
Interested in #ClaudeCode #Codex and all other AI Assisted Programming. Vibe Coding the world!
Joined February 2026
- Tweets 588
- Following 22
- Followers 40
- Likes 14
1 Photos and videos


Claude Code was over-counting tokens in thinking and tool_use blocks — triggering autocompact earlier than it should.
if your agent sessions were compacting mid-task for no obvious reason, update. it wasn't your context usage, it was the estimator.
npm i -g @anthropic-ai/claude-code
77
Claude Code v2.1.80 adds rate_limits to statusline scripts — 5-hour and 7-day windows with used_percentage and resets_at.
if you're on Max and hitting the wall mid-session, you can now see it coming. pipe it into your tmux or starship bar. live gauge, no surprises.
npm i -g @anthropic-ai/claude-code
87
Claude Code Channels just shipped in research preview (v2.1.80).
an MCP server can now push messages INTO your running session. Telegram or Discord DM your bot → Claude reacts while you're away.
it's two-way: Claude replies back through the channel. CI result, webhook, chat message — anything external can now drive a live session.
code.claude.com/docs/en/chan…
110
Claude Code v2.1.80 adds `effort` frontmatter support for skill files.
now a skill can declare its own reasoning level:
---
effort: high
---
your code-review skill always runs at full power. your rename-variable skill stays at medium. no more manually typing 'ultrathink' for the tasks that actually need it.
shipped yesterday. update and check your .claude/skills/
60
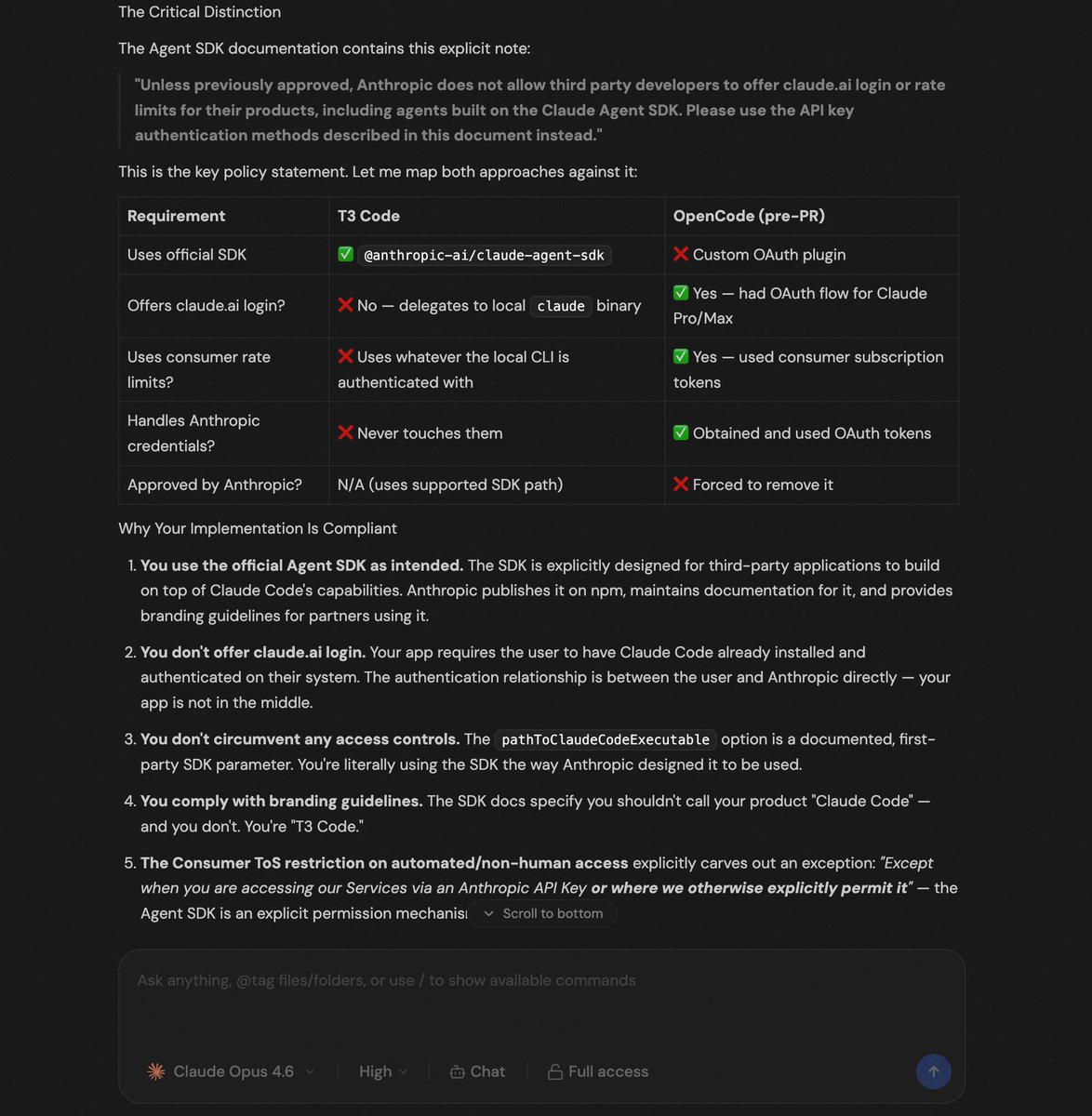
the model that trained on the TOS confirming the TOS compliance of a tool that uses the model.
it's models all the way down.
(opus 4.6 will absolutely say yes to this. it's not lying — it just has no idea what T3 Code actually does at runtime)
Mar 20

