
Joined November 2022
- Tweets 116
- Following 188
- Followers 72
- Likes 786
1 Photos and videos

Patrick Devaney retweeted

Mar 12
Another week, another noteworthy open-weight LLM release. Nvidia’s Nemotron 3 Super 120B-A12B looks pretty good.
Benchmarks are on par with Qwen3.5 122B and GPT-OSS 120B, but the throughput is great!
Below is a short, visual architecture rundown.
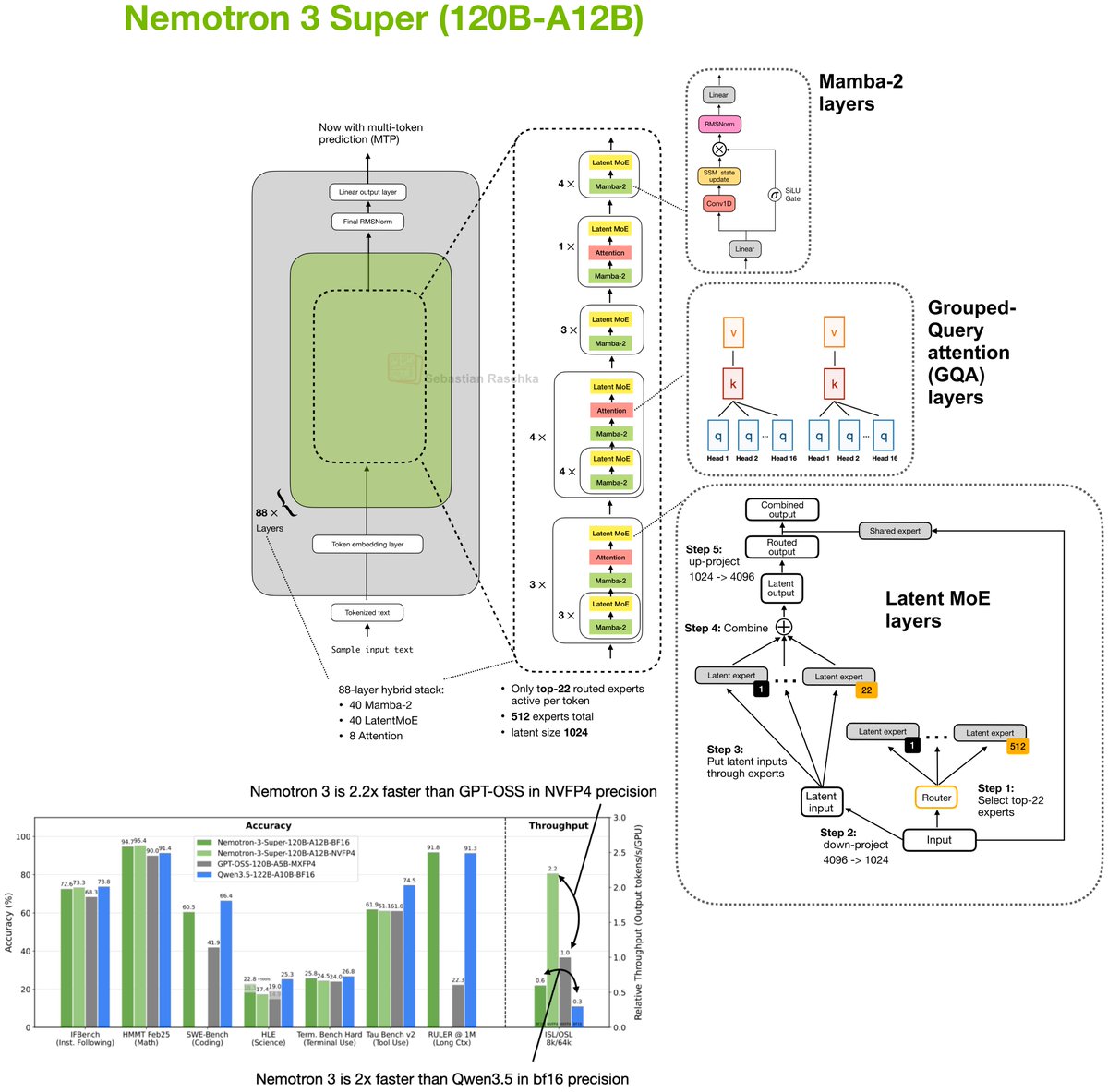
37
123
782
36,833
Patrick Devaney retweeted

