
architecting systems that think - responsibly • senior ml engineer • bit of stock market too.
Joined May 2020
- Tweets 954
- Following 100
- Followers 146
- Likes 12,807
284 Photos and videos














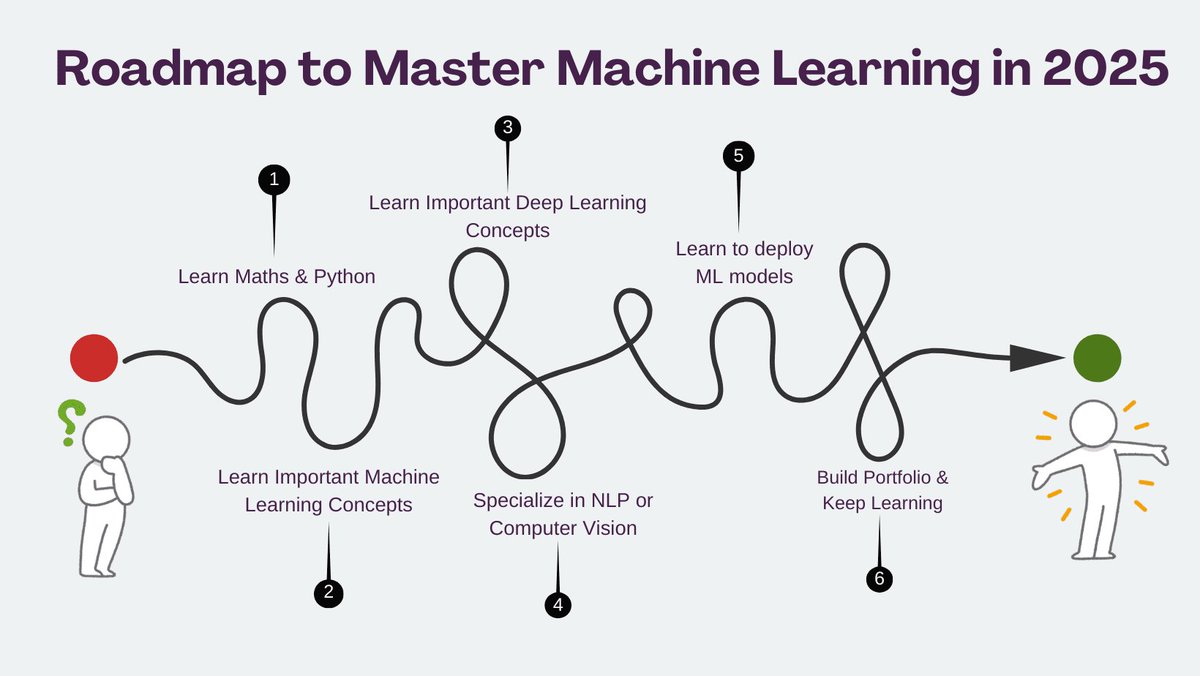
🧵 How to Become a #MachineLearning and #AI Expert in 6 Months (Detailed, Free Resources)
Ready to dive deep into ML? From my 5 years of experience in ML and AI, here's a month-by-month roadmap using comprehensive, high-quality, and free resources. Let's get started! 👇
1
1
7
2,160
The Information Bottleneck (IB) principle offers a profound lens for understanding why deep networks generalize despite overparameterization. Introduced by Tishby et al. (2015), IB frames learning as an optimal compression problem: a network layer should retain only information in input X that is predictive of label Y.
Formally, IB minimizes:
L = I(X; T) - β·I(T; Y)
where I(·;·) denotes mutual information, T is the learned representation, and β controls the compression-prediction tradeoff. The optimal solution satisfies:
p(t|x) ∝ p(t)·exp(-β·D_KL[p(y|x) || p(y|t)])
During SGD training, neural networks exhibit two distinct phases:
1. 𝐅𝐢𝐭𝐭𝐢𝐧𝐠 𝐩𝐡𝐚𝐬𝐞: I(X;T) and I(T;Y) both increase rapidly as the network memorizes patterns
2. 𝐂𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 𝐩𝐡𝐚𝐬𝐞: I(X;T) decreases while I(T;Y) remains stable-the network forgets irrelevant input details while preserving task-relevant signals
The critical insight: 𝐠𝐨𝐨𝐝 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧 𝐜𝐨𝐫𝐫𝐞𝐥𝐚𝐭𝐞𝐬 𝐰𝐢𝐭𝐡 𝐜𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧. Layers progressively discard nuisance information (noise, spurious correlations) irrelevant to Y. Empirically, the penultimate layer's I(X;T) correlates strongly with test accuracy.
For a k-class problem, the representation T at the final hidden layer satisfies I(T;Y) ≤ H(Y) ≤ log k bits, bounding retained label information. Stochastic gradient noise implicitly implements a form of variational optimization over this constrained objective.
Recent work (Saxe et al., 2018) nuances this: without nonlinearities or specific activation symmetries, networks don't always compress. However, with ReLU-like activations and finite precision, compression emerges naturally as an implicit regularizer.
This explains a paradox: massive networks (millions of parameters) generalize well because they learn 𝐦𝐢𝐧𝐢𝐦𝐚𝐥 𝐬𝐮𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐭 𝐫𝐞𝐩𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧𝐬-encoding exactly what Y requires and nothing more, effectively solving an information-theoretic optimization that classical statistical learning theory struggles to characterize.
#InformationBottleneck #DeepLearningTheory #Generalization
18
Mohit 😼 retweeted