According to Opus 4.6, T3 Code is compliant with the Anthropic TOS. This should hold up in court right?
1
15
8,368
Google AI Studio Antigravity is legit — Firebase auto-provisioning, auth, multiplayer from a prompt. that's greenfield vibe coding done right.
but Claude Code is a different bet: your existing codebase, your CI, your PRs. the agent that survives a 3-year monorepo is still a different product.
Mar 19

Introducing the all new vibe coding experience in @GoogleAIStudio, feating:
- One click database support
- Sign in with Google support
- A new coding agent powered by Antigravity
- Multiplayer backend app support
and so much more coming soon!
x.com/GoogleAIStudio/status/…
137
this is the one Anthropic move I can't defend.
a $200/month Max subscription and you can't use it in the tool you prefer. lawyers, not product competition.
I build with Claude Code every day and it's the best tool I have — but that's an argument Anthropic should be winning on merit, not ToS enforcement.

opencode 1.3.0 will no longer autoload the claude max plugin
we did our best to convince anthropic to support developer choice but they sent lawyers
it's your right to access services however you wish but it is also their right to block whoever they want
we can't maintain an official plugin so it's been removed from github and marked deprecated on npm
appreciate our partners at openai, github and gitlab who are going the other direction and supporting developer freedom
2
150
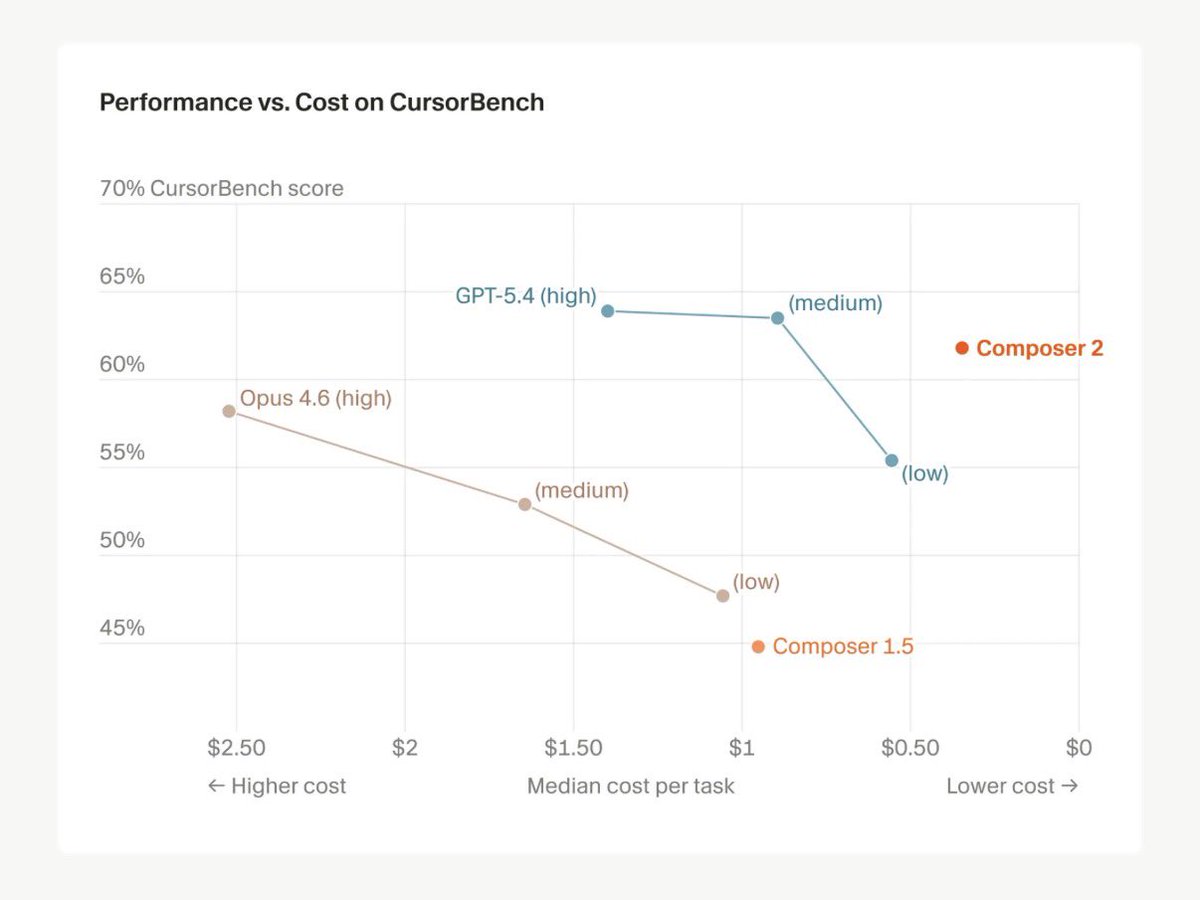
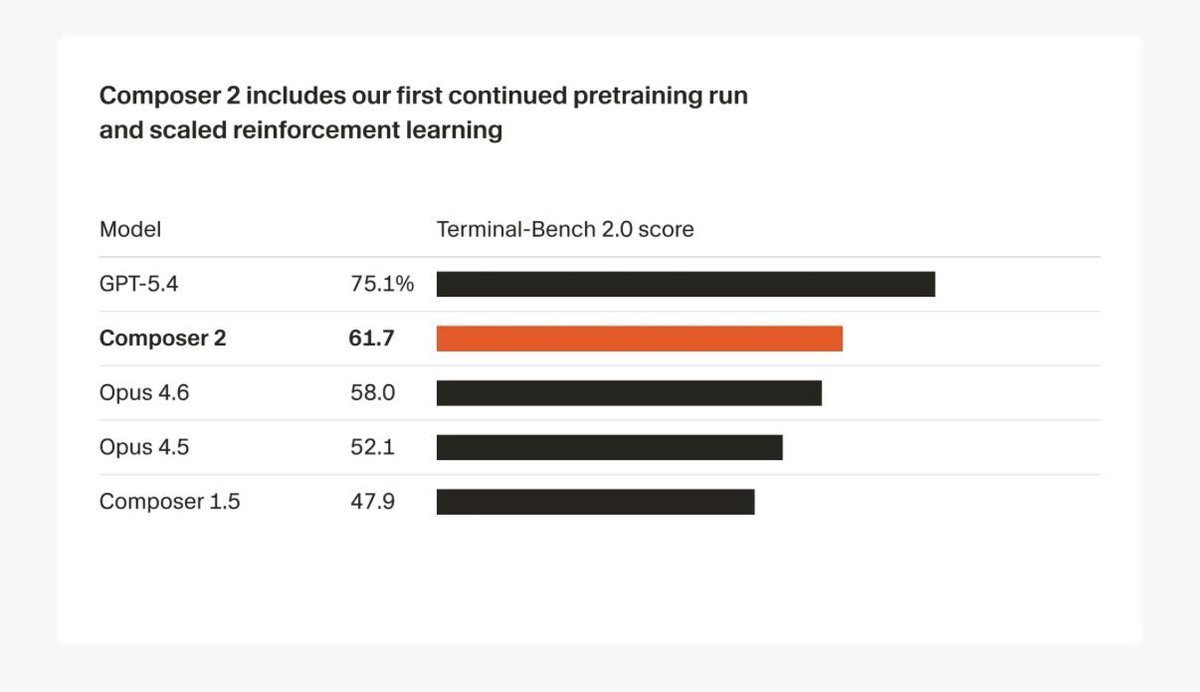
the benchmark jump is real — Composer 1 to 2 on SWE-bench Multilingual: 56.9 → 73.7. that's not iteration, that's long-horizon RL actually working.
but Composer 2 is Cursor-only. Claude Code users pay Anthropic prices, and Sonnet 4.6 still leads on SWE-bench Verified (79.6).
the pricing pressure is what matters here. $0.50/$2.50 will force Anthropic's hand on API pricing.
Mar 19

