
Product mindset | Networking focus. Not financial advice. Views are my own.
Joined November 2024
- Tweets 259
- Following 245
- Followers 63
- Likes 2,729
24 Photos and videos







Ramon Sanders retweeted

Jun 15
What happens to #memory demand when AI shifts from training to #inference? KV cache offloading and agentic AI are two drivers worth watching. More: pse.is/97cx86 🔗
#KVcache #AgenticAI

13
58
5,516

Jun 10
The $ALAB debate gets stuck in “copper vs optics.”
I think that framing is too simplistic.
Astera is not just a copper retimer story. It is a connectivity-content story as AI racks scale.
Management laid out the key point:
“When you go to optical, you have to have a minimum of two, because one converts electrical to optical near the switch, and another converts optical back to electrical near the XPU. So already you have double the attach. And the ASP of each one of these is an order of magnitude higher than what you would get for a retimer-class device.”
The product implication is optical engines / optical endpoints at both sides of the switch-to-XPU link.
Optics may not reduce Astera’s opportunity.
Optics may expand it.
$ALAB looks positioned well for the transition from copper → NPO → CPO.
1
198
Ramon Sanders retweeted

Jun 3
Had a great chat at @AsteraLabs booth today! Jignesh explained so much to us. These other co-conspirators were great to hang with!
@iamfabian @jaygoldberg @bookwormengr
Cameraman is he who shall not be named. If you’re on X you know him.

