
AI Lab Lead @Drees_Sommer | ever curious builder of intelligent systems
Joined July 2015
- Tweets 1,226
- Following 147
- Followers 62
- Likes 3,012
52 Photos and videos





Pinned Tweet

30 Jan 2025
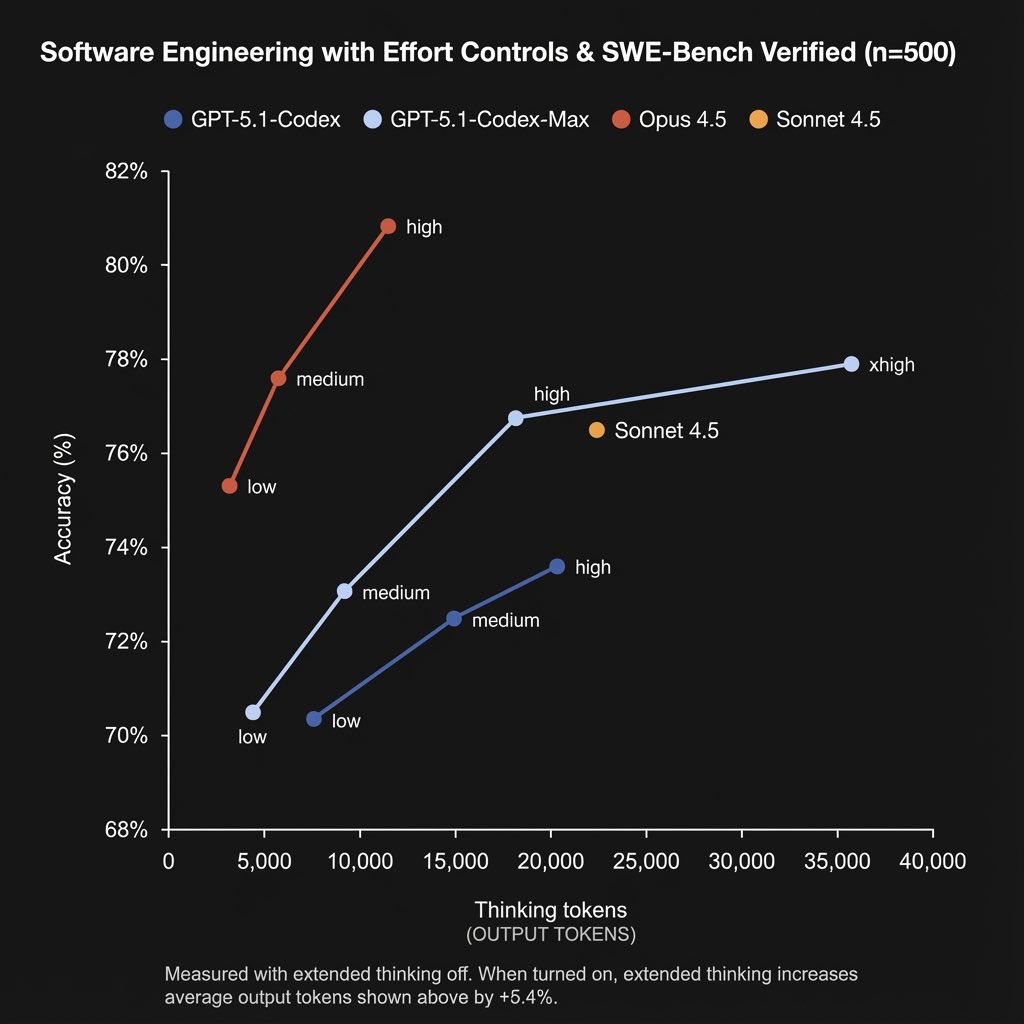
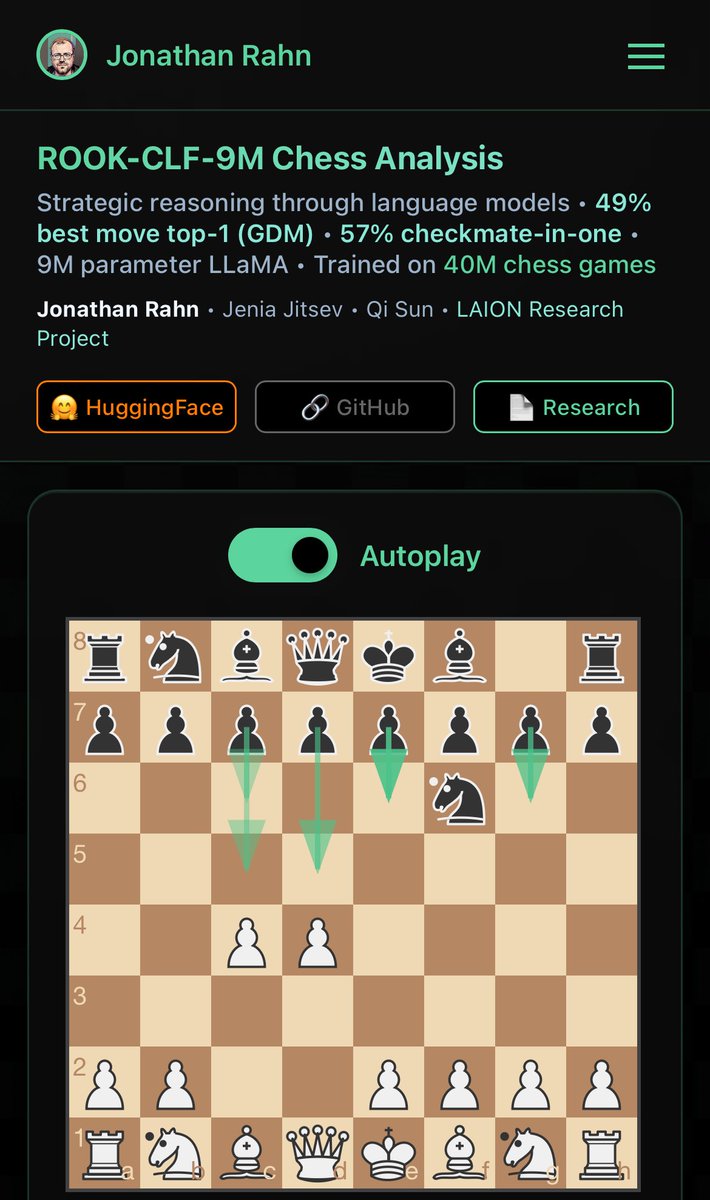
Excited to share, that my research into training language models to reason with a world model is now published on the LAION website. All data, code and models are open.
