
Cloud, AI, XR | Engineer
Joined May 2012
- Tweets 596
- Following 445
- Followers 378
- Likes 12,937
80 Photos and videos














Ever dreamt of having a job where you deliver mail to the residents of a tiny planet? Us too.
messenger.abeto.co
#webgl #threejs
435
2,735
21,383
3,218,369
Ben retweeted

15 Oct 2024
@NVIDIAAI recently released InstantSplat which allows for fast 3D reconstruction, so I decided I wanted to make a demo of it using @rerundotio and @Gradio! It's one of the fastest ways to go from sparse images -> Gaussian splat I've come across. pablovela5620-instant-splat.…
3
70
353
27,814
Ben retweeted

8 Oct 2024
We will be able to turn regular 2D videos into volumetric 4D content sooner than you expect.
28
121
1,072
104,569
Ben retweeted

25 Sep 2024
Metas iPhone moment

439
269
9,546
1,338,765
Ben retweeted

29 May 2024
Building a drag-and-drop editor for creating @discord games and Activities, all within Discord.
Yes, right inside Discord 😱
Think of it as a mix between Webflow and Roblox, to create games and community experiences on Discord.
@JoshLu @AnjneyMidha
11
16
229
25,185
Ben retweeted

10 May 2024
Today we'd like to humbly share some thoughts about an **important but often-overlooked** feature of UI in XR -- UI Mobility 💡 in this thread #CHI2024
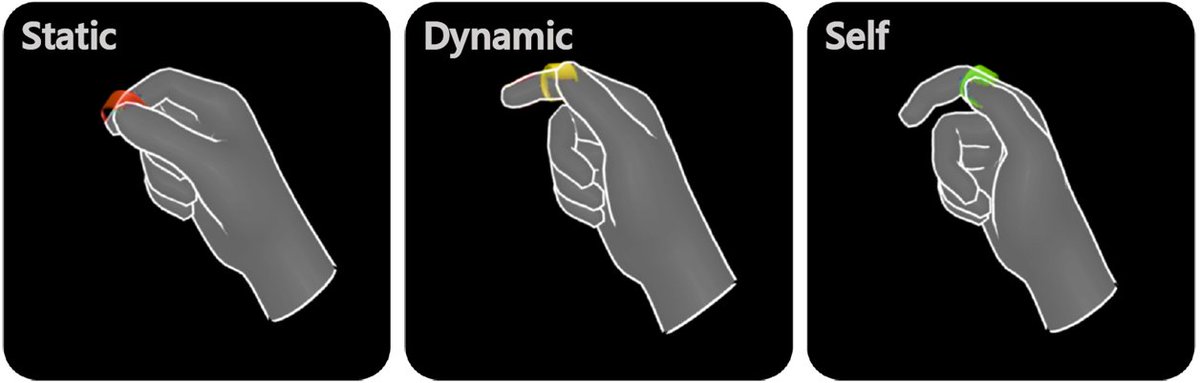
ALT A human hand is pinching with the thumb resting on the tip, middle, and the base of the index finger, which respectively indicates "static", "dynamic", and "self" mode.
4
18
168
26,524
Ben retweeted

9 May 2024
Here’s an early preview of ElevenLabs Music.
All of the songs in this thread were generated from a single text prompt with no edits.
Title: It Started to Sing
Style: “Pop pop-rock, country, top charts song.”
329
1,003
4,574
1,086,666
Ben retweeted

20 Apr 2024
"Every pixel will be generated (not rendered)" - J. Huang
The TV shows, movies, ads, video games and more.
We're getting there 👇👇
20 Apr 2024

EndlessDreams: Voice directed real-time video at 1280x1024. A 2 min video gen'ed directed by my voice in 2min. A crude first start. Don't confuse smooth 60 sec vids that take hours to do. This is RT exploration of gems hidden in the latent space. This is only the beginning.
3
3
11
2,623

11 Apr 2024
I’m here at Laval Virtual demoing @Luminous_XR mixed reality applications at the Meta booth. Come swing by if you’re attending!
6
132
16 Feb 2024
AI rendering in game dev is inevitable. Anyone working in this space?