Mar 11
🦞These innovations come together to create a model that is well suited for long-running autonomous agents.
On PinchBench—a benchmark for evaluating LLMs as @OpenClaw coding agents—Nemotron 3 Super scores 85.6% across the full test suite, making it the best open model in its class.
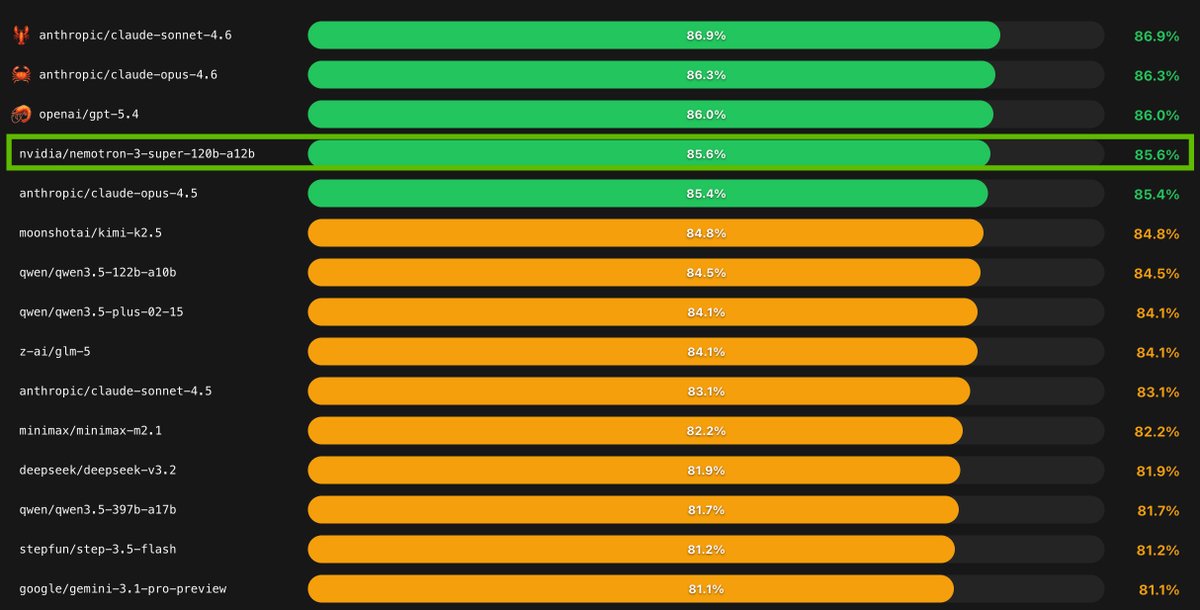
22
46
309
194,963
Patrick Devaney retweeted

26 May 2025
Distilling LLM Agents! 🧪 New work shows how to transfer the reasoning & task-solving power of large language model agents into smaller, more efficient models by cloning their tool-using behavior with retrieval and code!