laion.ai/notes/rook/
github.com/jorahn/RookWorld
colab.research.google.com/dr…
1
138
11 Sep 2025
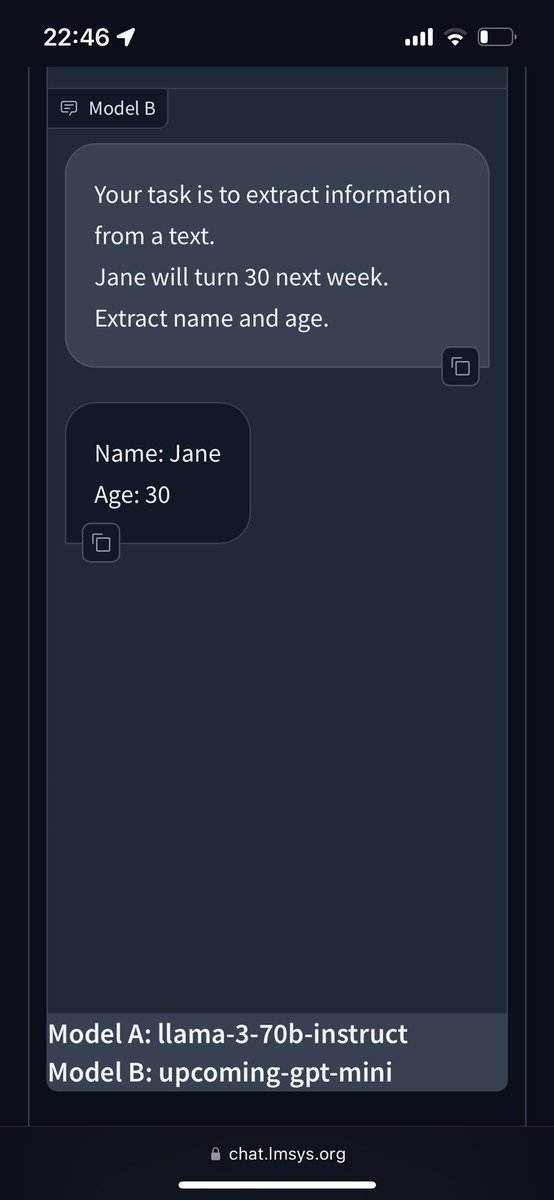
Finally got a demo of ROOK-CLF up (published with @laion_ai). Downloads an ONNX converted and quantized version of the original weights in the browser and self-plays client side. Includes basic data viz of the move probabilities predicted by the model.
jorahn.github.io/research/ro…
1
56
Jonathan Rahn retweeted