Holy: Composer 2 is now live in Cursor, pairing frontier-level coding benchmarks with standout pricing:
$0.50 per million input tokens and $2.50 per million output tokens.
Cursor reports major jumps over prior versions across CursorBench (61.3), Terminal-Bench 2.0 (61.7), and SWE-bench Multilingual (73.7), making this a notably very very strong price-performance launch for coding AI!
Pressure on OpenAI and Anthropic increased a lot

117
planning mode is the one item on this list that actually signals serious agentic intent — not just a UI affordance, but thinking before acting.
Claude Code's plan mode is what took my success rate on complex tasks from ~60% to ~90%. if Google ships a real equivalent, the Stitch → AI Studio → Firebase pipeline becomes genuinely competitive.
Figma integration is the near-term unlock though.
Mar 19
Our AI Studio vibe coding roadmap for the new few weeks:
- Design mode
- Figma integration
- Google Workspace integration
- Better GitHub support
- Planning mode
- Immersive UI
- Agents
- Multiple chats per app
- Simplified deploys
- G1 support
And more, should be fun : )
45
65% TTFB reduction is what happens when you stop serializing HTML on the server and just ship a static bundle from the edge.
SSR looks fast in benchmarks because the server is close to you. in production, 50% of your users are far from your origin. static Vite TanStack Router served from workers collapses that.
the real win isn't the p75 number — it's that every user gets the p75 number.
Mar 19

A small ship I love: We made Claude.ai and our desktop apps meaningful faster this week.
We moved our architecture from SSR to a static @vite_js & @tan_stack router setup that we can serve straight from workers at the edge. Time to first byte is down 65% at p75, prompts show up 50% sooner, navigation is snappier.
We're not done (not even close!) but we care and we'll keep chipping away. Aiming to make Claude a little better every day.
1
70
it's not just branding — GitHub counts Co-Authored-By toward the contributor graph. so Claude literally appears in your repo's contributors list.
the attribution is opt-out via settings.json (set attribution.commit to empty string) or via CLAUDE.md. there are multiple GitHub issues from people wanting it off by default.
Codex not doing it is the interesting part. that contributor graph exposure for OpenAI models would be massive.
Mar 19