1. Never tell anyone how much you make
2. Get proper sleep (or at least try to do so)
3. Live in a way no one else does (do the opposite)
4. Read every day
5. Learn to communicate
6. Go off the radar for 48 hours
7. Use AI the right way
8. You are one DM away from changing your life
9. Find a stress protocol that works for you
10. Learn how to communicate your emotions (#1 way not to get depressed)
11. Always minimize (less is more)
12. Phone calls > podcasts, audiobooks, and music
13. Change your workspace often (Creativity hack)
14. Spontaneity
12
60
656
28,728


uh here we go again.

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
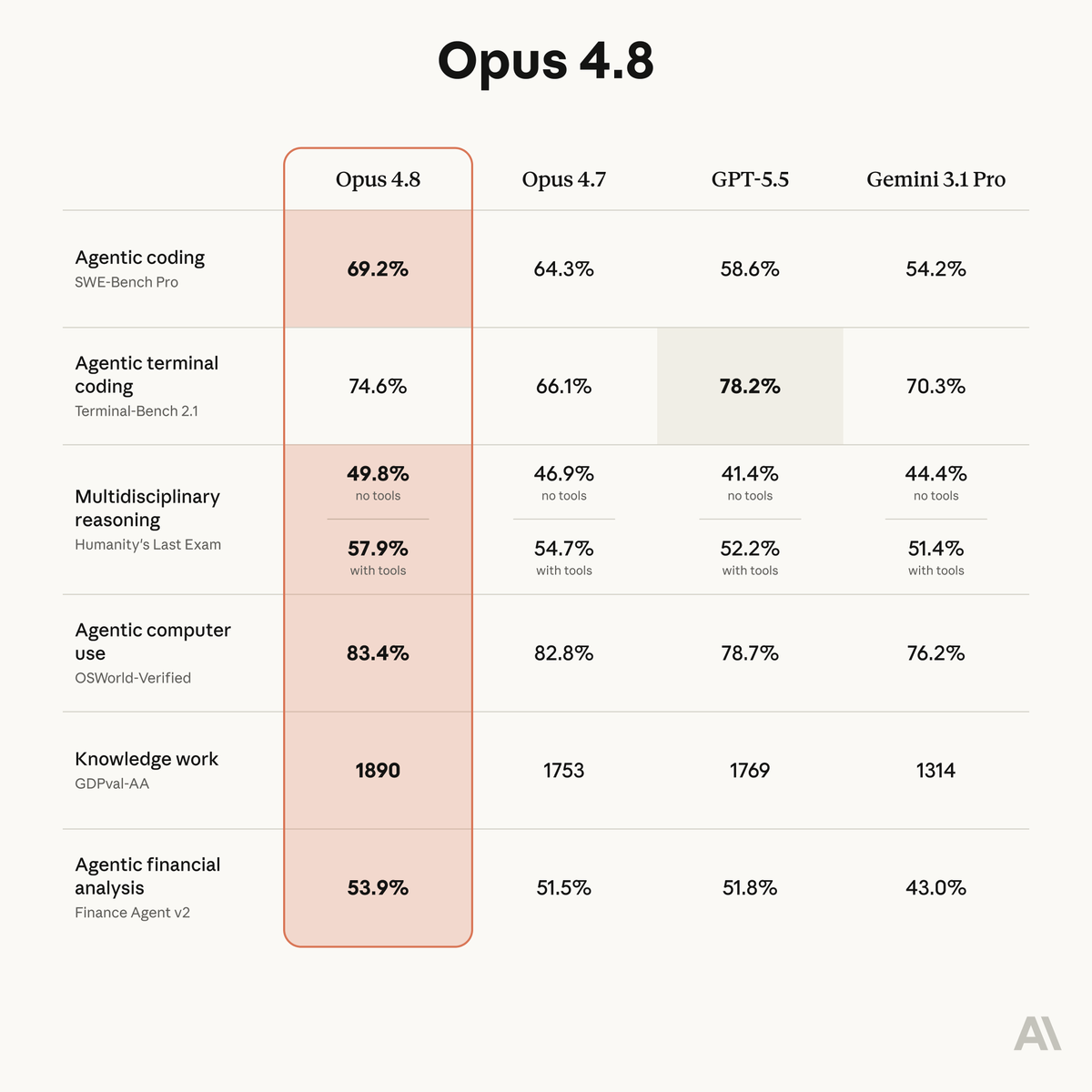
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
36
Mohit 😼 retweeted