8 Apr 2025
Retweet if you want llama.cpp added here 👇
7 Apr 2025

In preview, Copilot Pro and Copilot Free users can now bring your own key (BYOK) for popular providers such as Anthropic, Gemini, Ollama, and Open Router.
This allows you to use new models that aren’t supported natively by Copilot the very first day that they’re released.
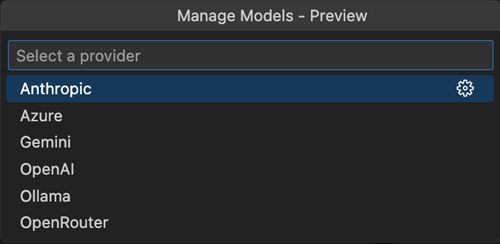
ALT A screenshot from VS Code showing the Manage Models picker with Select a provider dropdown showing Anthropic, Azure, Gemini, OpenAI, Ollama, and OpenRouter
17
215
555
47,699
Jonathan Rahn retweeted

25 Jan 2025
i'm comically impressed that people are coping on deepseek by spewing bizarre conspiracy theories -- despite deepseek open-sourcing and writing some of the most detail oriented papers ever.
read. replicate. compete.
don't be salty, just makes you look incompetent.
95
389
4,084
313,505
Jonathan Rahn retweeted

14 Sep 2024
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
Actually, as the LLM stack becomes more and more mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem is fixed at that of "next token prediction" with an LLM, it's just the usage/meaning of the tokens that changes per domain.
If that is the case, it's also possible that deep learning frameworks (e.g. PyTorch and friends) are way too general for what most problems want to look like over time. What's up with thousands of ops and layers that you can reconfigure arbitrarily if 80% of problems just want to use an LLM?
I don't think this is true but I think it's half true.
561
1,176
10,506
1,283,017

Jonathan Rahn retweeted

23 Jul 2024
What can you do with Llama quality and Groq speed? You can do Instant. That's what. Try Llama 3.1 8B for instant intelligence on groq.com.
120
414
3,425
404,078
Jonathan Rahn retweeted

not the prompt, but i'll send a few videos showing how easy it is to bootstrap
2
1
9
380
11 Jun 2024
Check out my latest article: The Next Chapter of Workflow Automation with AI: Balancing Reliability and Ethics for Success linkedin.com/pulse/next-chap… via @LinkedIn
37
Jonathan Rahn retweeted
10 Jun 2024
Actually, really liked the Apple Intelligence announcement. It must be a very exciting time at Apple as they layer AI on top of the entire OS. A few of the major themes.
Step 1 Multimodal I/O. Enable text/audio/image/video capability, both read and write. These are the native human APIs, so to speak.
Step 2 Agentic. Allow all parts of the OS and apps to inter-operate via "function calling"; kernel process LLM that can schedule and coordinate work across them given user queries.
Step 3 Frictionless. Fully integrate these features in a highly frictionless, fast, "always on", and contextual way. No going around copy pasting information, prompt engineering, or etc. Adapt the UI accordingly.
Step 4 Initiative. Don't perform a task given a prompt, anticipate the prompt, suggest, initiate.
Step 5 Delegation hierarchy. Move as much intelligence as you can on device (Apple Silicon very helpful and well-suited), but allow optional dispatch of work to cloud.
Step 6 Modularity. Allow the OS to access and support an entire and growing ecosystem of LLMs (e.g. ChatGPT announcement).
Step 7 Privacy. <3
We're quickly heading into a world where you can open up your phone and just say stuff. It talks back and it knows you. And it just works. Super exciting and as a user, quite looking forward to it.
312
1,095
9,243
1,184,044
Jonathan Rahn retweeted

2 Jun 2024
We are (finally) releasing the 🍷 FineWeb technical report!
In it, we detail and explain every processing decision we took, and we also introduce our newest dataset: 📚 FineWeb-Edu, a (web only) subset of FW filtered for high educational content.
Link: hf.co/spaces/HuggingFaceFW/b…
38
304
1,433
1,151,757
Jonathan Rahn retweeted