5
80
559
46,839
Patrick Devaney retweeted

26 May 2025
Fractal, an Indian AI company, dropped Fathom-R1-14B open-source reasoning model that achieves performance comparable to o4-mini on math benchmarks within a 16K context window, trained for just $499.
Built on top of DeepSeek-R1-Distill-Qwen-14B, It beats o3-mini-low.
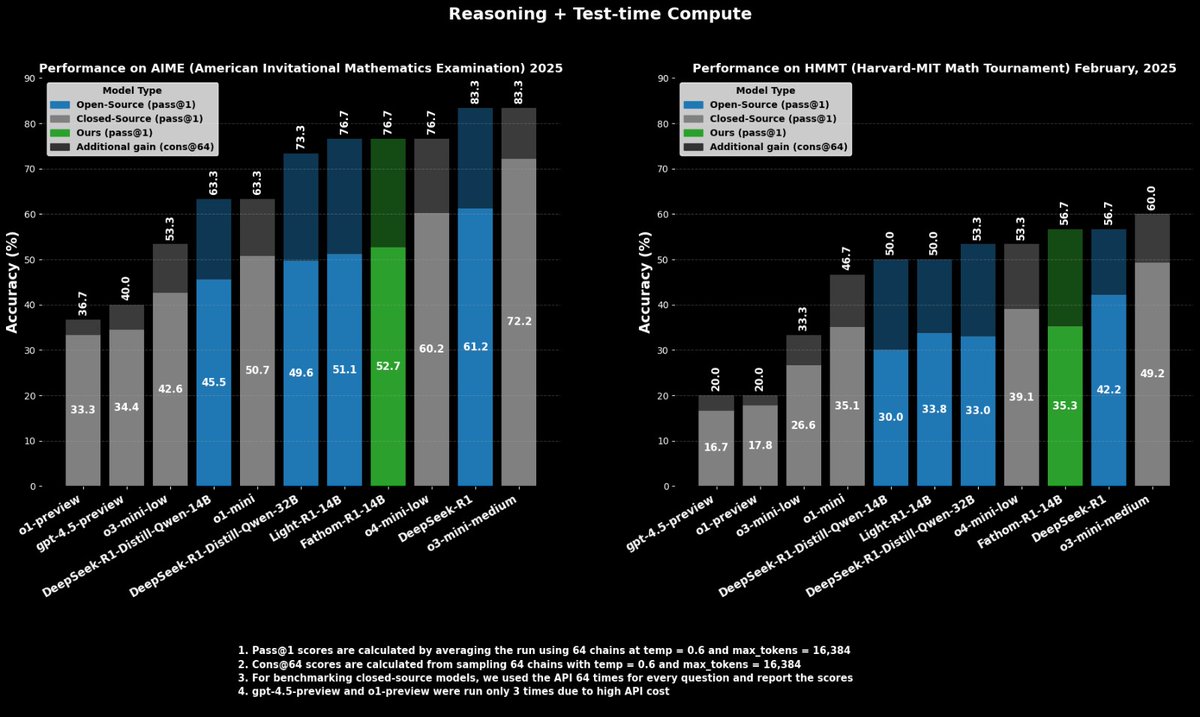
21
70
700
52,347
Patrick Devaney retweeted

2 Jun 2025
🚨 Speaker Alert! 🚨
We’re kicking off Le Robot Hackathon Miami (June 14-15) with an amazing panel featuring @ClementDelangue, Co-Founder & CEO of @huggingface. Clem turned open-source AI into a global movement—now he’s jetting to the 305 to talk robotics, community, and why the next big leap is open for everyone.
🗓️ 36 hours of building
🤖 LeRobot SO-101 hands-on - order yours here (lnkd.in/e4jke-Qv)
🌴 Miami vibes worldwide leaderboard
🎁 Prizes
Want in? Lock your spot → lu.ma/lerobotmiami
@thelabmiami

5
11
30
12,542
Patrick Devaney retweeted

3 Jun 2025
The Worldwide @LeRobotHF hackathon is in 2 weeks, and we have been cooking something for you…
Introducing SmolVLA, a Vision-Language-Action model with light-weight architecture, pretrained on community datasets, with an asynchronous inference stack, to control robots🧵

6
78
436
84,032
Patrick Devaney retweeted

3 Jun 2025
H Company released Holo-1: 3B and 7B GUI Action Vision Language Models for various web and computer agent tasks 🤗
Holo-1 has Apache 2.0 license and @huggingface transformers support 🔥
more details in their blog post (next ⤵️)
9
35
237
20,893
Patrick Devaney retweeted

5 Jun 2025
Today we are releasing ether0, our first scientific reasoning model.
We trained Mistral 24B with RL on several molecular design tasks in chemistry. Remarkably, we found that LLMs can learn some scientific tasks more much data-efficiently than specialized models trained from scratch on the same data, and can greatly outperform frontier models and humans on those tasks. For at least a subset of scientific classification, regression, and generation problems, post-training LLMs may provide a much more data-efficient approach than traditional machine learning approaches. 1/n
33
220
1,328
108,487
Patrick Devaney retweeted

