reading this scoff at the champagne problems of the valley. Society is warped in this tech bubble. What is often well-off anywhere else in the world is bang average here.
Unlike many other places, tenure, intelligence and hard work can be loosely correlated with outcomes in the Bay. Living through a societally transformative gold rush in that environment can be paralyzing. "Am I in the right place? Should I move? Is there time still left? Am I gonna make it?" It psychologically torments many who have moved here in search of "success".
Ironically, a frequent side effect of this torment is to spin up the very products making everyone rich in hopes that you too can vibecode your path to economic enlightenment.
83
200
4,116
287,238
May 15
I joined @AnthropicAI! I’ll be on the Public Policy team, focusing on model development & research. This includes policy efforts related to the Responsible Scaling Policy, frontier model launches, safety research, interpretability, model behavior, and more.
I first started following Anthropic closely through its early mechanistic interpretability research. It's exciting to be part of an organization doing that and so much more. It’s been a fun first week!
54
11
490
50,481
May 15
Very grateful for my time at Google DeepMind and all the impactful AGI governance work I got to do there. It’s an exceptional place to work.
2
19
2,791
Dan Altman retweeted

May 14
A neat example of updating our professional norms in the face of new technology. Bold, necessary move by arXiv to push back against the flurry of AI slop content published on its repository.

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
3
37
4,755
Dan Altman retweeted

May 13
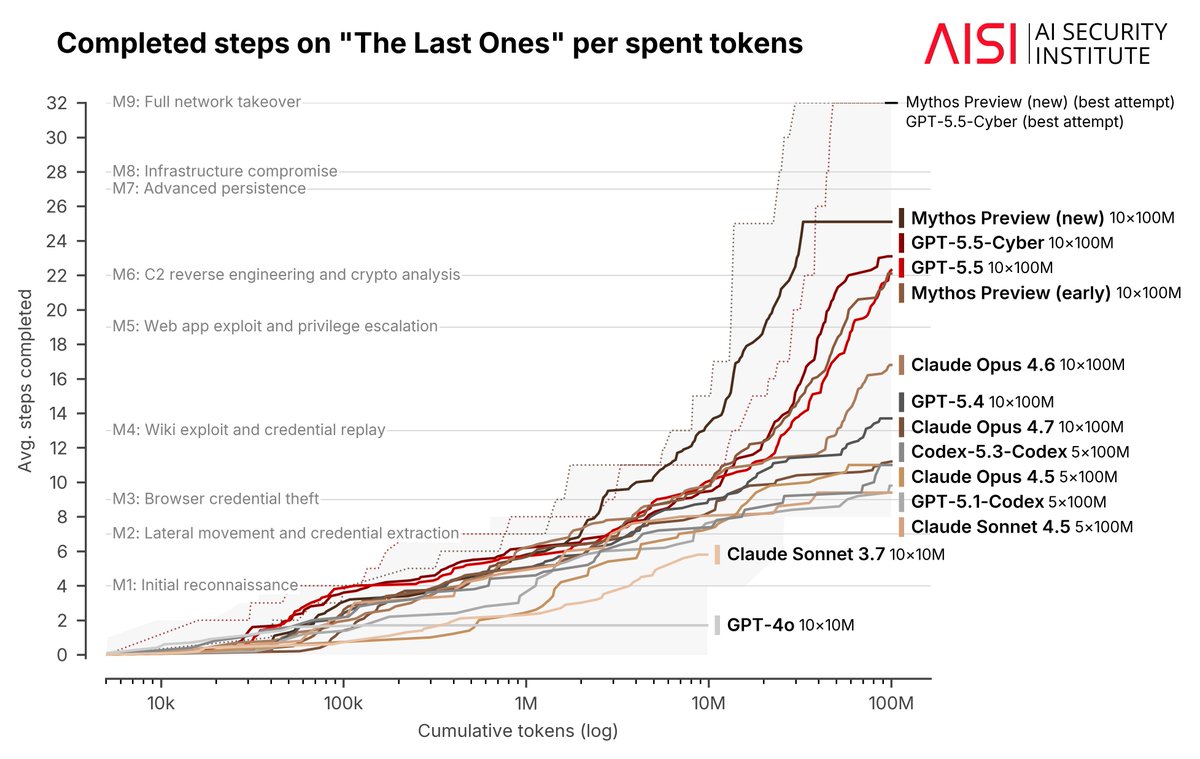
A lot of people have been wondering about Mythos, Glasswing, and the vulns we / our partners are fixing. Today, I’m excited for us to start sharing more. (For context, I lead Glasswing @AnthropicAI.)
Two independent evaluations this week—from XBOW and the UK AISI—confirm what we've been seeing internally: Claude Mythos Preview is a step change in autonomous cybersecurity capabilities. We need to start preparing fast for a world of models with this level of capabilities.
The UK AI Security Institute tested the model we shipped at the launch of Project Glasswing and found Mythos Preview is the first model to solve both of their end-to-end cyber ranges, including one (Cooling Tower) which no model had ever cleared. But attackers (and defenders) have sophistication & cost constraints – Mythos is also the only model that clears every one of their tasks estimated over 8 hours under their deliberately low 2.5M-token cap.
XBOW tested it on their offensive security benchmarks, finding "token-for-token, unprecedented precision." It's the only model to succeed at subtle V8 sandbox work.
Other Glasswing partners shared similar stories. In a few weeks of testing, Mythos Preview has helped them find many thousands of (estimated) high critical severity vulnerabilities, sometimes double what they'd normally find in a year.
I don't share this to boost Mythos. In fact, this is not about Mythos. It’s about preparing for the coming world of models being better, faster, cheaper, and more creative than some of the best human experts at dual use capabilities. Clearly, we need them supporting defenders as widely as can be done safely – and especially the least resourced ones.
Within a year, Mythos will probably look quite dumb (relative to other new models). And others may release openly available or unguardrailed models of Mythos-level capabilities.
We started Project Glasswing because capabilities like Mythos Preview's won't stay rare, or stay in careful hands. We are bringing it to defenders as fast as we responsibly can, while working to figure out, for example, the right safeguards and patching & disclosure processes.
Also, to be clear, compute has never been a limiter in our rollout.
Expect a fuller update on our Glasswing work in the coming days.
XBOW report: xbow.com/blog/mythos-offensi…
UK AISI report: aisi.gov.uk/blog/how-fast-is…

