
Senior staff research scientist at DeepMind. Opinions are my own. Re-tweets and favorites not to be considered as endorsements.
Joined May 2009
- Tweets 9,351
- Following 1,378
- Followers 6,358
- Likes 15,618
122 Photos and videos





Pinned Tweet

Feb 13
Excited to share our work on envisioning Intelligent AI Delegation (arxiv.org/abs/2602.11865). Delegation in most existing AI systems is brittle, and relies on simplified hand-crafted control flows. As such, it fails to meet the requirements of what is needed to truly scale distributed reasoning and task completion in multi-agent systems and collectives.
5
16
75
7,944
Nenad Tomasev retweeted

Jun 12
Our Robotics Accelerator has launched with 15 startups helping shape the future of physical AI in Europe. 🤖
This three-month program will connect them with access to our AI stack, Gemini Robotics models and hands-on support from our teams.
Meet the companies → goo.gle/4oeEk2K
47
64
455
49,797
Nenad Tomasev retweeted
Jun 11
When millions of AI agents interact with each other, new collective behaviors can emerge. 🌐
Together with @schmidtsciences, @coop_ai, @ARIA_research and supported by @GoogleOrg, we’re launching a $10M research fund to help understand how AI systems behave as a group. → goo.gle/3Si6rCl
87
93
464
60,046
Nenad Tomasev retweeted

Jun 11
I’m very excited that this is out. We’re looking forward to funding some great research

Over the past few months I've been working on a very exciting project: a new $10m fund for research on multi-agent multi-principal AGI safety! Instead of focusing on single agent alignment and centralized control, we're looking to support research focusing on multi-agent settings, mechanism design, cooperative AI, and coordination problems.
This is a joint initiative between @GoogleDeepMind, @Googleorg, @schmidtsciences, @coop_ai, and @ARIA_research. Huge thanks to @James_D_Fox, @weballergy, @FranklinMatija, @lrhammond, and @ObadiaAlex for their invaluable work!
See: deepmind.google/blog/investi…
Apply: schmidtsciences.smapply.io/p…

5
37
4,368
Nenad Tomasev retweeted
Jun 11
We’re teaming up @Palmeiras, the first football club to meaningfully build upon TacticAI: our AI system that can help simulate field scenarios and predict open play dynamics up to 8 seconds in advance. ⚽
109
359
3,225
919,210

Over the past few months I've been working on a very exciting project: a new $10m fund for research on multi-agent multi-principal AGI safety! Instead of focusing on single agent alignment and centralized control, we're looking to support research focusing on multi-agent settings, mechanism design, cooperative AI, and coordination problems.
This is a joint initiative between @GoogleDeepMind, @Googleorg, @schmidtsciences, @coop_ai, and @ARIA_research. Huge thanks to @James_D_Fox, @weballergy, @FranklinMatija, @lrhammond, and @ObadiaAlex for their invaluable work!
See: deepmind.google/blog/investi…
Apply: schmidtsciences.smapply.io/p…
34
90
511
72,015
Nenad Tomasev retweeted

Jun 11
Congrats @sebkrier @weballergy @FranklinMatija @lrhammond!
Oversight systems that help comps and govs oversee millions of AI agents from different labs are going to be hugely important and won't (and shouldn't be) be build by any of the big labs.
Over the past few months I've been working on a very exciting project: a new $10m fund for research on multi-agent multi-principal AGI safety! Instead of focusing on single agent alignment and centralized control, we're looking to support research focusing on multi-agent settings, mechanism design, cooperative AI, and coordination problems.
This is a joint initiative between @GoogleDeepMind, @Googleorg, @schmidtsciences, @coop_ai, and @ARIA_research. Huge thanks to @James_D_Fox, @weballergy, @FranklinMatija, @lrhammond, and @ObadiaAlex for their invaluable work!
See: deepmind.google/blog/investi…
Apply: schmidtsciences.smapply.io/p…
3
18
2,454
Jun 11
I am excited to announce this funding call, in collaboration with @schmidtsciences, @coop_ai @ARIA_research and @Googleorg
As we are thinking about moving beyond individual powerful AI agents towards large-scale agentic collectives that can communicate and coordinate towards completing long-horizon complex tasks - it is paramount to design these future agentic societies safely.
Jun 11