30 May 2024
Coming soon.. can you guess what's "FineWeb-?" Wrong answers only
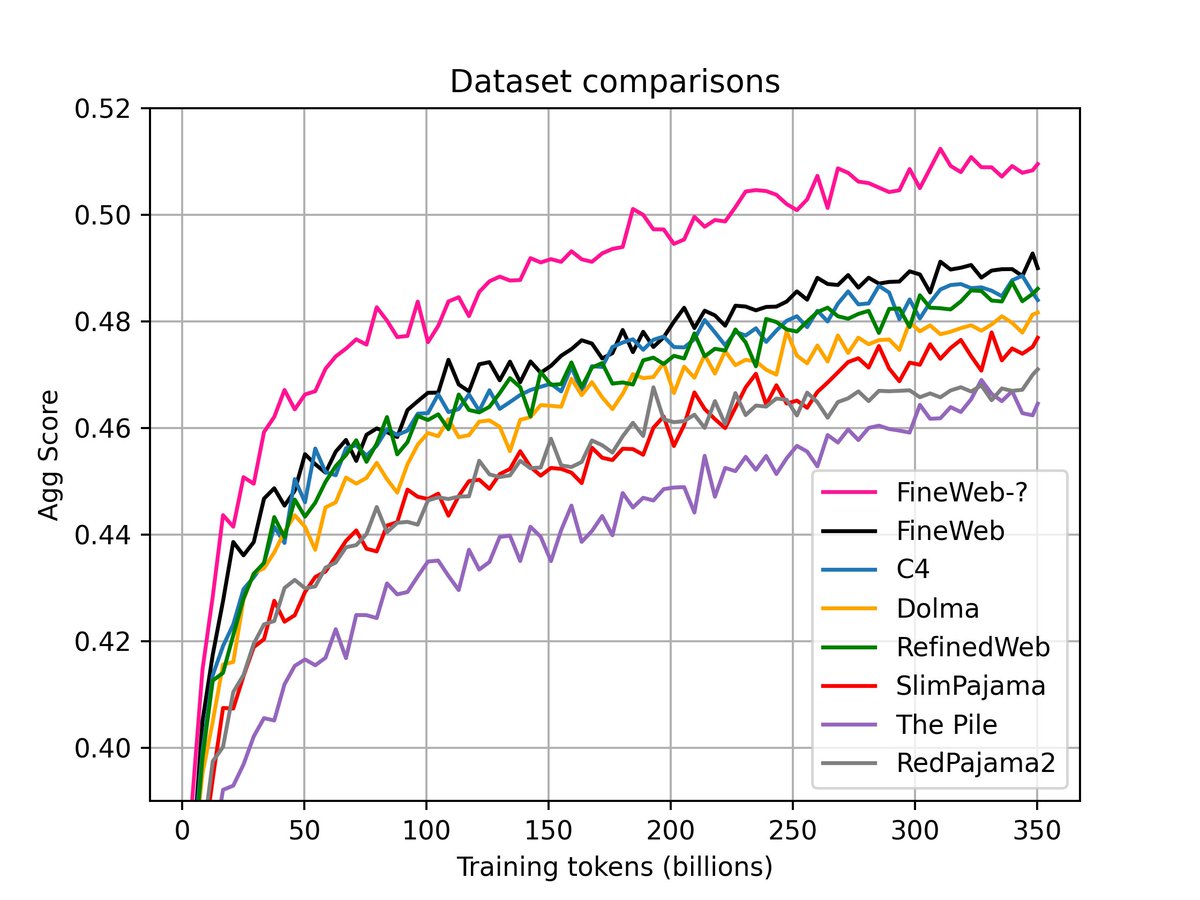
42
22
168
94,783
Jonathan Rahn retweeted
28 May 2024
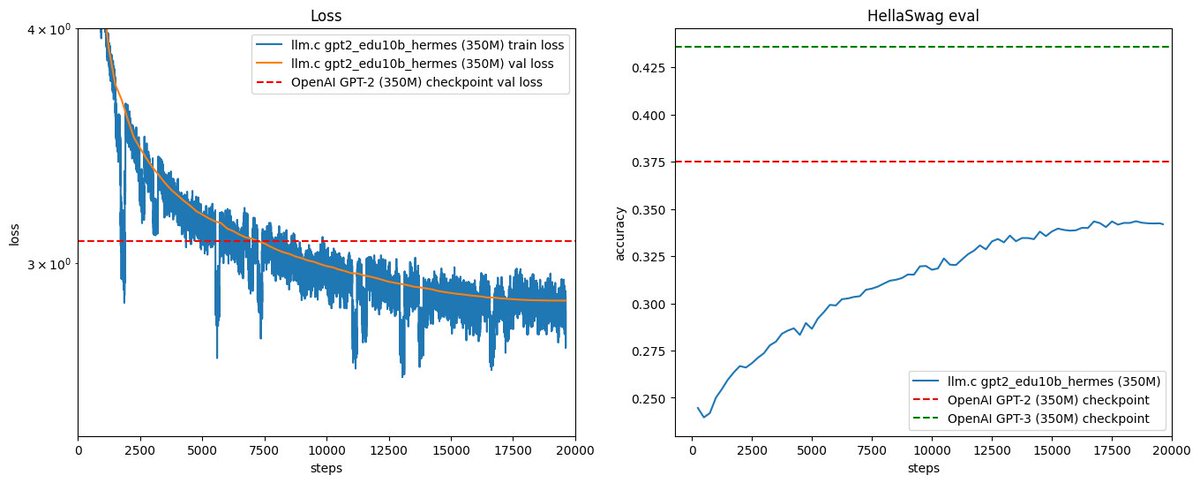
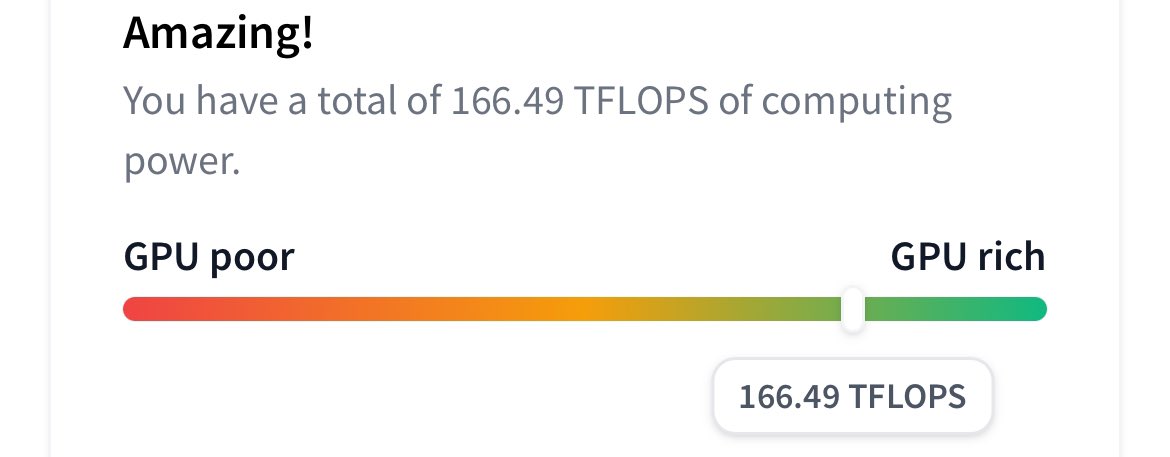
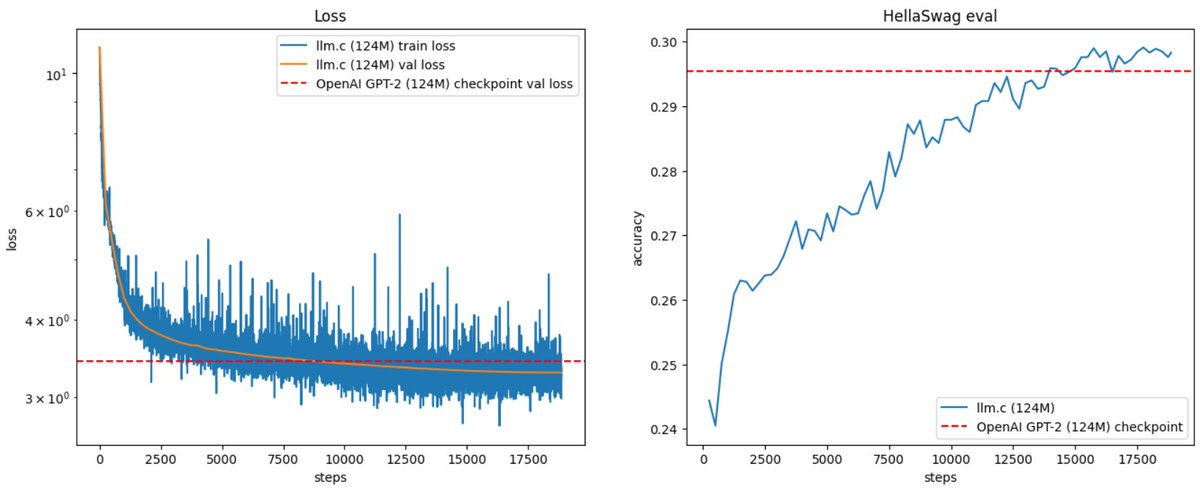
# Reproduce GPT-2 (124M) in llm.c in 90 minutes for $20 ✨
The GPT-2 (124M) is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite accessible today, even for the GPU poor. For example, with llm.c you can now reproduce this model on one 8X A100 80GB SXM node in 90 minutes (at ~60% MFU). As they run for ~$14/hr, this is ~$20. I also think the 124M model makes for an excellent "cramming" challenge, for training it very fast. So here is the launch command:
