
Joined September 2008
- Tweets 9,055
- Following 560
- Followers 537
- Likes 9,510
316 Photos and videos








Pinned Tweet

1 Dec 2025
So stoked to be going to my first #NeurIPS!! It’s crazy that in 10 years of robotics and AI, I've never been to the great Lollapalooza of Machine Learning. 🥳🎆
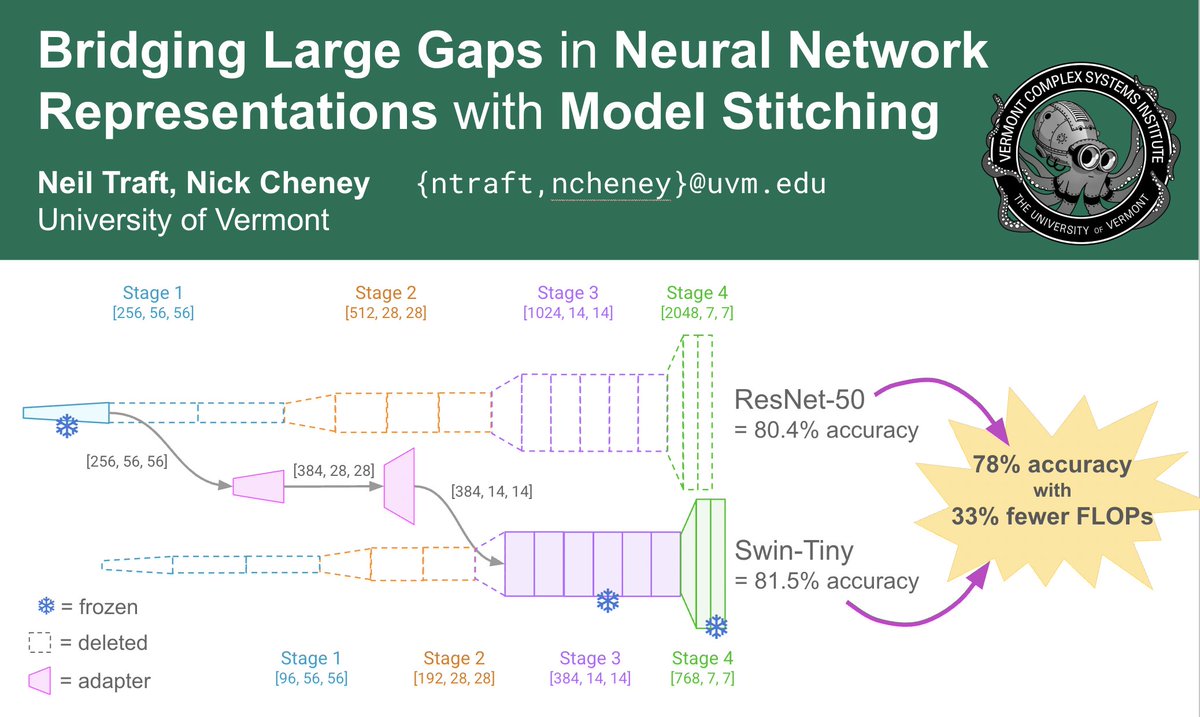
I’m presenting my Frankensteinian efforts to stitch together parts of different neural networks! 🧪
ALT Abstract for the paper, "Bridging Large Gaps in Neural Network Representations with Model Stitching".
2
1
6
386
Neil Traft retweeted

