
New Gen and tech
Joined June 2020
- Tweets 1,082
- Following 822
- Followers 509
- Likes 44,235
112 Photos and videos















Jun 7
That looked like such an experienced drive from Kimi 🙌🏽. He absolutely deserves to win
#MonacoGP
1
50


Part of the reason we can't have nice things.. imagine Urban Planning is busy grafting in one of the most important cities in Africa.
Regardless, at least EACC is on it.

EACC detectives raid home of Nairobi County Chief Officer for Urban planning, recovers unknown amount of cash in graft probe
Video by Pkemoi Ng’enoh
16
44
115
7,268
Jun 4
Head of urban planning in Nairobi busy accumulating wealth!
Yet people, shops, cars... are out here being swept by floods.
29
Ray ᯅ retweeted

The @GreenBeltMovmnt condemns plans to excise part of Imenti Forest for an airstrip, golf course & State Lodge. Imenti is a critical water tower & biodiversity haven.
Sign the petition and demand its protection: lnkd.in/dUd_Ku8H
#HandsOffImentiForest #SaveOurForests


8
325
313
9,829
Ray ᯅ retweeted

Jun 3
When a hacker leaves the command line and enters the room!


5
4
114
4,243
Jun 3
My team and I won the @build54Africa x @MLHacks hackathon over the weekend, also got some nice google merch



May 29

Hellooo....
We’re excited to announce the partnership between SpaceYaTech and build54 for an electrifying hackathon experience 🤩😍
.
.
Get ready to build, collaborate, and push ideas beyond limits.
#Hackathon #build54 #SpaceYaTech

41
Jun 1
Anthropic plans to go public!
Jun 1

Anthropic has confidentially submitted a draft S-1 registration statement to the Securities and Exchange Commission.
Pending completion of SEC review, this gives us the option to pursue an initial public offering.
Read more: anthropic.com/news/confident…
22
May 27
I think this is a challenge I can take on.
#WhatIsARoad used to help in spotting potholes
May 26

#Whatisaroad lived a short life. It was an initiative by @kenyanpundit and supported by the tech community. A mobilizer needed to restart it.
1
1
1
319
May 25
Speaking on audacity, I have always wanted to see autonomous driving in Kenya, imagine if nbo-mba highway had order and not these reckless trucks, lorries and matatus.
The models are there all that's needed is hardware and permits
1
1
51

Lifted onto the top, TOP step of the podium! ☝😎
#F1 #CanadianGP
90
2,182
14,717
337,087
May 24
Never even seen one of these in Nairobi!


1
195
May 24
On that note, it's always a pittance how many self declared AI Engineers we have in Nairobi's tech scene😂
I dare say there's less than a hundred actual AI/ML Engineers from Kenya

Now that GITEX Kenya is over, can we all agree it was underwhelming?
I had expected to see Kenyan brands in the AI space. Cool gadgets/software by Kenyans.
Most of them were established international brands. A sign that we are still consumers instead of producers of the tech
4
5
70
6,384
Ray ᯅ retweeted

May 23
Nikupee reason ya kutokea Monday ?
1. Rent increment
2.KRA access to mpesa statements
3.Transaction cost increment
4.Phones will become expensive to purchase
5.MTumba clothes increment
6.Bundles will become more expensive
Ni hayo Tu kwa sasa🖐️😔
170
4,143
11,841
333,710
Ray ᯅ retweeted

May 21
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
May 7

Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
25
151
1,017
173,506
May 21
So many Kenyan tech startups and founders are being pushed out by "serial founders" who know how to raise as much money possible for nothing to show for!
1
8
1,761

We’re partnering with @Samsung, @_GentleMonster_ and @WarbyParker on new intelligent eyewear.
Here's a sneak peek at two designs from this fall's upcoming collections.
#GoogleIO


288
951
8,856
1,535,558
Ray ᯅ retweeted

May 19
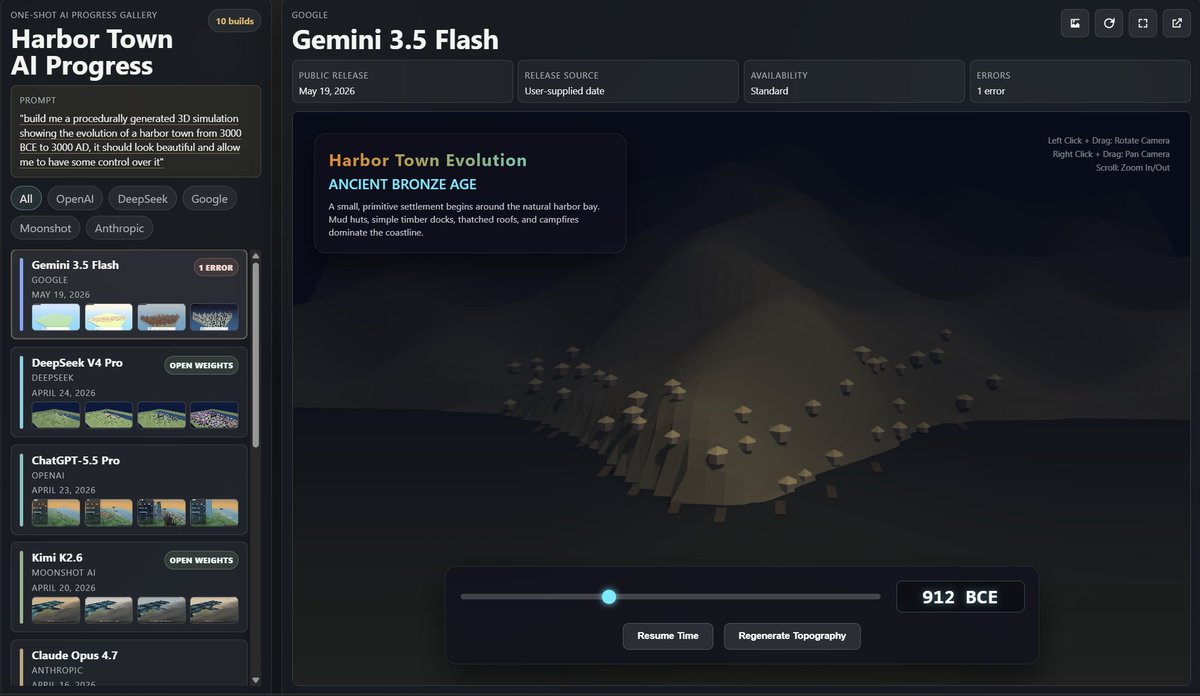
Also had some early access to Gemini 3.5 Flash. Very fast for a flash model and very capable, though not as powerful as a full frontier model.
I added it to the gallery or procedurally generated one-shot towns (it made one error that it corrected): hg-20f7d1a3ce.netlify.app/#g…
12
10
207
13,900

We’re adding new ways for people to identify AI-generated images and understand where they came from.
In addition to C2PA Content Credentials, images now also contain a SynthID watermark, and can be identified using a public verification tool to check whether an image was made by OpenAI products.
openai.com/index/advancing-c…
300
390
4,155
622,313