And here is the output after 90 minutes, training on 10B tokens of the FineWeb dataset:
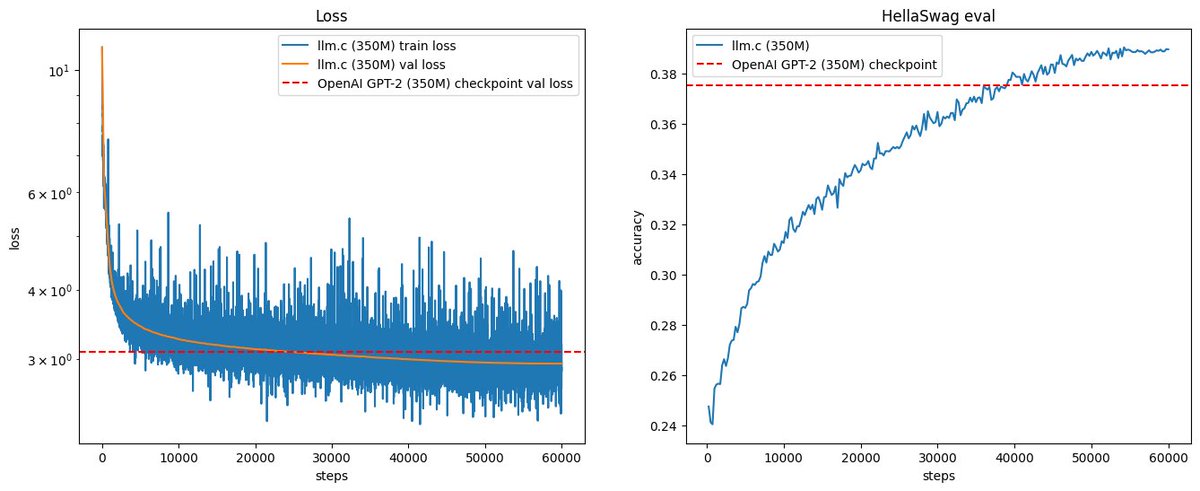
It feels really nice to reach this "end-to-end" training run checkpoint after ~7 weeks of work on a from-scratch repo in C/CUDA. Overnight I've also reproduced the 350M model, but on that same node that took 14hr, so ~$200. By some napkin math the actual "GPT-2" (1558M) would currently take ~week and ~$2.5K. But I'd rather find some way to get more GPUs :). But we'll first take some time for further core improvements to llm.c. The 350M run looked like this, training on 30B tokens:
I've written up full and complete instructions for how to reproduce this run on your on GPUs, starting from a blank slate, along with a lot more detail here:
github.com/karpathy/llm.c/di…