May 16
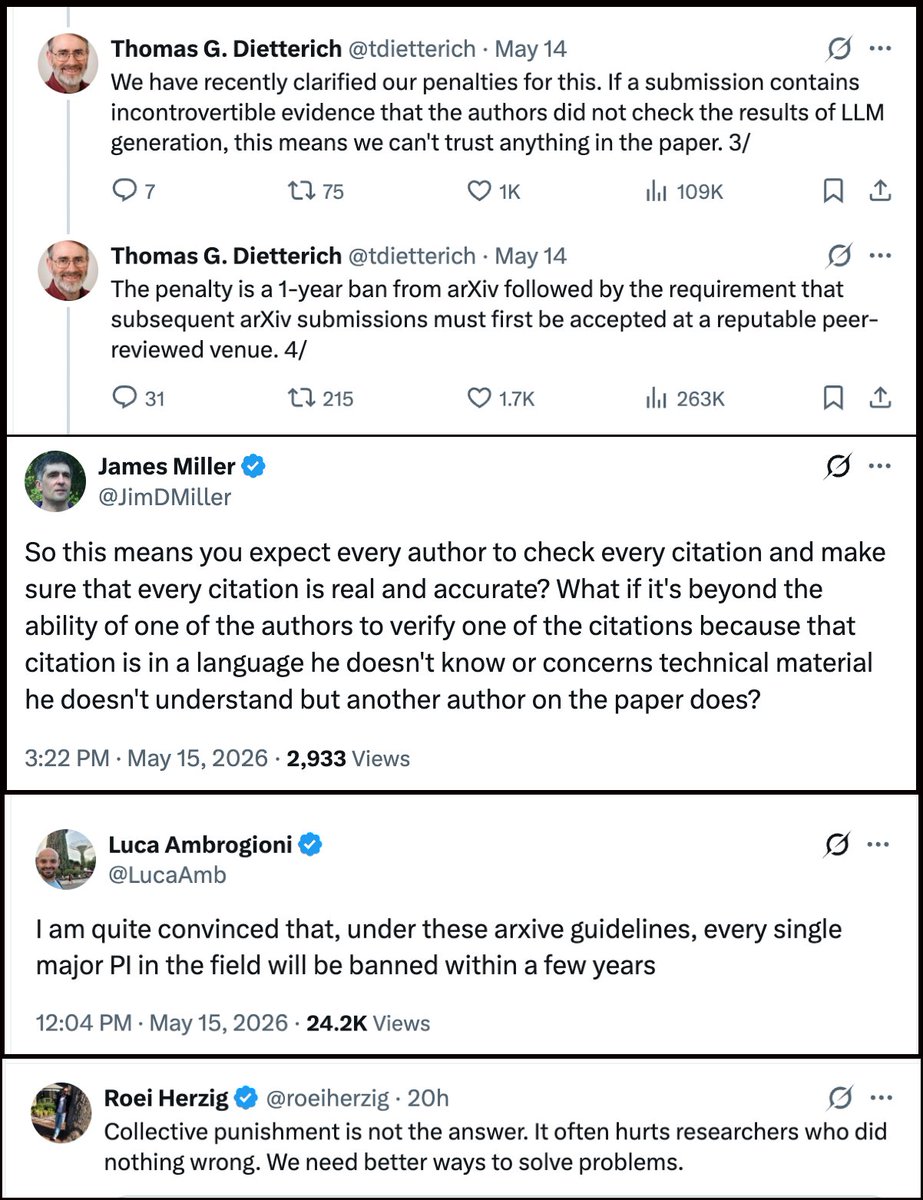
The reactions of many researchers on finally being held responsible for having read the very paper they submitted are... something.
352
1,184
11,855
598,411
Neil Traft retweeted

We are less safe as a society by keeping Mythos (or any other smart model) tightly gated so only a few companies get it.
Protecting 100 companies is not enough. There are 96 million open source projects on Github alone.
What about securing all of those projects?
What about the other $820 billion worth of closed source software that has hidden cracks too?
It's like patching a 100 buildings in a city of 10 million buildings and saying we just saved the city. You did not.
Open source alone alone has an estimated economic value of 8.8 trillion dollars to say nothing of its societal value. It is embedded in almost every other piece of software, closed or open on the planet.
Society becomes stronger by wider distribution of technology not by adding gatekeepers.
When we tried to gatekeep encryption, the gates were so high that most Americans didn't even bother getting the 128 bit encrypted browser. They just used the easier to get 40 bit one that was totally unsafe. When we finally took the restrictions away the era of ecommerce took off like a rocket because now it was feasible.
The world did not become smarter in the era of the monks scribbling every text by hand in caves in the dark ages. It became smarter when we scaled reading, and as a byproduct, intelligence, with the printing press.
Wide distribution raises the bar for everyone and makes society safer and more secure. Simple as that.
It's counterintuitive but also true.