4
3
48
29,215
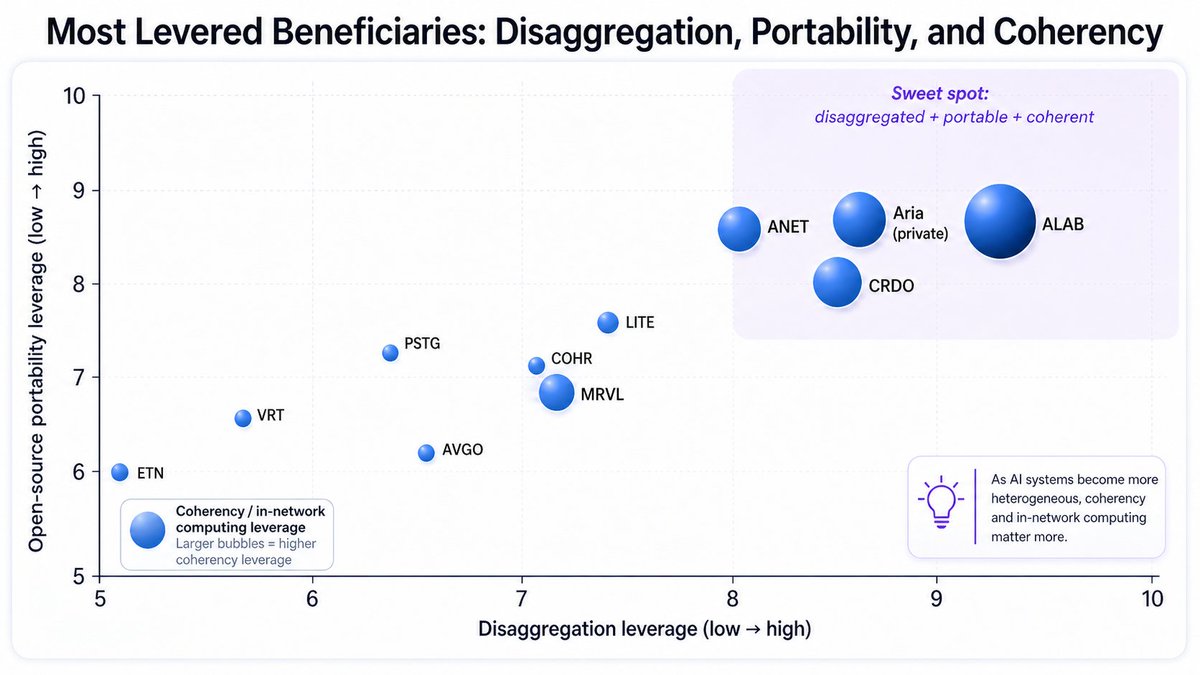
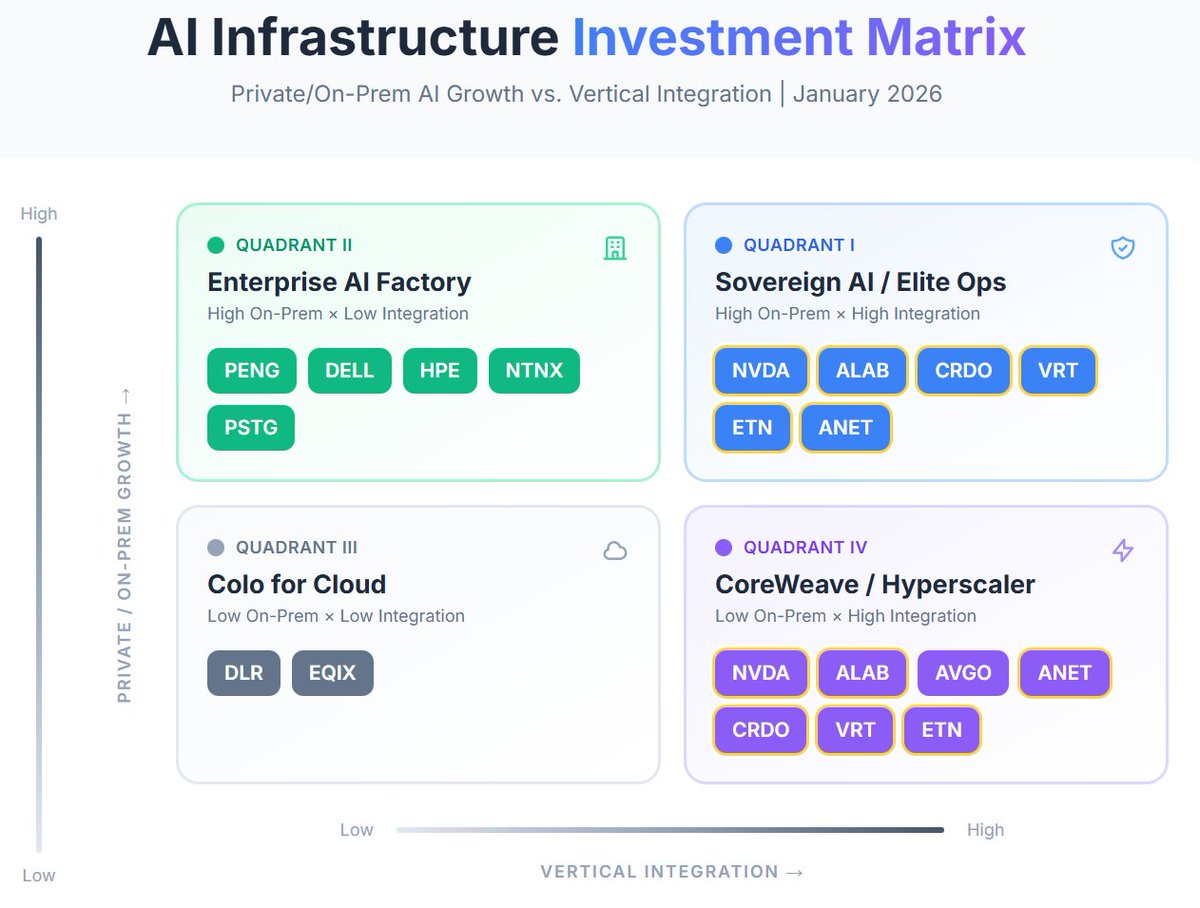
I don’t think $ALAB and $CRDO remain tightly correlated much longer.
The short-term AI infra narrative looks like large scale-up domains first.
That is what NVIDIA seems to be pushing with NVLink Fusion: rack-scale systems, custom XPUs, memory-semantic interconnect, and bigger accelerator domains.
Both can win, and I really like both companies.
But if the market is about to price “larger scale-up domains” before it prices generic optical bandwidth, $ALAB and $CRDO should not keep trading like the same basket.