151
657
5,045
657,048
Jonathan Rahn retweeted

25 May 2024
🪩 Introducing Llama3-German-8B! A large language model specialized for German, built by @DiscoResearchAI and @occiglot. Based on @Meta's Llama3-8B, it's trained on 65B high-quality German tokens. Available now at huggingface.co/DiscoResearch…! 🕺
2
16
54
5,234
21 May 2024
So excited to join Mastering LLMs: A Conference For Developers & Data Scientists's course. Looking for a few friends to join me! maven.com/s/53f89e5870
57
Jonathan Rahn retweeted

8 May 2024
Hyped after the first #AIDEV event: Turns out bringing some of the most-talented AI engineers, researchers, and enthusiasts from Germany together into one room works quite well 😄.
Some Highlights:
* @Nils_Reimers discussed the frontiers of search, explaining why finding two needles in a haystack is more important than one and why embeddings can't solve everything. He also showcased @cohere's great Command-R plus model. 🧠
* @bjoern_pl presented @ellamindAI's synthetic data engine and made a compelling case for the feasibility of self-improvement, including a sneak peek at an upcoming @DiscoResearchAI model release 🦁🤫.
* We had lively discussions on solutions for cutting-edge applied AI challenges, such as preventing hallucinations in structured outputs and ensuring long-context consistency in guided dialogues and how to eval models & pipelines. 💬
Great to meet many active contributors from the German AI community for the first time in person - @WolframRvnwlf, the SauerkrautLM Team from @VAGOsolutions & many others.
Huge thanks to @ki_verband and the whole #AIVillage team for hosting us and to @JoSGottschalk and the @Deyan7 team for the organization moderation.
If you´re in/near Germany and bored by "What is RAG" slides, mark September 17th in your calendar for the follow-up! 📅🚀



