
here for.. startups | code | ai | crypto | stocks
Joined June 2022
- Tweets 5,196
- Following 2,234
- Followers 204
- Likes 100,344
117 Photos and videos








Pinned Tweet

12 Jun 2024
When AI becomes super efficient, human craftsmen will be an exquisite class.
The minor imperfections made by human will make a product even more valuable
3
5
1,347
bee retweeted

Jun 14
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!

214
514
5,170
819,014


Do yourself a favor
Stop what you're doing.
This is important.
Even if you don't have a GPU.
Go download one of the latest local models and just keep it in storage.
There may come a time when you can no longer access intelligence freely
12-27B is enough.
Jun 14

Gemma 4 12B Coder is here and it's a game changer for local code generation. This GGUF model packs Google's latest gemma-4 architecture into a compact 12B size, perfect for running on consumer hardware. It's optimized for reasoning and thinking, making it ideal for developers who want fast, private coding assistance without the cloud.
80
152
2,432
318,021
bee retweeted

First production batch of the Forgix has arrived, our $50 simple FPGA Board. Get on the mailing list here forgix.tech/

23
24
310
19,159
bee retweeted

Jun 12
Today on the blog, we discuss a pathway for the second life of phones through the exploration of “phone cluster computing”, which can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction. More →goo.gle/4aJe5vO
92
278
2,271
1,107,418
bee retweeted

I’m yet to see an AI skill that can’t be replaced by a Bash script and an index with fuzzy search.
We’re still too early.

35
14
267
28,606
bee retweeted

Jun 12
flexigrip uses soft robotics to handle fragile objects
without damage pastries, irregular packages, delicate components, same gripper
rigid automation fails at variety compliant mechanisms dont
4
8
84
7,666

🚀 🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀
Jun 12

Today, @SpaceX (Nasdaq: SPCX) makes its public market debut with a $75Bn offering (pre-greenshoe) at $135 per share, marking the largest IPO in history.
Congratulations to the SpaceX team. We are honored to serve as joint lead bookrunner and sole stabilization agent.
8,744
17,297
138,462
14,106,473
bee retweeted

Jun 12
DiffusionGemma can now run at 2000 tokens/sec! ⚡
We made local DiffusionGemma inference 1.8× faster.
Run it on 18GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/models/diffu…
Jun 10

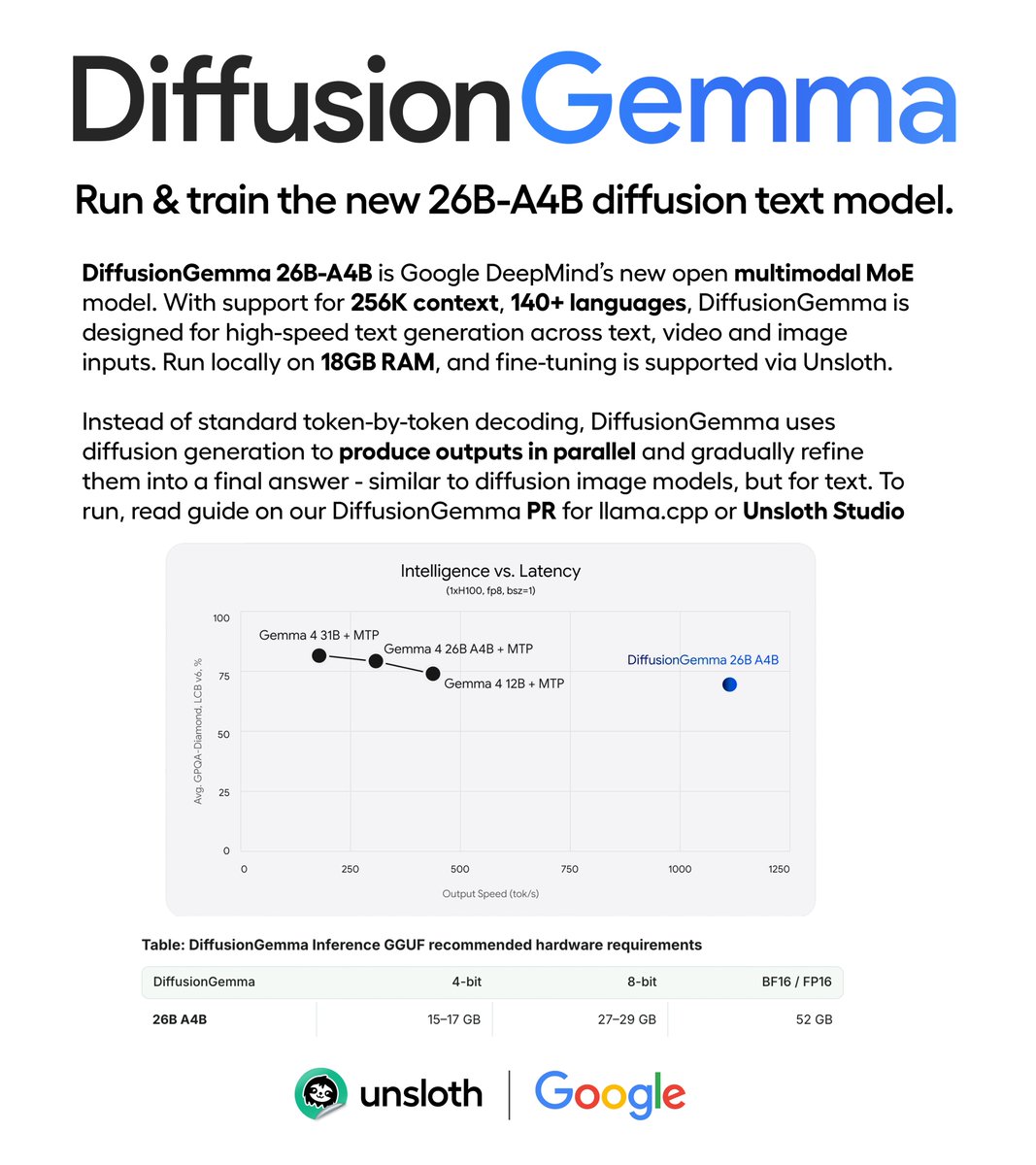
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
64
181
1,721
163,229
bee retweeted