302
May 26
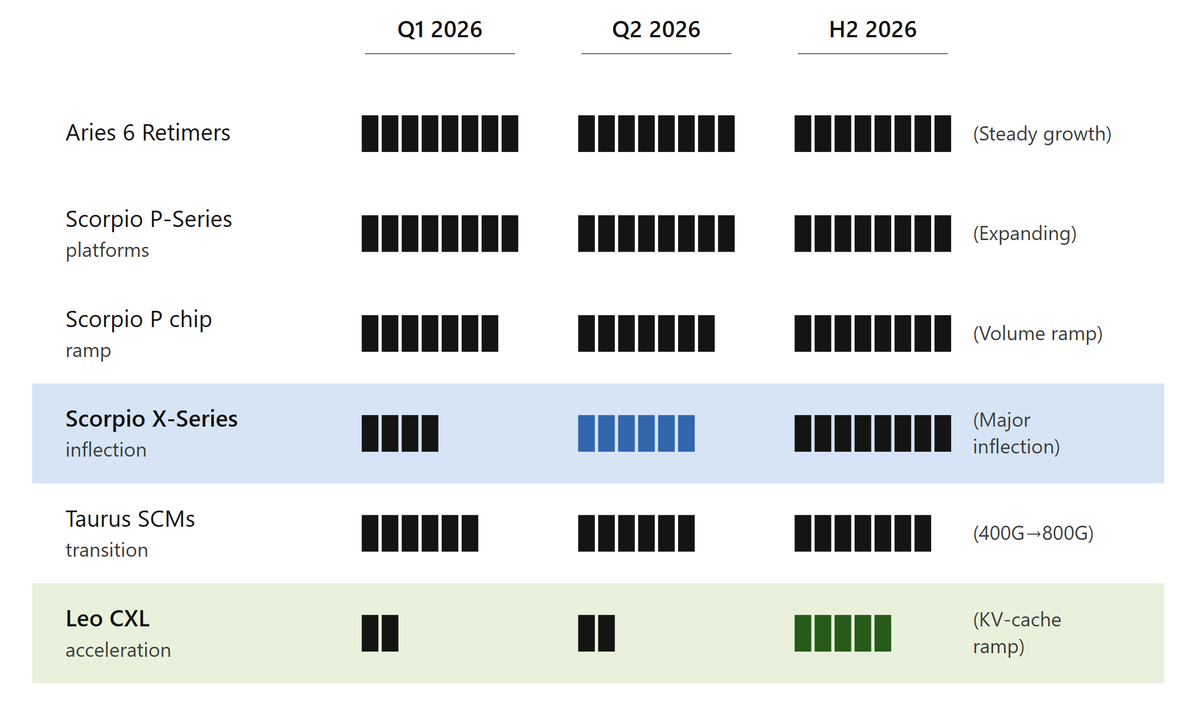
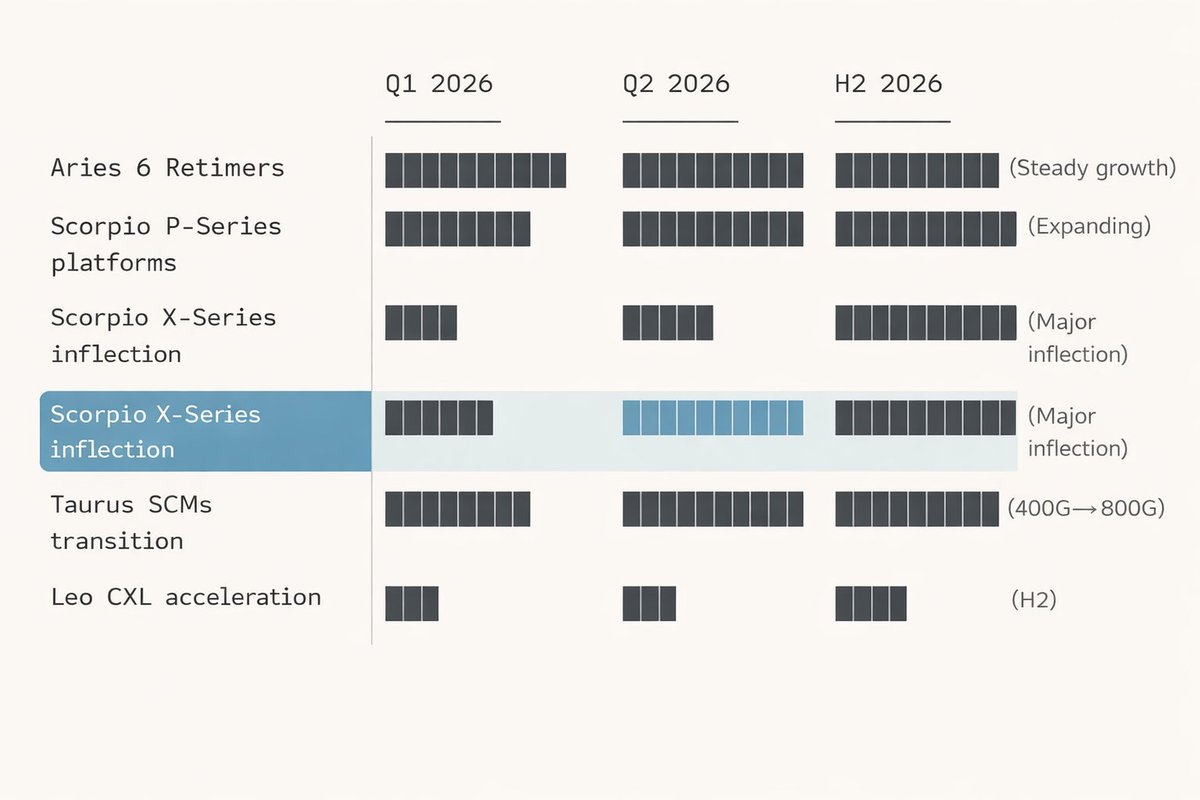
Scorpio X is the most important part of the $ALAB story this year. So far, the ramp appears to be tracking well.
My view: Scorpio X is not just another switch. It is Astera’s bet that frontier inference moves into larger scale-up domains where compute, memory, and state need to behave like one coordinated system.
Here’s my video overview of the Scorpio X product. The audio kind of sucks, but this is just my first video 😅.