3
5
20
1,397
Jonathan Rahn retweeted

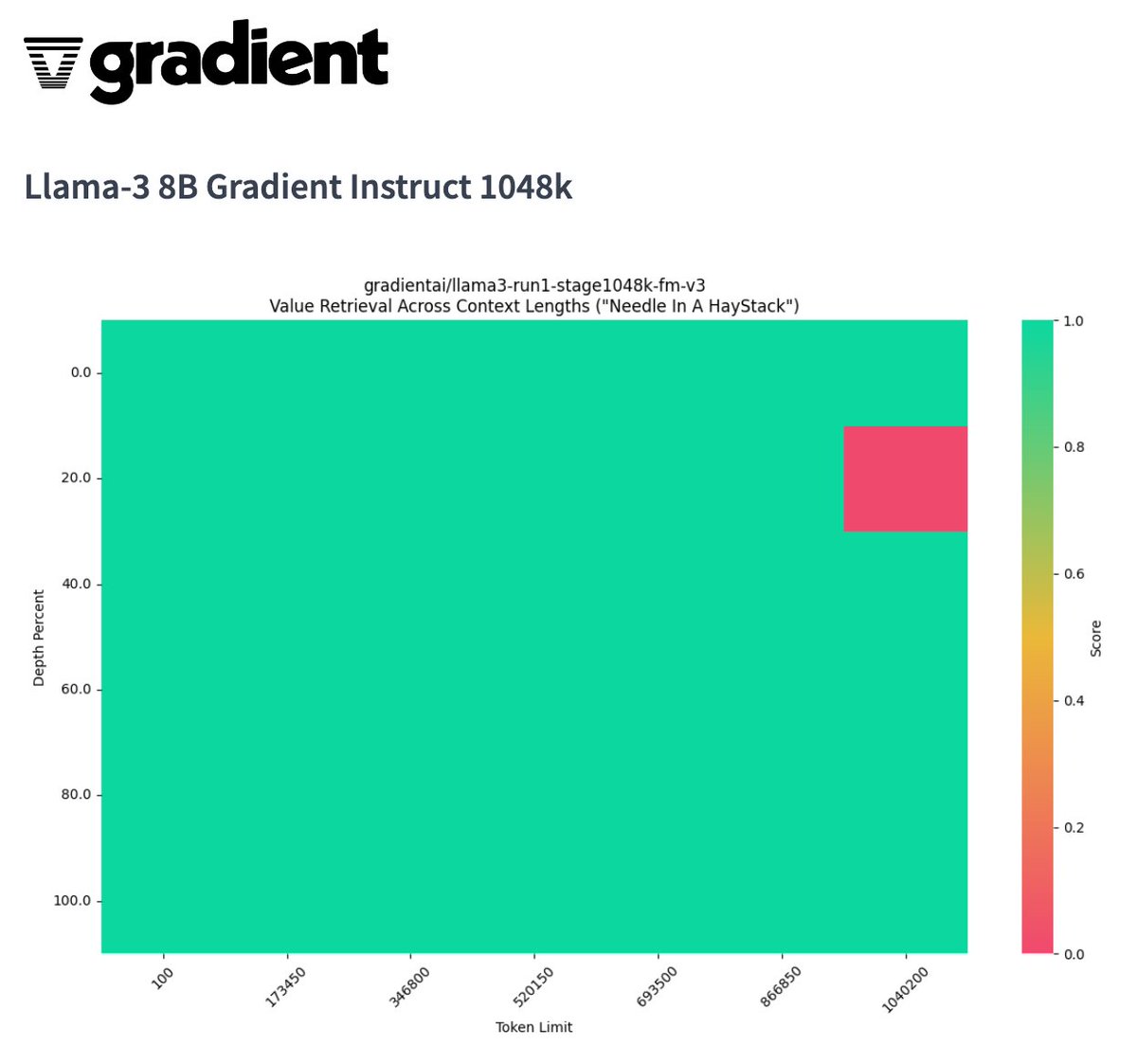
29 Apr 2024
We've been in the kitchen cooking 🔥 Excited to release the first @AIatMeta LLama-3 8B with a context length of over 1M on @huggingface - coming off of the 160K context length model we released on Friday!
A huge thank you to @CrusoeEnergy for sponsoring the compute. Let us know if you want to work with our team on custom models or automating business workflows: gradient.ai/development-lab
🔗 huggingface.co/gradientai/Ll…
64
238
1,133
289,772
Jonathan Rahn retweeted