With @schmidtsciences, @coop_ai, @ARIA_research and @GoogleOrg, we’re launching a $10M research fund to help understand how AI systems behave as a group and to fund work in multi-agent safety.
We invite researchers to submit proposals in four priority areas:
1. Sandboxes and testbeds
2. The science of agent networks
3. Strengthening agent infrastructure
4. Oversight and control
A big thank you to everyone that was involved including @James_D_Fox, @sebkrier, @weballergy, @lrhammond, and @ObadiaAlex!
1
3
13
802
Jun 11
The call covers the following priority areas:
1. Sandboxes and testbeds
2. The science of agent networks
3. Strengthening agent infrastructure
4. Oversight and control
Huge thanks to @James_D_Fox, @sebkrier, @FranklinMatija, @lrhammond, @ObadiaAlex, and others who have helped shape this and make it happen!
1
10
206
Nenad Tomasev retweeted

Jun 5
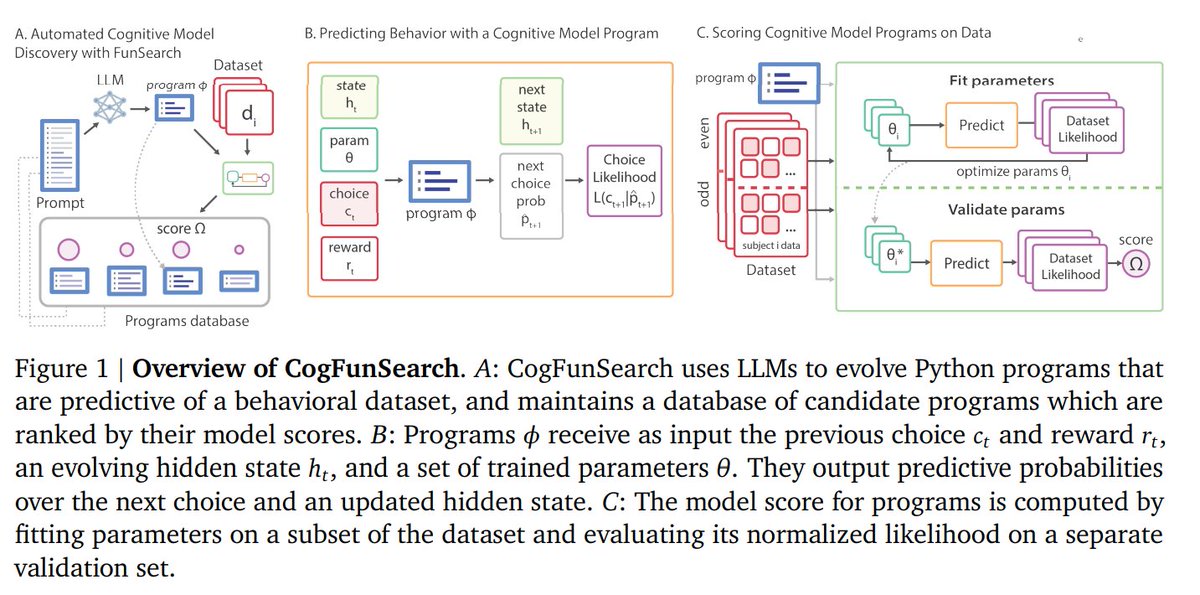
Check out my team mates' work on using AlphaEvolve to discover novel cognitive models of learning! This is such an important stepping stone towards building tools that help human scientists gain more insights from their data. We certainly did!

Computational models are a key part of science but discovering new ones is hard!
DataDIVER discovers concise models from data, surfacing new mechanistic ideas and generating clear predictions for future experiments
Preprint from @GoogleDeepMind Neuroscience Lab collaborators

3
15
1,851
Nenad Tomasev retweeted

Building autonomous agents for scientific discovery? 🧬🤖
@GoogleDeepMind Science Skills is now available on GitHub. We've open-sourced this specialized toolkit to accelerate your agentic workflows with scientific grounding and higher token efficiency.
Download now ↓
github.com/google-deepmind/s…
31
269
1,604
88,610
Nenad Tomasev retweeted