5
199

Job Simulator is one of the highest selling VR games of all time and its technical lead has a message for developers:
You need to have a hand tracking plan now:
uploadvr.com/editorial-hand-…
25
40
302
148,264
Ben retweeted

21 Dec 2023
Google just revealed an ABSOLUTE depth estimation model 🤯
As opposed to recent depth models (Marigold, PatchFusion) which aim for maximum details, DMD aims to estimate the ABSOLUTE depth (in meters) within the image
More details below ⬇️⬇️
27
258
1,806
199,523
10 Dec 2023
Oh god why would you showcase the power of mixed reality using a 2D image.
9 Dec 2023

Just add mixed reality 👩🍳
Take your hobbies to the next level with #MetaQuest. Get yours: metaque.st/Order
5
297
Ben retweeted
7 Dec 2023
This scene was scanned using only 3 pictures 🤯
In my opinion, this was the biggest flaw of NeRFs & 3D Gaussian splats: they are trained from scratch every time with no knowledge of the world. With ReconFusion, we now acquire it from diffusion models
More examples below ⬇️⬇️
24
79
665
100,165

Ben retweeted

23 Nov 2023
Excited to present our new paper "LucidDreamer", a new #3D #gaussiansplatting scene generation pipeline! LucidDreamer can generate high-quality 3D gaussian splatting scenes from any text or image prompt.
Project page 👉: luciddreamer-cvlab.github.io…
Paper 📃: huggingface.co/papers/2311.1…
19
208
1,003
248,744
Ben retweeted