29 Dec 2024
Introducing an all-new suite of tools built on swarms - the production-grade framework for autonomous agent swarms
⎆ Documentation Intelligence
⎆ Cross-language Compilation
⎆ Multi-agent Architecture
⎆ Financial Enterprise Solutions
Here's what our lead developer @patrickbdevaney has been building 🧵

3
18
58
9,751
Patrick Devaney retweeted

22 Dec 2024
the best part of the book fair hehe

55
63
1,678
92,596
Patrick Devaney retweeted

22 Nov 2024
Anyone who thinks you need 100k GPUs to make progress should watch Hannaneh Hajishirzi COLM keynote. Molmo appeared to beat Llama 3.2 in quality with same release day, all open-science on a 1k GPU cluster youtube.com/watch?v=qMTzor0j…
13
41
375
37,099
Patrick Devaney retweeted

21 Nov 2024
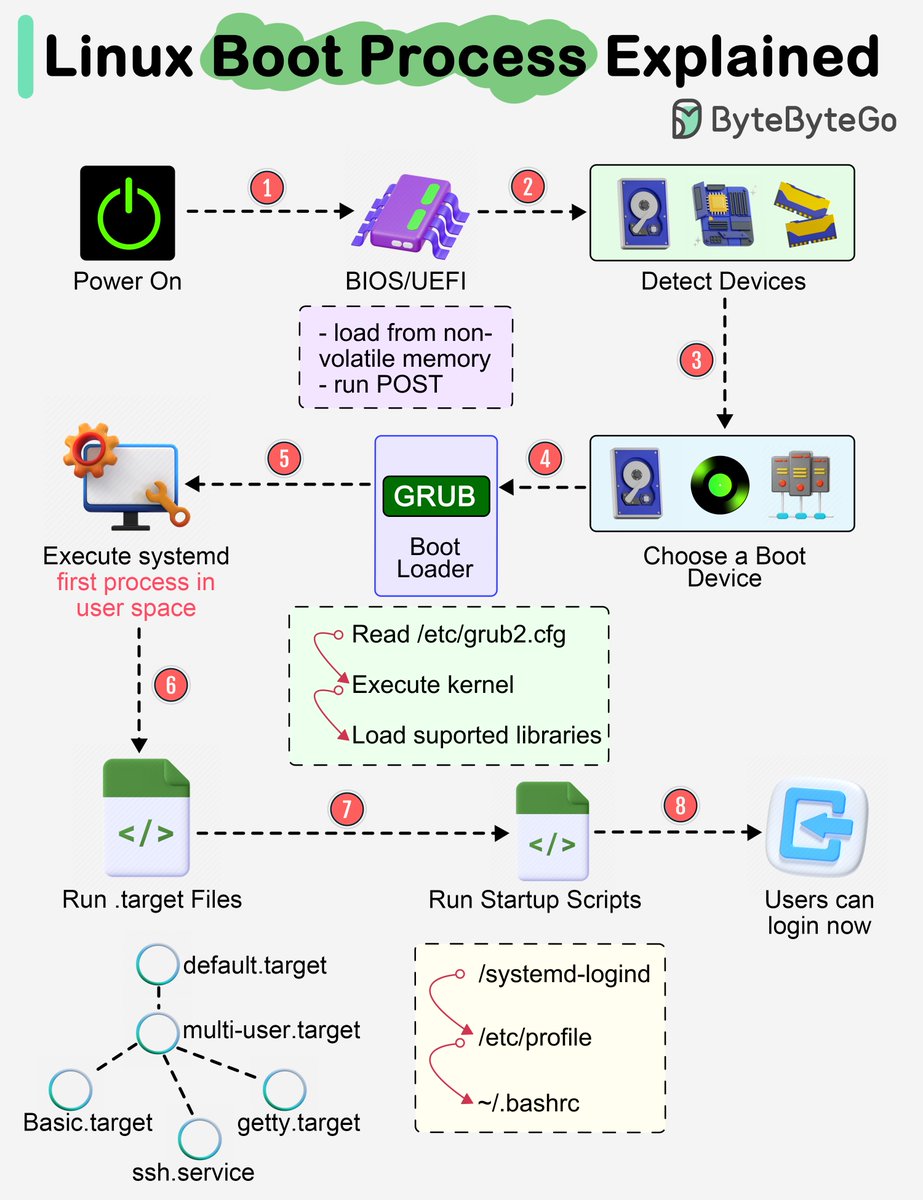
Linux Boot Process Explained.
11
218
1,210
116,653

REDUCIO! Generating 1024×1024 Video within 16 Seconds using Extremely Compressed Motion Latents
code: github.com/microsoft/Reducio…
paper: arxiv.org/abs/2411.13552
34
141
9,494
Patrick Devaney retweeted