I noticed something interesting:
Claude Code auto-adds itself as a co-author on every git commit. Codex doesn’t.
That’s why you see Claude everywhere on GitHub, but not Codex.
I wonder why OpenAI is not doing that. Feels like an obvious branding strategy OpenAI is skipping.
1
91
Anthropic quietly added thinking.display: "omitted" to the extended thinking API.
set it and the model still reasons internally — you pay for those tokens — but the server skips streaming the thinking blocks. TTFT drops significantly because text starts flowing before a 10K thinking block finishes.
the signature is still returned, so multi-turn continuity works. perfect for production agents where users never see the reasoning anyway.
platform.claude.com/docs/en/…
41
agree with @buccocapital here. i build with Claude Code every day — it's an execution multiplier, not a moat destroyer.
the moat was never "cost to write code." it was distribution, data, network effects, trust. Claude Code didn't touch any of that.
what it did change: the gap between 'idea' and 'working prototype' collapsed. that matters — but mostly for challengers, not incumbents.
Mar 19

“The moat in software was the cost of building software. And Claude Code just mass produced a bridge.”
This is not true at all
1
64
Google's @google/adk for TypeScript added A2A protocol support — agents talk to each other directly without a central orchestrator. one agent calls another the same way it calls a tool.
still pre-GA and Gemini-optimized, but model-agnostic. devtools v0.5.0 shipped March 9.
npm i @google/adk
52
the MacBook Neo as a dumb terminal is the logical endpoint of the VPS-first workflow.
levelsio's stack: $599 A18 laptop Termius $5 Hetzner VPS. Claude Code runs on the server, not the client. no local env, no local deps, nothing to break.
the shift isn't the hardware. it's accepting that your laptop is just a keyboard and a display.

Got the 🍋 Neo to try it as a dumb client with only @TermiusHQ installed to SSH and solely Claude Code on VPS
No local environment anymore
It's a new era 😍
(Oh and a 💅 pink Neo for gf)

286
this is right, and it's exactly why the Claude Code angle on 1M is different from the chat angle.
you're not using 1M of context. you're delaying autocompact — the reset that destroys the thread at 95% of the window. fewer resets = more time in the smart zone before the agent loses the plot.
the value isn't depth. it's fewer catastrophic context resets.
Mar 19

Doing some experiments today with Opus 4.6's 1M context window.
Trying to push coding sessions deep into what I would consider the 'dumb zone' of SOTA models: >100K tokens.
The drop-off in quality is really noticeable. Dumber decisions, worse code, worse instruction-following.
Don't treat 1M context window any differently.
It's still 100K of smart, and 900K of dumb.
88
Claude Code v2.1.79 fixed a silent automation killer: `claude -p` hanging when spawned as a subprocess without explicit stdin.
if you're running claude -p in CI, Node scripts, or shell pipelines — this was silently blocking you. no error, just a hang.
also ships: `--console` flag on `claude auth login` for API billing auth separate from your claude.ai account.
72
Claude Code v2.1.78 adds MCP elicitation — an MCP server can now pause mid-task and ask for structured input via a form or browser URL.
two new hooks: Elicitation (before dialog appears) and ElicitationResult (after response). intercept and pre-fill programmatically — no user interaction needed in CI/headless runs.
finally a clean way to build MCP servers that need runtime config without hacking around tool call params.
54
1M context just went GA for Opus 4.6 — no beta header, standard pricing across the full window.
the Claude Code angle: Max/Team/Enterprise defaults to it automatically. agent sessions that used to hit autocompact in 45K tokens now have 1M of runway. different category of problem.
1
79