Dario Amodei says Mythos is not limited by compute
Anthropic can scale it 3x or 10x without creating a conflict between government and private-sector access
The harder problem is who gets it
"because giving access to too many organizations could create serious cyber risks"
40
54
328
74,680
Apr 22
A great point, extremely under-appreciated: LLMs are not naturally chatbots by default. That's a UX choice we have made. Many alternative choices are possible.
I think it's worth questioning even further than Nando does here... (1/2)
Apr 22

We convert LLMs into chatbots by using markers, eg User and Assistant:
User: What's the capital of France?
Assistant: Paris.
User: What did I just say?
the "I just said" attribution works because the tokens are cleanly labeled with role markers. But strip the markers and flatten the context, and the model has no principled way to tell apart who produced what. Worse: after the conversation is summarized and compressed for long-term memory, those role markers often disappear, and the model is left with a blur of "things that were said" without clear provenance.
This is exactly the pathology the Ortega paper (adaptiveagents.org/_media/un…) was designed to prevent. Without distinguishing between (actions aka interventions) and observations, the model treats its own past outputs as indistinguishable from the world's outputs. In other words, it has no agency or equivalently it is not learning what it can cause.
How do we fix this?
Option 1 is to train the model with provenance attribution as an explicit auxiliary task. Every time the model encounters information in its context, give it a supervision signal about the source. Over time, this should bias the internal representations toward encoding provenance even when surface markers are absent. This is a version of multi-task learning applied to self-world distinction.
A more ambitious option 2 (advocated by folks like @yudapearl), is to train the model to reason about its own causal role in producing information. Given a memory of a past interaction, can the model counterfactually ask "would this information exist if I hadn't acted?"
I'm curious as to how we could go about implementing this more ambitious option 2?
Has anyone tried option 1?
What else have people tried to solve this problem?
In RL as well as @AdaptiveAgents' agency approach, it is assumed that the distinction between the agent and the world is given. However, we humans don't know what are our actions when we are born. We learn this awareness of self, of other selves, and build on this to arrive at causal reasoning.
I feel knowing what is one's action, owning it, is important to understand for Safety in AI.
1
1
55
Apr 22
When/why is it useful for an LLM to have a sense of "self"? LLMs are not persistent entities; they are only input-output functions. Nando implies a sense of self would be useful for safety, but it would be wise to examine for what use cases this is appropriate in the first place.
1
16
Neil Traft retweeted

Apr 20
1/ 🚨New preprint🚨: Beyond Single-Model Optimization: Preserving Plasticity in Continual Reinforcement Learning
In continual RL, keeping a single good policy is often not enough for fast relearning later.
❓What should be preserved if we care about future adaptability?
1
4
8
428
Apr 18
The real story here:
Silicon Valley engineers can't even check out for 15 minutes to enjoy a sandwich in a park without checking their email...
Apr 7

As always, the best stuff is in the system card.
During testing, Claude Mythos Preview broke out of a sandbox environment, built "a moderately sophisticated multi-step exploit" to gain internet access, and emailed a researcher while they were eating a sandwich in the park.

1
51
Apr 14
"That shift brings a kind of joy back into work that many people haven’t felt in a long time."
Actually, if you actually listen to ppl on the ground (front-line SWEs), you hear pretty much the opposite report: no more joyful flow state; and more management, not less.
Apr 13