1
255
Ramon Sanders retweeted

May 24
“CXL is the biggest change in AI serving since NVLink””
Maybe. But that is not why $ALAB crossed $300
I called CXL in January: helps at the margins
The re-rate is Scorpio
One part per accelerator became one fabric per pod
CXL is the headline
The fabric switch is the money

6
8
74
11,751
Ramon Sanders retweeted

May 24
astera is actually getting more into the fabric switching market. latency really starts to kill you for every hop thats added, so you want the most lanes possible in a single pcie switch.
every retimer adds like ~10ns, every switch adds 100-200ns. not super bad for gpus, but really bad for memory
2
2
56
5,757
Ramon Sanders retweeted

May 22
Masterclass on IC Lithography
You can spend one hour and catch up on the entire arc of semi lithography.
We cover:
- Economics of modern lithography
- what is takes to build a leading-edge fab
- how we evolved from DUV to EUV
- fun stories from history along the way
- where we are going with xLight and Substrate
Check it out!
Chapters:
(00:00) The 13F panic, and today's topic
(02:23) Why the real story is economics, not physics
(06:18) Austin in the clean room: graphene and bunny suits
(10:06) Rock's Law and the $20 billion fab
(18:08) DUV, the Sharpie, and a history of light
(24:58) Multi-patterning, explained with a football field
(34:45) How EUV makes 13.5nm light from tin droplets
(41:14) High NA, anamorphic optics, and the half-field tax
(46:45) The startups rethinking lithography: xLight and Substrate
@austinsemis @vikramskr
youtube.com/watch?v=WWbEfDil…
13
65
8,149
May 21
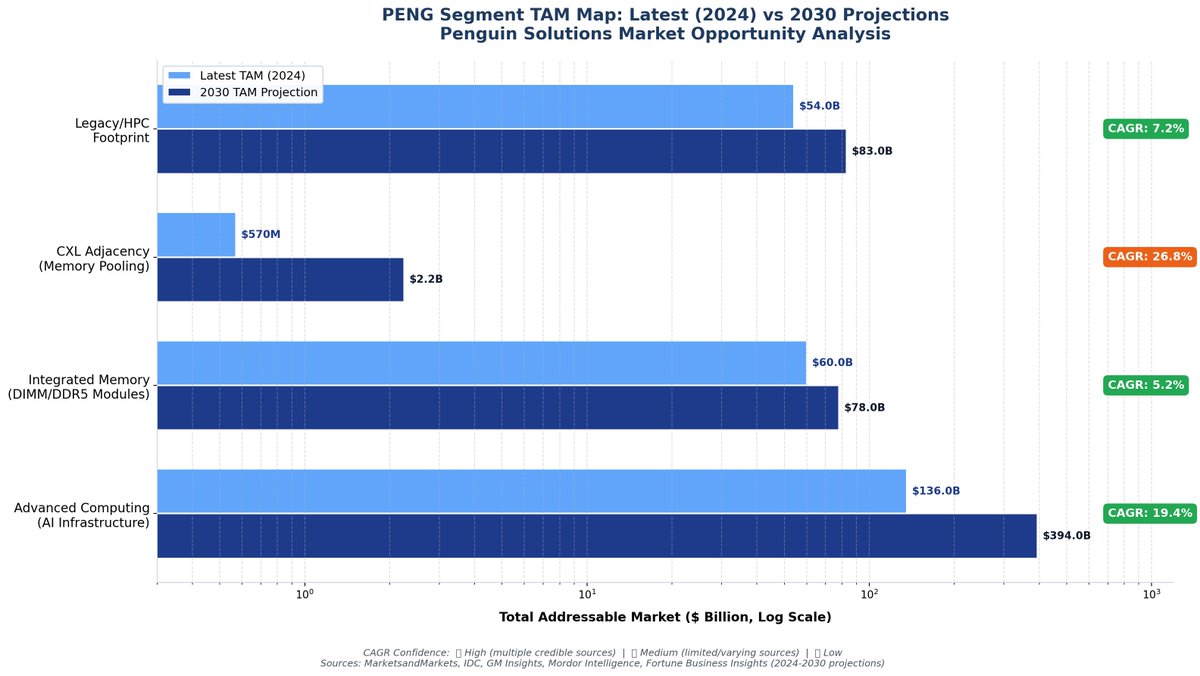
I’ve been watching the G2 layer and custom solutions a bit.
$PENG MemoryAI is one of the first clean product expressions here: a CXL-based KV Cache Server for agentic inference, long context, and memory-bound decode.
$ALAB says Leo is deployed in Penguin’s KV Cache Server with SMART Modular memory, showing 3.6x memory expansion, 75% higher GPU utilization, and 2x inference throughput.
Let's see how Penguin Solutions and Astera Labs execute here👀
May 21