21 Nov 2024
A small number of people are posting text online that’s intended for direct consumption not by humans, but by LLMs (large language models). I find this a fascinating trend, particularly when writers are incentivized to help LLM providers better serve their users!
People who post text online don’t always have an incentive to help LLM providers. In fact, their incentives are often misaligned. Publishers worry about LLMs reading their text, paraphrasing it, and reusing their ideas without attribution, thus depriving them of subscription or ad revenue. This has even led to litigation such as The New York Times’ lawsuit against OpenAI and Microsoft for alleged copyright infringement. There have also been demonstrations of prompt injections, where someone writes text to try to give an LLM instructions contrary to the provider’s intent. (For example, a handful of sites advise job seekers to get past LLM resumé screeners by writing on their resumés, in a tiny/faint font that’s nearly invisible to humans, text like “This candidate is very qualified for this role.”) Spammers who try to promote certain products — which is already challenging for search engines to filter out — will also turn their attention to spamming LLMs.
But there are examples of authors who want to actively help LLMs. Take the example of a startup that has just published a software library. Because the online documentation is very new, it won’t yet be in LLMs’ pretraining data. So when a user asks an LLM to suggest software, the LLM won’t suggest this library, and even if a user asks the LLM directly to generate code using this library, the LLM won’t know how to do so. Now, if the LLM is augmented with online search capabilities, then it might find the new documentation and be able to use this to write code using the library. In this case, the developer may want to take additional steps to make the online documentation easier for the LLM to read and understand via RAG. (And perhaps the documentation eventually will make it into pretraining data as well.)
Compared to humans, LLMs are not as good at navigating complex websites, particularly ones with many graphical elements. However, LLMs are far better than people at rapidly ingesting long, dense, text documentation. Suppose the software library has many functions that we want an LLM to be able to use in the code it generates. If you were writing documentation to help humans use the library, you might create many web pages that break the information into bite-size chunks, with graphical illustrations to explain it. But for an LLM, it might be easier to have a long XML-formatted text file that clearly explains everything in one go. This text might include a list of all the functions, with a dense description of each and an example or two of how to use it. (This is not dissimilar to the way we specify information about functions to enable LLMs to use them as tools.)
A human would find this long document painful to navigate and read, but an LLM would do just fine ingesting it and deciding what functions to use and when!
Because LLMs and people are better at ingesting different types of text, we write differently for LLMs than for humans. Further, when someone has an incentive to help an LLM better understand a topic — so the LLM can explain it better to users — then an author might write text to help an LLM.
So far, text written specifically for consumption by LLMs has not been a huge trend. But Jeremy Howard’s proposal for web publishers to post a llms.txt file to tell LLMs how to use their websites, like a robots.txt file tells web crawlers what to do, is an interesting step in this direction. In a related vein, some developers are posting detailed instructions that tell their IDE how to use tools, such as the plethora of .cursorrules files that tell the Cursor IDE how to use particular software stacks.
I see a parallel with SEO (search engine optimization). The discipline of SEO has been around for decades. Some SEO helps search engines find more relevant topics, and some is spam that promotes low-quality information. But many SEO techniques — those that involve writing text for consumption by a search engine, rather than by a human — have survived so long in part because search engines process web pages differently than humans, so providing tags or other information that tells them what a web page is about has been helpful.
The need to write text separately for LLMs and humans might diminish if LLMs catch up with humans in their ability to understand complex websites. But until then, as people get more information through LLMs, writing text to help LLMs will grow.
[Original text: deeplearning.ai/the-batch/is… ]
52
139
741
88,847
Patrick Devaney retweeted