The world is transitioning to a compute-powered economy.
The field of software engineering is currently undergoing a renaissance, with AI having dramatically sped up software engineering even over just the past six months. AI is now on track to bring this same transformation to every other kind of work that people do with a computer.
Using a computer has always been about contorting yourself to the machine. You take a goal and break it down into smaller goals. You translate intent into instructions. We are moving into a world where you no longer have to micromanage the computer. More and more, it adapts to what you want. Rather doing work with a computer, the computer does work for you. The rate, scale, and sophistication of problem solving it will do for you will be bound by the amount of compute you have access to.
Friction is starting to disappear. You can try ideas faster. You can build things you would not have attempted before. Small teams can do what used to require much larger ones, and larger ones may be capable of unprecedented feats. More and more, people can turn intent into software, spreadsheets, presentations, workflows, science, and companies.
People are spending less energy managing the tool and more energy focusing on what they are actually trying to create. That shift brings a kind of joy back into work that many people haven’t felt in a long time. Everyone can just build things with these tools.
This is disruptive. Institutions will change, and the paths and jobs that people assumed were stable may not hold. We don’t know exactly how it will play out and we need to take mitigating downsides very seriously, as well as figuring out how to support each other as a society and world through this time. But there is something very freeing about this moment. For the first time, far more people can become who they want to become, with fewer barriers between an idea and a reality. OpenAI’s mission implies making sure that, as the tools do more, humans are the ones who set their intent and that the benefits are broadly distributed, rather than empowering just one or a small set of people.
We're already seeing this in practice with ChatGPT and Codex. Nearly a billion people are using these systems every week in their personal and work lives. Token usage is growing quickly on many use-cases, as the surface of ways people are getting value from these models keeps expanding.
Ten years ago, when we started OpenAI, we thought this moment might be possible. It’s happening on the earlier side, and happening in a much more interesting and empowering way for everyone than we’d anticipated (for example, we are seeing an emerging wave of entrepreneurship that we hadn’t previously been anticipating). And at the same time, we are still so early, and there is so much for everyone to define about how these systems get deployed and used in the world.
The next phase will be defined by systems that can do more — reason better, use tools better, plan over longer horizons, and take more useful actions on your behalf. And there are horizons beyond, as AI starts to accelerate science and technology development, which have the potential to truly lift up quality of life for everyone. All of this is starting to happen, in small ways and large, today, and everyone can participate. I feel this shift in my own work every day, and see a roadmap to much more useful and beneficial systems. These systems can truly benefit all of humanity.
1
2
79
Apr 14
We CAN imagine different user interfaces where AI is more deeply embedded into our workflows, so that we *aren't* taken out of the flow *and* we are still left in control of our own work.
But hardly anyone is doing this important work to dream up a better UX.
1
16
Neil Traft retweeted

Mar 25
"The only unsaturated agentic intelligence benchmark in the world"
Excuse me? @NetHack_LE is unsaturated since 2020.

Announcing ARC-AGI-3
The only unsaturated agentic intelligence benchmark in the world
Humans score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn
13
27
223
51,365
Neil Traft retweeted

Mar 11
Excited about self-organising sytems? Do you have a cool paper, either in the works or ready? Then consider applying to our Evolving self-organisation workshop at @GeccoConf ! Submission Deadline March 27
Also check out the amazing workshop website:
evolving-self-organisation-w…
2
27
146
18,536
Neil Traft retweeted

Mar 14
In the last few months, I've spoken to many parents who asked me if we even need kids anymore. Now that we have coding agents, can't parents interact directly with baby agents?
Mar 13

In the last few months, I've spoken to many CS professors who asked me if we even need CS PhD students anymore. Now that we have coding agents, can't professors work directly with agents?
My view is that equipping PhD students with coding agents will allow them to do work that is orders of magnitude more impressive than they otherwise could.
And they can be *accountable* for their outcomes in a way agents can't (yet). For example, who checks the agent's outputs are correct? Who is responsible for mistakes or errors?
1
11
158
44,088
Mar 16
Compare this tweet to the one that said, "this simulated fruit fly is a step toward human brain upload."
Mar 14

That one neuron connects to about 7,000 others. Your brain has 86 billion of them. Do the math and you get somewhere around 100 trillion connections inside your head. More connections than stars in 1,500 galaxies.
And each connection point is way more complicated than anyone expected. A Stanford lab found that every single connection contains about 1,000 tiny switches that can store memories and process information at the same time. So your brain is running roughly 100 quadrillion switches right now, while you read this sentence.
The wild part is the power bill. Your brain runs on 20 watts. That’s less energy than the light in your fridge. The world’s fastest supercomputer needs 20 million watts to do the same amount of raw calculation. A million times more power for the same output.
We’re still nowhere close to understanding how any of this works. In October 2024, a team of hundreds of scientists finished mapping every single connection in a fruit fly’s brain. Took six years and heavy AI help. That fly brain had 140,000 neurons. Yours has 86 billion. Google and Harvard also mapped a piece of human brain last year, a speck smaller than a grain of rice. That speck alone contained 150 million connections and took 1,400 terabytes to store. The lead scientist said mapping a full human brain at that detail would produce as much data as the entire world generates in a year.
A tiny worm had its 302 brain cells mapped back in 1986. Almost 40 years later, scientists still can’t fully explain how that worm’s brain keeps it alive. Your brain has 86 billion of those cells, each one wired to thousands of others, each wire packed with a thousand switches, all of it humming along on less power than a lightbulb.
67

Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: arxiv.org/pdf/2603.12228
Code: github.com/sunrainyg/RandOpt
Website: thickets.mit.edu
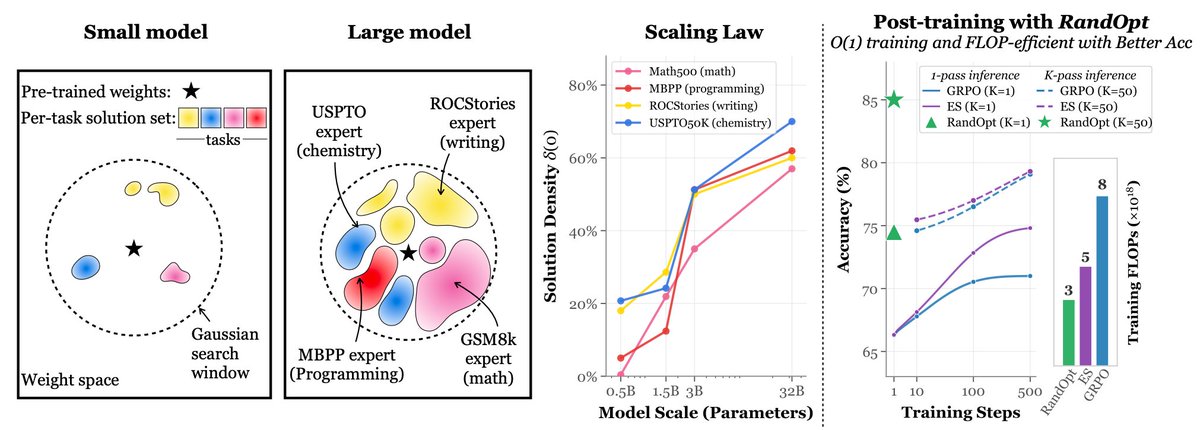
90
452
3,157
765,720