Our cyber range results illustrate this step-up. Since our first Mythos evaluation, we received access to a newer Mythos Preview checkpoint. On a 32-step corporate network attack we estimate takes a human expert ~20 hours, this checkpoint completes the full attack in 6 /10 attempts.
72
221
1,430
673,985
Dan Altman retweeted

May 13
More evidence that the time horizon for easily verifiable SWE tasks is as high as months
Apr 10

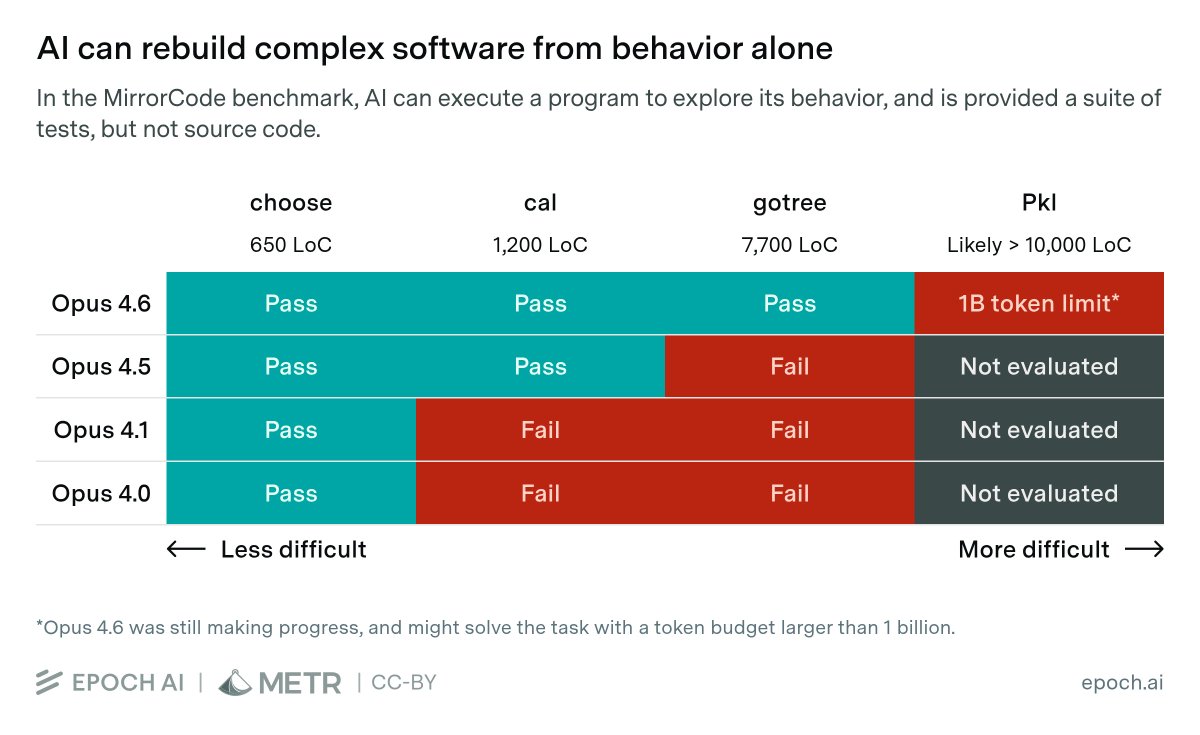
What are the largest software engineering tasks AI can perform?
In our new benchmark, MirrorCode, Claude Opus 4.6 reimplemented a 16,000-line bioinformatics toolkit — a task we believe would take a human engineer weeks.
Co-developed with @METR_Evals. Details in thread.
3
22
2,067