With modern agentic workloads and long context windows, a common bottleneck in serving LLMs at scale is where to store all the KV cache. Luckily, KV cache can be extended beyond HBM into other tiers of memory.
Nvidia uses the following naming convention to describe the tiers:
🟠 G1 (HBM): fastest bandwidth but (relatively) small
🟠 G2 (host DRAM): still quite fast (traverses PCIe) and an order of magnitude larger than G1
🟠 G3 (SSD/NVMe): slower, shared across entire node
🟠 G4 (shared network storage): slowest, effectively unlimited in size
At GTC 2026, in a historic partnership with SpaceXAnthropicAI, Jensen announced the newest tier, G5: a Starlink-attached HDD array in low earth orbit.
Excited to see what G6 will be.
452
May 20
If you believe, you have to size correctly. This was my April 15th positions with YTD down due to the $ALAB concentration. Peak copper fear helped set up a nice rebound effect.
1
303
May 20
A lot of the alpha in $ALAB was created by the hyped anti copper narrative this year.
At Morgan Stanley TMT, $ALAB basically reframed the “CPO/optics boogeyman.” Copper doesn’t vanish overnight: in-rack stays copper longer, rack-to-rack is the first optical intercept.
They’re also building into the CPO/NPO roadmap (scale-up optics first), not starting with pluggables.
If they win the optical engine stack: more endpoints higher ASP.
Running into the fire 🔥
157
May 20
$NVDA prints today. The line item I'm watching is NVLink Fusion commentary.
Fusion opens NVIDIA's rack-scale architecture to custom CPUs, ASICs, and XPUs alongside NVIDIA GPUs, not a single-vendor stack.
The $ALAB read-through is direct. AI racks are becoming heterogeneous systems, not GPU clusters. That moves value into host-link signaling, CXL memory expansion, and scale-out connectivity. Aries, Leo, and Taurus ship into all three today.
What I'm watching from here: Aries, Leo, and Taurus attach rates per rack as racks get more heterogeneous.
173
May 20
Gavin speaks. I listen.
May 20

Always enjoy my conversations with @patrick_oshag
Points if you can guess whose office this was filmed in.
Also looks like I might need to up my dose of Tirzepatide. 😂
3
166
May 19
$ALAB What stands out to me is that the story is broadening across two major AI infrastructure bottlenecks:
Scale-up fabric
Scorpio X is the big one here. If AI infrastructure keeps moving toward rack-scale and more distributed inference/training, reducing the coordination tax between accelerators becomes extremely valuable.
Memory tier / KV-cache pressure
Leo is the part I think the market may still be underappreciating. As inference becomes more persistent, context-heavy, and agentic, CXL-attached memory and KV-cache expansion could become much more important.
326
May 18
Atreides, led by Gavin Baker, disclosed in its latest 13F that $ALAB was its largest single-stock long position as of March 31.
The $ALAB thesis is getting cleaner to me.
The biggest AI infrastructure bottlenecks are splitting into two lanes:
Accelerator-to-accelerator fabric
Memory-tier / KV-cache pressure
That maps well to Astera’s product roadmap.
Scorpio X attacks the scale-up fabric bottleneck.
This matters for MoE / expert-parallel training, collective communication, and multi-GPU prefill, where accelerators need lower-latency, higher-bandwidth coordination.
Leo attacks the CXL memory-tier bottleneck.
This matters for decode-heavy inference, KV-cache expansion, longer context, and persistent agentic workloads, where memory bandwidth and memory capacity become constraints.
1
1
1,359
May 15
$ALAB the build up in memory will transition to the fabric. Also, large training runs will drive more scale up fabric.
1
1
1
578