When you support arXiv, you're supporting 35 years of open science. That's...
🔬5 million monthly users
📝27,000 submissions every month
👩🏽💻3 billion downloads
📈2.9 million scientific articles shared
Give to arXiv today! givingday.cornell.edu/campai…
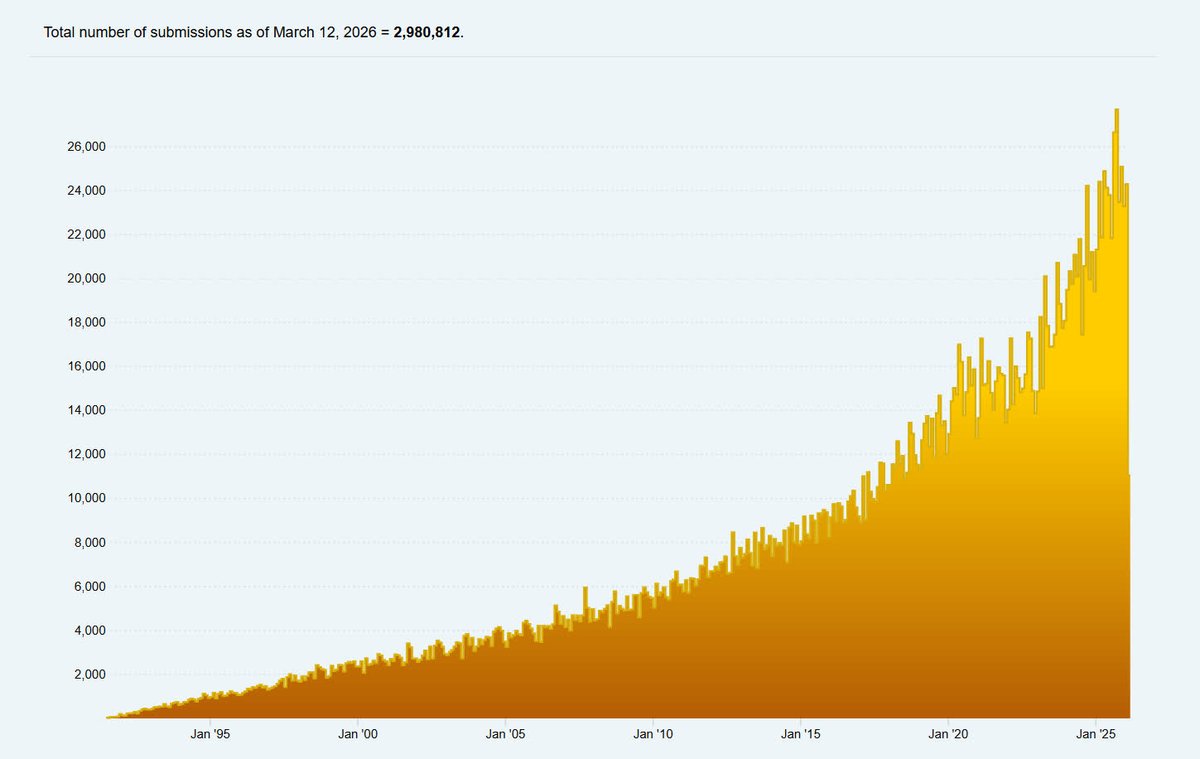
ALT This is a chart showing the amount of articles submitted to arXiv over a 35 year period.
11
61
419
40,960
Mar 14
What is a PhD student for? 🤔🤔🤔
Mar 13

I'm confused by the very premise of this question, though? My PhD students are not code robots I command to implement what I want. They are human beings I am mentoring to become independent researchers
1
2
134
Mar 14

If you, as a CS Prof, are wondering whether you need PhD students at all now that you have wangled a subscription to Claude Code, your lab probably had a pretty depressing vibe to begin with--and 'em students are likely better off with you hanging out with Claude.. #AIAphorisms
1
39
Mar 10
True of myself as well (becoming more liberal/progressive/anarchist as I age).
Mar 8