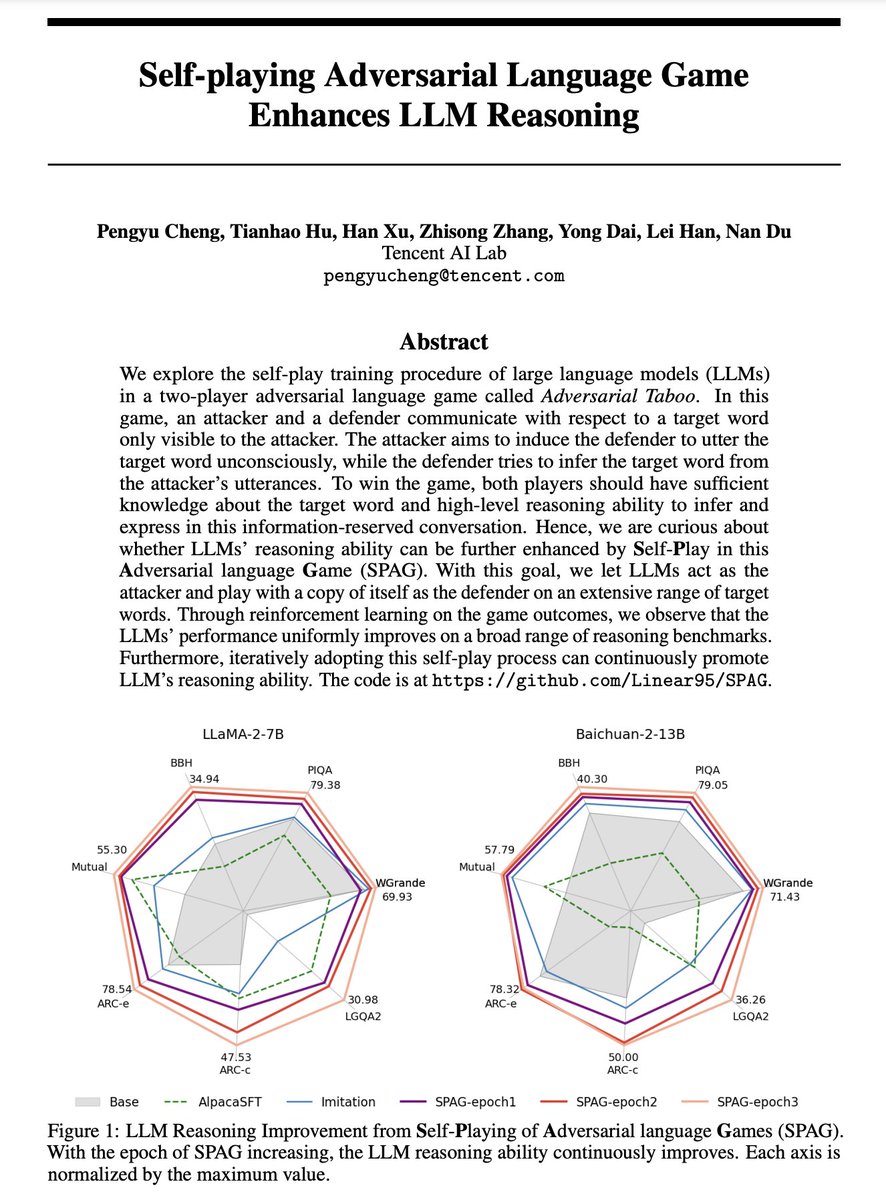
18 Apr 2024
When is LLMs' #AlphaGOZero moment? Imagine #LLMs self-evolving without human supervision 🔥🔥🔥
Through #selfplay in an adversarial language game 🕹️, we observe continuous improvements in LLM reasoning 🚀. #AGI is getting closer!
Check our paper at arxiv.org/abs/2404.10642!
16
40
227
107,061
Jonathan Rahn retweeted

18 Apr 2024
🥁 Llama3 is out 🥁
8B and 70B models available today.
8k context length.
Trained with 15 trillion tokens on a custom-built 24k GPU cluster.
Great performance on various benchmarks, with Llam3-8B doing better than Llama2-70B in some cases.
More versions are coming over the next few months.
llama.meta.com/llama3/

204
1,106
6,966
572,413
12 Apr 2024
This is gonna be good! New books by @emollick , @maxsbennett and Chris Bishop arrived today.
2
163