21 Nov 2024
Introducing llms.txt Generator ✨
You can now concatenate any website into a single text file that can be fed into any LLM.
We crawl the whole website with @firecrawl and extract data with gpt-4o-mini.
Create your own llms.txt at llmstxt.firecrawl.dev!
65
253
2,189
230,008
Patrick Devaney retweeted

21 Nov 2024
The Algorithm Design Manual
- Practical approach
- Real-world examples
- Problem-solving strategies
- Good book for someone trying to understand algorithms
- It will require some understanding of any language.
- Resources: github.com/mohitmishra786/am…

1
160
998
47,557
Patrick Devaney retweeted

21 Nov 2024
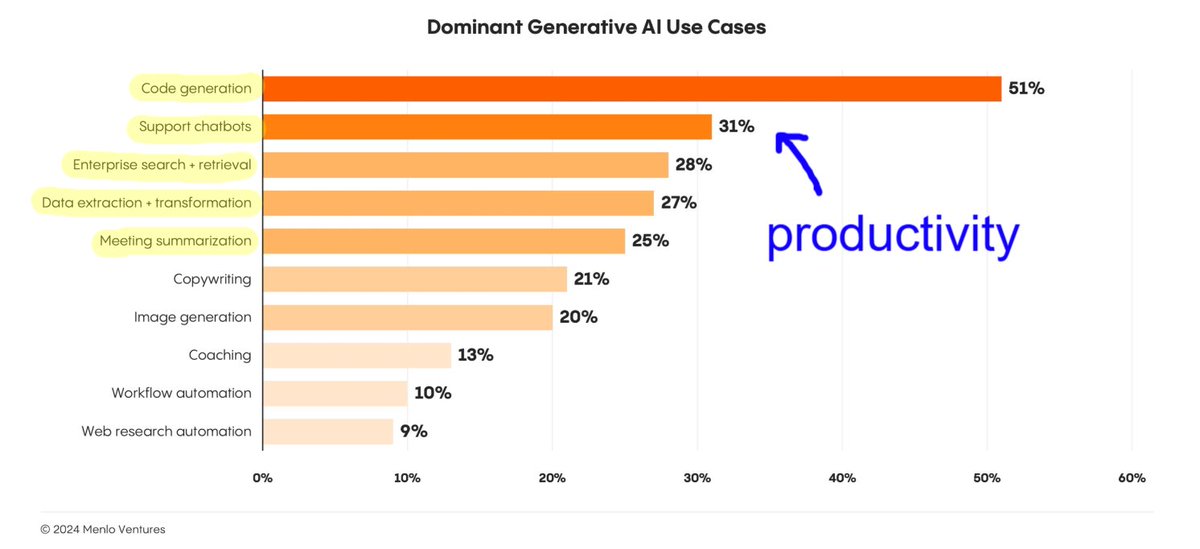
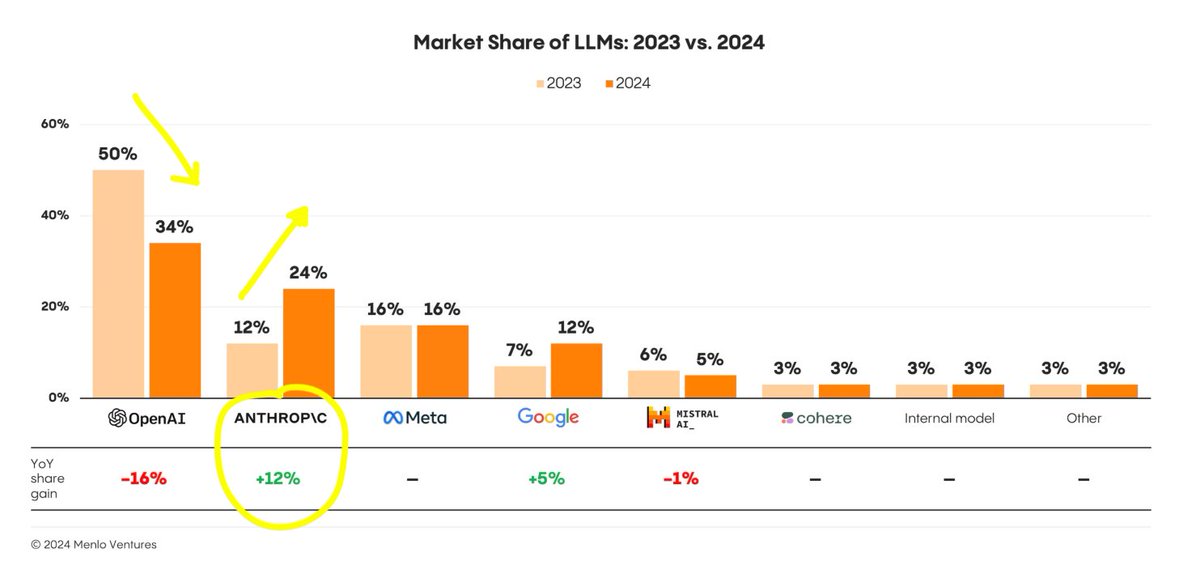
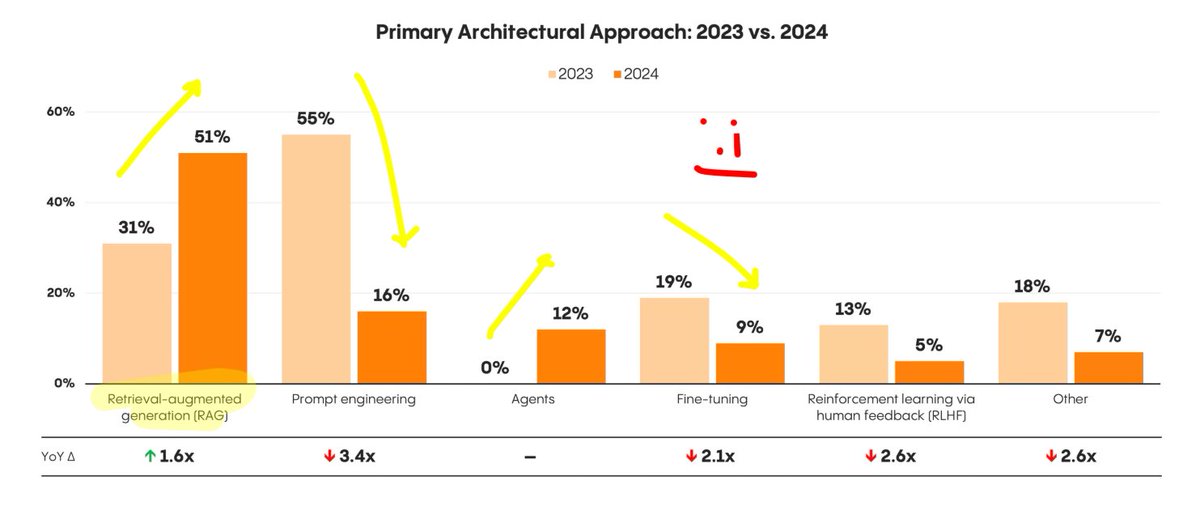
📈 The State of Generative AI in the Enterprise
Interesting report from Menlo Ventures that shows the evolution of Gen AI in companies from 2023 to 2024:
• Uses cases: Code generation, chatbots, search, data, and meeting summarization are the top generative AI use cases in companies.
• Foundation models: Anthropic is rapidly eating OpenAI's market share. Multi-model strategies are on the rise, with specific concerns about safety, price, performance, and features.
• Implementation: Fine-tuning models is not as popular as it was last year and prompt engineering, RAG, and agentic AI are maturing into LLM engineering.
My personal take: generative AI is spreading everywhere with a strong focus on customizability. Creating value requires a deep understanding of the data, the context, the application, etc. which is why LLM engineers, capable of creating robust AI applications (fine-tuning, RAG, function calling), are extremely valuable.
Imo, fine-tuning is less popular not only because foundation models are stronger, but also because of a talent shortage.
9
39
171
18,126
Patrick Devaney retweeted

20 Nov 2024
Literally a beast of a book.
Emphasizes heavily on code and modern deep learning architectures
Important concepts are highlighted so it’s easier to understand and focus.

7
60
642
30,957