Computational models are a key part of science but discovering new ones is hard!
DataDIVER discovers concise models from data, surfacing new mechanistic ideas and generating clear predictions for future experiments
Preprint from @GoogleDeepMind Neuroscience Lab collaborators
22
54
297
64,087
Nenad Tomasev retweeted
We believe AI can be a dedicated research partner to help discover the next breakthrough.
Enter Co-Scientist: our latest Gemini-based multi-agent system that can generate, debate and evolve novel hypotheses for complex scientific problems 🧵
150
332
1,656
189,623
May 28
RT @mweber_PU: Can we learn the curvature of a data manifold from a finite sample? We study continuum limits of Ollivier’s Ricci curvature…
39
Nenad Tomasev retweeted

May 25
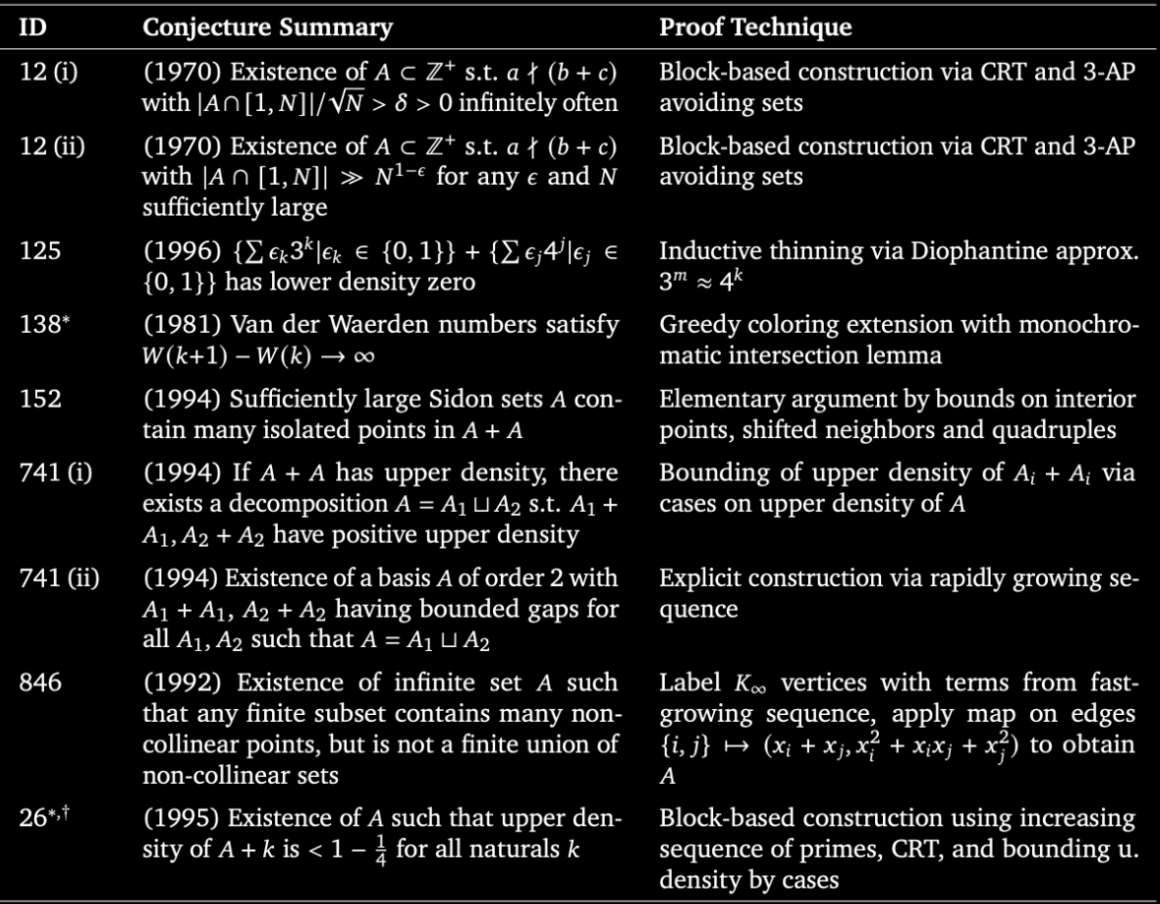
AI agents are advancing research-level math. 🚀
I’m thrilled to share @GoogleDeepMind’s AlphaProof Nexus - an agentic framework for formal proof search powered by Gemini.
When applied to a set of open formal math problems, our agent autonomously solved:
✅ 9 open Erdős problems (including two open for 56 years!)
✅ 44 Online Encyclopedia of Integer Sequences (OEIS) problems
✅ A 15-year-old open problem in algebraic geometry ✅ A 7-year-old open question in min-max optimization
We are collaborating with mathematicians across disciplines - from combinatorics and graph theory to quantum optics. Ultimately, these results show the massive potential of even simple agentic loops powered by Gemini.
Read the paper here: arxiv.org/abs/2605.22763v1
80
242
1,508
217,785
Nenad Tomasev retweeted