👏 Congratulations to the @Oracle Cloud team on being among the first to bring up NVIDIA Vera Rubin NVL72.
Together, we're delivering the infrastructure for the agentic AI era.
Jun 10

OCI continues to push the frontier of AI infrastructure. We are among the first cloud providers to bring up an @nvidia Vera Rubin NVL72 rack for validation testing, working closely with NVIDIA to deliver next-generation accelerated computing to customers at cloud scale.
Pic 1: What it takes to bring up the first rack. Pic 2: What it looks like after the models it will help train get a chance to clean up the photo.


13
42
413
27,936



bee retweeted

Jun 11
Claw Patrol handles real world SRE Agent problems.
For example, internally we have a clickhouse that's only accessible via tailscale.
The agent just uses clickhouse-client on the hostname (redacted), Claw Patrol intercepts, evals, and forwards.
screenshots are real claw patrol config


3
4
31
3,726
bee retweeted

Jun 11
Researchers found a way to make LLMs 8.5x faster!
(without compromising accuracy)
Speculative decoding is quite an effective way to address the single-token bottleneck in traditional LLM inference.
A small "draft" model first generates the next several tokens, then the large model verifies all of them at once in a single forward pass.
If a token at any position is wrong, you keep everything before it and restart from there. This never does worse than normal decoding.
But current drafters in Speculative decoding still guess one token at a time. That makes the drafting step itself a bottleneck, capping real-world speedups at 2-3x.
DFlash is a new technique that swaps the autoregressive drafter with a lightweight block diffusion model that guesses all tokens in one parallel shot.
Drafting cost stays flat no matter how many tokens you speculate.
On top of that, the drafter is conditioned on hidden features pulled from multiple layers of the target model and injected into every draft layer, so it makes significantly better guesses than a drafter working from scratch.
In the side-by-side demo below, vanilla decoding runs at 48.5 tokens/sec. DFlash hits 415 tokens/sec on the same model, with zero quality loss.
It's already integrated with vLLM, SGLang, and Transformers, with draft models on HuggingFace for several models like Qwen3, Qwen3.5, Llama 3.1, Kimi-K2.5, gpt-oss, and many more.
I have shared the GitHub repo in the replies!
KV caching is another must-know technique to boost LLM inference. I recently wrote an article about it. Read it below.
I'll soon publish another article on speculative decoding.
Stay tuned!!

21
93
529
65,858
bee retweeted

Jun 11
Undeniable that Anthropic presents the biggest known structural business risk with their arbitrary, customer-hostile, non-negotiable, non-transparent model limitations user data retention.
If you use Claude as a business you should want to have an offramp to another model.
Jun 10

Even if you dont have an ethical/moral stance on the limitations of Anthropic models, there's a practical business one:
I will avoid Anthropic models because they keep imposing more limits on the products I can build. I'm not going to build on a completely walled off ecosystem.
39
51
876
71,576

anyone running a 16gb card, stop scrolling. @pupposandro and @davideciffa got qwen 35b-a3b down to 13.3gb, measured on a 3090 gpu.
which means a model you literally could not load before now fits, running around 100 tok/s, near what you'd get with every expert resident on a 24gb card.
the clever part is the thing everyone gets wrong about moe. it only touches ~3b of its 35b params per token, routes to about 8 of 256 experts, but you still pay full vram to keep all of them around in case they're next.
luce spark learns which experts your traffic actually hits, pins those hot, and streams the rest from ram hidden under the matmuls so there's no speed cliff. one flag, and it tunes itself warmer every restart.
this is the kind of work that quietly drops the whole local inference tier down a card. don't let it scroll past.

10
37
420
81,859
bee retweeted

Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
169
810
5,025
921,918