May 27
> lifted 30 crore indians out of poverty
> free ration to 80cr poor people
how both things work simultaneously?
May 27

What's the biggest scam in history?
69
381
2,929
54,755


I never really understood why people call their newly bought gadgets or vehicles a “new toy.”
For someone coming from a lower middle-class background, it’s never just a toy. It carries years of hard work, sacrifices, patience, and silent prayers behind it.
Every small achievement feels deeply personal because you know what it took to reach there.
Grateful. Blessed. Proud. ❤️
Definitely not a toy. 🧿
6
18
2,328
Reading the comments made me realize how many people started watching cricket after COVID and still don’t understand the game.
Anyway - Arjun bowled really well. 🥎
May 23

Well done, Arjun. ❤️
Proud of the way you’ve carried yourself through this season, always believing in your ability, staying patient, working hard quietly, and remaining positive despite having to wait for your opportunity till the very last match.
Cricket tests patience as much as skill, and you handled both beautifully today.
Keep your feet on the ground, and continue being in love with the game like you always have.
Love you always.👏

109
एक माँ से बड़ा योद्धा कोई नहीं होता ♥️

She lost her husband in an accident.
Now she’s working as a Zomato delivery worker to feed her family.
She even takes her two kids with her during deliveries.
Respect to such brave women.
She is a million times better than feminist girls like Rebel Kid Apoorva.

102
Lagrangian formulations for implicit neural representations and solver theory-
The Lagrangian formulation of implicit neural representations (INRs) reveals a deep connection between neural networks and classical mechanics-unifying network architecture with variational principles.
An INR parameterized by weights θ represents a continuous signal as f(x; θ), where x ∈ ℝᵈ. The Lagrangian approach introduces a functional:
ℒ[θ] = ∫_Ω L(x, θ, ∇θ, ∇²θ...) dx
Minimizing this action S = ∫ ℒ dt yields Euler-Lagrange equations: ∂ℒ/∂θ - ∇ · (∂ℒ/∂∇θ) = 0
This connects to solver theory: training INRs is equivalent to solving a boundary value problem. The network dynamics follow:
M(θ)θ̈ D(θ)θ̇ = -∇V(θ)
where M is the mass matrix (parameter metric) and V captures reconstruction loss.
Key insight: symplectic integrators preserve the symplectic structure of (θ, ∂ℒ/∂θ), ensuring long-term stability-critical for physics-informed INRs.
Alternatively, treating θ as generalized coordinates gives the Hamiltonian: ṗ = -∇V(θ), θ̇ = M⁻¹p, enabling geometrically stable optimization via reversible dynamics solvers like Ritter et al.'s port-Hamiltonian approach.
This framework connects directly to adaptive solvers, residual networks as discrete symplectic systems, and the geometry of loss landscapes. The action principle provides principled regularization beyond simple L² reconstruction, with natural energy conservation properties.
#LagrangianMechanics #ImplicitNeural #SolverTheory #MachineLearning
1
3
133
If he plays all 20 overs - almost every bowler will get hit for four sixes in their spell by him.
Crazy kid 🤯
Apr 29

Vaibhav Suryavanshi has smashed 61 sixes from his 290 balls career in the IPL so far. 🥶
- A six every 4.75 ball. 🤯

108