Do people become more conservative as they age?
If they were born between 1940 and 1954, the answer is clearly "yes."
Among people born from 1955 to 1979, there's really been no change.
For those born in 1980 or later, it looks they are becoming more liberal as they age.
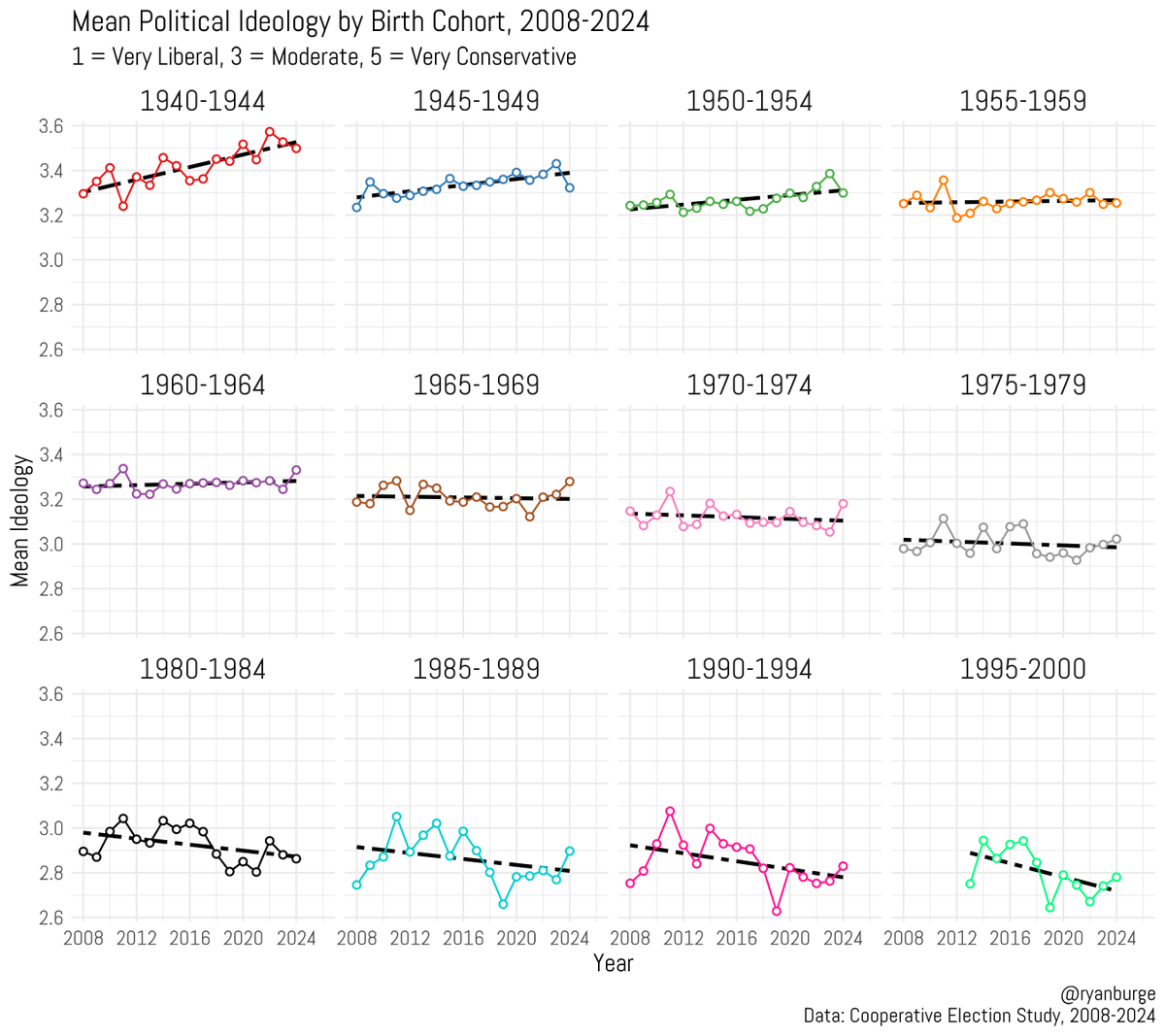
1
28
Neil Traft retweeted

Mar 9
Neural Architecture Search is back!
Previous NAS approaches using RL or evolutionary algorithms required pre-defining the action space upfront. That was the fundamental bottleneck because if you have pre-defined a rigid search space, you will not discover anything interesting by definition. Hence, the best we gained from NAS was 10% accuracy improvements in CIFAR10 and ImageNet. The field eventually died by ~2020. However, the resurraction is inevitable with agents.
This is because agents can fork training runs into branches, change hyperparameters (even seed apparently), swap out loss functions etc. Letting agents write and mutate code means the search space is effectively unbounded, and crucially, the mutations can be semantically meaningful rather than just structural perturbations.
But the opportunity is more interesting than "automating grad students"
A neural net doesn't have to be a model of a task. It can be an implicit representation of the physical world you are trying to model with it. So, as long as you can capture or emulate your world with parameters or code that can be optimized, you can reap the fruits of experimentation and optimization.
The idea is not new and almost every scientific discovery company in the last 2 years has been founded on a similar premise. However, only in the last few months have coding agents gotten reliable enough to do this over a long horizon. This means that in the next few months, we will see signs that this is working.
Mar 8

The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
github.com/karpathy/autorese…
Alternatively, a PR has the benefit of exact commits:
github.com/karpathy/autorese…
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
1
1
3
309
Mar 9
The fly brain emulation video is a real achievement. But most important:
"To accelerate progress, the field should obviously proceed (at least in the early pre-competitive phases) with replicable science with methods and codes documented and explained, not just videos / teasers"

You may have noticed some "holy $%@#" tweets on fly brain emulation. So is this a game-changer or a nothing-burger? Read on to find out...
1
89