22 Nov 2023
People are just starting to realize the power of Local LLMs
Especially with new Apple chips. It's a game-changer
Let me show you:
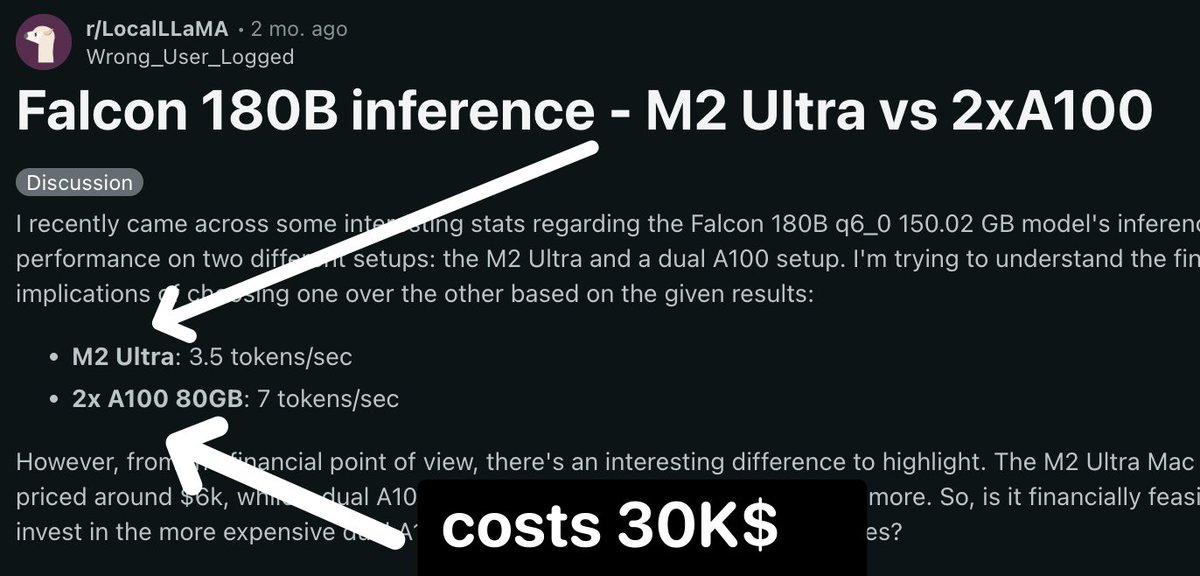
Falcon is 180B LLM. It is the size of GPT3.
How fast would it run on your Mac?
Apple M3 Max: 3.5 tokens/sec
We can compare it to 2 x A100 (2 x 30k$)
2x A100 80GB: 7 tokens/sec
Now add to this the recent speed of @NousResearch & @teknium with models like openHermes
And the fact that soon they will add Vision functionality to send images
x.com/Teknium1/status/172661…
and we get real competition to commercial models from OpenAI and Anthropic
More of independent companies start to publish their model weights
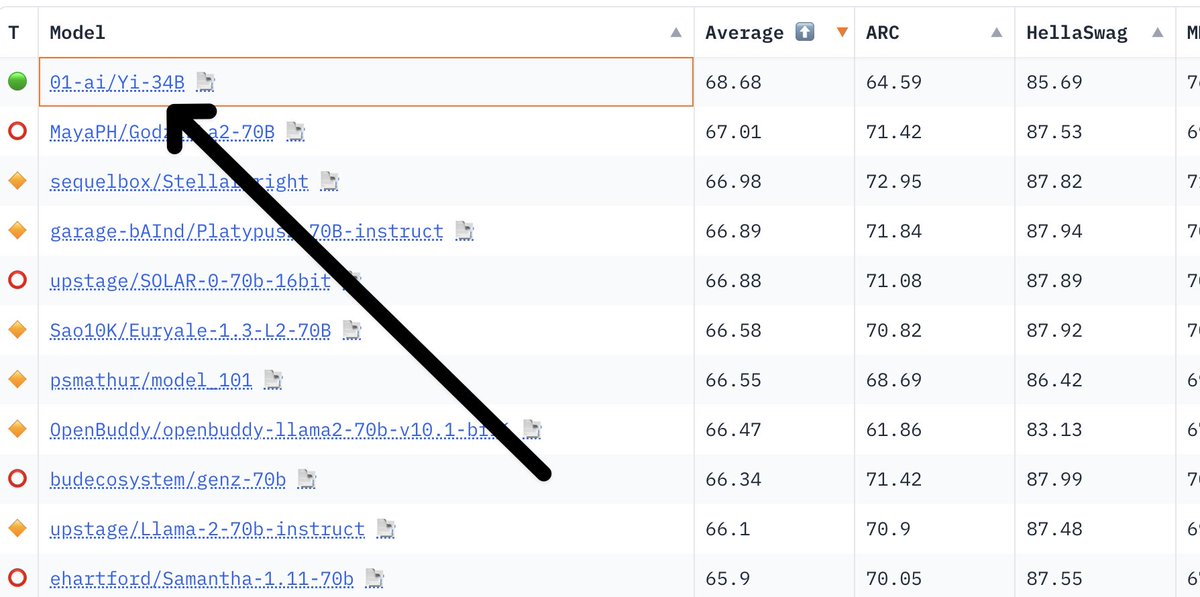
Take 01.ai team from China. It is currently leading the OSS leaderboard in quality & context size
01 team has 200k context window model.
It's the 7 copies of Shakespeare's Hamlet which can fit onto a single prompt
GPT4 turbo has only 128K
7B models like Mistral are already running at 40 tok/s!
This is insanely fast! I have run a test on my old M1 a gif below to give you a feeling of the speed of it.
Absolutely stunning work is done by @ggerganov. Georgi & llama.cpp community have literally shaped the progress of open source models with llama.cpp project. It allows you to run any LLM on your computer. You can even run llama on your ios with it
I am incredibly bullish on Apple metal & local computations.
There are many interesting projects rising around it, one that came to my mind is @opentensor – decentralized commodity of computing resources like selling your GPU to someone
And I haven't even started on the power of webGPU & Web LLM
What other interesting stuff have you seen? share in comments


87
372
2,589
976,771
Ben retweeted

16 Nov 2023
Build for visionOS with Unity Pro, Enterprise and Industry license starting today! We're opening up the closed beta for PolySpatial and visionOS support letting unity developers build for Apple Vision Pro!
I can't wait to see what you build!
More info: create.unity.com/spatial
8
59
288
75,213
Ben retweeted

14 Nov 2023
This is huge!!
Spline now supports Gaussian splats 👀
You can now capture anything in 3D from your phone with Luma, export the .ply file, import it into spline, crop, adjust, and embed on your site.
Luma Spline Webflow is an insane 3D workflow 🔥
99
925
7,567
1,139,654