May 22
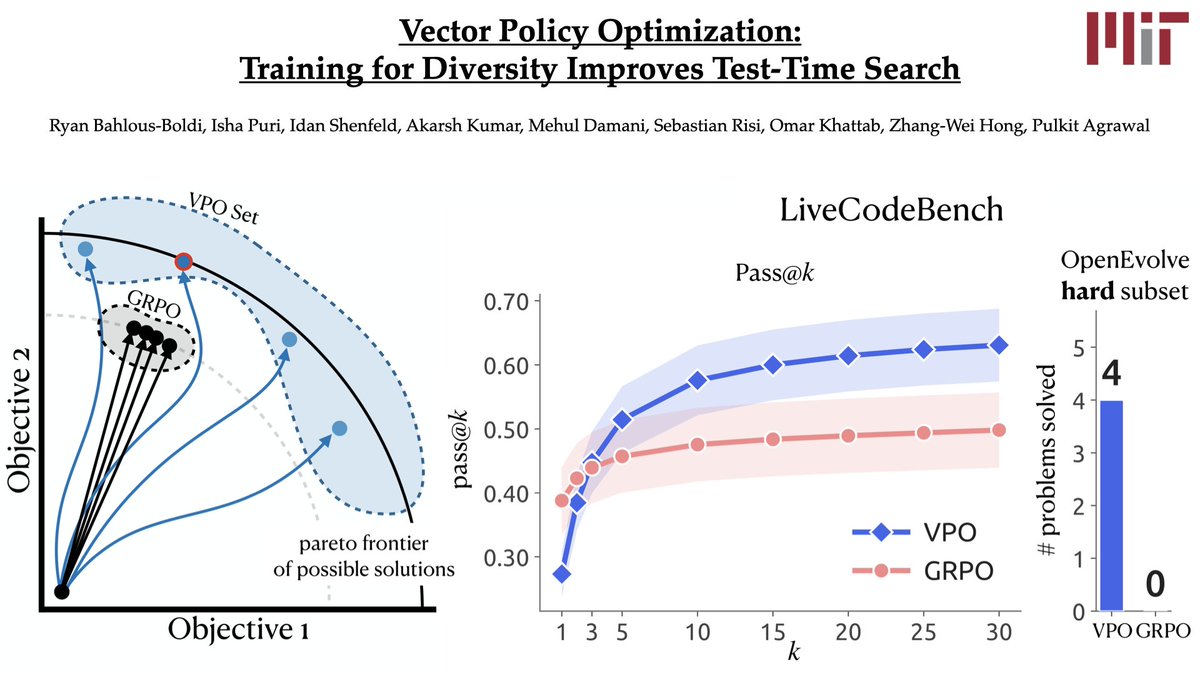
Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
34
121
860
212,525
Nenad Tomasev retweeted

Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.

33
154
1,230
221,931
Nenad Tomasev retweeted
May 19
We want to help scientists discover their next breakthrough with AI.
Gemini for Science is our new suite of experimental tools to help them explore more hypotheses, validate work at scale, unpack literature with ease, and more 🧵
136
328
2,029
15,755,560
Nenad Tomasev retweeted
May 19
Really happy to see @OpenAI adopt @GoogleDeepMind's SynthID for watermarking AI generated images.
We need more such cross industry partnerships for enabling responsible use of AI systems.

We’re adding new ways for people to identify AI-generated images and understand where they came from.
In addition to C2PA Content Credentials, images now also contain a SynthID watermark, and can be identified using a public verification tool to check whether an image was made by OpenAI products.
openai.com/index/advancing-c…
6
19
332
40,057
Nenad Tomasev retweeted

May 19
Our paper “Accelerating scientific discovery with Co-Scientist” is published today in @Nature. Read it here: nature.com/articles/s41586-0… and learn more about our real-world partnerships on the DeepMind blog: deepmind.google/blog/co-scie…
5
32
154
34,209